
重现基线模型
我们选择重现的模型是 Hamel's model。
图片来源及参考博文
https://towardsdatascience.com/semantic-code-search-3cd6d244a39c
https://github.com/hamelsmu/code_search
https://www.code2vec.org/
基线模型原理
如何实现semantic search?我们需要建立一个代码空间和语言空间共享的向量空间,如下图

分别把code和自然语言映射到这个向量空间,就可以对比{text, code}的相似度从而选择相似度最高的进行匹配。所以我们输入自然语言text来搜索代码时,将该语言片段转换成共享空间中的vector,再从code构造的vector数据库中寻找相似度最高的进行匹配并返回。
Overview
整个过程可分为五步:
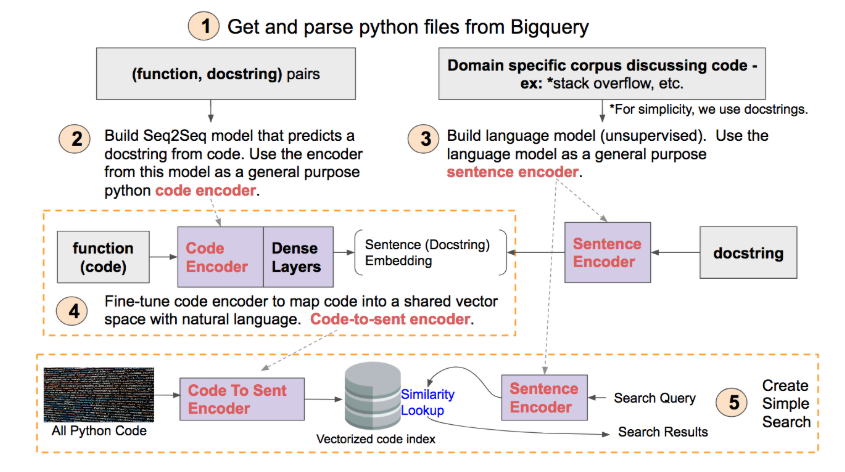
Preprocess
数据预处理,从数据库中提取出代码(函数)、docstring及代码路径。通过代码建立一个词汇表,将代码转化成向量,接下来要作为encoder的输入。docstring是代码的comment,也用词汇表转化成向量作为监督训练encoder的label。保存代码路径是为了查找匹配成功时索引到源码返回给用户。
Code encoder
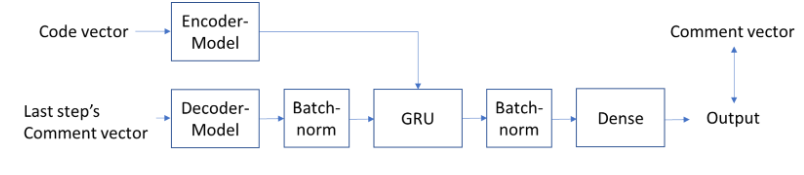
这里使用了Seq2Seq模型,并且采用了teacher forcing的训练策略。什么是teacher forcing呢?RNN模型通常在预测下一个step T时,是将前面T-1个step的输出当作输入来预测,但teacher forcing策略将前T-1个step的Ground Truth作为当前输入。
Seq2Seq模型采用了一个Encoder和decoder结构,并采用GRU来构建。
sentence(text) encoder
使用fast.ai中的AMD_LSTM模型,输入docstring来训练,预测句子中的下一个单词。训练好的模型迁移到编码短词组或句子上。什么是AMD_LSTM模型呢?AMD_LSTM是当前最先进的语言模型之一,在字符模型上也展现了突出的成功。一个简单描述就是,它使用了一些正则化方法、DropConnect策略以及NT-SGD优化器等方式改进了传统的LSTM网络使得它拥有了更好的泛化语言的能力。
Code-to-sent encoder
在预训练好的Seq2Seq模型基础上,用code向量为输入及上一步训练好的language model的输出为监督,对上上步的Code encoder进行fine-tuning,使之将code向量映射到共享空间。
模型的优缺点
该模型实现了code的语义搜索,并且取得了不错的效果,但是其中每一步的过程都尽量简化了(作者在博客中也调到了这一点)。
模型优点
模型的优点感觉一是提供了进行对codeSearch这个任务的整体框架,即将code和docstring编码到相同的向量空间进行比较来完成搜索。另一个是这个模型不光可以应用于代码语义搜索,还可以自然的拓展到其他的搜索或者匹配,比如只需要将其映射到向量空间即可。
模型缺点
缺点的话感觉一是很耗费时间和计算资源,感觉这个模型还是挺大的。二是有很多简化和能提升的地方,比如没有利用的code本身就很结构化的这一特征,直接将code也当作像自然语言一样进行处理。
模型重现结果
我们复现的是项目Semantic Code Search,主要参考的是博客How To Create Natural Language Semantic Search For Arbitrary Objects With Deep Learning
环境配置
由于项目环境配置过程过于复杂,我们使用了作者推荐的Docker容器: hamelsmu/ml-gpu。我们的机器配置,硬件为12核的Intel Core i9 CPU,2块NVIDIA RTX 2080 Ti,系统为Ubuntu 16.04,CUDA版本为10.1,使用Python3.6。
数据准备
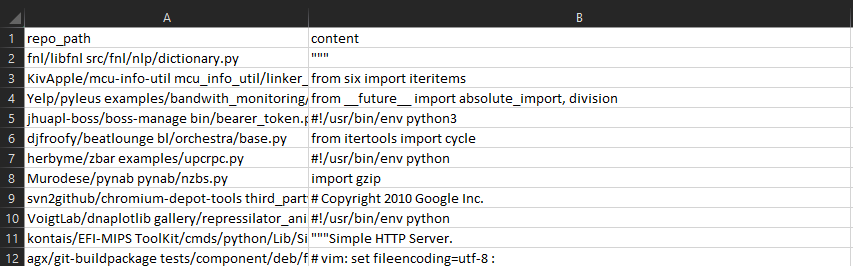
从BigQuery中下载数据,其数据格式如下图所示:
使用AST库存,将这些数据首先解析为(code, docstring)对,结果如下:
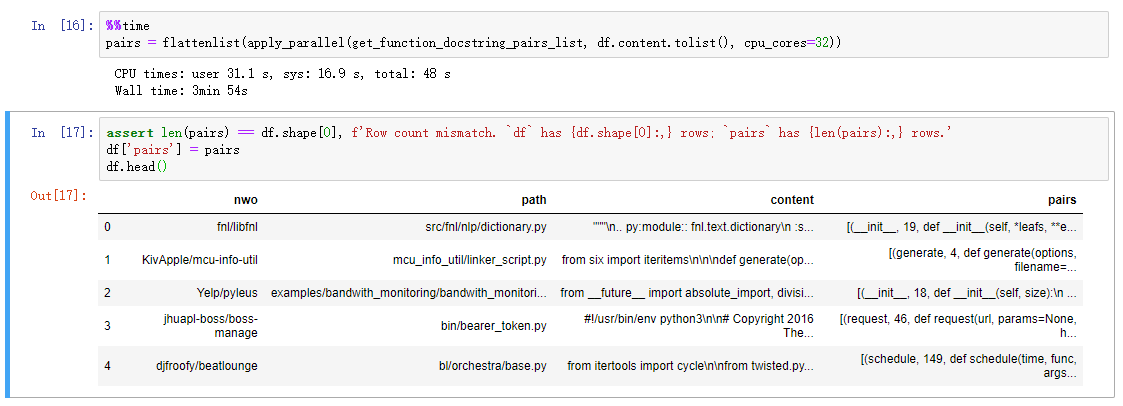
将上表中的pair项中的数据展开为function_name, lineno等,接着对数据进行去重,并根据有无docstring(至少3个单词)对数据进行划分,接着对有docstring的数据分别按照0.87, 0.82的比例对数据进行train,test,valid,得到的结果如下所示:

最后将划分的数据每一类按照function, docstring, linage存储。这一步花费的时间很长,为了节省时间,我们只处理了一部分数据,后面使用的都是作者提供的数据。
训练一个Seq2Seq的模型
在这一步中,会训练一个Seq2Seq的模型,这个模型可以预测给定代码段的docstring。
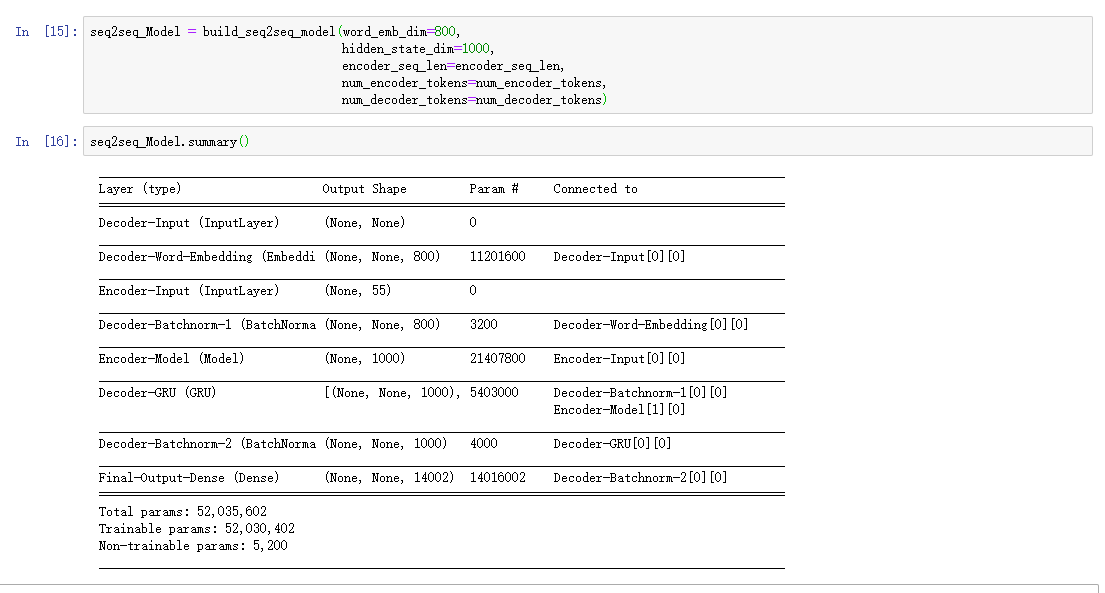
对该模型进行训练,由于我们的卡不是很强,我们修改了batchsize和迭代的次数
![train]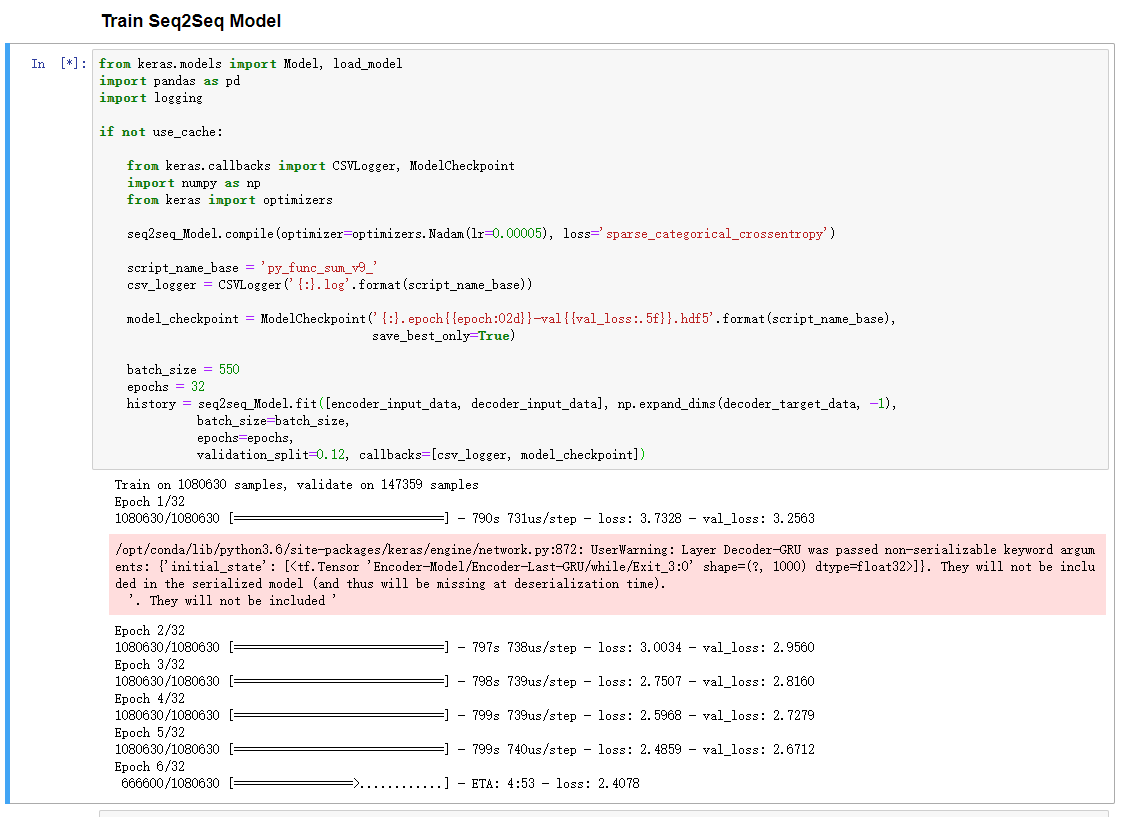
对训练的模型进行测试
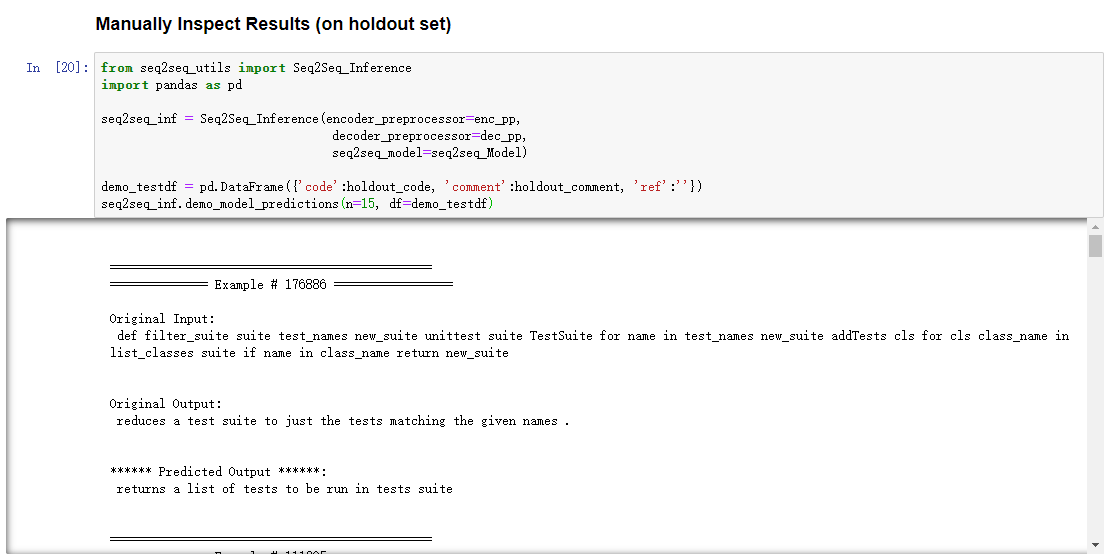
将训练好的模型保存再本地,以备使用
训练一个Language模型
这个模型的作用是可以用docstring生成embedding。
首先处理该模型需要的数据,将数据存在本地。这里直接使用了作者提供的接口。利用这些数据训练一个Fast.AI模型,
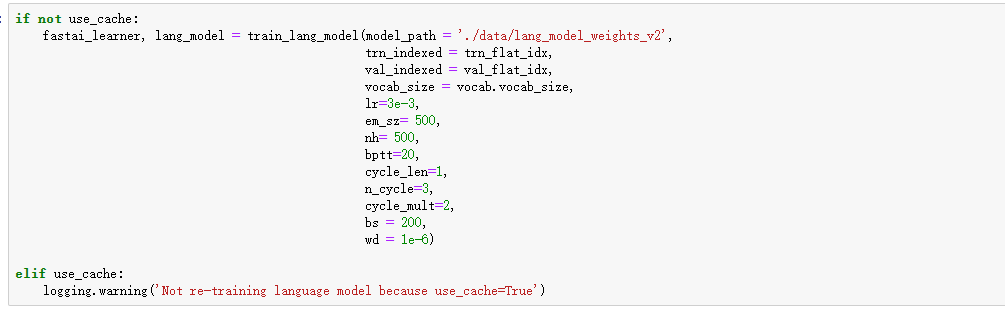
使用训练好的模型处理Docstring,这里的时间太长了,我们中途停止了处理,后面直接使用作者处理好的。

训练一个将Code映射到Embeding空间中的模型
这里需要使用到前面训练好的Seq2Seq模型中的decoder和前面的docstring-embeding模型。
首先加载Seq2Seq中的encoder
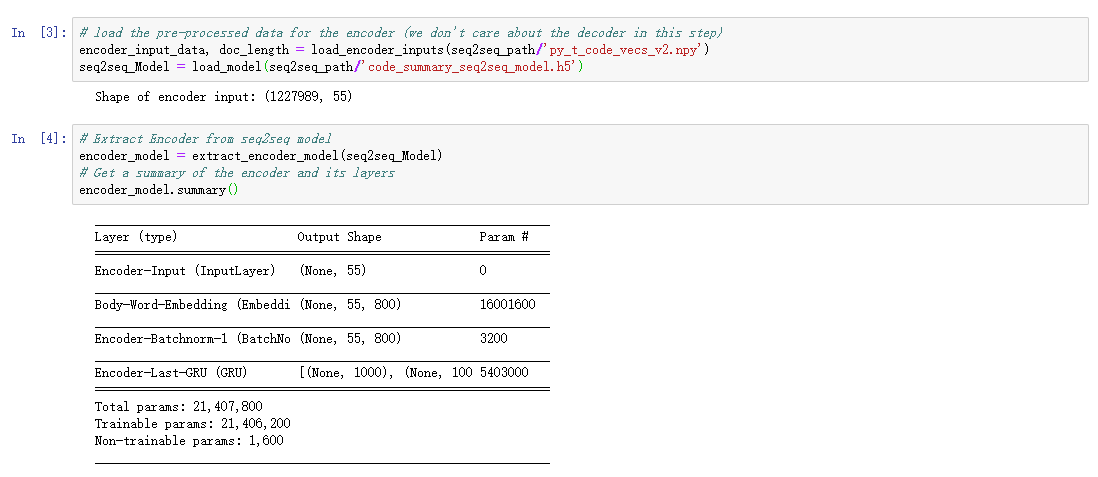
在其后面加上Dense得到Code2Emd模型
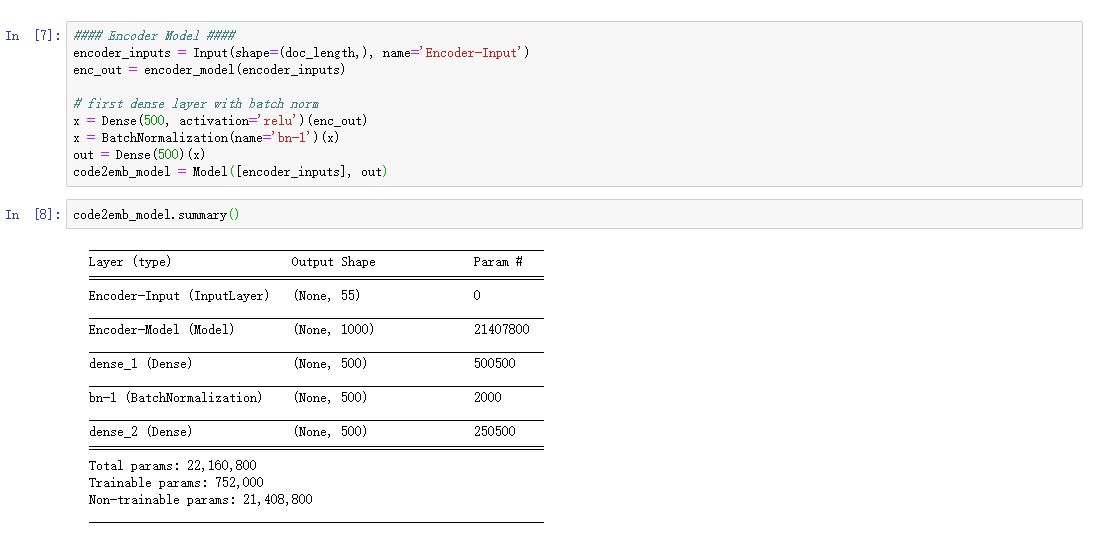
加载docstring-embeding模型,命名为fastailm_emb,在训练Code2Emd模型时使用它
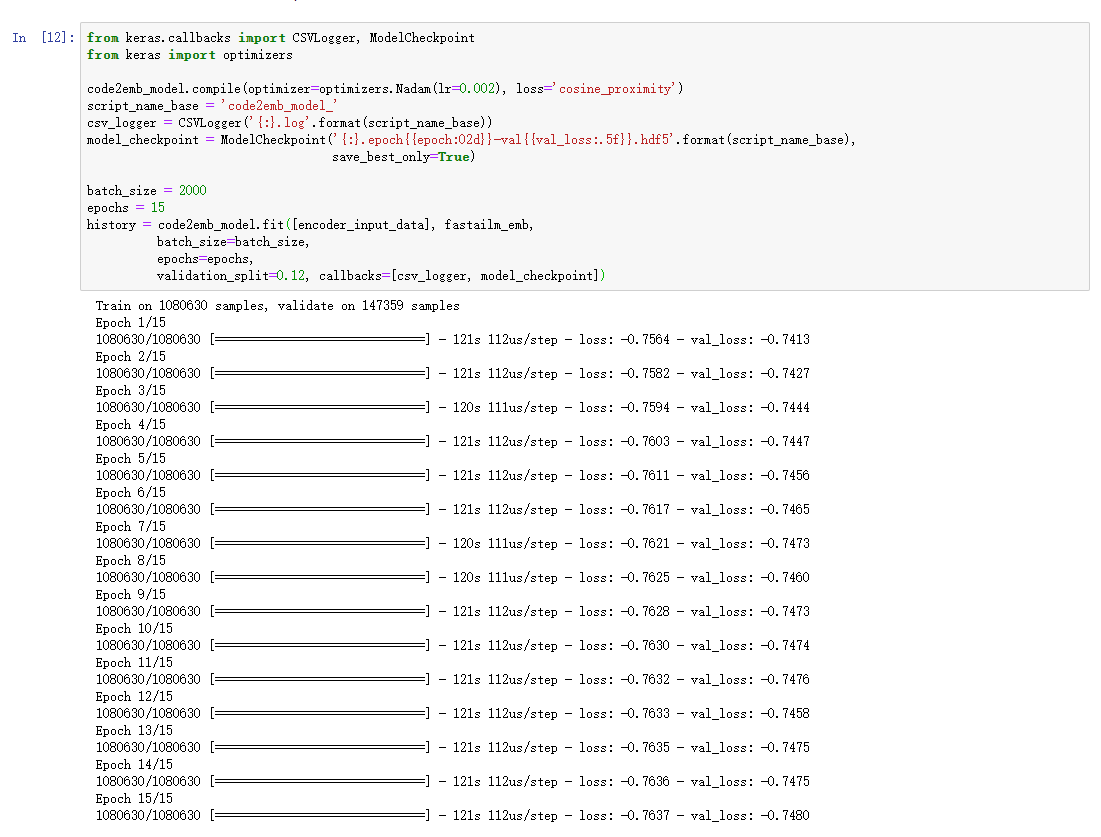
前面我们先将encoder固定住来训练该模型,此时在对整个模型进行一些训练,以便使模型在该数据上表现更好。
在训练好之后,使用该模型将所有的Code生成Embedding.

使用模型创建一个CodeSaerch引擎
使用作者提供的search_enigne类

进行测试
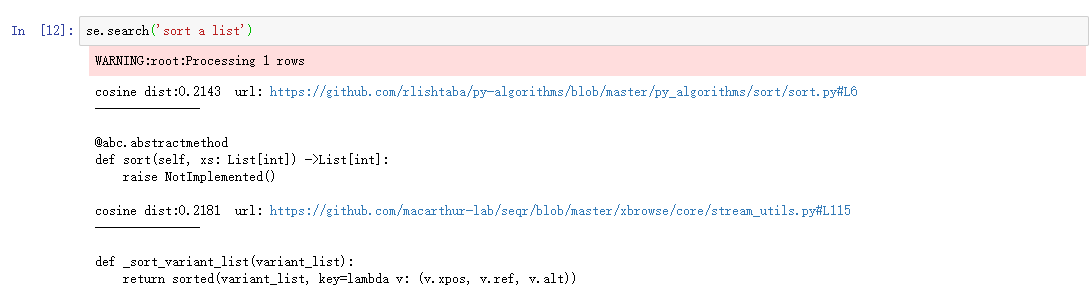
总结
由于作者提供了完整的代码,但是由于我们在硬件上的限制,在训练次数上要比作者少,而且一些很耗时间的refine也没有做,所以我们的模型效果比起原来的应该要略差一点。
我觉得复现中的难点有两个,一个是数据的处理,另一个就是环境的配置。载数据的处理上如果稍不留神,那么我们的模型就根本不可能训练好,因此在实现过程中使用了很多断言来保证数据的正确性。起初我们是在一个新的Anaconda环境下实现的,但是项目中的各种库和依赖配置起来太耗费时间和经历,所以中途转到用docker了,复现工作一下进度就上来了。
提出改进方法
改进动机
我们的改进动机是提高Code Summarizer在将代码映射到向量空间的性能,具体想法是改变代码表示的结构。
在baseline中,Code Summarizer 对代码的处理是比较暴力的,将代码也当作自然语言进行处理,虽然可以得到合理的结果,但这个步骤从直觉上存在很大的提升空间,实际上代码的作者在其文中提到了这个summarizer本身就可以是一个很酷的项目,并建议读者在此引入优化。
从作业给出的参考链接的code2vec中可以得到启发,将function或者method转换成语义树的结构应该比直接将代码parse成词汇能保留更多的语义信息,应该可以提高编码器的性能。
参考链接code2vec 给出了可视化的demo,这里贴出一个截图
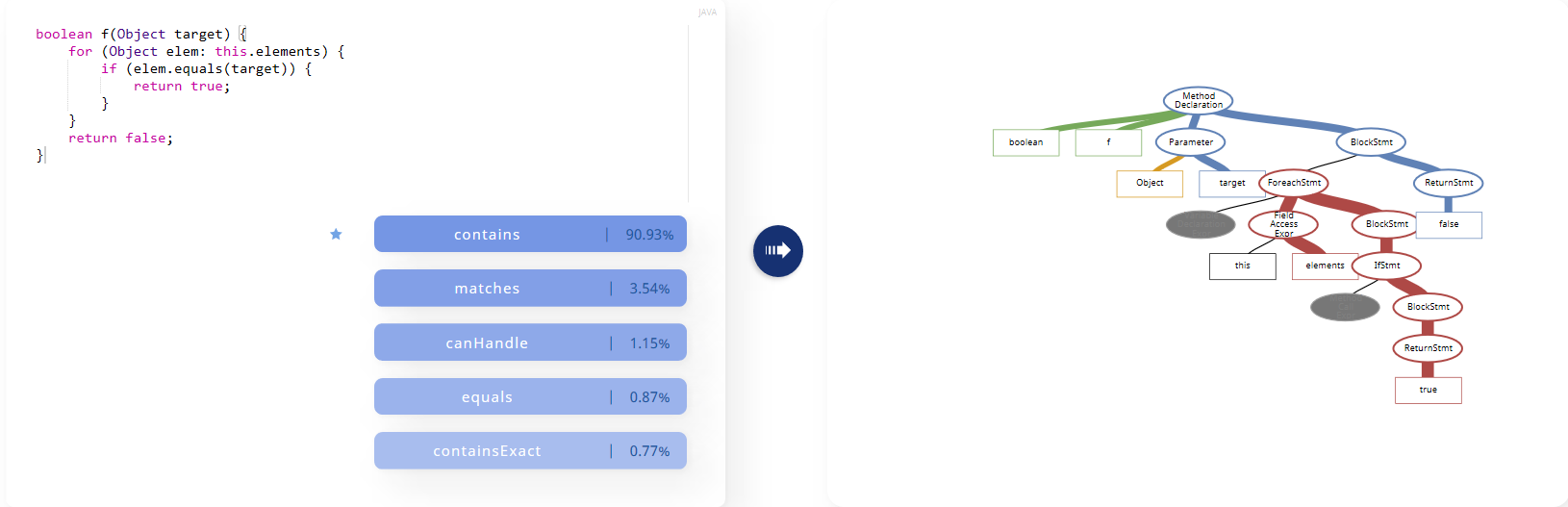
但这样一来Code Summarizer就需要以树作为输入,可能需要引入基于树的LSTM, 虽然对NLP的了解很少,但感觉应该是可以这样进行优化的。
搜索了一下验证可行性,TreeLSTM已经有可以安装的pyhton模块了,Tree LSTM DGL Tutorial, 以及提出TreeLSTM的Paper。
新模型框架
改进的Code Summarizer如下
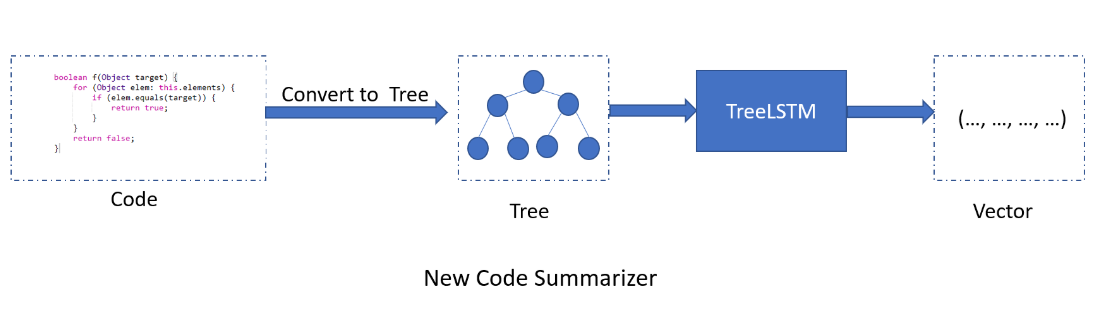
评价合作伙伴
虽然时间很紧,但我们小组三个人分工还是比较明确的,非常幸运小组内部也有同学有空闲的机器,解决了计算资源不足的问题。开过几次会进行讨论,确定了基线模型原理和代码、配置运行环境与实验、阅读其他模型的分工,赶在ddl之前完成了本次作业。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号