
Django基础mysql多表操作
一 创建模型
表和表之间的关系
一对一、多对一、多对多 ,用book表和publish表自己来想想关系,想想里面的操作,加外键约束和不加外键约束的区别,一对一的外键约束是在一对多的约束上加上唯一约束。
实例:我们来假定下面这些概念,字段和关系
作者模型:一个作者有姓名和年龄。
作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息。作者详情模型和作者模型之间是一对一的关系(one-to-one)
出版商模型:出版商有名称,所在城市以及email。
书籍模型: 书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many);一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many)。
模型建立如下:
from django.db import models # Create your models here. class Author(models.Model): #比较常用的信息放到这个表里面 nid = models.AutoField(primary_key=True) name=models.CharField( max_length=32) age=models.IntegerField() # 与AuthorDetail建立一对一的关系,一对一的这个关系字段写在两个表的任意一个表里面都可以 authorDetail=models.OneToOneField(to="AuthorDetail",to_field="nid",on_delete=models.CASCADE) #就是foreignkey+unique,只不过不需要我们自己来写参数了,并且orm会自动帮你给这个字段名字拼上一个_id,数据库中字段名称为authorDetail_id。在django 1.xx的版本不需要加(to_field="nid",on_delete=models.CASCADE)默认是级联的 ,如果on_delete=models.SET_NULL默认为空。(to="AuthorDetail")要加字符串(引号用反射查找) class AuthorDetail(models.Model):#不常用的放到这个表里面 nid = models.AutoField(primary_key=True) birthday=models.DateField() # telephone=models.BigIntegerField() telephone=models.CharField() addr=models.CharField( max_length=64) class Publish(models.Model): nid = models.AutoField(primary_key=True) name=models.CharField( max_length=32) city=models.CharField( max_length=32) email=models.EmailField() #CharField--xx@xx.com #多对多的表关系,我们学mysql的时候是怎么建立的,是不是手动创建一个第三张表,然后写上两个字段,每个字段外键关联到另外两张多对多关系的表,orm的manytomany自动帮我们创建第三张表,两种方式建立关系都可以,以后的学习我们暂时用orm自动创建的第三张表,因为手动创建的第三张表我们进行orm操作的时候,很多关于多对多关系的表之间的orm语句方法无法使用 #如果你想删除某张表,你只需要将这个表注销掉,然后执行那两个数据库同步指令就可以了,自动就删除了。 class Book(models.Model): nid = models.AutoField(primary_key=True) title = models.CharField( max_length=32) publishDate=models.DateField() price=models.DecimalField(max_digits=5,decimal_places=2) # 与Publish建立一对多的关系,外键字段建立在多的一方,字段publish如果是外键字段,那么它自动是int类型 publish=models.ForeignKey(to="Publish",to_field="nid",on_delete=models.CASCADE) #foreignkey里面可以加很多的参数,都是需要咱们学习的,慢慢来,to指向表,to_field指向你关联的字段,不写这个,默认会自动关联主键字段,on_delete级联删除 字段名称不需要写成publish_id,orm在翻译foreignkey的时候会自动给你这个字段拼上一个_id,这个字段名称在数据库里面就自动变成了publish_id # 与Author表建立多对多的关系,ManyToManyField可以建在两个模型中的任意一个,自动创建第三张表,并且注意一点,你查看book表的时候,你看不到这个字段,因为这个字段就是创建第三张表的意思,不是创建字段的意思,所以只能说这个book类里面有authors这个字段属性 authors=models.ManyToManyField(to='Author',) #注意不管是一对多还是多对多,写to这个参数的时候,最后后面的值是个字符串,不然你就需要将你要关联的那个表放到这个表的上面
表操作
python提供admin后台管理系统
在django项目下的url

访问网页http://127.0.0.1:8000/admin/

创建用户
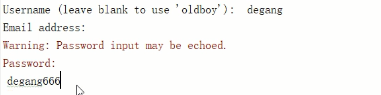
用户名:degang
Email:可以为空
Password:密码要求要有复杂度(要有数字,字母,不少于八位)输入两次密码
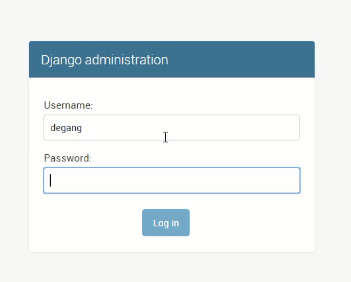
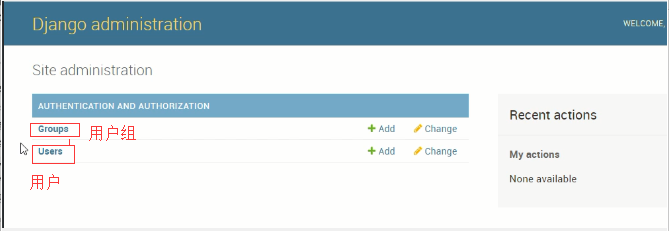
在django项目下把models导入到admin中,然后重启项目
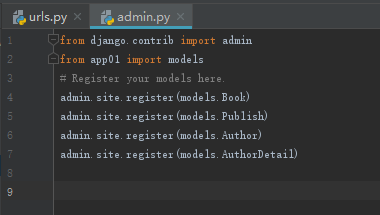

orm 常用字段和参数
字段
AutoField # 主键 CharField # 字符串 TextField # 大字符串 IntegerField # 整形 DateTimeField DateField # 日期 日期时间 BooleanField # 布尔 DecimalField max_digits=5 decimal_places=2 999.99
参数
null=True 数据库该字段可以为空 blank=True 校验时可以为空 default 默认值 unique 唯一索引 verbose_name 显示的名称 choices=((True, '男'), (False, '女')) 可选择的参数
class Meta(在models设置)
class Meta: # 数据库中生成的表名称 默认 app名称 + 下划线 + 类名 db_table = "person" # admin中显示的表名称 verbose_name = '个人信息' # verbose_name加s verbose_name_plural = '所有用户信息' # 联合索引 index_together = [ ("name", "age"), # 应为两个存在的字段 ] # 联合唯一索引 unique_together = (("name", "age"),) # 应为两个存在的字段
关于多对多表的三种创建方式(目前你先作为了解)
方式一:自行创建第三张表

class Book(models.Model):
title = models.CharField(max_length=32, verbose_name="书名")
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name="作者姓名")
# 自己创建第三张表,分别通过外键关联书和作者
class Author2Book(models.Model):
author = models.ForeignKey(to="Author")
book = models.ForeignKey(to="Book")
class Meta:
unique_together = ("author", "book")
方式二:通过ManyToManyField自动创建第三张表
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name="书名")
# 通过ORM自带的ManyToManyField自动创建第三张表
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name="作者姓名")
books = models.ManyToManyField(to="Book", related_name="authors")
方式三:设置ManyTomanyField并指定自行创建的第三张表
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name="书名")
# 自己创建第三张表,并通过ManyToManyField指定关联
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name="作者姓名")
books = models.ManyToManyField(to="Book", through="Author2Book", through_fields=("author", "book"))
# through_fields接受一个2元组('field1','field2'):
# 其中field1是定义ManyToManyField的模型外键的名(author),field2是关联目标模型(book)的外键名。
class Author2Book(models.Model):
author = models.ForeignKey(to="Author")
book = models.ForeignKey(to="Book")
class Meta:
unique_together = ("author", "book")
注意:
当我们需要在第三张关系表中存储额外的字段时,就要使用第三种方式。
但是当我们使用第三种方式创建多对多关联关系时,就无法使用orm提供的set、add、remove、clear方法来管理多对多的关系了,需要通过第三张表的model来管理多对多关系。


to
设置要关联的表。
to_field
设置要关联的字段。
on_delete
同ForeignKey字段。
to 设置要关联的表 to_field 设置要关联的表的字段 related_name 反向操作时,使用的字段名,用于代替原反向查询时的'表名_set'。 related_query_name 反向查询操作时,使用的连接前缀,用于替换表名。 on_delete 当删除关联表中的数据时,当前表与其关联的行的行为。
多对多的参数:
to
设置要关联的表
related_name
同ForeignKey字段。
related_query_name
同ForeignKey字段。
through
在使用ManyToManyField字段时,Django将自动生成一张表来管理多对多的关联关系。
但我们也可以手动创建第三张表来管理多对多关系,此时就需要通过
through来指定第三张表的表名。
through_fields
设置关联的字段。
db_table
默认创建第三张表时,数据库中表的名称。
元信息 ORM对应的类里面包含另一个Meta类,而Meta类封装了一些数据库的信息。主要字段如下: class Author2Book(models.Model): author = models.ForeignKey(to="Author") book = models.ForeignKey(to="Book") class Meta: unique_together = ("author", "book") db_table ORM在数据库中的表名默认是 app_类名,可以通过db_table可以重写表名。db_table = 'book_model' index_together 联合索引。 unique_together 联合唯一索引。 ordering 指定默认按什么字段排序。 ordering = ['pub_date',] 只有设置了该属性,我们查询到的结果才可以被reverse(),否则是能对排序了的结果进行反转(order_by()方法排序过的数据)
增删改查
增
一对一
obj=models.AuthorDetail.objects.create( birthday='1979-12-12', telephone='13838338', addr='黑龙江' ) models.Author.objects.create( name='王涛', age=72, # authorDetail=obj, )
obj1=models.AuthorDetail.objects.filter(addr='山西').first() #取得对象 models.Author.objects.create( name='b哥', age=63, authorDetail_id=obj1.id )
一对多
new_pu=models.Publish.objects.get(id=1) obj=models.Book.objects.create( title='亚索的故事', publishDate='2013-09-12', price=11.1, publish=new_pu, ) print(obj)
new_pu=models.Publish.objects.get(id=2) models.Book.objects.create( title="箫曲", publishDate='2011-07-04', price=96, publish_id=new_pu.id )
多对多
book_obj=models.Book.objects.get(nid=1) print(book_obj) book_obj.authors.add(*[1,2])
author1 = models.Author.objects.get(id=1) author2 = models.Author.objects.get(id=3) book_obj = models.Book.objects.get(nid=2) book_obj.authors.add(*[author1,author2])
删
models.AuthorDetail.objects.get(id=6).delete()
models.Publish.objects.get(id=2).delete()
models.Book.objects.get(pk=5).delete()
book_obj = models.Book.objects.get(nid=4) print(book_obj) book_obj.authors.remove(2) # book_obj.authors.remove(*[5,6]) # book_obj.authors.clear() # book_obj.authors.add(*[1,]) # book_obj.authors.set('1') # book_obj.authors.set(['5','6'])
多表删除
URL下
url(r'(\w+)_del/(\d+)/$', views.delete, name='delete')
VIEWS下
def delete(request,table,pk): #table 表名 pk 删除的id print(table,pk) model_cls=getattr(models,table.capitalize(),) #capitalize 首字母大写 model_cls.objects.filter(pk=pk).delete() return redirect(table)
HTML下
<a class="btn btn-danger btn-sm" id="{{ i.nid }}" href="{% url 'delete' 'author' i.nid %}" >删除</a>
改
models.Author.objects.filter(id=3).update( name='壮壮', age=80, authorDetail_id=7, )
models.Book.objects.filter(pk=1).update( title='b哥的往事3', publishDate='2019-01-01', price='100', publish_id=1. )
多对多
book_obj.authors.remove() # 将某个特定的对象从被关联对象集合中去除。 ====== book_obj.authors.remove(*[1,2]),将多对多的关系数据删除 book_obj.authors.clear() #清空被关联对象集合 book_obj.authors.set() #先清空再设置 =====
查(重点)
关系属性(字段)写在哪个类(表)里面,从当前类(表to)的数据去查询它关联类(表)的数据叫做正向查询,反之叫做反向查询
# 查询 # 一对一 # 正向查询 # 1 查询崔老师的电话号 author_obj = models.Author.objects.filter(name='崔老师').first() print(author_obj.authorDetail) #辽宁峨眉山 print(author_obj.authorDetail.telephone) #444 #2 反向查询 #2 查询一下这个444电话号是谁的. author_detail_obj = models.AuthorDetail.objects.get(telephone='444') print(author_detail_obj.author) #崔老师 print(author_detail_obj.author.name) #崔老师 ''' 正向查询:Authorobj.authorDetail,对象.关联属性名称 Author----------------------------------->AuthorDetail <----------------------------------- 反向查询:AuthorDetailobj.author ,对象.小写类名 ''' # 一对多 # 查询一下李帅的床头故事这本书的出版社是哪个 # 正向查询 book_obj = models.Book.objects.get(title='李帅的床头故事') print(book_obj.publishs) # B哥出版社 print(book_obj.publishs.name) # B哥出版社 # B哥出版社出版社出版了哪些书 # 反向查询 pub_obj = models.Publish.objects.get(name='B哥出版社') print(pub_obj.book_set.all()) # <QuerySet [<Book: 李帅的床头故事>, <Book: 李帅的床头故事2>]> ''' 正向查询 book_obj.publishs 对象.属性 Book ---------------------------------------------> Publish <---------------------------------------------- 反向查询 publish_obj.book_set.all() 对象.表名小写_set ''' # 多对多 # 李帅的床头故事这本书是谁写的 # 正向查询 book_obj = models.Book.objects.get(title='李帅的床头故事') print(book_obj.authors.all()) # 高杰写了哪些书 author_obj = models.Author.objects.get(name='高杰') print(author_obj.book_set.all()) ''' 正向查询 book_obj.authors.all() 对象.属性 Book ---------------------------------------------> Author <---------------------------------------------- 反向查询 author_obj.book_set.all() 对象.表名小写_set '''
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的model 为止。
'''
基于双下划线的查询就一句话:正向查询按字段,反向查询按表名小写用来告诉ORM引擎join哪张表,一对一、一对多、多对多都是一个写法,注意,我们写orm查询的时候,哪个表在前哪个表在后都没问题,因为走的是join连表操作。
'''
一对一查询
# 查询yuan的手机号 # 正向查询 ret=Author.objects.filter(name="yuan").values("authordetail__telephone") # 反向查询 ret=AuthorDetail.objects.filter(author__name="yuan").values("telephone")
一对多查询
# 练习: 查询苹果出版社出版过的所有书籍的名字与价格(一对多) # 正向查询 按字段:publish queryResult=Book.objects .filter(publish__name="苹果出版社") #通过__告诉orm将book表和publish表进行join,然后找到所有记录中publish.name='苹果出版社'的记录(注意publish是属性名称),然后select book.title,book.price的字段值 .values_list("title","price") #values或者values_list # 反向查询 按表名:book queryResult=Publish.objects .filter(name="苹果出版社") .values_list("book__title","book__price")
多对多查询
# 练习: 查询yuan出过的所有书籍的名字(多对多) # 正向查询 按字段:authors: queryResult=Book.objects .filter(authors__name="yuan") .values_list("title") # 反向查询 按表名:book queryResult=Author.objects .filter(name="yuan") .values_list("book__title","book__price")
进阶练习(连续跨表)
# 练习: 查询人民出版社出版过的所有书籍的名字以及作者的姓名 # 正向查询 queryResult=Book.objects .filter(publish__name="人民出版社") .values_list("title","authors__name") # 反向查询 queryResult=Publish.objects .filter(name="人民出版社") .values_list("book__title","book__authors__age","book__authors__name") # 练习: 手机号以151开头的作者出版过的所有书籍名称以及出版社名称 # 方式1: queryResult=Book.objects .filter(authors__authorDetail__telephone__regex="151") .values_list("title","publish__name") # 方式2: ret=Author.objects .filter(authordetail__telephone__startswith="151") .values("book__title","book__publish__name")
related_name
只能反向查找用
反向查询时,如果定义了related_name ,则用related_name替换 表名,例如:
publish = ForeignKey(Blog, related_name='bookList')
# 练习: 查询人民出版社出版过的所有书籍的名字与价格(一对多) # 反向查询 不再按表名:book,而是related_name:bookList queryResult=Publish.objects .filter(name="人民出版社") .values_list("bookList__title","bookList__price")
聚合查询、分组查询、F查询和Q查询
聚合
aggregate(*args, **kwargs) # 计算所有图书的平均价格 >>> from django.db.models import Avg >>> Book.objects.all().aggregate(Avg('price')) #或者给它起名字:aggretate(a=Avg('price')) {'price__avg': 34.35} aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。 >>> Book.objects.aggregate(average_price=Avg('price')) {'average_price': 34.35} 如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询: >>> from django.db.models import Avg, Max, Min >>> Book.objects.aggregate(Avg('price'), Max('price'), Min('price')) #count('id'),count(1)也可以统计个数,Book.objects.all().aggregete和Book.objects.aggregate(),都可以 {'price__avg': 34.35, 'price__max': Decimal('81.20'), 'price__min': Decimal('12.99')}
分组
annotate() 为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数)。 models.Publish.objects.annotate(a=Avg('book__price')).values('a') models.Book.objects.values('publish_id','id').annotate(a=Avg('price')) {'pulish_id':1,'a':11.11} 总结 :跨表分组查询本质就是将关联表join成一张表,再按单表的思路进行分组查询,,既然是join连表,就可以使用咱们的双下划线进行连表了。
F查询
from django.db.models import F,Q F 针对自己单表中字段的比较和处理 # good(点赞)comment(评论) #比较 models.Book.objects.filter(good__gt=F('comment')*2) #修改 models.Book.objects.all().update(price=F('price')+1)
Q查询
Q 对象可以使用&(与) 、|(或)、~(非) 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。 bookList=Book.objects.filter(Q(authors__name="yuan")|Q(authors__name="egon")) 你可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询: bookList=Book.objects.filter(Q(authors__name="yuan") & ~Q(publishDate__year=2017)).values_list("title") bookList=Book.objects.filter(Q(Q(authors__name="yuan") & ~Q(publishDate__year=2017))&Q(id__gt=6)).values_list("title") #可以进行Q嵌套,多层Q嵌套等,其实工作中比较常用 查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。例如: bookList=Book.objects.filter(Q(publishDate__year=2016) | Q(publishDate__year=2017), title__icontains="python" #也是and的关系,但是Q必须写在前面 )
ORM执行原生sql语句(了解)
在模型查询API不够用的情况下,我们还可以使用原始的SQL语句进行查询。
Django 提供两种方法使用原始SQL进行查询:一种是使用raw()方法,进行原始SQL查询并返回模型实例;另一种是完全避开模型层,直接执行自定义的SQL语句。
执行原生查询
raw()管理器方法用于原始的SQL查询,并返回模型的实例:
注意:raw()语法查询必须包含主键。
这个方法执行原始的SQL查询,并返回一个django.db.models.query.RawQuerySet 实例。 这个RawQuerySet 实例可以像一般的QuerySet那样,通过迭代来提供对象实例。
举个例子:
class Person(models.Model):
first_name = models.CharField(...)
last_name = models.CharField(...)
birth_date = models.DateField(...)
可以像下面这样执行原生SQL语句
>>> for p in Person.objects.raw('SELECT * FROM myapp_person'):
... print(p)
raw()查询可以查询其他表的数据。
举个例子:
ret = models.Student.objects.raw('select id, tname as hehe from app02_teacher')
for i in ret:
print(i.id, i.hehe)
raw()方法自动将查询字段映射到模型字段。还可以通过translations参数指定一个把查询的字段名和ORM对象实例的字段名互相对应的字典
d = {'tname': 'haha'}
ret = models.Student.objects.raw('select * from app02_teacher', translations=d)
for i in ret:
print(i.id, i.sname, i.haha)
原生SQL还可以使用参数,注意不要自己使用字符串格式化拼接SQL语句,防止SQL注入!
d = {'tname': 'haha'}
ret = models.Student.objects.raw('select * from app02_teacher where id > %s', translations=d, params=[1,])
for i in ret:
print(i.id, i.sname, i.haha)
直接执行自定义SQL
有时候raw()方法并不十分好用,很多情况下我们不需要将查询结果映射成模型,或者我们需要执行DELETE、 INSERT以及UPDATE操作。在这些情况下,我们可以直接访问数据库,完全避开模型层。
我们可以直接从django提供的接口中获取数据库连接,然后像使用pymysql模块一样操作数据库。
from django.db import connection, connections
cursor = connection.cursor() # cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
ret = cursor.fetchone()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号