目录扫描哪家强?-Dirbuster-使用教程-2024
一、Dirbuster介绍
dirbuster是一个网站内容扫描器,它认为扫描工具好不好取决于它的字典好不好,它使用自己在网络上爬取收集的9个字典文件来工作,相信它应该很牛。这款工具在kali系统上已经内置。
参考文章:dirbuster | Kali Linux Tools
二、Dirbuster使用
1、本地Centos7环境下的实验
(一)、靶场环境
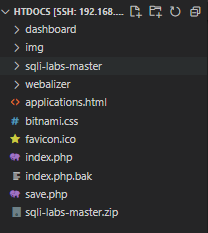
系统环境信息。
系统版本:"CentOS Linux release 7.6.1810 (Core)" #cat /etc/redhat-release
IP地址:"192.168.225.60" #ifconfig
Lampp版本:"XAMPP for Linux 5.6.40-1" #/opt/lampp/lampp status
Web服务根目录:"/opt/lampp/htdocs" #cat /opt/lampp/etc/httpd.conf | grep DocumentRoot
网站内容信息。
(二)、基本使用
(1)、设置代理
为了能够直观的看到扫描流量,笔者为dirbuster配置了一个指向的burp代理。

在host和port中填上需要代理的信息。

(2)、基本请求
笔者创造了一个自定义的字典,字典内容如下。
index
favicon
设置好参数进行扫描。

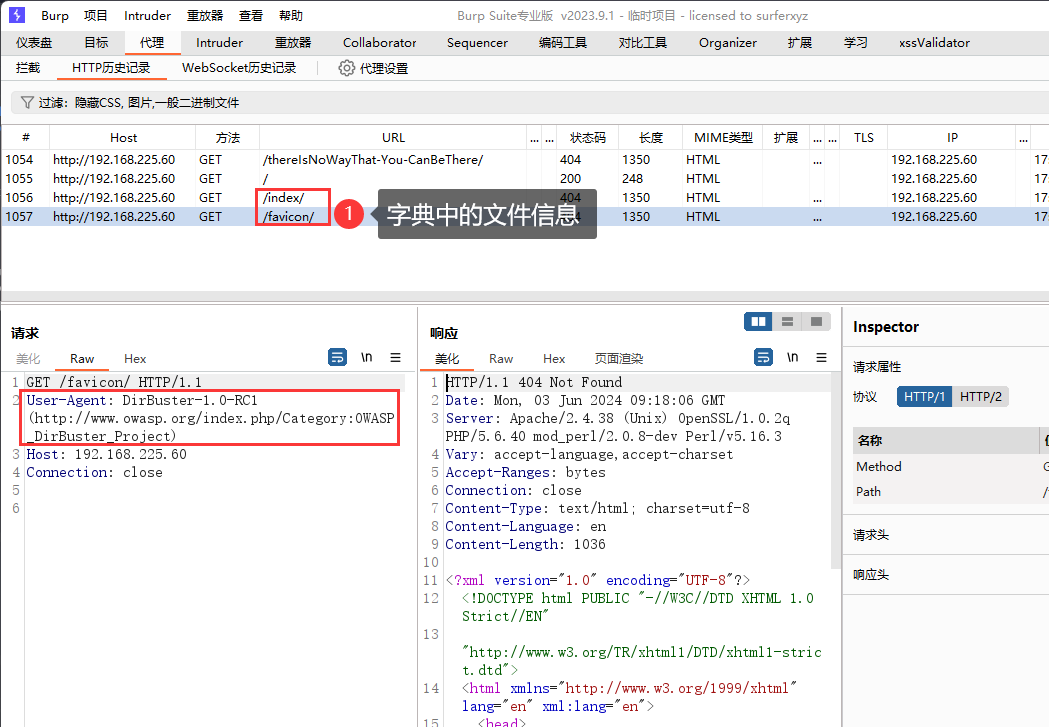
扫描结果如下,可以看到dirbuster也在一开始发送了两个自己的请求,而后才发送的是我字典中的请求,由于我使用的是字典模式,所以它在我的字典后面添加了一个斜杠。
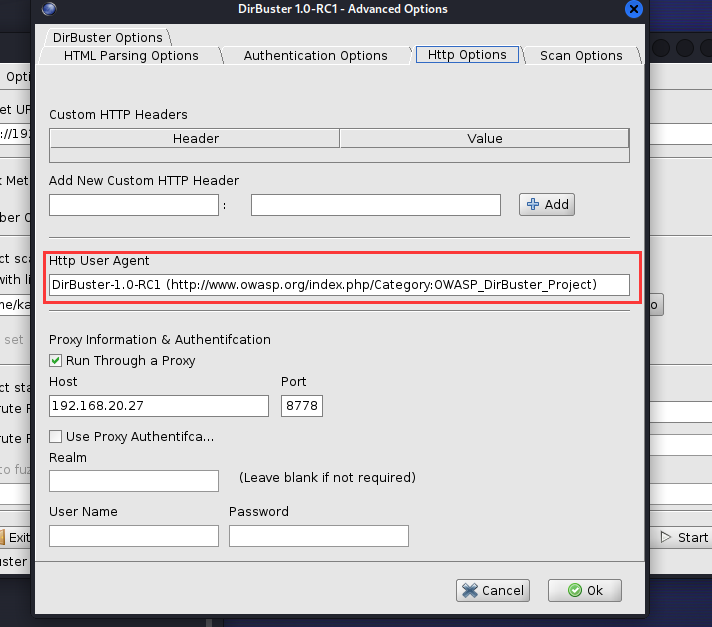
(3)、User-Agent头设置
并且在http的流量特征中我们发现dirb添加了自己的user-agnet头部信息,这个信息可以在下图位置修改,这里就是笔者上面修改代理的地方。
(4)、爬虫模式
我会很好奇上面的递归爆破字段是什么效用,于是我向字典中添加dashboard字段,以便它真的能扫描出来一些目录。
新的字典文件。
dashboard
奇怪的事情发生了,dirbuster开始自动发送一些不存在我字典文件中的请求。

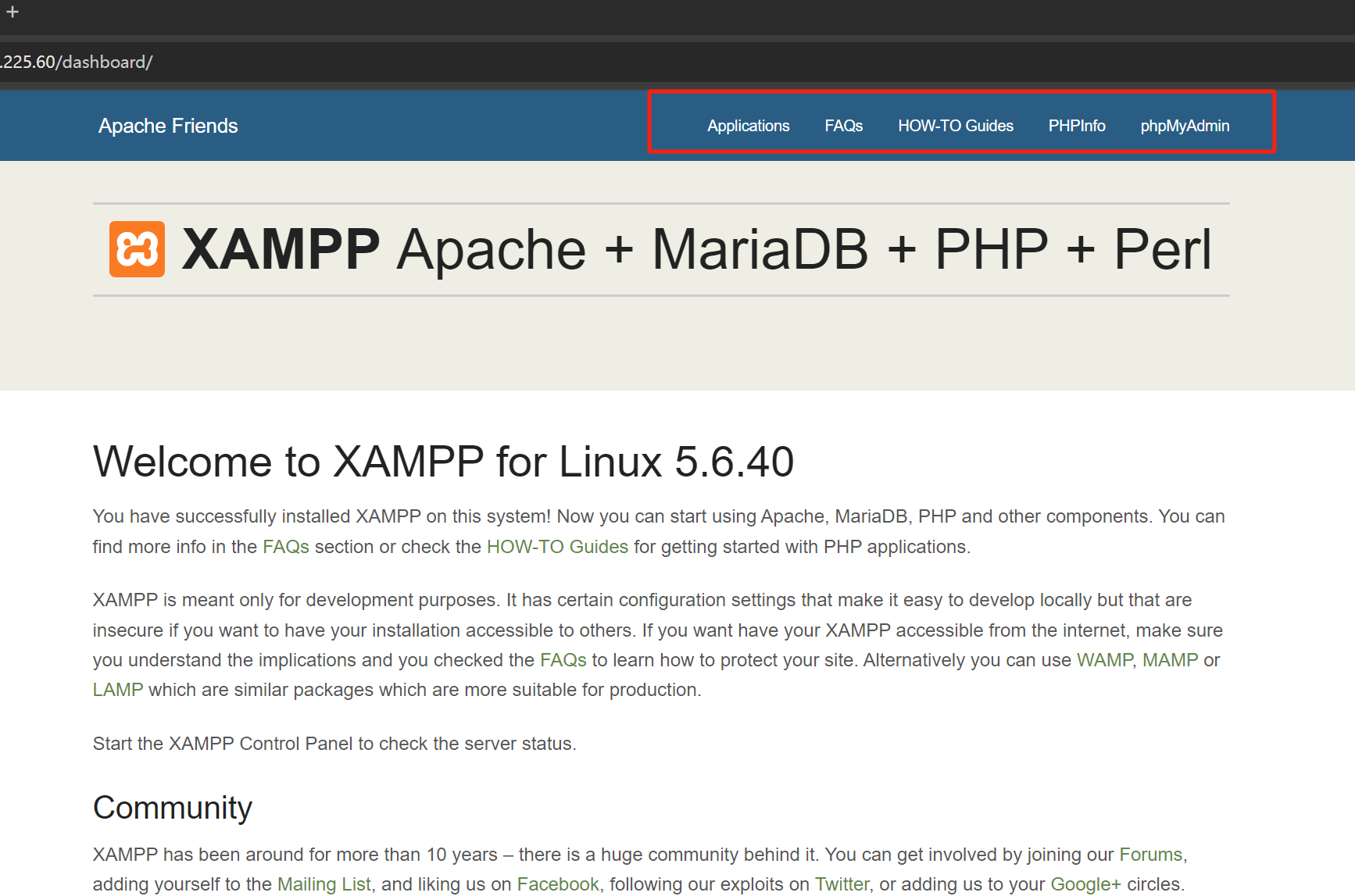
我怀疑这可能是因为dirbuster还使用到了爬虫机制,来获取文件中的链接,我们查看dashboard的主页,大概爆破出来的就是这些链接。
并且dirbuster还支持树状图浏览文件,这无疑比旁边的dirb方便很多,而且dirbuster还是ui界面,用起来很方便。
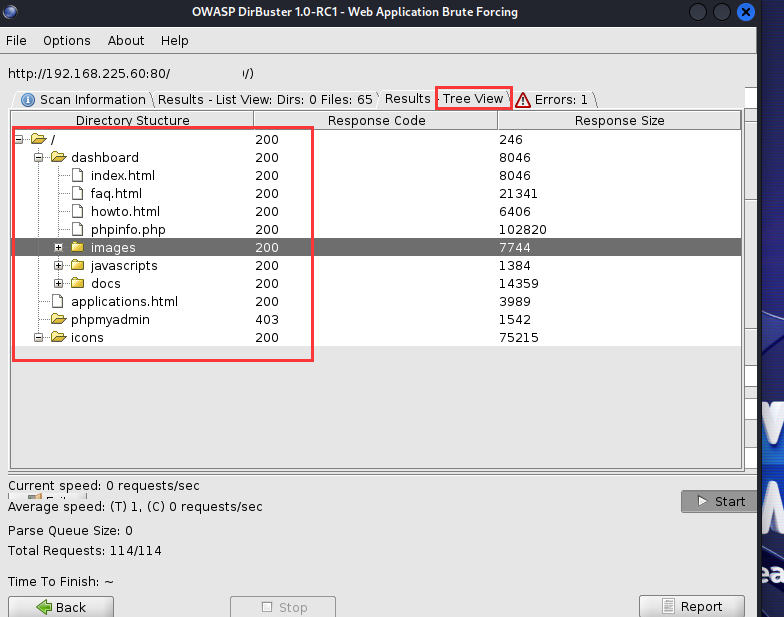
为了证明它是不是使用的爬虫模式,笔者最终找到这个按钮,并关闭它,就消失了爬虫模式,变成和dirb相同的傻瓜模式了(我好喜新厌旧555....)。

(5)、递归模式
让我们再次尝试递归模式是什么意思。
修改字典为下。
dashboard
index
favicon
这是非递归模式的请求流量。

这是递归模式下的请求流量,很明显,这里的递归和dirb里面的是一个意思,就是只要有一个字典值相应成功了,就把所有字典值添加在这个目录后面再爆破一遍。

(6)、文件爆破
使用刚才的字典文件,且后缀名指定为php,注意,文件后缀名不用写.php,只写php即可。也可也使用use balnk extension,不添加后缀名进行爆破。

使用上面的参数进行扫描,流量如下,后缀名php被完整的添加到字典文件后面。
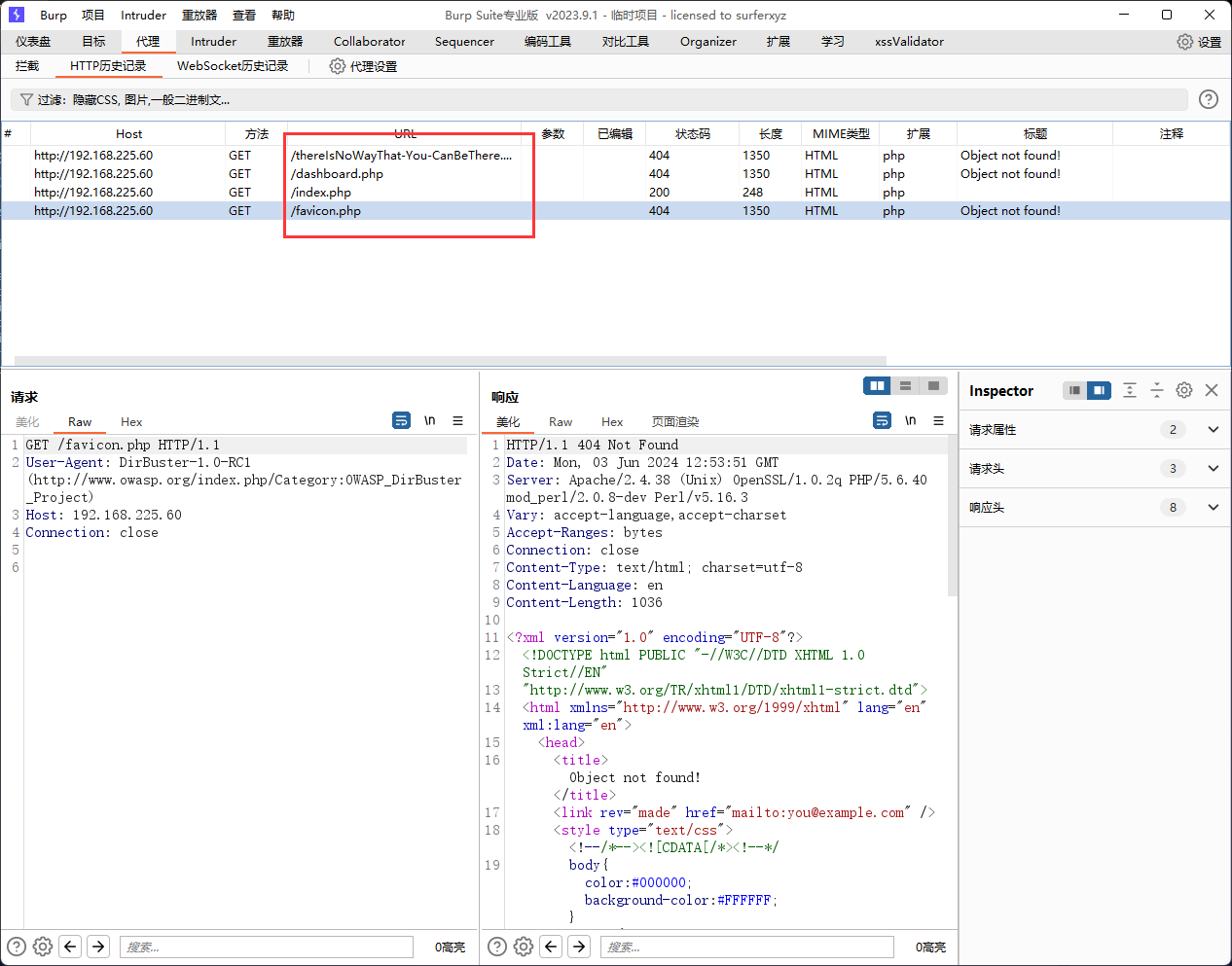
如果我们再勾选上面的使用空白后缀名的功能的话,扫描器就会多发送一组不带后缀名的请求。

流量是这样的。

同时使用两种不同的后缀,这会大大增加我们爆破的成功率。
(7)、定义文件扫描范围
这里还增加一个文件扫描范围,只要我输入任意字符,它就会扫描指定目录下的文件。
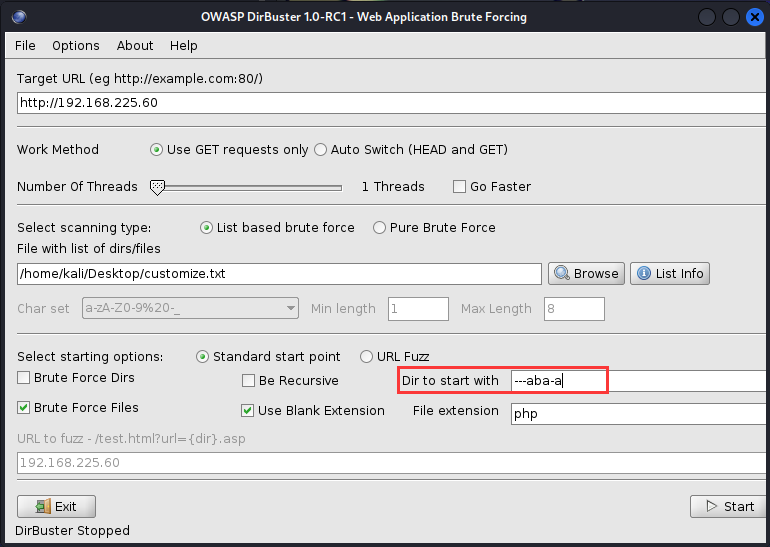
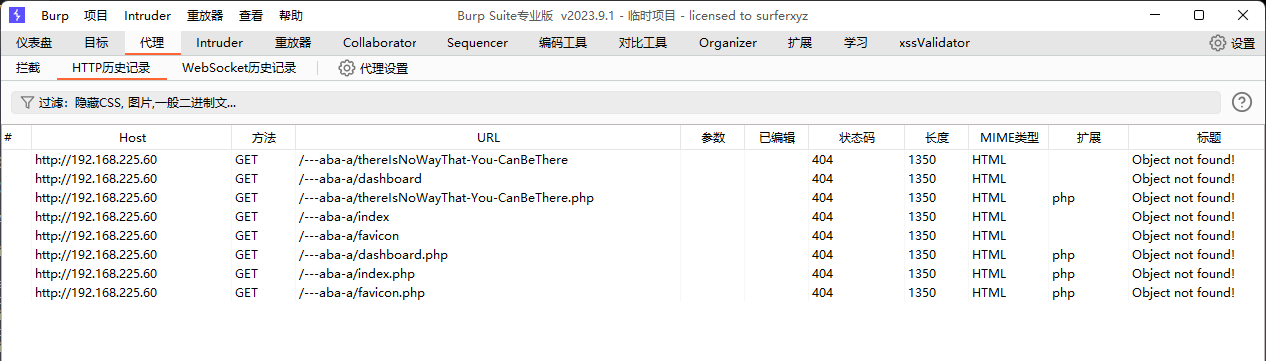
(8)、请求方法
请求方法有两种模式,一种是只使用get请求,另外一种是get和head两种来回切换。
那么head和get请求的差别是什么呢?
get请求获取响应的所有内容,而head请求只获得响应头。举例来说,get去商店买电视,把价格参数说明书和电视全都拿回来。而head只拿回价格参数说明书。
我想,使用head是为了节省时间吧,但我不明白它自动切换的机制是什么。
于是笔者设置了一个实验,在目录扫描中开启爬虫模式,然后分别使用get和head,看看两者的区别。
[一]、Only get模式

[二]、Auto Switch模式

对比两个扫描的结果并没有什么差别,但是流量差别会很大,这里笔者提出一个猜想,在autoswitch模式,dirbuster会先使用head去探测文件是否存在,而后使用get请求再去请求,为了测试这个效果,我们修改字典文件如下,并且只进行文件爆破,
a.php #不存在的文件,应该只会head请求
b.php #不存在的文件,应该只会head请求
.htaccess #存在的文件,应该先发head请求,再发get请求
index.js #存在的文件,应该先发head请求,再发get请求
index.jsp #存在的文件,应该先发head请求,再发get请求
上面的字典文件是根据服务器上的目录来做的。
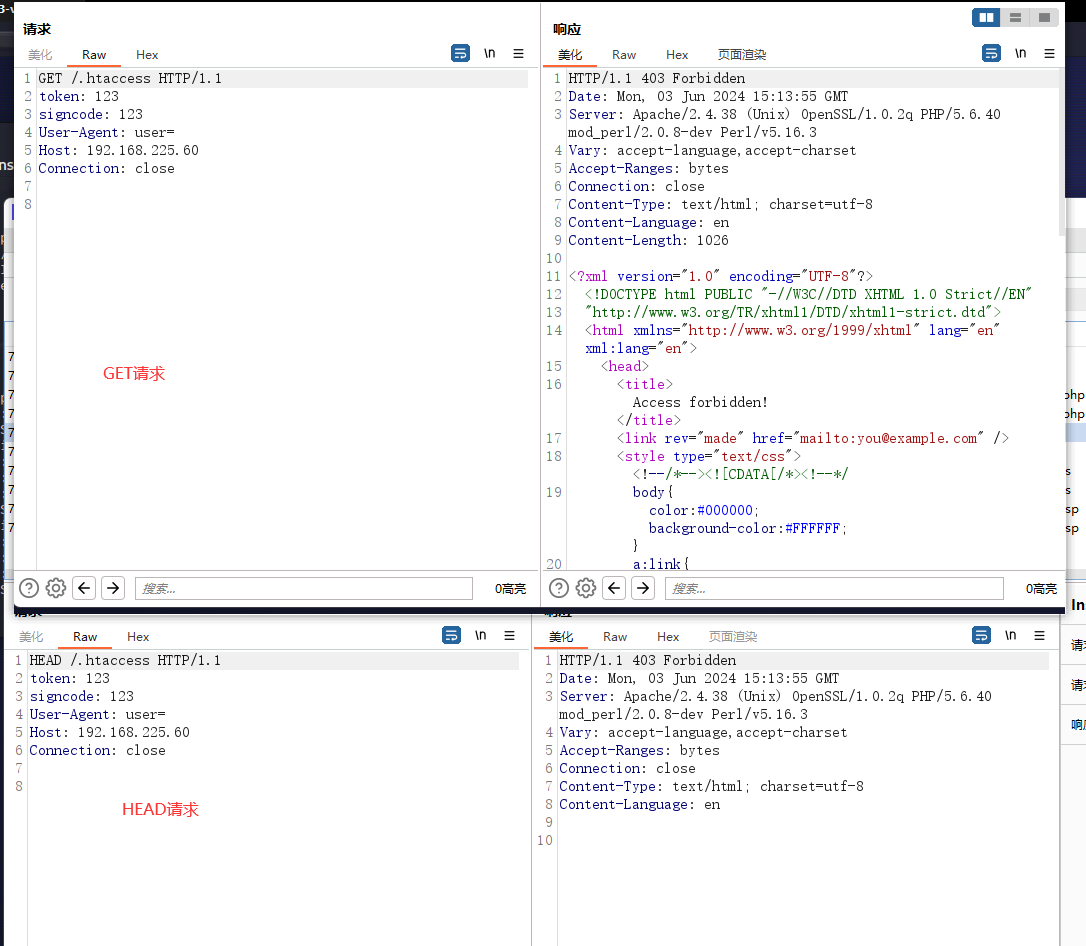
下面的流量证实了我们的猜想。

并且我们明显看到head和get请求的区别,以.htaccess文件为例子,在head的响应中长度只有292,并且没有标题,虽然响应码是403我们也知道这是什么意思。在get响应中包的长度就达到了1340,返回了所有的html信息。
所以在这里推荐使用auto模式,效率上更快速一些,如果在爬虫模式下,每个无用的404都要被解析的话,可能会浪费很多时间,虽然不知道dirbuster是否会解析404中的html链接数据,但从理论上来说,auto模式更快一些,这里就不测试了,因为速度现在不是我们最关心的问题。
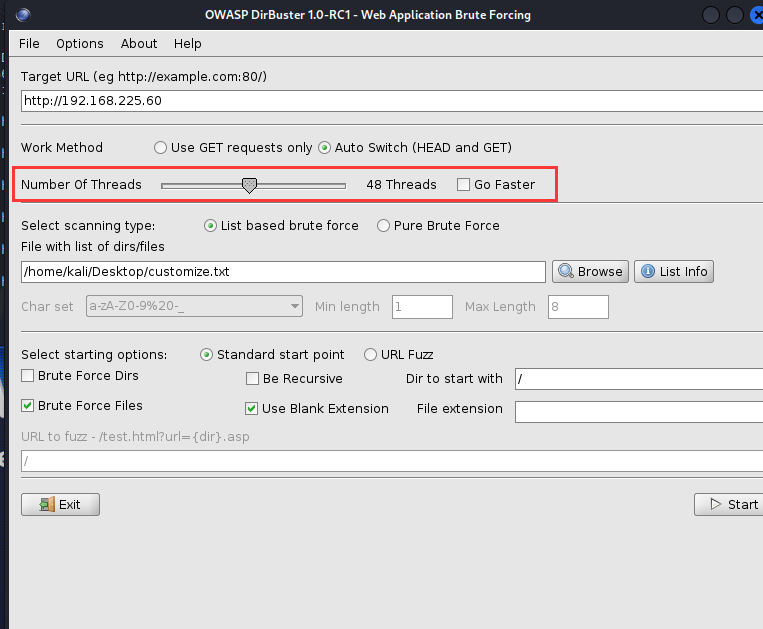
(9)、线程
这玩意就是让你扫描的更快,可以理解为一个线程就是一个小人在帮你扫描,十个线程就是十个小人在帮你扫描,关于线程和进程的概念我已经有点模糊了,所以我的解释可能不太正确,但是这个功能就是让你的扫描更快。
线程越多,扫描越快。
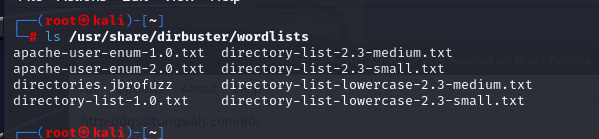
(10)、字典
前面说到dirbuster弄了很多字典,这些字典存放在哪里呢,点开字典选项旁边的list info就会得到完整的信息,可以根据情况按需选择。
/usr/share/dirbuster/wordlist

(11)、Fuzz
还有fuzz模式可以在字典前后添加任意参数来扫描。
但是fuzz其实可以用burp来做更合适,burp有更多功能。
不了解什么是fuzz的同学可以参考这篇文章。
参考文章:什么是模糊测试(含示例) (freecodecamp.org)
但说实话,笔者到现在没有很分的很清楚fuzz和字典爆破的区别,可能是fuzz的范围更广一些吧。现在一个能接受的解释是,fuzz指的是所有乱七八糟的数据,比如1000个字符那么长的a,或者是100个空格,或者是其他乱七八糟的异形字符串,而
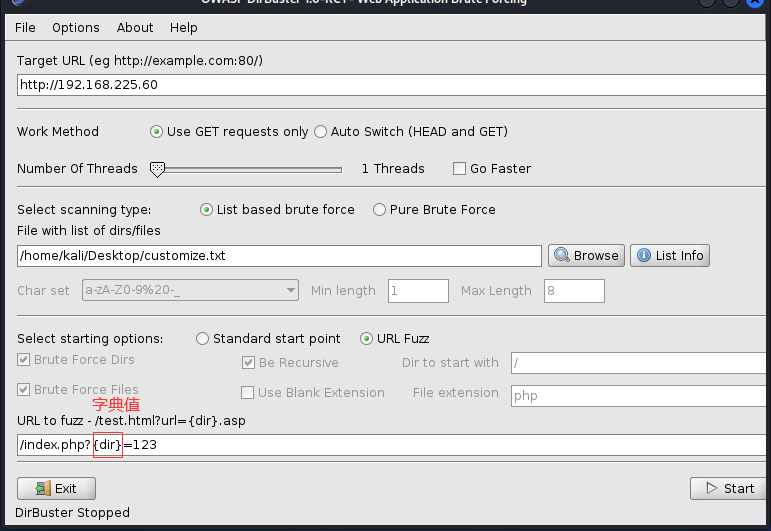

(12)、其他参数设置
此处还有其他options可设置,有我们上文提到的parse html,意思是解析html页面中的链接,说白就是爬虫。
follow redirects,就是说当遇到重定向时会向重定向的网址重新发送请求,这一点比dirb好,它是不会跟随重定向的,也可能是我没找到?
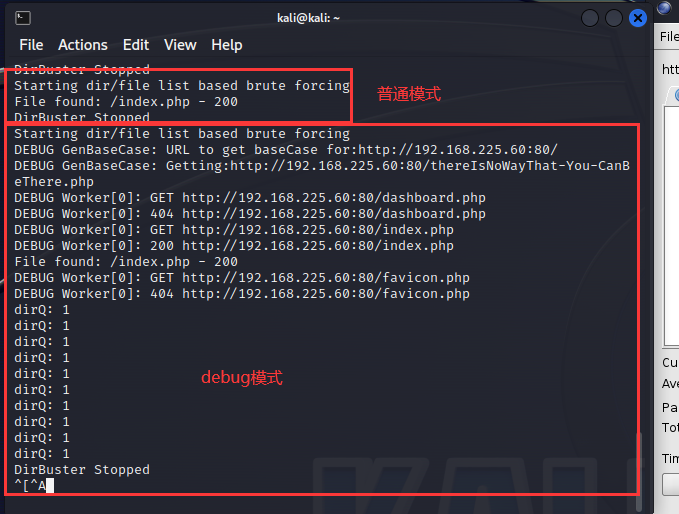
还有debug mode,用来显示详细的dirb工作流程,可以在下图看见普通模式和debug模式的差别。
look&feel是用来给界面换外观的,可见dirbuster设计之用心,太感动了555,好产品给五星。
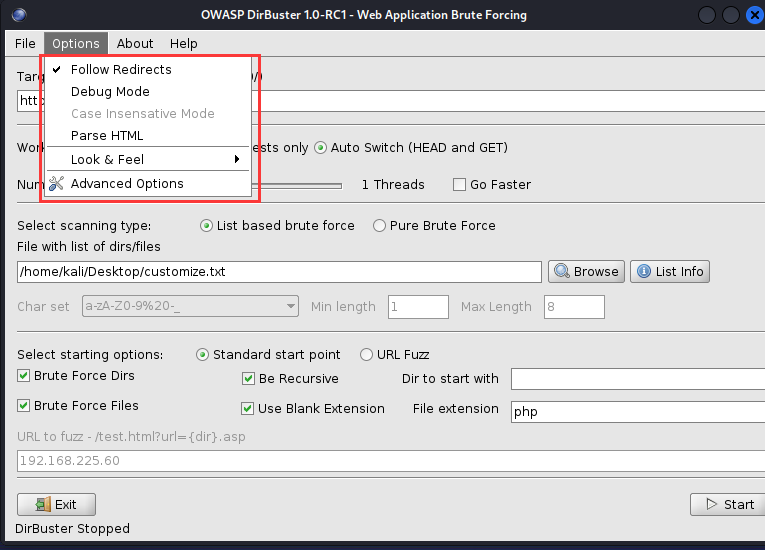
(13)、高级参数设置
[一]、间隔时间设置
此处设置每秒最多发多少个包。

[二]、头部信息设置
此处设置各种头部信息。
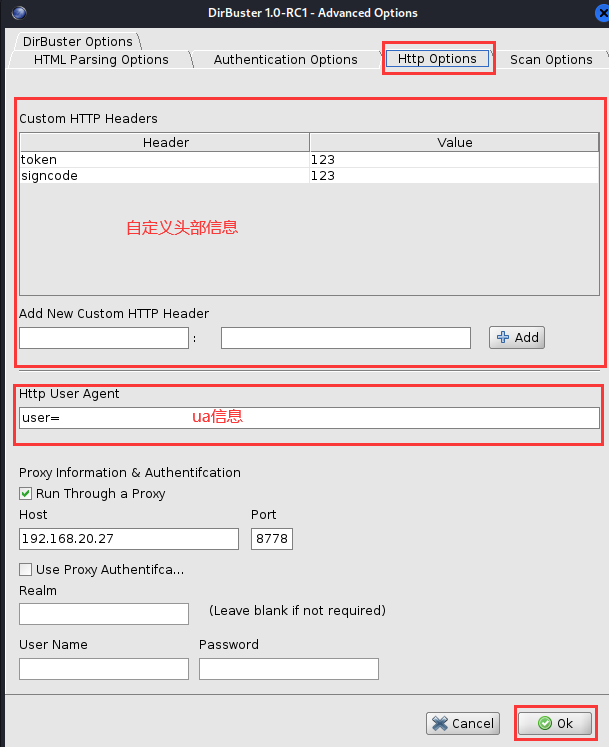
流量显示如下。
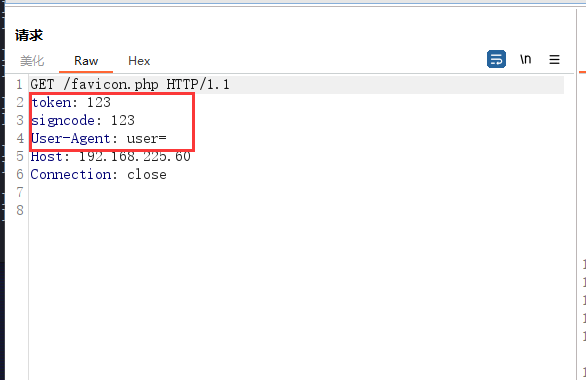
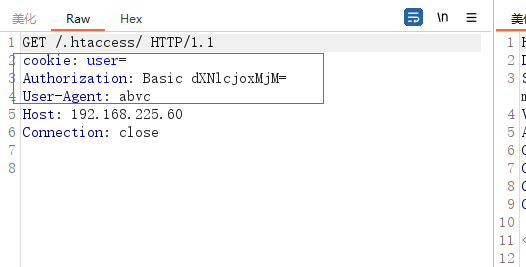
还可以设置http认证信息。

在测试时,笔者发现dirbuster并没有在每个请求头中都携带basic认证头,经过一番实验后发现,需要网站开启basic认证之后,dirbuster接收到401的信息,才会在下一次请求中携带basic认证字段。
关于服务器如何开启basic认证,可以参见dirb中的详细说明。

感觉这样有些麻烦,而且浪费我们的时间,如果我们知道网站要认证,那就直接把认证信息带上,不然我们就要花两倍的时间来做同样的事情。
所以笔者的建议是,遇到这样的网站我们直接使用头部信息字段将认证值写入进去,像这样。
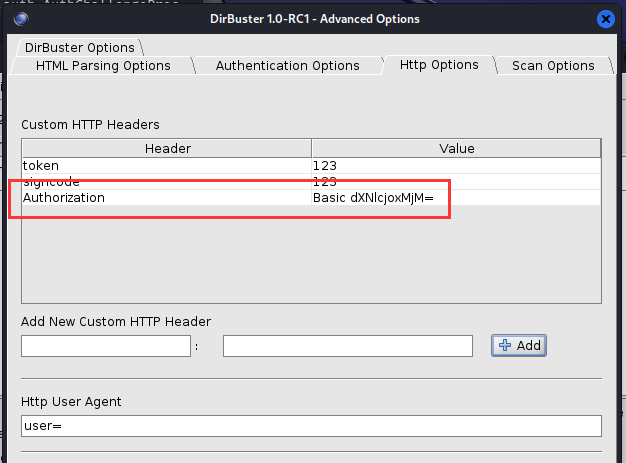
这样无论如何它都会携带我们的认证字段了。
(14)、生成报告
扫描结束之后,会有一个report的按钮给我们一份报告,我们来看看这些玩意如何。
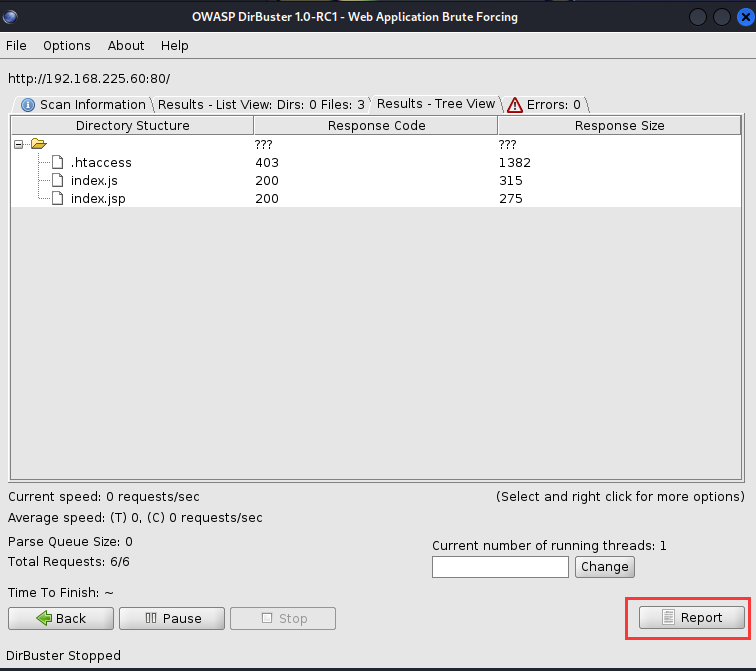

生成了四种不同格式的,但是对我来说没什么区别,这个功能可能要和一些支持xml或csv的分析工具一起使用才好。

个人觉得直接看前面的小目录树就很好,唯一的缺点是小目录树无法保存,但是因为我们吧流量引入到burpsuite上了,所以burp会替我们完成这个工作。
2、反爬和Cookie&Basic认证下的实验
在centos7靶场下,我们开启cookie,basic认证以及ua检测。
如何开启这些,详见dirb章节中的设置。
都开启好之后我们使用自定义字典进行扫描,字典内容如下。
a.php
b.php
.htaccess
index.js
index.jsp
扫描参数配置如下,相关的认证头没有配置。

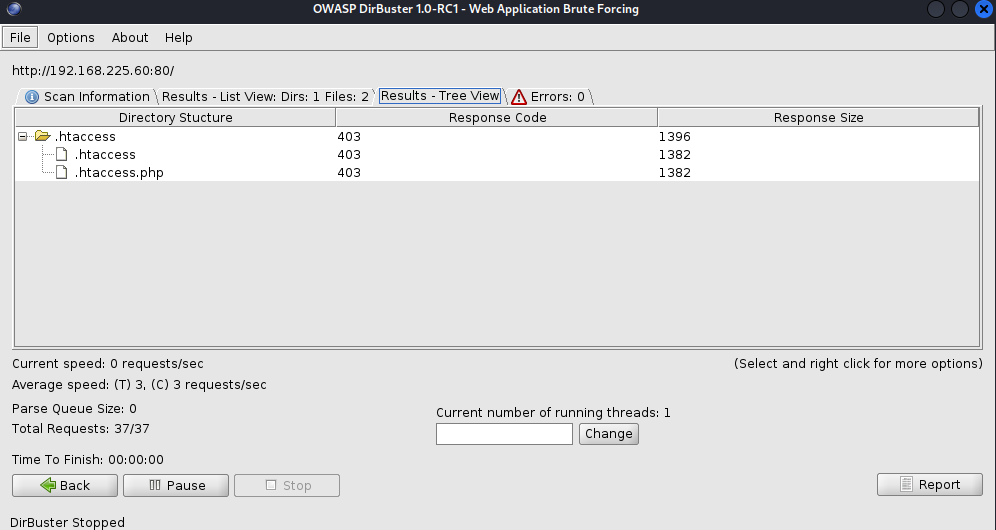
扫描结果如下,非常的不准,因为访问.htaccess.php也遭到403,所以它认为存在这两个文件,并且将.htaccess认定为文件夹。
其他的index.js和index.jsp由于401,直接就不显示了。

所以说扫描结果不能够全部相信,我们需要观察流量来判断会更准确一些,但是先不管这些,让我们为请求加上应该有的字段再试试。
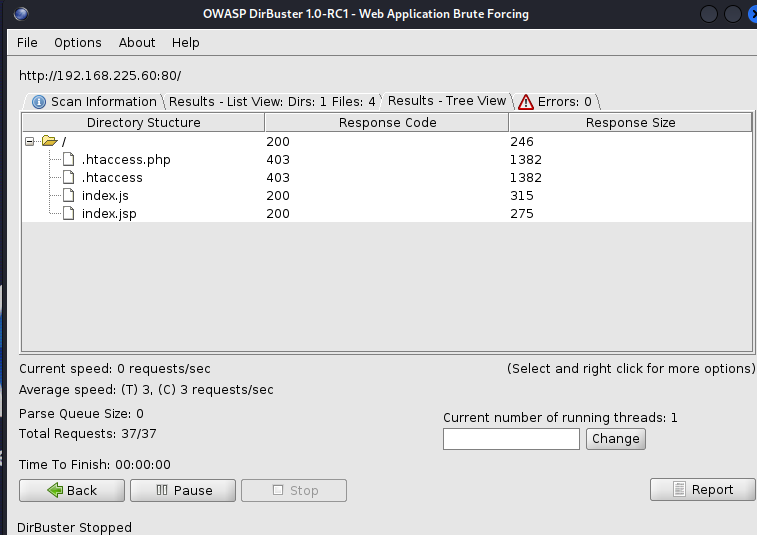
扫描结果正常,可以扫描出index.js以及index.jsp文件。需要注意的是,有些敏感文件,如.htaccess即使不存在于服务器,也会回显403无权限访问。这可能是因为配置文件中的设置。
三、Dirb实战
1、公网环境下的目录扫描
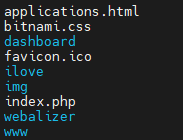
某个公网环境的根目录下存在这些文件和文件夹。
使用如下配置参数进行扫描,字典文件如下。
favicon.ico
.htaccess
index.js
index
img
扫描结果非常惊人。
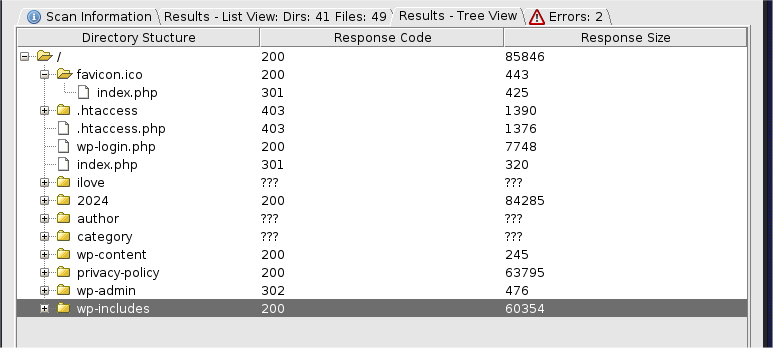
我怀疑这一切都是爬虫模式的功劳,让我们关闭爬虫模式重新扫描,果不其然,扫描结果大相庭径。

四、总结
我们了解了dirbuster的各种用法,分别是:
- 设置代理
- 设置
ua头 - 设置
http认证模式 - 爬虫模式
Fuzz模式- 文件爆破和目录爆破
- 线程数设置以及每秒请求包数量限制
还了解了dirbuster的扫描原理:
- 递归请求文件中的字典
- 可以跟随重定向
- 可以爬取返回的
html中的链接 - 可以使用
autoswitch模式增加扫描速度
总的来说,当我们使用dirbuster时,我们推荐下面的配置。

并且打开重定向和爬虫。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号