
2020寒假学习记录(11)——实验4-2
二、编写独立应用程序实现数据去重
对于两个输入文件A和B,编写spark独立应用程序。对两个文件进行合并,并剔除其中重复的内容。
输入文件A的样例如下:
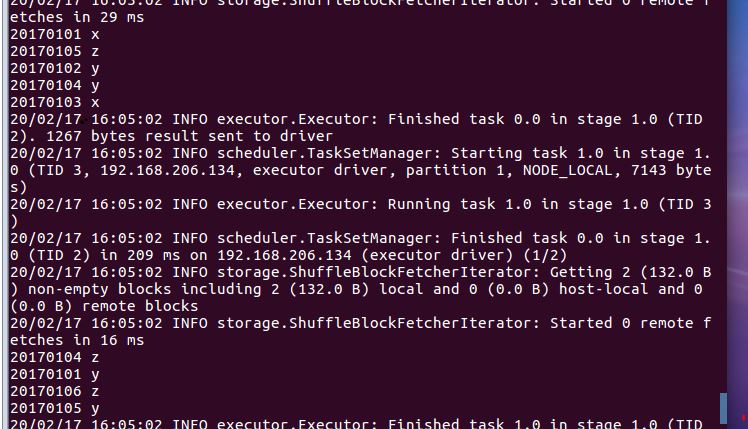
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件B的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z

import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf import org.apache.spark.HashPartitioner object app{ def main(args: Array[String]) { val conf = new SparkConf().setAppName("RemDup") val sc = new SparkContext(conf) val dataFile ="file:///home/hadoop/77/a.txt,file:///home/hadoop/77/b.txt" val data = sc.textFile(dataFile,2) val da = data.distinct() da.foreach(println) da.saveAsTextFile("/home/hadoop/c.txt") println("文件合并完成!") } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号