
数据结构图文解析之:哈夫曼树与哈夫曼编码详解及C++模板实现
0. 数据结构图文解析系列
1. 哈夫曼编码简介
哈夫曼编码(Huffman Coding)是一种编码方式,也称为“赫夫曼编码”,是David A. Huffman1952年发明的一种构建极小多余编码的方法。
在计算机数据处理中,霍夫曼编码使用变长编码表对源符号进行编码,出现频率较高的源符号采用较短的编码,出现频率较低的符号采用较长的编码,使编码之后的字符串字符串的平均长度 、期望值降低,以达到无损压缩数据的目的。
举个例子,现在我们有一字符串:
this is an example of a huffman tree
这串字符串有36个字符,如果按普通方式存储这串字符串,每个字符占据1个字节,则共需要36 * 1 * 8 = 288bit。
经过分析我们发现,这串字符串中各字母出现的频率不同,如果我们能够按如下编码:
| 字母 | 频率 | 编码 | --- | 字母 | 频率 | 编码 |
|---|---|---|---|---|---|---|
| space | 7 | 111 | s | 2 | 1011 | |
| a | 4 | 010 | t | 2 | 0110 | |
| e | 4 | 000 | l | 1 | 11001 | |
| f | 3 | 1101 | o | 1 | 00110 | |
| h | 2 | 1010 | p | 1 | 10011 | |
| i | 2 | 1000 | r | 1 | 11000 | |
| m | 2 | 0111 | u | 1 | 00111 | |
| n | 2 | 0010 | x | 1 | 10010 |
编码这串字符串,只需要:
(7+4+4)x3 + (3+2+2+2+2+2+2)x4 + (1+1+1+1+1+1)x 5 = 45+60+30 = 135bit
编码这串字符串只需要135bit!单单这串字符串,就压缩了288-135 = 153bit。
那么,我们如何获取每个字符串的编码呢?这就需要哈夫曼树了。
源字符编码的长短取决于其出现的频率,我们把源字符出现的频率定义为该字符的权值。
2. 哈夫曼树简介
哈夫曼又称最优二叉树。是一种带权路径长度最短的二叉树。它的定义如下。
哈夫曼树的定义
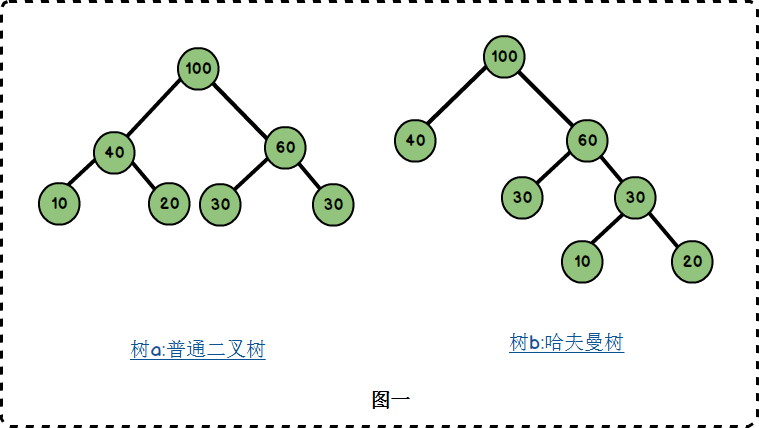
假设有n个权值{w1,w2,w3,w4...,wn},构造一棵有n个节点的二叉树,若树的带权路径最小,则这颗树称作哈夫曼树。这里面涉及到几个概念,我们由一棵哈夫曼树来解释
-
路径与路径长度:从树中一个节点到另一个节点之间的分支构成了两个节点之间的路径,路径上的分支数目称作路径长度。若规定根节点位于第一层,则根节点到第H层的节点的路径长度为H-1.如树b:100到60 的路径长度为1;100到30的路径长度为2;100到20的路径长度为3。
-
树的路径长度:从根节点到每一节点的路径长度之和。树a的路径长度为1+1+2+2+2+2 = 10;树b的路径长度为1+1+2+2+3+3 = 12.
-
节点的权:将树中的节点赋予一个某种含义的数值作为该节点的权值,该值称为节点的权;
-
带权路径长度:从根节点到某个节点之间的路径长度与该节点的权的乘积。例如树b中,节点10的路径长度为3,它的带权路径长度为10 * 3 = 30;
-
树的带权路径长度:树的带权路径长度为所有叶子节点的带权路径长度之和,称为WPL。树a的WPL = 2*(10+20+30+40) = 200 ;树b的WPL = 1x40+2x30+3x10+3x20 = 190.而哈夫曼树就是树的带权路径最小的二叉树。
3. 构造哈夫曼树
3.1 哈夫曼树的节点结构
/*哈夫曼树的节点定义*/
template <typename T>
struct HuffmanNode
{
HuffmanNode(T k,HuffmanNode<T>*l=nullptr,HuffmanNode<T>* r=nullptr)
:key(k),lchild(l), rchild(r){}
~HuffmanNode(){};
T key; //节点的权值
HuffmanNode<T>* lchild; //节点左孩
HuffmanNode<T>* rchild; //节点右孩
};
- value: 节点的权值
- lchild:节点左孩子
- rchild:节点右孩子
3.2 哈夫曼树的抽象数据类型
template <typename T>
class Huffman
{
public:
void preOrder(); //前序遍历哈夫曼树
void inOrder(); //中序遍历哈夫曼树
void postOrder(); //后序遍历哈夫曼树
void creat(T a[], int size); //创建哈夫曼树
void destory(); //销毁哈夫曼树
void print(); //打印哈夫曼树
Huffman();
~Huffman(){};
private:
void preOrder(HuffmanNode<T>* pnode);
void inOrder(HuffmanNode<T>* pnode);
void postOrder(HuffmanNode<T>*pnode);
void print(HuffmanNode<T>*pnode);
void destroy(HuffmanNode<T>*pnode);
private:
HuffmanNode<T>* root; //哈夫曼树根节点
deque<HuffmanNode<T>*> forest;//森林
};
- root:哈夫曼树的根结点。
- forset : 森林,这里使用deque来存储森林中树的根节点。
3.3 哈夫曼树的构造步骤
假设有n个权值,则构造出的哈夫曼树有n个叶子节点.n个权值记为{w1,w2,w3...wn},哈夫曼树的构造过程为:
- 将w1,w2,w3...wn看成具有n棵树的森林,每棵树仅有一个节点。
- 从森林中,选取两棵根节点权值最小的树,两棵树分别作为左子树与右子树,构建一棵新树。新树的权值等于左右子树权值之和。
- 从森林中删除两棵权值最小的树,将构建完成后的新树加入森林中。
- 重复2、3步骤,直到森林只剩一棵树为止。这棵树便是哈夫曼树。
图一的树b为一棵哈夫曼树,它的叶子节点为{10,20,30,40},以这4个权值构建树b的过程为:

这个过程很编码实现为:
/*创建哈夫曼树*/
template<typename T>
void Huffman<T>::creat(T a[],int size)
{
for (int i = 0; i < size; i++) //每个节点都作为一个森林
{
//为初始序列的元素构建节点。每个节点作为一棵树加入森林中。
HuffmanNode<T>* ptr = new HuffmanNode<T>(a[i],nullptr,nullptr);
forest.push_back(ptr);
}
for (int i = 0; i < size - 1; i++)
{
//排序,以选出根节点权值最小两棵树
sort(forest.begin(), forest.end(), [](HuffmanNode<T>* a, HuffmanNode<T>*b){return a->key< b->key; });
HuffmanNode<T>*node = new HuffmanNode<T>(forest[0]->key + forest[1]->key, forest[0], forest[1]); //构建新节点
forest.push_back(node); //新节点加入森林中
forest.pop_front(); //删除两棵权值最小的树
forest.pop_front();
}
root = forest.front();
forest.clear();
};
- 这里仅仅示范构建哈夫曼树的过程,没有经过性能上的优化和完善的异常处理。这里使用deque双端队列来存储森林中树根节点,使用库函数sort来对根节点依权值排序。这里也可以使用我们之前介绍的小顶堆来完成工作。
3.4 哈夫曼树的其他操作
其他操作在前几篇博文中都有介绍过,这里就不再啰嗦,可以在文章底部链接取得完整的工程源码。
这里贴出测试时需要的代码:
/*打印哈夫曼树*/
template<typename T>
void Huffman<T>::print(HuffmanNode<T>* pnode)
{
if (pnode != nullptr)
{
cout << "当前结点:" << pnode->key<<".";
if (pnode->lchild != nullptr)
cout << "它的左孩子节点为:" << pnode->lchild->key << ".";
else cout << "它没有左孩子.";
if (pnode->rchild != nullptr)
cout << "它的右孩子节点为:" << pnode->rchild->key << ".";
else cout << "它没有右孩子.";
cout << endl;
print(pnode->lchild);
print(pnode->rchild);
}
};
3.5 哈夫曼树代码测试
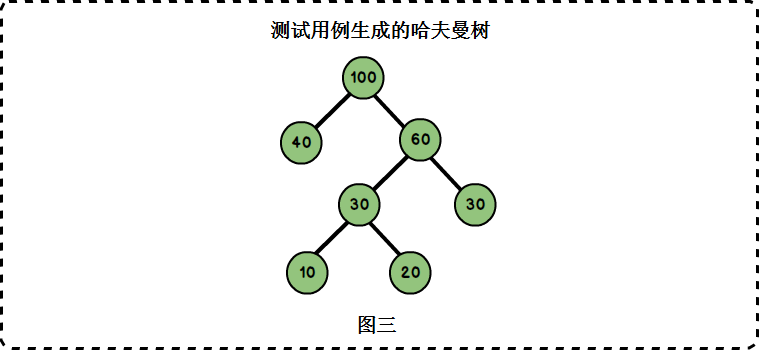
我们构建上图中的哈夫曼树,它的四个权值分别为{10,20,30,40}:
测试代码:
int _tmain(int argc, _TCHAR* argv[])
{
Huffman<int> huff;
int a[] = { 10,20,30,40 };
huff.creat(a, 4); //构建一棵哈夫曼树
huff.print(); //打印节点间关系
getchar();
return 0;
}
测试结果:
当前结点:100.它的左孩子节点为:40.它的右孩子节点为:60.
当前结点:40.它没有左孩子.它没有右孩子.
当前结点:60.它的左孩子节点为:30.它的右孩子节点为:30.
当前结点:30.它没有左孩子.它没有右孩子.
当前结点:30.它的左孩子节点为:10.它的右孩子节点为:20.
当前结点:10.它没有左孩子.它没有右孩子.
当前结点:20.它没有左孩子.它没有右孩子.
根据节点关系可以画出如下二叉树,正是上面我们构建的哈夫曼树。
4. 再看哈夫曼编码
为{10,20,30,40}这四个权值构建了哈夫曼编码后,我们可以由如下规则获得它们的哈夫曼编码:
- 从根节点到每一个叶子节点的路径上,左分支记为0,右分支记为1,将这些0与1连起来即为叶子节点的哈夫曼编码。如下图:
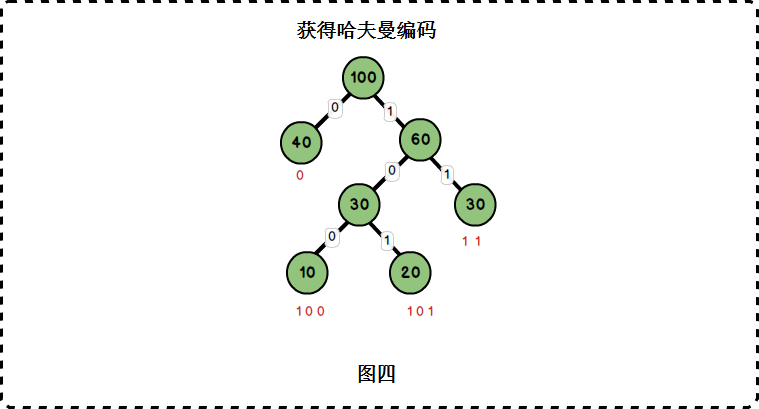
| (字母)权值 | 编码 |
|---|---|
| 10 | 100 |
| 20 | 101 |
| 30 | 11 |
| 40 | 0 |
由此可见,出现频率越高的字母(也即权值越大),其编码越短。这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
5. 哈夫曼树完整代码
哈夫曼树完整代码:https://github.com/huanzheWu/Data-Structure/blob/master/Huffman/Huffman/Huffman.h
更多数据结构C++实现代码:https://github.com/huanzheWu/Data-Structure
原创文章,转载请注明出处:http://www.cnblogs.com/QG-whz/p/5175485.html
作者:melonstreet
出处:https://www.cnblogs.com/QG-whz/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

