
5. 决策树算法原理以及ID3算法代码实现
完整的实验代码在我的github上👉QYHcrossover/ML-numpy: 机器学习算法numpy实现 (github.com) 欢迎star⭐
决策树算法是一种经典的机器学习算法,它在许多领域都有广泛的应用。决策树模型通过树形结构来表示不同的决策路径,每个节点代表一个特征变量,每个分支代表一个可能的取值。决策树模型是一种可解释性强的模型,它不仅可以用于分类问题,还可以用于回归问题。本文将介绍决策树算法的原理,并通过实例演示如何使用ID3算法构建决策树模型。
决策树算法原理
决策树是一种常用的分类和回归算法,其原理是通过不断地选择最佳分裂特征和阈值来构建一棵树形结构,从而对数据进行分类或预测。决策树的构建过程类似于一个问题的“筛选”过程,通过不断地提出问题和根据问题的答案将样本分割成不同的子集,最终将样本分到相应的类别或预测出其对应的数值。
决策树的构建是一个自上而下的递归过程,具体来说,它包含以下几个步骤:
- 特征选择:选择最优的特征作为当前节点的划分属性,使得划分后的各个子节点尽可能地“纯净”。
- 节点划分:按照选定的特征将当前节点的样本集划分为多个子节点,每个子节点对应于选定特征的不同取值。
- 递归构建:对每个子节点递归地执行上述步骤,直到满足终止条件,如节点中的样本数小于预定阈值,节点中的样本属于同一类别等。
决策树算法的原理其实就是不断地对特征进行选择和节点的划分,最终生成一个决策树模型,用于对新的样本进行分类或回归。
ID3算法是决策树算法中的一种,它基于信息增益来选择特征。信息增益的概念是在信息论中提出的,它表示在已知一个事件发生的前提下,该事件所提供的信息量。ID3算法通过计算每个特征的信息增益来选择分裂特征。这种方法的缺点是它倾向于选择取值数目较多的特征作为分裂特征,因此它的决策树往往比较深,容易出现过拟合的问题。ID3算法的信息增益计算公式为:
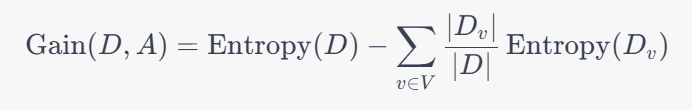
C4.5算法是ID3算法的改进版,它引入了增益率的概念,即用特征的信息增益比来选择分裂特征。增益率解决了ID3算法中倾向选择取值数目较多的特征的问题,因此它生成的决策树通常比ID3算法的决策树要浅,泛化性能也更好。此外,C4.5算法还可以处理缺失值和连续特征,它使用一种叫做“二分法”的方法将连续特征离散化,然后再按照离散化后的取值进行划分。C4.5算法的增益率计算公式为:
其中,$\operatorname{SplitInfo}(D, A)$为特征$A$的分裂信息,表示对数据集$D$进行特征$A$划分的难易程度。$\operatorname{SplitInfo}(D, A)$越大,表示特征$A$的分裂能力越弱。
ID3代码实践
from sklearn.model_selection import train_test_split
import numpy as np
from collections import Counter
class ID3DecisionTree:
@staticmethod
def entropy(y):
precs = np.array(list(Counter(y).values()))/len(y)
ent = np.sum(-1 * precs * np.log(precs))
return ent
def decide_feature(self,X,y,feature_order):
n_features = X.shape[-1]
ents = (feature_order != -1).astype(np.float64)
for i in range(n_features):
if feature_order[i] >= 0:
continue
for feature,size in Counter(X[:,i]).items():
index = (X[:,i] == feature)
splity = y[index]
ent = ID3DecisionTree.entropy(splity)
ents[i] += ent*size/len(X)
fi = np.argmin(ents)
return fi,ents[fi]
def fit(self,X,y):
feature_order = -1 * np.ones(X.shape[-1])
self.tree = self.build_tree(X,y,feature_order)
首先,ID3DecisionTree类中的entropy方法用于计算熵(entropy),也就是信息熵(information entropy)。
entropy(y)方法接受一个一维数组y作为参数,数组中每个元素代表一个样本的类别。它首先通过Counter(y)方法获取y数组中每个类别出现的次数,然后计算每个类别出现的概率,最后根据熵的公式计算并返回熵。
decide_feature(self, X, y, feature_order)方法用于选择当前最佳的特征,也就是决定在哪个特征上进行分类。该方法接受三个参数:
X:训练集特征;y:训练集标签;feature_order:已经选择过的特征。
decide_feature方法首先获取训练集X中的特征数,并初始化一个数组ents,数组的长度等于X中特征的个数。数组ents中的每个元素都初始化为0,代表每个特征对应的信息熵。
然后对于每个特征i,遍历该特征所有可能的取值,统计在该特征取值下,训练集中的样本数,然后按照该特征取值对训练集进行划分,计算该划分的信息熵,并将信息熵加权后加入ents[i]中。
最后,找到所有特征中信息熵最小的特征fi,返回该特征的索引fi和信息熵ents[fi]。
接下来是build_tree方法,该方法的作用是递归地构建决策树。首先计算当前数据集的熵(即curent变量),如果所有样本的类别都相同或者所有特征都已经被使用过,那么就停止递归,返回一个字典,其中counts表示各个类别的数量,result表示预测结果。否则,选择信息增益最大的特征进行划分,并将该特征从可用特征列表中移除,然后递归地构建每个分支,最终返回一个字典,其中feature表示划分特征的索引,entgain表示信息增益,counts表示各个类别的数量,result表示预测结果,next是一个字典,表示各个分支对应的子树。
def build_tree(self,X,y,feature_order):
curent = ID3DecisionTree.entropy(y)
counts = dict(Counter(y))
if len(counts) == 1 or min(feature_order) == 0:
result = max(counts,key=counts.get)
return {"counts":counts,"result":result}
fi,ent = self.decide_feature(X,y,feature_order)
feature_order[fi] = max(feature_order)+1
result = None
next_ = {}
for value,_ in Counter(X[:,fi]).items():
next_[value] = self.build_tree(X[X[:,fi]==value],y[X[:,fi]==value],feature_order)
return {"feature":fi,"entgain":curent-ent,"counts":counts,"result":result,"next":next_}
最后是predict方法,该方法的作用是使用已经构建好的决策树对测试集进行预测。对于每个测试样本,从根节点开始遍历决策树,直到遇到叶子节点为止,叶子节点的result字段就是预测结果。将所有测试样本的预测结果存储在列表y中,最终返回该列表。
def predict(self,X):
y = []
for i in range(len(X)):
x_test = X[i]
tree = self.tree
while tree["result"] == None:
feature = tree["feature"]
nexttree = tree["next"][x_test[feature]]
tree = nexttree
y.append(tree["result"])
return y
最后,在main函数中,我们使用create_data函数生成一个人工数据集,然后将其随机分成训练集和测试集,调用ID3DecisionTree类的fit方法进行训练,然后输出构建好的决策树和在测试集上的预测结果。
if __name__ == "__main__":
def create_data():
datasets = [['青年', '否', '否', '一般', '否'],
['青年', '否', '否', '好', '否'],
['青年', '是', '否', '好', '是'],
['青年', '是', '是', '一般', '是'],
['青年', '否', '否', '一般', '否'],
['中年', '否', '否', '一般', '否'],
['中年', '否', '否', '好', '否'],
['中年', '是', '是', '好', '是'],
['中年', '否', '是', '非常好', '是'],
['中年', '否', '是', '非常好', '是'],
['老年', '否', '是', '非常好', '是'],
['老年', '否', '是', '好', '是'],
['老年', '是', '否', '好', '是'],
['老年', '是', '否', '非常好', '是'],
['老年', '否', '否', '一般', '否'],
]
labels = [u'年龄', u'有工作', u'有自己的房子', u'信贷情况', u'类别']
# 返回数据集和每个维度的名称
return datasets, labels
dataset,columns = create_data()
X,y = np.array(dataset)[:,:-1],np.array(dataset)[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=1)
dt = ID3DecisionTree()
dt.fit(X_train,y_train)
print(dt.tree)
print(dt.predict(X_test))
总结
本篇博客主要介绍了决策树算法原理和ID3算法的代码实践。决策树是一种常用的分类算法,通过对特征的判断和分类来实现对目标的预测。决策树算法的核心思想是通过对数据进行分割来最小化熵或信息增益等指标,从而达到对数据的分类。而ID3算法是基于信息增益进行特征选择的决策树算法,它通过计算每个特征的信息增益来选择最优的特征进行切分,构建决策树模型。本篇博客使用Python实现了ID3算法,并通过一个小数据集的分类任务进行了演示,展示了算法的具体实现过程。
下一篇博客将介绍CART算法的原理和代码实现。CART算法是一种二叉树决策树算法,可以用于分类和回归任务。相较于ID3算法,CART算法采用的是基尼系数来进行特征选择,通过构建二叉决策树来实现对数据的分类。本篇博客将会介绍CART算法的核心思想、算法流程以及Python代码实现,以便读者更好地理解和掌握决策树算法。
完整的实验代码在我的github上👉QYHcrossover/ML-numpy: 机器学习算法numpy实现 (github.com) 欢迎star⭐
