pandas 写Excel 追加同一sheet内容,而不覆盖原数据(分别对应数据量小与数据量大)
最近在工作的时候需要追加写Excel,但是在百度上搜的都不是pandas 最新的版本,都是旧版本,官网给的列子也骗我,只好自己去读源码,找原因,今天把这个记录下来,省着以后再忘。
Python版本:3.9
pandas版本:1.3.0
首先呢,创造一下数据:
from pandas import ExcelWriter import pandas as pd df = pd.DataFrame([i for i in range(1, 10)]) with ExcelWriter("path_to_file.xlsx", mode="w", engine="openpyxl") as writer: df.to_excel(writer, sheet_name="Sheet31", index_label="数据")
得到的样本数据为:

得到如图所示的数据
然后我们进行追加操作:
with ExcelWriter("path_to_file.xlsx", mode="a", engine="openpyxl") as writer: writer.if_sheet_exists = "replace" # 在此版本的pandas 中,加入的这个属性,他有三个值:now , replace, error 这三个属性分别对应着:创建新的sheet,替换当前sheet里面的内容,当存在sheet 时,抛出异常 df1 = pd.read_excel("path_to_file.xlsx", index_col="数据") # 由于没有找到好的方法,所以我们读出之前文件的内容 f = [df1, df] result = pd.concat(f, axis=0) # 将两个文件concat,也就是合并 result.to_excel(writer, sheet_name="Sheet31", index_label="数据") # 保存 注意:index_label必须要和上面的index_col相同,不然下次读文件的时候会出index_col不存在的错误
参考图片
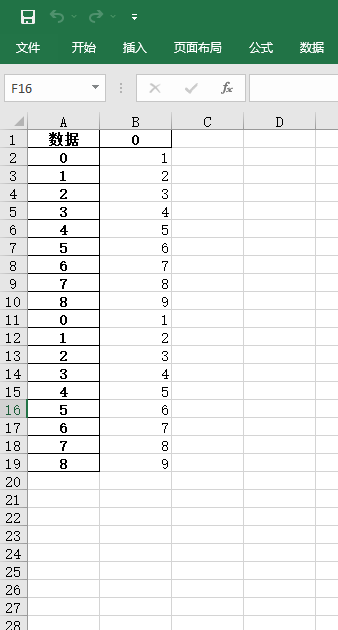
以上仅适用于当你追加的数据量小的时候,当我们数据量足够大的时候,你就不能统一进行加载。我们使用以下方式进行追加。
file_path = f"softnova/down_files/{file_name}.xlsx" startrow = 1 with pd.ExcelWriter(file_path, engine="openpyxl") as writer: for i, chunk in enumerate(pd.read_sql_query(stmt, db.engine, chunksize=5)): if i == 0: chunk.to_excel(writer, index=False, sheet_name="sheet1") header = None else: chunk.to_excel(writer, header=header, index=False, startrow=startrow, sheet_name="sheet1") startrow += chunk.shape[0]
复制时代码格式出现了小问题,可以自己格式化一下代码。
我们创建出文件,使用excelwriter创建文件后,每次写入都向文件的最后一行进行写入,而不是从首行写入,追加的原理就是向最后一行写入,我们自己实现追加即可。
致辞,敬礼!博客园原创,引用请贴出原文链接。感谢支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号