
!!!Ubuntu下相关命令!!!
!!利用GPU跑代码涉及的命令行指令!!
进入子路径:cd 子路径名 回车
返回至根目录 cd ..回车
查看实验室的GPU占用情况:nvidia-smi
谁在占用GPU:who
动态显示谁在输入什么命令之类的:top
杀死进程:先用nvidia-smi显示正在使用情况 PID,然后杀死进程,kill -9 PID号。
#进入虚拟环境
处于rootPath:who -Z270-HD3:~$
从rootPath进入virtualEnvi:who -Z270-HD3:~$ source activate tensorflow
处于virtualEnvi:(tensorflow) who-Z270-HD3:~$
#查找本机IP:ip addr
#当前文件夹下的内容列表(list)
input:(tensorflow) who-Z270-HD3:~/miniconda3$ ls
output:
bin envs lib share
compiler_compat etc LICENSE.txt ssl
conda-meta include pkgs x86_64-conda_cos6-linux-gnu
Ps:“ll”等价于“ls -l”它是输出该文件夹下的详细内容。
#某个文件夹的位置:find -name 文件夹名(eg:torch)
!!软件安装!!
#sudo的含义:
sudo是superuser do的简写,其含义是以超级用户的权限运行,普通用户无法执行许多命令,比如说安装程序。
#Ubuntu下apt-get install安装与pip install安装的区别
ddd:pip安装 the package of python,apt-get用于安装 the package of system(系统的包)。
#ubuntu安装解压rar文件:
solution:sudo apt-get install unrar
#ubuntu自带截图工具screenshot及快捷键的设置
https://blog.csdn.net/qq_38880380/article/details/78233687
#python安装在哪儿?查找可执行文件的安装位置
input:(tensorflow) who-Z270-HD3:~/miniconda3/envs$ which python
output:/home/who/.conda/envs/tensorflow/bin/python
#ubuntu下装teamviewer
https://blog.csdn.net/manjianchao/article/details/78566029
1. 查看Ubuntu的是64还是32位:sudo uname –m(返回值为x86_64就是64位系统的),然后在teamviewer官网下载Ubuntu的安装包:teamviewer_11.0.xxxxx_i386.deb。
2. 在安装包所在的文件夹下执行安装命令:sudo dpkg -i teamviewer_11.0.xxxxx_i386.deb,可能会报错缺少依赖包的安装,如下图所示:
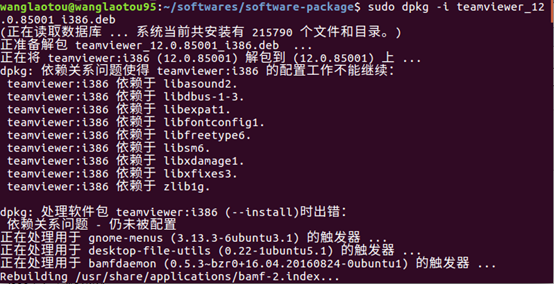
然后执行:sudo apt-get install –f (–”是2根“-”)
再次执行命令:sudo dpkg -i teamviewer_11.0.xxxxx_i386.deb
3. 接受license。在computer/opts/路径下找到teamviewer文件夹,文件夹中内容如下所示。标黄部分即为可执行文件,双击,在弹出来的对话框中“接受license”。

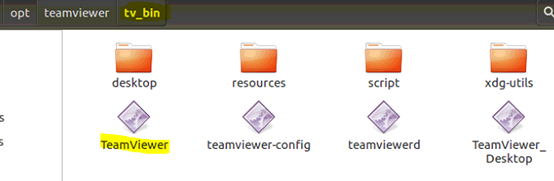
4. 执行命令停止服务:sudo teamviewer --daemon stop
5. 修改配置文件。
(1)别人的方法
进入子路径:cd /opt/teamviewer/config/
查看当前路径下内容列表:ll(2个小写的“L”)
文本编辑器查看:sudo vim global.conf
在末尾添加如下内容,然后保存退出,命令“wq”
[int32] EulaAccepted = 1
[int32] EulaAcceptedRevision = 6
查看修改后的文件:cat global.conf
(2)我的方法:深入路径,对global.conf内容进行添加。
找到 ,在终端中输入:sudo nautilus global.conf,以管理员权限打开文件,添加相应内容至末尾,保存退出。
,在终端中输入:sudo nautilus global.conf,以管理员权限打开文件,添加相应内容至末尾,保存退出。
若结合网址(https://blog.csdn.net/williamfan21c/article/details/56495261)对vim的相关命令进行理解后还是会使用方法(1)了。
6. 启动teamviewer:sudo teamviewer --daemon start
7. 然后再打开teamviewer的UI,就有ID和密码了,无人值守的密码设置见“optionsàsecurity”
若按照流程走下来没错就好,若UI中出现的“connection错误”,我尝试了sudo dpkg -i teamviewer_11.0.xxxxx_i386.deb命令再次进行安装,反复几次就安装成功了。
#ubuntu下VScode的安装
下载安装包后执行命令sudo dpkg -i code_1.19.2-1515599945_amd64.deb,就可以在菜单栏看到VScode这个软件了。使用命令“code”,就像打开matlab一样也能打开VScode。
!!!Windows下分割数据集标注软件labelme的安装与使用!!!
1. 语义分割标记数据的软件labelme:https://github.com/wkentaro/labelme
2. NotWritableError: The current user does not have write permissions to a required path。https://blog.csdn.net/qq_29680341/article/details/82917703
3. 安装的命令行指令:
conda create --name=labelme python=3.6
conda activate labelme
pip install pyqt5
pip install labelme
4. 如何使用labelme软件?
以管理员方式打开Anaoconda Prompt
输入:conda activate labelme
输入:labelme 打开软件
在UI界面完成标记,输出.json文件后,尝试将其转化为label.png。操作如下所示:
命令行指令:labelme_json_to_dataset input_json_name –o output_path
eg:input_json_name = “E:/imgsForLabel/pic1.json”
output_path = “E:/imgsForLabel/pic1_json”
输出:Saved to: F:/labelme-master/labelme/cli/pic1_json
PS:除此之外还有https://github.com/abreheret/PixelAnnotationTool,有.exe可直接使用;使用watershed marked算法,在前景和背景上分别做少许标记,就能完成分割,较智能化。但是感觉该软件一言不合就崩掉。
!!!运行代码报的错及解决方法!!!
#训练时
ImportError:No module named cv2
解决方法:pip install opencv-python
#测试时:
ModuleNotFoundError: No module named 'tqdm'
解决方法:pip install tqdm
!!!python的相关命令!!!
1. 查看已安装的包及版本: pip list
2. python 包的安装、卸载、升级等:https://www.cnblogs.com/wangzhao2016/p/6564362.html,重点涉及一次性在线安装多个包:pip install -r requirements.txt

3. visdom用于画图。
!!!pytorch的相关知识点!!!
1. 查看变量类型:(黄色内容为输入)

2. 数据类型转换:int(x),float(x)…https://www.cnblogs.com/paranoia/p/6164547.html
3. numpy中array数据的.size = 各个通道数的乘积,shape才是各个通道数的大小。
4. 输出log文件时报错,学习byte与str之间的转换:https://blog.csdn.net/bible_reader/article/details/53047550
5. TypeError: split() got an unexpected keyword argument 'split_size'。
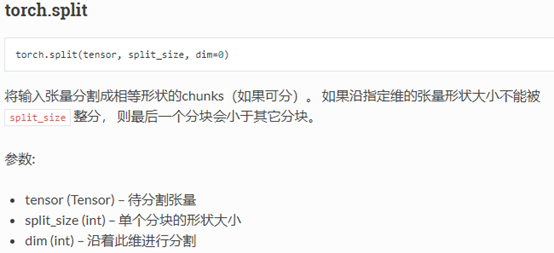
之后将’split_size’这个参数去掉之后,报错:TypeError: split() missing 1 required positional argument: 'split_size_or_sections',于是将'split_size'更改为'split_size_or_sections'问题就解决了。
6. AttributeError: 'dict' object has no attribute 'has_key'

7. 代码过长的换行:python代码换行就是每行后面加个 “\”。
8. permute:
9. contiguous():https://blog.csdn.net/appleml/article/details/80143212
10. a = torch.rand(1, 2, 3, 4) #即torch.Size(1, 2, 3, 4)。为什么a[:, 0]是一个torch.Size(1, 3, 4)的tensor?A:索引在哪个维度上就略掉该维度,输出其他维度上的所有内容。

11. unsqueeze:tensor维度的增加。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号