redis原理
参考
小林coding
《redis设计与实现》
以下代码源自redis7.2版本
redis是基于内存的数据库,对数据的读写操作都是在内存中完成,因此读写速度非常快,常用于缓存,消息队列、分布式锁等场景。
Redis提供了多种数据类型来支持不同的业务场景,比如String(字符串)、Hash(哈希)、 List(列表)、Set(集合)、Zset(有序集合)、Bitmaps(位图)、HyperLogLog(基数统计)、GEO(地理信息)、Stream(流),并且对数据类型的操作都是原子性的,因为执行命令由单线程负责的,不存在并发竞争的问题。
除此之外,Redis还支持事务、持久化、Lua脚本、多种集群方案(主从复制模式、哨兵模式、切片集群模式)、发布/订阅模式,内存淘汰机制、过期删除机制等等
线程模型
Redis单线程指的是接收客户端请求->解析请求->进行数据读写等操作->发送数据给客户端这个过程是由一个线程来完成的。但是Redis程序并不是单线程的,Redis在启动的时候会启动后台线程的。
Redis在2.6,会启动2个后台线程,分别处理关闭文件、AOF刷盘这两个任务;
Redis在4.0之后,新增了一个新的后台线程,用来异步释放Redis内存。例如执行unlink key/flushdb async/flushall async等命令,会把这些删除操作交给后台线程来执行,好处是不会导致Redis主线程卡顿。(因此,当删除一个大key的时候,不要使用del命令删除,因为del是在主线程处理的,这样会导致Redis主线程卡顿。应该使用unlink命令来异步删除大key)
Redis采用单线程快的原因:
Redis的大部分操作都在内存中完成,并且采用了高效的数据结构,因此Redis瓶颈可能是机器的内存或者网络带宽,而并非CPU,既然CPU不是瓶颈,那么自然就采用单线程的解决方案了
Redis采用单线程模型可以避免了多线程之间的竞争,省去了多线程切换带来的时间和性能上的开销,而且也不会导致死锁问题
Redis采用了I/O多路复用机制处理大量的客户端Socket请求
Redis6.0之后为什么引入了多线程?
Redis6.0版本之后,也采用了多个I/O线程来处理网络请求,这是因为随着网络硬件的性能提升,Redis的性能瓶颈有时会出现在网络I/O的处理上。所以为了提高网络I/O的并行度,Redis 6.0对于网络I/O采用多线程来处理。但是对于命令的执行,Redis仍然使用单线程来处理
底层数据结构
- String类型的应用场景:缓存对象、常规计数、分布式锁、共享session信息等。
- List类型的应用场景:消息队列(但是有两个问题:1. 生产者需要自行实现全局唯一 ID;2. 不能以消费组形式消费数据)等。
- Hash类型:缓存对象、购物车等。
- Set类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等。
- Zset类型:排序场景,比如排行榜、电话和姓名排序等。
- BitMap(2.2新增):二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
- HyperLogLog(2.8新增):海量数据基数统计的场景,比如百万级网页UV计数等;
- GEO(3.2新增):存储地理位置信息的场景,比如滴滴叫车;
- Stream(5.0新增):消息队列,相比于基于List类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据
字符串SDS(简单动态字符串)
C 语言的字符串不足之处以及可以改进的地方:
- 获取字符串长度的时间复杂度为 O(N)
- 字符串的结尾是以 “\0” 字符标识,字符串里面不能包含有 “\0” 字符,因此不能保存二进制数据
- 字符串操作函数不高效且不安全,比如有缓冲区溢出的风险,有可能会造成程序运行终止
struct sdshdr64 {
uint64_t len; //字符串长度
uint64_t alloc; //buf的大小
unsigned char flags; //字符串类型,sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64。这5种类型的主要区别就在于,它们数据结构中的 len 和 alloc 成员变量的数据类型不同
char buf[]; //C风格的字符串,以'\0'结尾(为了兼容C),但不算在len中
};
特点:
获取字符串长度的时间复杂度为O(1)
避免缓冲区溢出:拼接字符串时,首先判断buf空间是否足够,不够则自动扩容后再拼接
buf空间预分配与惰性空间释放:分配时额外多分配,释放时不释放先保留
列表
应用于列表键,发布订阅,慢查询,监视器等
typedef struct listNode {
struct listNode *prev;// 前一个节点
struct listNode *next;// 后一个节点
void *value;// 节点保存的值
} listNode;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);// 复制节点的值的函数
void (*free)(void *ptr);// 释放节点的值的函数
int (*match)(void *ptr, void *key);// 比较节点的值的函数
unsigned long len;//链表长度
} list;
压缩列表
为了节约内存,如果是链表,每个节点还要存放前后两个指针,比保存的数据本身占用的而空间还多,所以在数据量少的使用使用压缩列表
压缩列表的空间布局为
总字节长度zlbytes
尾节点偏移量zltail
节点数量zllen
多个节点项entry
结束符zlend
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
zl[bytes-1] = ZIP_END;
return zl;
}
typedef struct zlentry {
unsigned int prevrawlensize;// 前一个节点长度信息的长度
unsigned int prevrawlen; // 前一个节点长度,压缩列表保存前一个项的长度,主要用于从后向前遍历
unsigned int lensize; // 当前节点长度信息的长度
unsigned int len; // 当前节点长度
unsigned int headersize; // 当前节点头部信息长度
unsigned char encoding; // 数据的编码格式
unsigned char *p; // 数据
} zlentry;
连锁更新的隐患:因为每个节点保存了前一个节点的长度,所以当一个节点长度改变,后一个节点长度也可能改变,这样之后的都可能改变
新引入listpack作为压缩列表,结构如下
总字节数
元素总数
多个节点项:每个节点项只包含编码方式(即数据类型),数据,当前节点长度
结尾标记
unsigned char *lpNew(size_t capacity) {
unsigned char *lp = lp_malloc(capacity > LP_HDR_SIZE+1 ? capacity : LP_HDR_SIZE+1);
if (lp == NULL) return NULL;
lpSetTotalBytes(lp,LP_HDR_SIZE+1);
lpSetNumElements(lp,0);
lp[LP_HDR_SIZE] = LP_EOF;
return lp;
}
结合压缩列表节省内存的优点和双向链表的优点快表quicklist
即使用双向链表,每个链表节点是listpack
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next; // 双向链表,记录前后指针
unsigned char *entry; // 存储的元素
size_t sz; // 总字节数
unsigned int count : 16; // 节点中元素的数量
unsigned int encoding : 2; //RAW==1 or LZF==2 压缩还是不压缩
unsigned int container : 2; // PLAIN==1 or PACKED==2 采用哪种结构存储,这里使用listpack
unsigned int recompress : 1; //节点是否需要被压缩
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int dont_compress : 1; /* prevent compression of entry that will be used later */
unsigned int extra : 9; /* more bits to steal for future usage */
} quicklistNode;
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; // 每个quicklistNodes中元素的数量,
unsigned long len; // quicklistNodes的数量
signed int fill : QL_FILL_BITS; // 控制每个节点最大元素数量
unsigned int compress : QL_COMP_BITS; //左右两边不被压缩的节点的个数
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
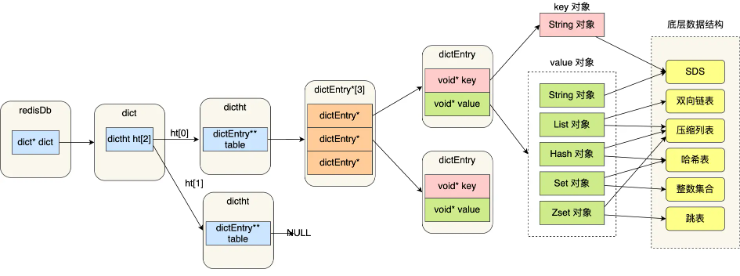
字典
redis使用字典作为底层实现
struct dict {
dictType *type;// 键值对的类型及对应函数
dictEntry **ht_table[2];// 哈希表,一般使用0哈希表,1在rehash时使用
unsigned long ht_used[2];// 字典中现有数据个数
long rehashidx;// rehash索引,如果没有进行reshash,值为-1
int16_t pauserehash;// 小于0表示rehash暂停
signed char ht_size_exp[2];
void *metadata[];// 不同type可能定义有任意字节的数据
};
哈希表桶中节点
struct dictEntry {
void *key;// 键
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;// 值
struct dictEntry *next;// 同一个桶中的下一个节点
void *metadata[];
};
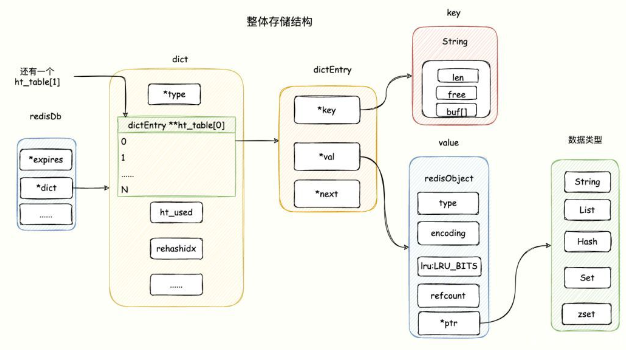
redis默认的hash函数是siphash,哈希冲突解决:拉链法
渐进式rehash(用于对哈希表进行扩展):
当哈希表中键值对过多或过少时,将表0中键值对重新哈希保存到表1,完成后用表1代替表0,再新建表1
rehash时采用渐进的方式,将rehashidx设为0,每次插入数据时,顺带将rehashidx处数据rehash,rehashidx++,直至最后完成
整数集合
typedef struct intset {
uint32_t encoding;//编码方式
uint32_t length;//包含元素的数量
int8_t contents[];// 包含的元素
} intset;
升级操作:
如果新加入的元素比原有元素的类型要长,必须将原有元素转为新元素相同类型(比如原来元素编码都是int16,新加入元素为int32,则要将原来元素转为int32)
整数集合升级的过程不会重新分配一个新类型的数组,而是在原本的数组上扩展空间,然后在将每个元素按间隔类型大小分割
跳表
有序集合键的底层
typedef struct zskiplistNode {
sds ele;// 数据
double score;// 分值,用于排序
struct zskiplistNode *backward; // 后向指针
struct zskiplistLevel {
struct zskiplistNode *forward;// 前向指针
unsigned long span;// 跨度,用于计算节点在表中的位置
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;// 指向跳表头节点与尾节点
unsigned long length;// 跳表节点数量
int level;// 表目前最大层数
} zskiplist;
相比平衡树的优点:
内存占用少
有利于范围查找
算法实现难度简单
对象
redis基于多种数据结构实现了5种对象,并使用对象表示数据库中的键和值,每种对象底层可以设置不同数据结构应对不同场景
5种对象为字符串对象,列表对象,哈希对象,集合对象,有序集合对象
#define OBJ_STRING 0 /* String object. */
#define OBJ_LIST 1 /* List object. */
#define OBJ_SET 2 /* Set object. */
#define OBJ_ZSET 3 /* Sorted set object. */
#define OBJ_HASH 4 /* Hash object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* No longer used: old hash encoding. */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* No longer used: old list/hash/zset encoding. */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of listpacks */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
#define OBJ_ENCODING_LISTPACK 11 /* Encoded as a listpack */
struct redisObject {
unsigned type:4; // 对象类型
unsigned encoding:4; // 对象底层数据结构类型
unsigned lru:LRU_BITS; //记录空转时长,用于LRU LFU等算法,内存回收时,根据这个字段进行对象的内存回收
int refcount; // 该对象的引用计数,垃圾回收机制
void *ptr; // 对象底层数据结构
};
字符串对象
使用整数int,原始字符串raw(原始的sds)或embstr(优化后的sds)作为底层数据结构
embstr短字符串优化:当字符串小于44字节的时候,会创建embstr编码的字符串对象(将字符串数据和对象保存在连续的内存中,可以减少内存分配和释放的次数)
embstr字符串对象是只读的,修改时需要转为raw原始的字符串对象再修改
列表对象
使用快表(双向链表)或listpack作为底层数据结构
当列表保存的所有字符串项小于512,且字符串长度小于64B才使用压缩列表
应用场景:
基于List类型的消息队列,满足消息队列的三大需求(消息保序、处理重复的消息和保证消息可靠性)。但List不支持多个消费者消费同一条消息
哈希对象
是键值对集合
使用字典或listpack作为底层数据结构
当哈希对象保存的所有键值对小于512,且键值的字符串长度小于64B才使用压缩列表
应用场景:
一般对象用String+Json存储,对象中某些频繁变化的属性可以考虑抽出来用Hash类型存储
集合对象
无序并唯一的键值对集合
使用整数集合或者字典或者listpack作为底层数据结构,使用字典时,所有值为NULL
当保存的都是整数,且数量少于512时,才使用整数集合
有序集合对象
使用跳表或者listpack作为底层数据结构
使用跳表时,实际上还会有一个字典,存储每个元素及对应的分值score(使其能够在O(1)时间内得到元素分值),score用于排序
当保存元素小于512,且元素的字符串长度小于64B才使用压缩列表
stream
专门为消息队列设计的数据类型
Stream没出来之前,消息队列的实现方式都有着各自的缺陷,例如:
发布订阅模式,不能持久化也就无法可靠的保存消息,并且对于离线重连的客户端不能读取历史消息
List实现消息队列的方式不能重复消费,一个消息消费完就会被删除,而且生产者需要自行实现全局唯一ID。
只有业务场景足够简单,对于数据丢失不敏感,而且消息积压概率比较小的情况下,才把 Redis当作消息队列,因为会导致数据丢失:
AOF持久化配置为每秒写盘,但这个写盘过程是异步的,Redis宕机时会存在数据丢失的可能
主从复制也是异步的,主从切换时,也存在丢失数据的可能。
Redis的数据都存储在内存中,这就意味着一旦发生消息积压,则会导致Redis的内存持续增长,如果超过机器内存上限,就会面临被OOM的风险
Redis发布/订阅机制为什么不可以作为消息队列?
发布/订阅机制没有基于任何数据类型实现,所以不具备数据持久化的能力,也就是发布/订阅机制的相关操作,不会写入到RDB和AOF中,当Redis宕机重启,发布/订阅机制的数据也会全部丢失。
发布订阅模式是“发后既忘”的工作模式,如果有订阅者离线重连之后不能消费之前的历史消息。
当消费端有一定的消息积压时,也就是生产者发送的消息,消费者消费不过来时,如果超过32M或者是60s内持续保持在8M以上,消费端会被强行断开
所以,发布/订阅机制只适合即时通讯的场景,比如构建哨兵集群的场景采用了发布/订阅机制
数据库
redis中每个数据库结构如下,默认使用0号数据库,可以通过select命令切换
typedef struct redisDb {
dict *dict; // 数据库中保存的所有数据,即保存的所有键值对
dict *expires; // 保存所有键的过期时间,当过期时间到来,键会被自动删除
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *blocking_keys_unblock_on_nokey; /* Keys with clients waiting for
* data, and should be unblocked if key is deleted (XREADEDGROUP).
* This is a subset of blocking_keys*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; // 正在被监视的数据库键
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
clusterSlotToKeyMapping *slots_to_keys; /* Array of slots to keys. Only used in cluster mode (db 0). */
} redisDb;
Redis如何保存所有键值对
过期键的删除策略
dict *expires保存了所有键的过期时间,读取键时,先查这个字典是否有过期时间,再判断是否过期
定时删除:设置过期时间时就创建一个定时器
优:内存友好,及时删除
缺:占用cpu
惰性删除:读取键时,判断键是否过期,过期就删除
优:CPU友好
缺:内存不友好,键不被访问,永远无法删除
定期删除:每隔一段时间,检查数据库,删除过期键
redis采用惰性+定期删除(定期删除时,每次取一部分数据检查,下次再接着这次的进度继续检查)
对于主从数据库,从的过期键依然能正常使用,只有当主发现过期键过期,并向从发送删除命令时,从的这个过期键才不能正常使用(为了保证主从一致性)
Redis持久化时,对过期键会如何处理的?
Redis持久化文件有两种格式:RDB(Redis Database)和 AOF(Append Only File)
RDB文件分为两个阶段,RDB文件生成阶段和加载阶段。
RDB文件生成阶段:从内存状态持久化成RDB(文件)的时候,会对key进行过期检查,过期的键不会被保存到新的 RDB 文件中
RDB加载阶段:RDB 加载阶段时,要看服务器是主服务器还是从服务器:
如果Redis是主服务器,在载入RDB文件时,程序会对文件中保存的键进行检查,过期键不会被载入到数据库中。
如果Redis是从服务器,在载入RDB文件时,不论键是否过期都会被载入到数据库中。但由于主从服务器在进行数据同步时,从服务器的数据会被清空。所以,过期键对载入RDB文件的从服务器也不会造成影响。
AOF文件分为两个阶段,AOF文件写入阶段和AOF重写阶段。
AOF文件写入阶段:当Redis以AOF模式持久化时,如果数据库某个过期键还没被删除,那么 AOF文件会保留此过期键,当此过期键被删除后,Redis会向AOF文件追加一条 DEL 命令来显式地删除该键值。
AOF重写阶段:执行AOF重写时,会对Redis中的键值对进行检查,已过期的键不会被保存到重写后的AOF文件中
内存淘汰策略
在Redis的运行内存达到设置的最大运行内存,才会触发内存淘汰策略
淘汰策略有:不淘汰(直接停止服务)和淘汰
淘汰又分为淘汰过期数据和淘汰所有数据
volatile-random:随机淘汰设置了过期时间的任意键值;
volatile-ttl:优先淘汰更早过期的键值。
volatile-lru(Redis3.0之前,默认的内存淘汰策略):淘汰所有设置了过期时间的键值中,最久未使用的键值;
volatile-lfu(Redis4.0后新增的内存淘汰策略):淘汰所有设置了过期时间的键值中,最少使用的键值;
在所有数据范围内进行淘汰:
allkeys-random:随机淘汰任意键值;
allkeys-lru:淘汰整个键值中最久未使用的键值;
allkeys-lfu(Redis4.0后新增的内存淘汰策略):淘汰整个键值中最少使用的键值。
Redis实现的是一种近似LRU算法,目的是为了更好的节约内存,它的实现方式是在Redis的对象结构体中添加一个额外的字段,用于记录此数据的最后一次访问时间。当Redis进行内存淘汰时,会使用随机采样的方式来淘汰数据,它是随机取5个值(此值可配置),然后淘汰最久没有使用的那个
LFU为最近最不常用,根据数据访问次数来淘汰数据的,它的核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高
在LFU算法中,Redis对象头的24 bits的lru字段被分成两段来存储,高16bit存储ldt,低8bit存储logc
ldt是用来记录key的访问时间戳;
logc是用来记录key的访问频次,它的值越小表示使用频率越低,越容易淘汰,每个新加入的key的logc初始值为5。logc并不是单纯的访问次数,而是访问频次(访问频率),因为 logc会随时间推移而衰减的。在每次key被访问时,会先对logc做一个衰减操作,衰减的值跟前后访问时间的差距有关系,如果上一次访问的时间与这一次访问的时间差距很大,那么衰减的值就越大。然后对logc进行增加操作,增加操作并不是单纯的+1,而是根据概率增加,如果 logc越大的key,它的logc就越难再增加
持久化
redis数据全部在内存中,一旦机器崩溃,数据将全部丢失,为此,redis提供了持久化功能,有两种实现方式:RDB和AOF
RDB
优:内容紧凑,数据恢复方便,适合备份
缺:一段时间才备份,可能会丢失这段时间数据。如果数据量大,处理占用CPU资源
保存数据集的快照。把内存中的所有数据都记录到磁盘中。
有三种方式触发,手动:运行save命令或bgsave命令,自动:配置隔一段时间触发
save:阻塞当前服务,将快照完全保存下来后,再对外进行服务
bgsave:fork子进程,父进程继续对外服务,子进程负责保存快照。
但是如果子进程保存数据的同时,父进程要对数据修改的冲突如何解决?
使用copy on write机制:fork子进程后,将父进程内存页的权限设为只读。当父进程要修改数据时,将数据页复制一份,父进程在复制的页上修改,子进程不影响。
自动:设置每隔多少秒修改超过多少次就生成快照一次
int rdbSaveRio(int req, rio *rdb, int *error, int rdbflags, rdbSaveInfo *rsi) {
char magic[10];
uint64_t cksum;
long key_counter = 0;
int j;
if (server.rdb_checksum)
rdb->update_cksum = rioGenericUpdateChecksum;
// 首先是redis魔术符,之后是rdb文件的格式
snprintf(magic,sizeof(magic),"REDIS%04d",RDB_VERSION);
if (rdbWriteRaw(rdb,magic,9) == -1) goto werr;
// 之后是rdb文件的元属性,记录文件被创建时的状态等信息
if (rdbSaveInfoAuxFields(rdb,rdbflags,rsi) == -1) goto werr;
if (!(req & SLAVE_REQ_RDB_EXCLUDE_DATA) && rdbSaveModulesAux(rdb, REDISMODULE_AUX_BEFORE_RDB) == -1) goto werr;
if (!(req & SLAVE_REQ_RDB_EXCLUDE_FUNCTIONS) && rdbSaveFunctions(rdb) == -1) goto werr;
// 记录各个数据库的信息,记录时先记录各个数据库编号(前面有魔术符RDB_OPCODE_SELECTDB)和大小(前面有魔术符RDB_OPCODE_RESIZEDB),然后记录各个键值对
// 每个键值对根据类型格式不同,基本除了保存的数据外,还保存类型,过期时间,长度等信息
if (!(req & SLAVE_REQ_RDB_EXCLUDE_DATA)) {
for (j = 0; j < server.dbnum; j++) {
if (rdbSaveDb(rdb, j, rdbflags, &key_counter) == -1) goto werr;
}
}
if (!(req & SLAVE_REQ_RDB_EXCLUDE_DATA) && rdbSaveModulesAux(rdb, REDISMODULE_AUX_AFTER_RDB) == -1) goto werr;
// 之后写入EOF
if (rdbSaveType(rdb,RDB_OPCODE_EOF) == -1) goto werr;
// 最后写入校验码
cksum = rdb->cksum;
memrev64ifbe(&cksum);
if (rioWrite(rdb,&cksum,8) == 0) goto werr;
return C_OK;
werr:
if (error) *error = errno;
return C_ERR;
}
AOF
优:发生故障丢失的数据少
缺:日志体积大
保存执行的写命令
对于每一条写命令,先执行,再将其写入AOF日志,有两种触发方式:每次数据修改都及时写日志和异步每一秒写一次日志(此时先将命令写入一个缓冲区),写回都是由主线程写回
日志重写:为了避免日志不断膨胀,每一段时间对日志整理重写。如果此时有新的命令,它要被同时发送到旧AOF日志和正在重写的AOF日志
日志重写由子进程执行,子进程进行AOF重写期间,主进程可以继续处理命令请求,从而避免阻塞主进程;
使用子进程而不是线程,因为如果是使用线程,多线程之间会共享内存,那么在修改共享内存数据的时候,需要通过加锁来保证数据的安全,而这样就会降低性能。而使用子进程,创建子进程时,父子进程是共享内存数据的,不过这个共享的内存只能以只读的方式,而当父子进程任意一方修改了该共享内存,就会发生写时复制,于是父子进程就有了独立的数据副本,就不用加锁来保证数据安全
混合持久化
保存RDB和下一次创建RDB间的AOF。使用了混合持久化,AOF文件的前半部分是RDB格式的全量数据,后半部分是AOF格式的增量数据
事件
文件事件处理
redis基于reactor模式开发了自己的网络事件处理器,被称为文件事件处理
https://www.jb51.net/article/230514.htm
https://blog.csdn.net/qq_34448345/article/details/128944766
redis实现了基于select epool evport kqueue四种IO多路复用函数
根据监听的每个事件(可读事件AE_READABLE和可写事件AE_WRITABLE),redis将其交给不同的处理器:
连接应答处理器:用于对连接服务器监听套接字的客户端进行应答,当有客户端连接时,产生可读事件,并分配给连接应答处理器处理
命令请求处理器:当客户端向服务器发送命令,会产生可读事件,并分配给命令请求处理器处理
命令回复处理器:当服务器向客户端回复时,产生可写事件,并分配给命令回复处理器处理
时间事件处理
时间事件以无序链表来保存,每次需要遍历查看事件是否到达
/* Time event structure */
typedef struct aeTimeEvent {
long long id; //唯一编号
monotime when; //时间事件的到达时间
aeTimeProc *timeProc; // 时间到达时处理函数
aeEventFinalizerProc *finalizerProc;
void *clientData;
struct aeTimeEvent *prev;
struct aeTimeEvent *next;
int refcount; /* refcount to prevent timer events from being
* freed in recursive time event calls. */
} aeTimeEvent;
发布订阅
每个客户端,可以订阅频道或模式(模式可以匹配多个频道),向频道发送消息,订阅的客户端都能收到消息
发布订阅模式也是一种生产者/消费者模型,和传统消息队列不同,消息队列只转发,不存储,所以新订阅的客户端收不到历史消息
发布订阅可以用作轻量级的消息队列,实现上下游解耦,也用在哨兵间通信
struct redisServer {
//...
dict *pubsub_channels; // 所有的频道的订阅关系都保存在这个字典中,一个频道有多个订阅者,以链表形式保存
dict *pubsub_patterns; // 所有模式的订阅关系
int notify_keyspace_events; /* Events to propagate via Pub/Sub. This is an xor of NOTIFY_... flags. */
dict *pubsubshard_channels; /* Map shard channels to list of subscribed clients */
//...
}
struct client {
dict *pubsub_channels; /* channels a client is interested in (SUBSCRIBE) */
list *pubsub_patterns; /* patterns a client is interested in (SUBSCRIBE) */
}
事务
执行MULTI命令开启事务,之后所有的命令都入队到mstate中,执行EXEC,所有命令依次出队执行
struct client{
multiState mstate;
}
typedef struct multiState {
multiCmd *commands; // 保存的多个命令
int count; // 命令的总数
int cmd_flags; /* The accumulated command flags OR-ed together.
So if at least a command has a given flag, it
will be set in this field. */
int cmd_inv_flags; /* Same as cmd_flags, OR-ing the ~flags. so that it
is possible to know if all the commands have a
certain flag. */
size_t argv_len_sums; /* mem used by all commands arguments */
int alloc_count; /* total number of multiCmd struct memory reserved. */
} multiState;
// 命令的信息
typedef struct multiCmd {
robj **argv; // 保存的命令指针
int argv_len;
int argc;
struct redisCommand *cmd; // 指向命令实现函数的指针
} multiCmd;
乐观锁WATCH
每个数据库都维护有一个监视的数据库键
之后每个客户端,每执行一条命令就要检查是否修改了被监视的数据库键,如果发现被修改,设置一个标识
当事务在执行EXEC提交时,如果发现该标识已经设置,则拒绝提交执行
基于watch实现秒杀功能,阻止超卖
typedef struct redisDb {
dict *watched_keys; // 正在被监视的数据库键
} redisDb;
redis事务的ACID
redis事务不具有原子性:
因为redis事务不支持回滚:
当入队的命令有语法错误时,会报错,事务取消
当EXEC提交事务执行时,出现命令执行失败,不影响其它命令的执行
一致性
入队时报错,事务取消
执行时失败,不影响其它命令
服务停机,如果有持久化,根据RDB或AOF恢复,没持久化,为空白数据库
隔离性
redis使用 单线程方式执行事务和事务中的命令
作者不支持事务回滚的原因有以下两个:
他认为Redis事务的执行时,错误通常都是编程错误造成的,这种错误通常只会出现在开发环境中,而很少会在实际的生产环境中出现,所以他认为没有必要为Redis开发事务回滚功能;
不支持事务回滚是因为这种复杂的功能和Redis追求的简单高效的设计主旨不符合。
这里不支持事务回滚,指的是不支持事务运行时错误的事务回滚
复本
首先要建立tcp长连接
当从服务器是第一次复制同步主服务器的日志,主服务器会将所有日志和自己的服务器id发送,发送的日志会保存在一个缓存区中(有大小限制,先入先出),并保存一个已发送日志的偏移量,从服务器也保存已复制日志的偏移量
之后从服务器再复制时,先对比保存的服务器id与现在的主服务器id是否一致,不一致则要复制所有日志
如果一致,看自己偏移量处的日志是否在缓存区中,如果在缓存区中,则发送需要的日志
如果不在缓存区中,发送所有日志
中间从服务器会默认每秒向主服务器发送心跳检测,如果发现主从偏移量不一致(可能由于网络原因),主服务器会重发缺失的日志
主从复制架构中,过期key如何处理?
主节点处理了一个key或者通过淘汰算法淘汰了一个key,这个时间主节点模拟一条del命令发送给从节点,从节点收到该命令后,就进行删除key的操作。
Redis是同步复制还是异步复制?
Redis主节点每次收到写命令之后,先写到内部的缓冲区,然后异步发送给从节点。
主从切换过程中,产生数据丢失的情况有两种:
异步复制同步丢失
集群产生脑裂数据丢失
哨兵sentinel
主从如何做到故障自动切换?
主节点挂了,从节点是无法自动升级为主节点的。哨兵在发现主节点出现故障时,由哨兵自动完成故障发现和故障转移,并通知给应用方,从而实现高可用性
一个或多个哨兵可以监视多个主服务器和从服务器,当主服务器下线,可以自动将从属的从服务升级为主服务器
初始化一个哨兵实例,其状态保存为
/* Main state. */
struct sentinelState {
char myid[CONFIG_RUN_ID_SIZE+1]; /* This sentinel ID. */
uint64_t current_epoch; /* Current epoch. */
dict *masters; //所有监视的主服务器信息。键为主服务器名字,值为sentinelRedisInstance,记录了服务器的信息(如它的所有从服务器,同样监视这个服务器的哨兵等)
int tilt; /* Are we in TILT mode? */
int running_scripts; /* Number of scripts in execution right now. */
mstime_t tilt_start_time; /* When TITL started. */
mstime_t previous_time; /* Last time we ran the time handler. */
list *scripts_queue; /* Queue of user scripts to execute. */
char *announce_ip; /* IP addr that is gossiped to other sentinels if
not NULL. */
int announce_port; /* Port that is gossiped to other sentinels if
non zero. */
unsigned long simfailure_flags; /* Failures simulation. */
int deny_scripts_reconfig; /* Allow SENTINEL SET ... to change script
paths at runtime? */
char *sentinel_auth_pass; /* Password to use for AUTH against other sentinel */
char *sentinel_auth_user; /* Username for ACLs AUTH against other sentinel. */
int resolve_hostnames; /* Support use of hostnames, assuming DNS is well configured. */
int announce_hostnames; /* Announce hostnames instead of IPs when we have them. */
} sentinel;
之后哨兵会建立两个连接主服务器的网络,一个用于发送命令,一个用于订阅主服务器
哨兵会一定时间向主服务器发送INFO命令,并通过回复分析主服务器状态(比如得到其从服务器)
同样哨兵也会和从服务器建立连接,并发送INFO命令
各哨兵之间也会建立命令连接
哨兵会每秒向所有建立连接的实例(主从服务器,其它哨兵)发送PING命令,来判断实例是否在线
如果判断下线了,哨兵还会向其它哨兵实例询问是否它们也认为对方下线(哨兵集群中大多数投票认定下线就下线),如果是,就要进行下线处理
当要对下线的主服务器处理时,所有哨兵要选举领导,由领导进行处理
规则:
当哨兵发现主服务器下线,就向别的哨兵发送请求投票,如果被请求的哨兵还没有投过票就投一票,如果哨兵发现收到投票超过一半,就成为领导,如果过了一段时间还没选出来,就进入下一个周期,重新请求投票
故障处理时,最新的(没有下线,最近成功通信过),复制偏移量最大的从服务器优先成为主服务器
然后让其它从服务器复制新主服务器
通知客户端主节点变更(通过订阅机制)
故障转移操作最后要做的是,继续监视旧主节点,当旧主节点重新上线时,哨兵集群就会向它发送SLAVEOF命令,让它成为新主节点的从节点
哨兵节点之间是通过Redis的发布者/订阅者机制来相互发现,建立网络连接的
集群
是redis提供的分布式数据库方案,通过分片进行数据共享
每个redis服务器在开启集群模式后,会额外保存集群下用到的数据
typedef struct clusterNode {
mstime_t ctime; //节点创建时间
char name[CLUSTER_NAMELEN]; //节点名字
char shard_id[CLUSTER_NAMELEN]; /* shard id, hex string, sha1-size */
int flags; //节点状态
uint64_t configEpoch; //节点当前轮数,用于故障恢复时选举领导
unsigned char slots[CLUSTER_SLOTS/8]; //节点负责处理哪些槽
uint16_t *slot_info_pairs; /* Slots info represented as (start/end) pair (consecutive index). */
int slot_info_pairs_count; /* Used number of slots in slot_info_pairs */
int numslots; /* Number of slots handled by this node */
int numslaves; /* Number of slave nodes, if this is a master */
struct clusterNode **slaves; /* pointers to slave nodes */
struct clusterNode *slaveof; /* pointer to the master node. Note that it
may be NULL even if the node is a slave
if we don't have the master node in our
tables. */
unsigned long long last_in_ping_gossip; /* The number of the last carried in the ping gossip section */
mstime_t ping_sent; /* Unix time we sent latest ping */
mstime_t pong_received; /* Unix time we received the pong */
mstime_t data_received; /* Unix time we received any data */
mstime_t fail_time; /* Unix time when FAIL flag was set */
mstime_t voted_time; /* Last time we voted for a slave of this master */
mstime_t repl_offset_time; /* Unix time we received offset for this node */
mstime_t orphaned_time; /* Starting time of orphaned master condition */
long long repl_offset; /* Last known repl offset for this node. */
char ip[NET_IP_STR_LEN]; /* Latest known IP address of this node */
sds hostname; /* The known hostname for this node */
int port; /* Latest known clients port (TLS or plain). */
int pport; /* Latest known clients plaintext port. Only used
if the main clients port is for TLS. */
int cport; //连接节点所需信息,包括套接字,输入输出缓冲区
clusterLink *link; /* TCP/IP link established toward this node */
clusterLink *inbound_link; /* TCP/IP link accepted from this node */
list *fail_reports; /* List of nodes signaling this as failing */
} clusterNode;
// 保存当前节点视角下,集群的状态(包括集群中所有的节点等)
typedef struct clusterState {
clusterNode *myself; /* This node */
uint64_t currentEpoch;
int state; /* CLUSTER_OK, CLUSTER_FAIL, ... */
int size; /* Num of master nodes with at least one slot */
dict *nodes; /* Hash table of name -> clusterNode structures */
dict *shards; /* Hash table of shard_id -> list (of nodes) structures */
dict *nodes_black_list; /* Nodes we don't re-add for a few seconds. */
clusterNode *migrating_slots_to[CLUSTER_SLOTS];
clusterNode *importing_slots_from[CLUSTER_SLOTS];
clusterNode *slots[CLUSTER_SLOTS];
rax *slots_to_channels;
/* The following fields are used to take the slave state on elections. */
mstime_t failover_auth_time; /* Time of previous or next election. */
int failover_auth_count; /* Number of votes received so far. */
int failover_auth_sent; /* True if we already asked for votes. */
int failover_auth_rank; /* This slave rank for current auth request. */
uint64_t failover_auth_epoch; /* Epoch of the current election. */
int cant_failover_reason; /* Why a slave is currently not able to
failover. See the CANT_FAILOVER_* macros. */
/* Manual failover state in common. */
mstime_t mf_end; /* Manual failover time limit (ms unixtime).
It is zero if there is no MF in progress. */
/* Manual failover state of master. */
clusterNode *mf_slave; /* Slave performing the manual failover. */
/* Manual failover state of slave. */
long long mf_master_offset; /* Master offset the slave needs to start MF
or -1 if still not received. */
int mf_can_start; /* If non-zero signal that the manual failover
can start requesting masters vote. */
/* The following fields are used by masters to take state on elections. */
uint64_t lastVoteEpoch; /* Epoch of the last vote granted. */
int todo_before_sleep; /* Things to do in clusterBeforeSleep(). */
/* Stats */
/* Messages received and sent by type. */
long long stats_bus_messages_sent[CLUSTERMSG_TYPE_COUNT];
long long stats_bus_messages_received[CLUSTERMSG_TYPE_COUNT];
long long stats_pfail_nodes; /* Number of nodes in PFAIL status,
excluding nodes without address. */
unsigned long long stat_cluster_links_buffer_limit_exceeded; /* Total number of cluster links freed due to exceeding buffer limit */
} clusterState;
当一个新节点要加入集群,首先两个节点先握手建立连接,集群的节点向待加入节点发送MEET,并将其结构记录在clusterState中的字典中,待加入节点收到消息,也将对方结构记录到clusterState中的字典中,并返回PONG消息,之后集群中节点返回PING,待加入节点收到消息后知道加入成功,之后这个集群中节点通过Gossip协议将信息传播给集群中其它节点
集群将数据库分为多个槽,每个键值对属于一个槽,集群中每个节点负责处理一部分槽
每个节点都会给其它节点传播自己处理哪些槽,其它节点也会记录这个信息
redis作为缓存
为了避免用户直接访问数据库,会用Redis作为缓存使用
常见的缓存更新策略?
常见的缓存更新策略共有3种:
Cache Aside(旁路缓存)策略;
Read/Write Through(读穿/写穿)策略;
Write Back(写回)策略;
实际开发中,Redis和MySQL的更新策略用的是Cache Aside。
写策略的步骤:先更新数据库中的数据,再删除缓存中的数据。
读策略的步骤:如果读取的数据命中了缓存,则直接返回数据;如果读取的数据没有命中缓存,则从数据库中读取数据,然后将数据写入到缓存,并且返回给用户。
Read/Write Through(读穿/写穿)策略原则是应用程序只和缓存交互,不再和数据库交互,而是由缓存和数据库交互,相当于更新数据库的操作由缓存自己代理了。
Read Through:先查询缓存中数据是否存在,如果存在则直接返回,如果不存在,则由缓存组件负责从数据库查询数据,并将结果写入到缓存组件,最后缓存组件将数据返回给应用。
Write Throgh:当有数据更新的时候,先查询要写入的数据在缓存中是否已经存在:
如果缓存中数据已经存在,则更新缓存中的数据,并且由缓存组件同步更新到数据库中
如果缓存中数据不存在,直接更新数据库,然后返回
Write Back(写回)策略在更新数据的时候,只更新缓存,同时将缓存数据设置为脏的,然后立马返回,并不会更新数据库。之后再通过批量异步更新的方式更新数据库(比如CPU的缓存、操作系统中文件系统的缓存)
Write Back适合写多的场景,因为发生写操作的时候,只需要更新缓存,就立马返回了。但是一旦缓存机器掉电,就会造成原本缓存中的脏数据丢失
缓存雪崩
当大量缓存数据在同一时间过期(失效)或者Redis故障宕机时,如果此时有大量的用户请求,都无法在Redis中处理,于是全部请求都直接访问数据库,从而导致数据库的压力骤增,严重的会造成数据库宕机
应对方法有下面这几种:
均匀设置过期时间:设置过期时间再加一个随机数
互斥锁:当无法命中缓存时,由一个请求构建缓存,其它请求等待,完成后,其它请求可以使用缓存
双key策略:一个有过期时间,一个备份key无过期时间
后台更新缓存;
业务线程不再负责更新缓存,缓存也不设置有效期,而是让缓存“永久有效”,并将更新缓存的工作交由后台线程定时更新
缓存击穿
通常会有几个数据会被频繁地访问,比如秒杀活动,这类被频地访问的数据被称为热点数据。
如果缓存中的某个热点数据过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮
解决:
互斥锁
后台更新缓存
缓存穿透
当用户访问的数据,既不在缓存中,也不在数据库中,导致请求在访问缓存时,发现缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据,没办法构建缓存数据,当有大量这样的请求到来时,数据库的压力骤增
缓存穿透的发生一般有这两种情况:
业务误操作,缓存中的数据和数据库中的数据都被误删除了,所以导致缓存和数据库中都没有数据;
黑客恶意攻击,故意大量访问某些读取不存在数据的业务;
解决
第一种方案,非法请求的限制
第二种方案,对于该查询缓存空值或默认值
第三种方案,使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在
保证缓存与数据库一致性
先更新数据库再更新缓存:并发AB时有问题,更新数据库是A先后B,更新缓存是B先后A
先更新缓存再更新数据库:同样
针对以上可以:在更新缓存前先加个分布式锁,保证同一时间只运行一个请求更新缓存
先删除缓存再更新数据库:并发读写有问题,A写先删除缓存,B读又更新缓存,A再写数据库
先更新数据库再更新缓存:同样读写有问题,但问题不大。B读未命中,从数据库读到值,A写数据库,再删除缓存,B将读到的值写入缓存
在删除缓存(第二个操作)的时候失败了,导致缓存还是旧值,而数据库是最新值,造成数据库和缓存数据不一致的问题
两种方法:
重试机制。
订阅MySQL的binlog,再操作缓存。
redis应用
延迟消息队列
使用有序集合(ZSet)的方式来实现延迟消息队列,ZSet有一个Score属性可以用来存储延迟执行的时间。在淘宝、京东等购物平台上下单,超过一定时间未付款,订单会自动取消
大key会带来以下四种影响:
客户端超时阻塞。由于Redis执行命令是单线程处理,然后在操作大key时会比较耗时,那么就会阻塞Redis,从客户端这一视角看,就是很久很久都没有响应。
引发网络阻塞。每次获取大key产生的网络流量较大,如果一个key的大小是1 MB,每秒访问量为1000,那么每秒会产生1000MB的流量
阻塞工作线程。如果使用del删除大key时,会阻塞工作线程,这样就没办法处理后续的命令。
内存分布不均。集群模型在slot分片均匀情况下,会出现数据和查询倾斜情况,部分有大 key的Redis节点占用内存多,QPS也会比较大
分布式锁
Redis的SET命令有个NX参数可以实现key不存在才插入,所以可以用它来实现分布式锁:
如果key不存在,则显示插入成功,可以用来表示加锁成功;
如果key存在,则会显示插入失败,可以用来表示加锁失败。
基于Redis节点实现分布式锁时,对于加锁操作,需要满足三个条件。
加锁包括了读取锁变量、检查锁变量值和设置锁变量值三个操作,但需要以原子操作的方式完成,所以,我们使用SET命令带上NX选项来实现加锁;
锁变量需要设置过期时间,以免客户端拿到锁后发生异常,导致锁一直无法释放,所以,我们在SET命令执行时加上EX/PX选项,设置其过期时间;
锁变量的值需要能区分来自不同客户端的加锁操作,以免在释放锁时,出现误释放操作,所以,我们使用SET命令设置锁变量值时,每个客户端设置的值是一个唯一值,用于标识客户端;
满足这三个条件的分布式命令如下:
SET lock_key unique_value NX PX 10000
lock_key就是key键;
unique_value 是客户端生成的唯一的标识,区分来自不同客户端的锁操作;
NX代表只在lock_key不存在时,才对lock_key进行设置操作;
PX 10000表示设置lock_key的过期时间为10s,这是为了避免客户端发生异常而无法释放锁。
而解锁的过程就是将lock_key键删除,但不能乱删,要保证执行操作的客户端就是加锁的客户端。所以,解锁的时候,我们要先判断锁的unique_value是否为加锁客户端,是的话,才将lock_key键删除
基于Redis实现分布式锁的优点:
性能高效
实现方便
避免单点故障(因为Redis是跨集群部署的,自然就避免了单点故障)。
基于Redis 实现分布式锁的缺点:
超时时间不好设置。如果锁的超时时间设置过长,会影响性能,如果设置的超时时间过短会保护不到共享资源。
Redis主从复制模式中的数据是异步复制的,这样导致分布式锁的不可靠性。如果在Redis主节点获取到锁后,在没有同步到其他节点时,Redis主节点宕机了,此时新的Redis主节点依然可以获取锁,所以多个应用服务就可以同时获取到锁。
Redis 如何解决集群情况下分布式锁的可靠性?
为了保证集群环境下分布式锁的可靠性,Redis官方已经设计了一个分布式锁算法Redlock
Redlock算法的基本思路,是让客户端和多个独立的Redis节点依次请求申请加锁,如果客户端能够和半数以上的节点成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁,否则加锁失败。
如果有超过半数的Redis节点成功的获取到了锁,并且总耗时没有超过锁的有效时间,那么就是加锁成功

 浙公网安备 33010602011771号
浙公网安备 33010602011771号