数据库多表查询、SQL注入、pymysql、事务
概要
1、多表查询思路
2、navicate可视化软件
3、python操作mysql
4、SQL注入问题
5、MySQL中的事务
1、多表查询的思路
1、多表查询前戏
# 数据准备
# 建立一张员工表和部门表
create table dep(
id int primary key auto_increment,
name varchar(32)
);
create table emp(
id int primary key auto_increment,
name varchar(32),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
# 插入数据
insert into dep values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营'),
(205,'保洁')
;
insert into emp(name,sex,age,dep_id) values
('jason','male',18,200),
('egon','female',48,201),
('kevin','male',18,201),
('nick','male',28,202),
('owen','male',18,203),
('jerry','female',18,204);
# 注意:这里我们并没有给员工表建立外键,所以就不能用外键字段来进行相关的操作
问题1:查询jason所在的部门名称
1、先明确题目需要涉及到几张表,很明显,部门名称只在部门表里,而jason只在员工表里,部门表和员工表哪两个字段有关系?
2、利用两张表中有关联的两个字段进行剖析
3、知道了员工姓名,如何查找员工所在的部门名称
解决:
1、先查询jason所在的部门编号
select dep_id from emp where name='jason'; # 得出jason所在的部门编号
2、再根据部门编号去查询对应的部门名称
select name from dep where id=
'''
在这里需要注意,在MySQL中,一条SQL语句的执行结果,可以看成是一张新的表,同时也可以看成是一条查询条件,因此,上述的完整语句可以写为
select dep.name from dep where dep_id=(select emp.dep_id from emp where emp.name='jason');
'''
2、多表查询的思路
多表查询的方式
1、子查询
简单来说就是把一条SQL语句的执行结果用括号括起来当作另外一条SQL语句的条件(即分步操作)
上述例子采用的即是子查询的方式来实现多表查询
2、连表操作(重要)
所谓的连表操作就是将需要用到的表拼接成一张达标,之后基于单表查询操作即可
连表操作中的四个关键词
inner join 内连接
left join 左连接
right join 右连接
union 全连接
# ps:涉及到多表查询时,字段名容易发生冲突,所以最好的方式是表名点字段名的方式进行区分(表明.字段名)
3、连表操作关键词介绍
# 连表操作的基本语法格式
select * from 表1名 关键词(inner join等) 表2名 on 表1里的字段1=表2里的字段2;
# 需要注意的是,这里的字段1和字段2必须是能够代表两张表关系的字段
# inner join:只拼接两张表中共有的部分
select * from emp inner join dep on emp.dep_id=dep.id;
select dep.name from emp inner join dep on emp.dep_id=dep.id where emp.name='jason';
# left join:以left join 左边的表为基准展示所有内容,没有的用null填充
select * from emp left join dep on emp.dep_id=dep.id;
# right join:以right join右边的表为基准展示所有内容,没有的用null填充
select * from emp right join dep on emp.dep_id=dep.id;
# union:将左右两张表所有的数据展示出来,没有数据的用null填充
select * from emp left join dep on emp.dep_id=dep.id
union
select * from emp right join dep on emp.dep_id=dep.id;
'''
但是上述操作又带来的一个问题:
上述操作一次只能操作两张表,如何做到操作多张表?
解决方式:上面说到了,SQL语句的执行结果可以看成是一张新的表,所以我们可以将拼接的两张表看成是一张新的表,
然后拿着这张新的表再与其他的表进行拼接,如此往复,即可实现多表拼接,
下面会讲关于多表拼接时可以使用关键字as给拼接的表起别名,
然后基于这张表进行操作即可
'''
2、navicate可视化软件
# 软件介绍
navicate可视化软件:作用是简化用户的操作,只需要用鼠标点的方式
即可完成对数据库的操作,但是其底层还是基于原生的SQL语句进行的,即用户通过鼠标点的方式,其内部会自动构建SQL语句
所以,掌握基本的SQL语句其实才是最重要的。
# 下载与安装
navicate是一款收费的软件,正版的有14天的试用期,
不过可以使用破解版的,网页上搜索navicate破解版即可
# 基本使用
navicate可以看成是很多数据库软件的客户端
MySQL的注释语法
符号:警号注释
-- 注释
快捷键:选中 ctrl+?
navicate基本使用
- 连接数据库
进入navicate界面,点击连接,选择相应的数据库,选择`MySQL`
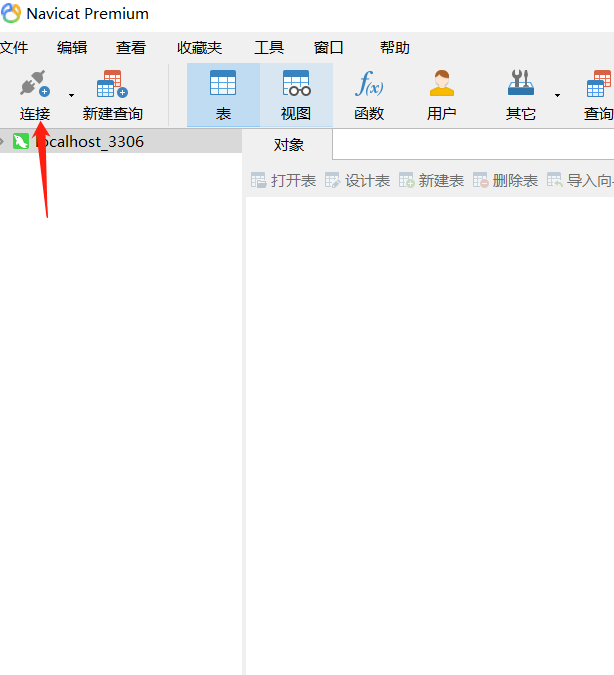
连接名可以自己设置,我当前是在自己本地电脑操作,主机名默认即可,端口号选择MySQL默认的端口号(3306),用户名和密码选择你要访问数据库的用户名和密码,这里我先使用管理员账户密码登录连接,密码不确定可以先点击左下角的`测试连接`进行测试,然后点击确定。
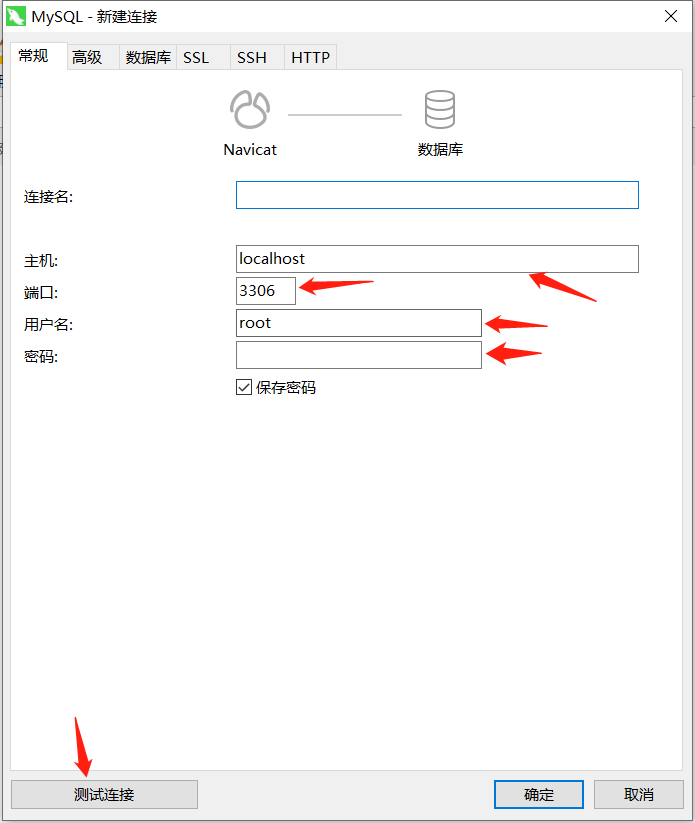
链接到数据库以后,双击左侧的链接名,就能看到已经创建的数据库名称了
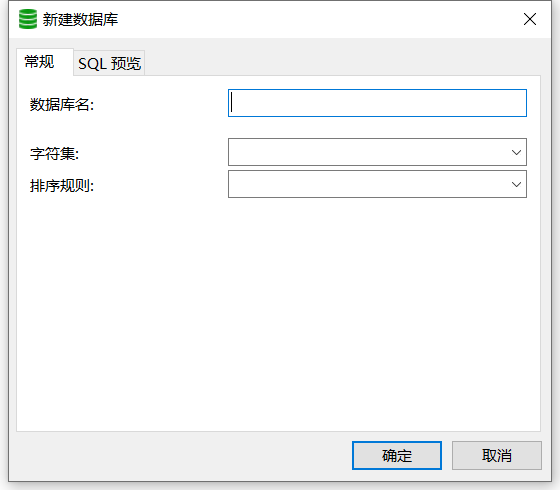
- 创建新的数据库
右键点击连接名(localhost),选择新建数据库,数据库名填写你想要修改的数据库名称,字符集一定要选,这里为了避免出现中文乱码,我选择`utf8mb4`,点击确定。
双击数据库,由于新建的数据库里没有数据,右键点击表格,选择新建表
填写字段名,类型会自动添加,也可手动选择
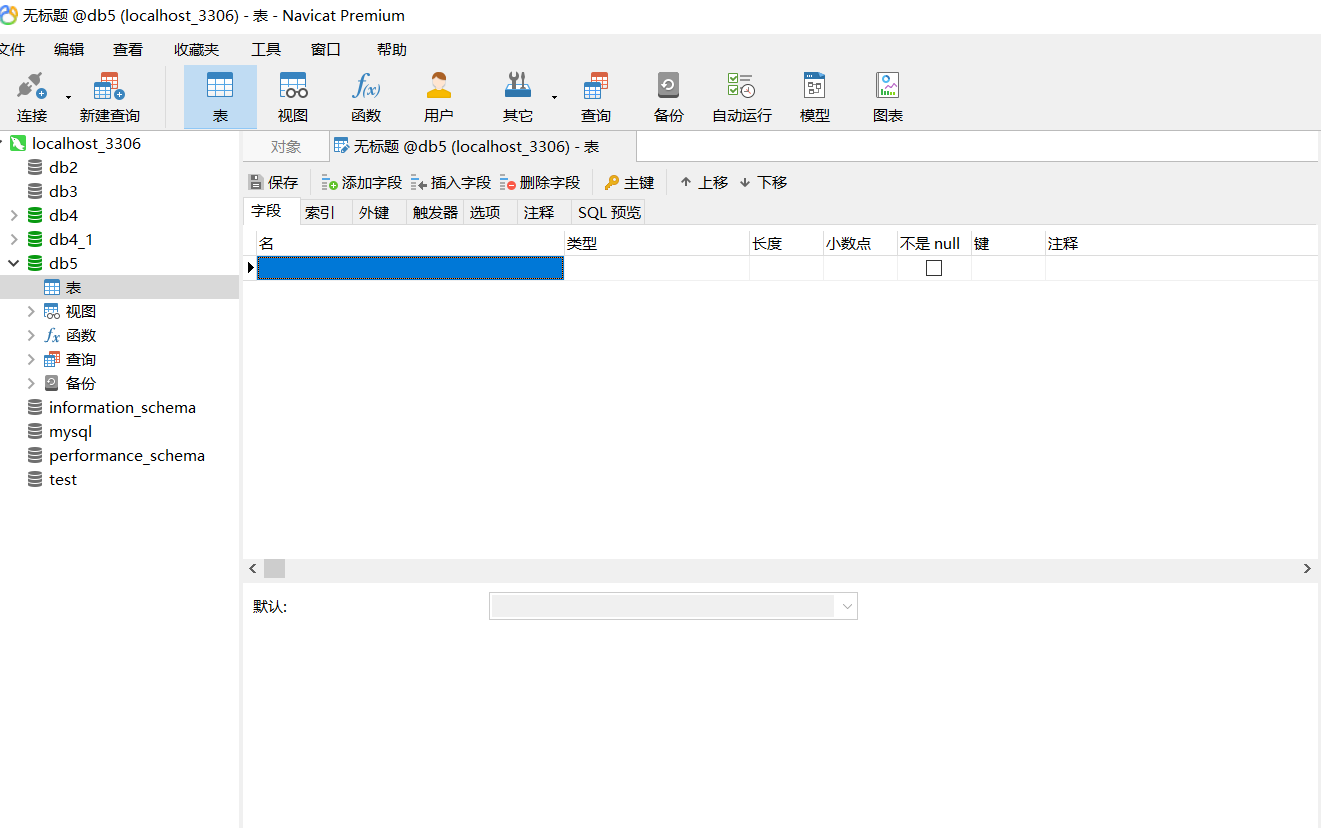
- 设置主键
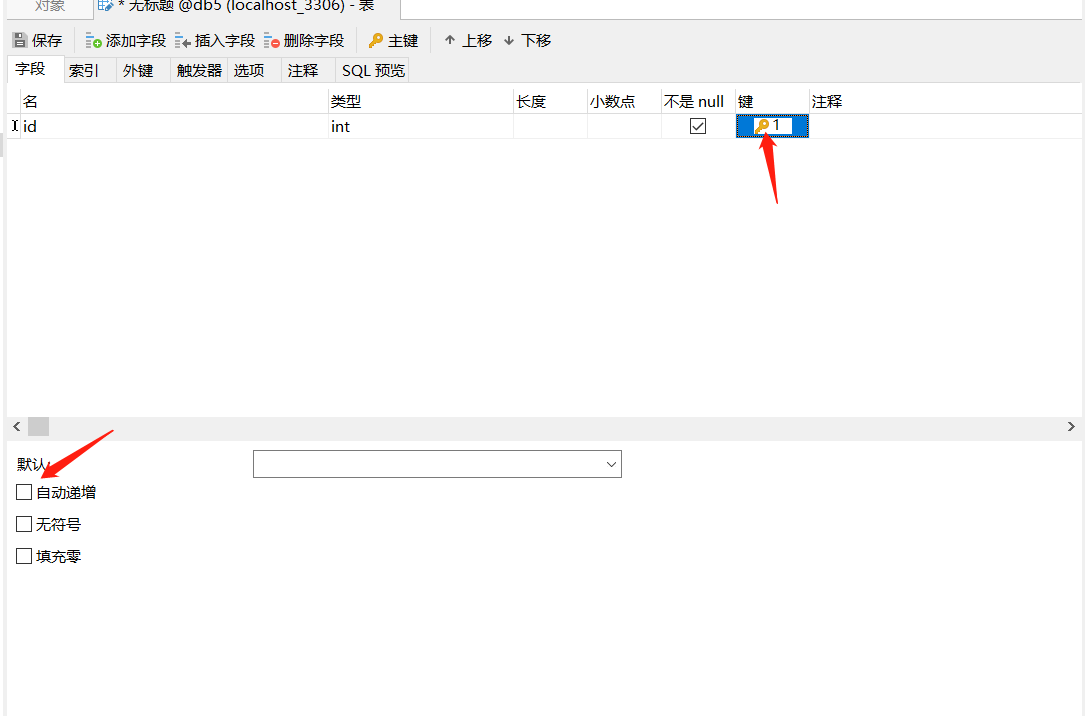
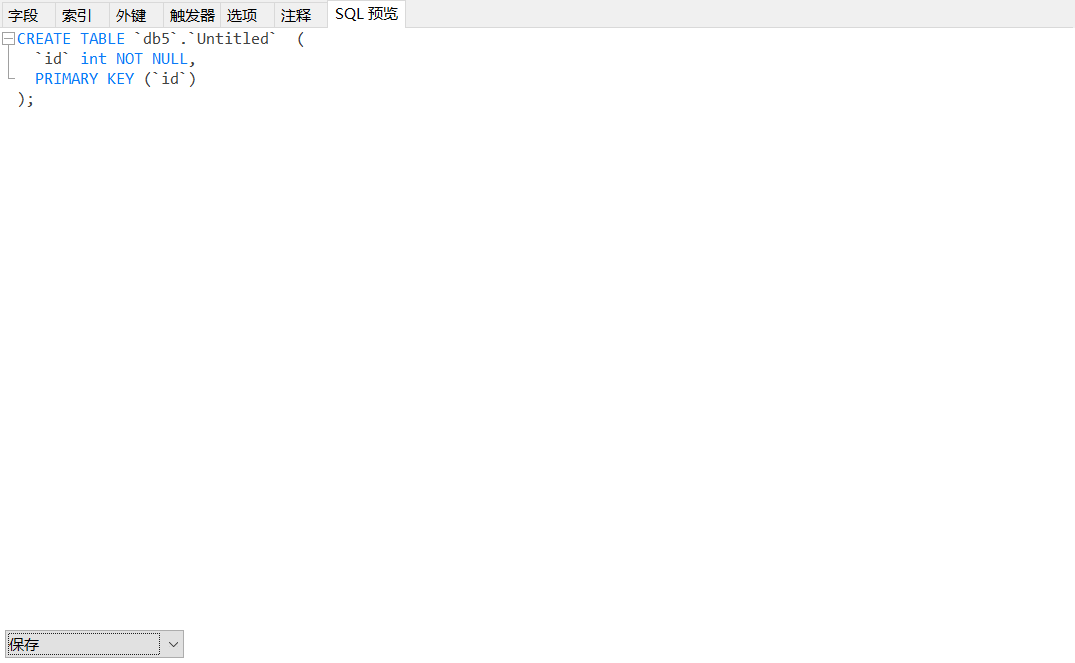
在键的位置,通过空格控制是否为主键,钥匙形状即为主键的意思,然后勾选上下面的自动递增,再点击SQL预览就会出现和我们用SQL语句建立时一样的效果,点击`添加字段`就可以添加多个字段名了,然后点击保存,输入表名点击确定即可。
- 往表中插入信息
双击表>>双击表名,就会进入到插入数据的界面,填写相关的数据,使用`Tab`键进入下一行或者使用下面的加号和减号来控制数据的删除与增加,然后点击下面的对勾点击保存即可。
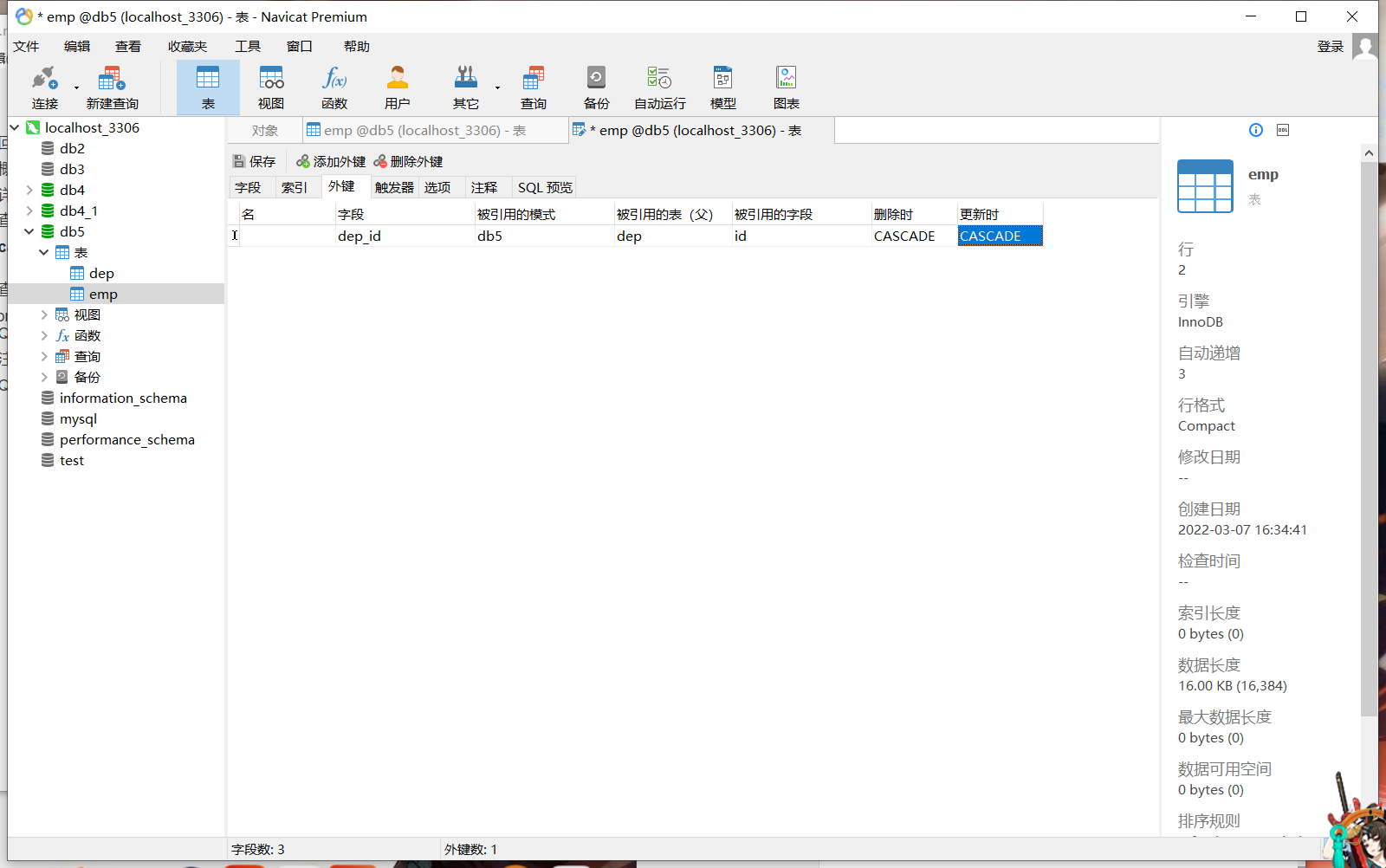
- 增加主键(以一对多为例)
创建一张表作为主表(即不含外键的表),在从表中增加一个字段名,右键从表,点击设计表,点击外键,字段选择要创建的外键字段(必须要存在),引用模式即数据库名称,选择db5,被引用的表选择主表(dep),被引用字段选择主表中的字段(必须要有数据),删除和更新时选择CASCADE(级联更新和级联删除)
- 新建查询
也可以通过新建查询写原生的SQL语句来操作数据库,可以选择连接名和操作的数据库名称,运行时点击运行即可,或者选中SQL语句单独运行选中的语句
- 导入和导出数据库文件
导出:右键数据库名>>转储SQL文件>>>结构和数据,选择文件的存放位置
导入:右键连接名>>>运行SQL文件,选择SQL文件
3、多表查询练习
1、查询所有的课程的名称以及对应的任课老师姓名
2、查询平均成绩大于八十分的同学的姓名和平均成绩
3、查询没有报李平老师课的学生姓名
4、查询没有同时选修物理课程和体育课程的学生姓名
5、查询挂科超过两门(包括两门)的学生姓名和班级
'''
在进行多表查询时:
1、先确定需要使用到的表
2、再思考多表查询的方式
'''
-- 1、查询所有的课程的名称以及对应的任课老师姓名
# 1.1 运用连表查询先查询所有的信息
SELECT
*
FROM
course
INNER JOIN teacher ON course.teacher_id = teacher.tid
# 1.2 再查询课程名称及对应的任课老师姓名
SELECT
course.cname,
teacher.tname
FROM
course
INNER JOIN teacher ON course.teacher_id = teacher.tid
-- 2、查询平均成绩大于八十分的同学的姓名和平均成绩
# 2.1 先以学生编号进行分组,并获取平均成绩
SELECT
score.student_id,
avg( num )
FROM
score
GROUP BY
score.student_id
# 2.2 再筛选出平均成绩大于80的学生编号和平均成绩(针对聚合函数,字段名最好是另起别名,防止发生冲突)
SELECT
score.student_id,
avg( num ) AS avg_num
FROM
score
GROUP BY
score.student_id
HAVING
avg( score.num )> 80
# 2.3 再利用连表操作查询出同学的姓名
SELECT
student.sname,
t1.avg_num
FROM
student
INNER JOIN ( SELECT student_id, avg( num ) AS avg_num FROM score GROUP BY student_id HAVING avg( num )> 80 ) AS t1 ON student.sid = t1.student_id
-- 3、查询没有报李平老师课的学生姓名
# 3.1 先查询李平老师教授的课程编号
SELECT
cid
FROM
course
WHERE
teacher_id =(
SELECT
tid
FROM
teacher
WHERE
tname = '李平老师'
)
# 3.2 再查询报了李平老师教授的课程的同学编号
SELECT DISTINCT
student_id
FROM
score
WHERE
course_id IN (
SELECT
cid
FROM
course
WHERE
teacher_id =(
SELECT
tid
FROM
teacher
WHERE
tname = '李平老师'
))
# 3.3 再筛选出没报李平老师课程的同学姓名
SELECT
sname
FROM
student
WHERE
sid NOT IN (
SELECT DISTINCT
student_id
FROM
score
WHERE
course_id IN (
SELECT
cid
FROM
course
WHERE
teacher_id =(
SELECT
tid
FROM
teacher
WHERE
tname = '李平老师'
)))
-- 4、查询没有同时选修物理课程和体育课程的学生姓名
# 4.1 先获取两门课程的id
SELECT
course.cid
FROM
course
WHERE
course.cname IN ( '物理', '体育' )
# 4.2 再去分数表中查询选修了两门课程(选一门或者两门)的学生id
SELECT
score.student_id
FROM
score
WHERE
score.course_id IN (
SELECT
course.cid
FROM
course
WHERE
course.cname IN ( '物理', '体育' ))
# 4.3 再通过学生编号分组,利用count计数筛选出只报了一门的学生编号
SELECT
score.student_id
FROM
score
WHERE
score.course_id IN (
SELECT
course.cid
FROM
course
WHERE
course.cname IN ( '物理', '体育' ))
GROUP BY
score.student_id
HAVING
count( score.course_id )= 1
# 4.4 根据学生编号去学生表中查询学生姓名
SELECT
student.sname
FROM
student
WHERE
student.sid IN (
SELECT
score.student_id
FROM
score
WHERE
score.course_id IN (
SELECT
course.cid
FROM
course
WHERE
course.cname IN ( '物理', '体育' ))
GROUP BY
score.student_id
HAVING
count( score.course_id )= 1
)
-- 5、查询挂科超过两门(包括两门)的学生姓名和班级
# 5.1 先筛选出所有挂科的数据
SELECT
*
FROM
score
WHERE
score.num < 60
# 5.2再利用学生编号进行分组,统计出挂科数量
SELECT
score.student_id,
count( score.course_id )
FROM
score
WHERE
score.num < 60
GROUP BY
score.student_id
# 5.3 筛选出挂科超过两门的学生id
SELECT
score.student_id
FROM
score
WHERE
num < 60
GROUP BY
score.student_id
HAVING
count( score.course_id )>= 2
# 5.4 将上述结果当成查询条件,将学生表和班级表拼接在一起,查询出挂科超过两门的学生姓名和班级
SELECT
student.sname,
class.caption
FROM
student
INNER JOIN class ON student.class_id = class.cid
WHERE
student.sid IN ( SELECT score.student_id FROM score WHERE num < 60 GROUP BY score.student_id HAVING count( score.course_id )>= 2 )
3、python操作mysql
# 1、导入第三方模块(需要下载)
import pymysql
1、针对数据的查询
# 连接MySQL服务端
conn = pymysql.connect(
host='127.0.0.1', # 主机名
port=3306, # 端口号(MySQL默认为3306)
user='root', # 连接的用户名
password='123', # 连接的用户对应的密码
database='db6', # 使用的数据库名
charset='utf8', # 字符编码(不能写成utf-8)
)
# 产生一个游标对象
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 查询的数据以列表套字典的形式展现
# cursor = conn.cursor() # 查询的数据以元组套元组的形式展现(只展示字段对应的数据)
# 编写SQL语句
sql = 'select * from teacher' # 这句话只是执行SQL语句会影响的行数
affect_rows = cursor.execute(sql) # 结果是影响的行数值
print(affect_rows)
# 获取SQL语句的真正执行结果
# print(cursor.fetchall()) # 获取查询到的所有数据
# print(cursor.fetchone()) # {'tid': 1, 'tname': '张磊老师'} 一次拿一个数据
# print(cursor.fetchone()) # {'tid': 2, 'tname': '李平老师'}
# print(cursor.fetchone()) # {'tid': 3, 'tname': '刘海燕老师'}
# print(cursor.fetchmany(2)) # 一次拿多个,括号内的参数可以控制一次拿几个
# print(cursor.fetchmany(2))
'''
解释说明:出现上述情况的原因是,使用python去操作数据库获取数据时,游标就相当于操作文件时的光标
,控制当前所在的位置,因此,才会出现拿完一个以后继续拿下一个的情况
'''
# print(cursor.fetchone()) # {'tid': 1, 'tname': '张磊老师'}
# cursor.scroll(2, 'relative') # 控制游标的移动
# print(cursor.fetchone()) # {'tid': 3, 'tname': '刘海燕老师'}
# cursor.scroll(2, 'absolute')
# print(cursor.fetchone()) # {'tid': 3, 'tname': '刘海燕老师'}
# cursor.scroll(2, 'absolute')
# print(cursor.fetchone()) # # {'tid': 3, 'tname': '刘海燕老师'}
'''
cursor.scroll方法,括号里的参数,第一位控制光标移动的次数,第二个参数控制光标相对哪个位置来移动
"relative"控制的是,相对于当前位置进行移动。"absolute"控制的是相对于开始位置移动
'''
'''
在使用代码对数据进行操作的时候,不同的操作级别是不一样的
针对数据的查看无限制
针对增、改、删需要二次确认才能实现对数据的修改
conn.commit()
'''
2、针对数据的增、改、删
# 增加数据
sql = 'insert into teacher values(6,"马云老师")'
res = cursor.execute(sql)
conn.commit()
print(res)
# 修改数据
sql = 'update teacher set tname="json老师" where tname="马云老师"'
res = cursor.execute(sql)
conn.commit()
print(res)
# 删除数据
sql = 'delete from teacher where tid=6'
res = cursor.execute(sql)
conn.commit()
print(res)
# 针对需要二次确认的,可以在连接数据库服务端时,加上参数autocommit=True,这样后续再进行增改删操作时就不需要再手动进行二次确认了
4、SQL注入问题
# 什么是SQL注入问题
结论:所谓的SQL注入问题就是使用MySQL中的特殊字符的组合来实现特殊的效果
实际生活中,尤其是在注册用户名的时候,会提示很多特殊符号不能使用,这也是为了避免SQL注入问题
注:在涉及到敏感数据部分(登录名和密码)时,不要自己拼接,最好是交给现成的方法进行拼接
# 以登录界面为例
# 为了更好的展示SQL注入问题,下面以一个登录小程序来验证
# 导入第三方模块
import pymysql
# 连接数据库服务端
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='123',
database='userinfo',
charset='utf8',
autocommit=True,
)
# 产生一个游标对象
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
# 获取用户输入
user = input('username>>>:').strip()
pwd = input('password>>>:').strip()
# 编写SQL语句
sql = "select * from userinfo where username='%s' and password='%s'" % (user, pwd)
cursor.execute(sql)
data = cursor.fetchall()
if data:
print('登录成功')
else:
print('用户名或密码错误')
'''
以用户名jason为例
当输入jason ' -- asdadasdasdas不输入密码或者
jason ' # asdasdasdas时,也会提示登录成功
这就是典型的SQL注入问题,特殊符号结合在一起会有特殊的效果,这就造成了数据的不安全性
那么如何解决这一问题呐,其实很简单,上面说了,遇到数据拼接式,最好是交给现成的拼接方法来实现
'''
解决方式
# 编写SQL语句
sql = "select * from userinfo where username=%s and password=%s"
cursor.execute(sql, (user, pwd)) # 使用自带的execute方法自动筛选,这样就能有效的去避免SQL注入问题
data = cursor.fetchall()
if data:
print('登录成功')
else:
print('用户名或密码错误')
5、MySQL中的事务
# 事务简介
事务是在存储引擎层实现的,也就是说并不是所有引擎都可以使用事务,MyISAM 就不支持事务,这也是为什么会被 InnoDB 取代的原因。
# 事务的四大特性
提到事务就不得不不说一下事务的四大特性:ACID
A:原子性
C:一致性
I:隔离性
D:持久性
# 四大特性介绍
原子性(atomicity)
一个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
一致性(consistency)
事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
隔离性(isolation)
一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
持久性(durability)
持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响
# 事务的相关操作
start transcation; # 开启事务
rollback ; # 回滚到操作之前的状态
commit ; # 确认事务操作,之后不能回滚
# 使用实际的表操作来展示事务的三个关键字
create table user(
id int primary key auto_increment,
name varchar(32),
balance int
);
insert into user(name,balance) values
('jason',1000),
('tony',1000),
('jane',1000);
# 修改数据之前先开启事务操作
start transcation;
# 修改表中的数据
update user set balance=900 where name='jason';
update user set balance=1010 where name='tony';
update user set baleance=1090 where name='jane';
# 回滚到上一个状态
rollback;
# 查看表中的数据
select * from user;
# 开启事务之后,只要没有执行commit确认操作,数据其实并没有刷到硬盘里
commit;
'''
开启事务检测操作是否完整,不完整回滚到上一个状态,如果完整就应该执行commit操作结束事务
'''
# 站在python代码层面看,应该使用异常捕获来实现,相关伪代码如下
try:
update user set balance=900 where name='jason';
update user set balance=1010 where name='tony';
update user set baleance=1090 where name='jane';
except Exceptions:
rollback;
else:
commit;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号