PWN-堆基础知识
堆
什么是堆
堆是用于动态内存分配的一个区域
堆:
- 是虚拟地址空间的一块连续的线性区域
- 提供动态分配的内存,允许程序申请大小未知的内存
堆管理器:
- 在用户与操作系统之间,作为动态内存管理的中间人
- 相应用户的申请内存请求,向操作系统申请内存,然后将其返回给用户程序
- 管理用户所释放的内存,适时归还给操作系统
#include<stdio.h>
int main(){
int n;
scanf("%d",&n);
void * ptr = malloc(n);
}
比如上述代码中,在分配空间前,不知道所需要空间的大小(n)。此时就需要进行动态内存分配。实现这样的区域就是堆。
需要区分堆和堆管理器
堆如上。堆管理器是动态链接库中的代码,由链接库实现,封装了一些系统调用,为用户提供方便的动态内存分配接口的同时,力求高效地管理由系统调用(brk、mmap)申请来的内存。
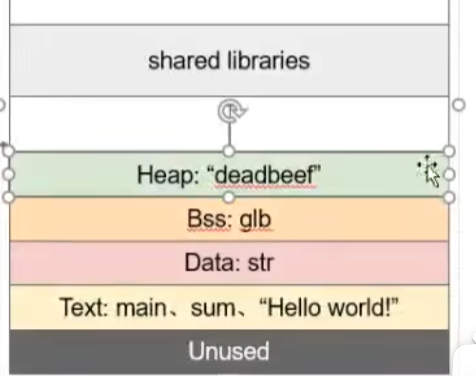
brk:
break的缩写。由于堆的下方是data段,data段有一个末尾,这个末尾可以称为break,也就是结束的地方。主线程所用到的堆的内存分配,都是brk内存调用,直接从data段上扩展而来。每调用一次brk,data段就向上扩展大一点,堆内存就不断增长。由于堆申请的是物理内存,所以堆中虚拟内存中的页(4kb)与物理内存有映射关系
mmap:
hared library实际上是mmap段。mmap是memory map的缩写,翻译成内存映射。
动态链接总是存放在物理内存的一部分。对于新申请的内存空间,我们先在这部分物理内存中开辟空间,再映射到虚拟内存空间中。
mmap还可以实现磁盘映射到虚拟内存空间
所以堆不仅可以通过data段向上增长得到,还可以在物理内存中申请一大段空间再映射到mmap中
主线程可以用brk和mmap,子线程只能用mmap。主线程如果申请空间过大则用mmap,过小则用brk。
堆管理器有各种:
dlmalloc - General purpose allocator
ptmalloc - glibc (linux使用的)(g是gnu的首字母)
jemalloc - FreeBSD and Firefox
tcmalloc - Google
libumem - Solaris
分配内存的过程
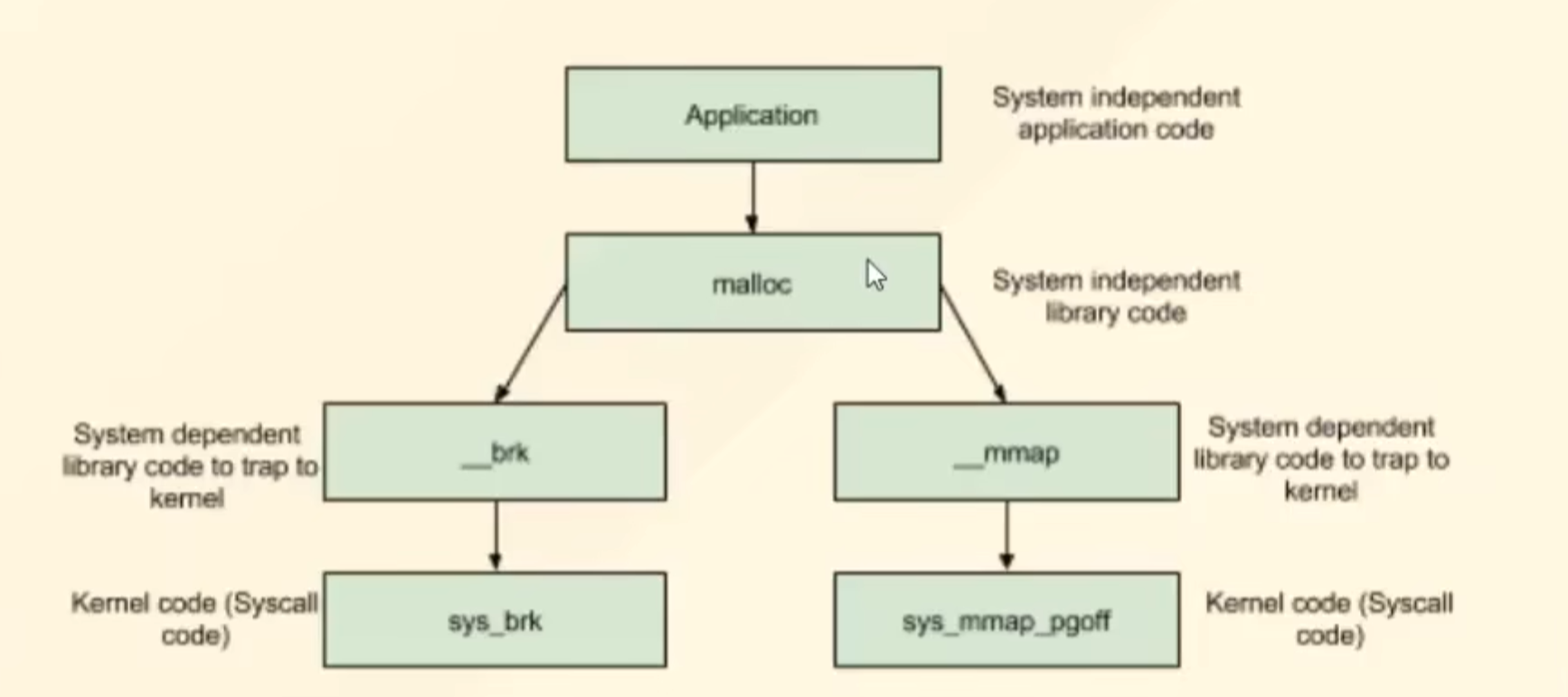
malloc:软件向堆管理器要内存
brk / mmap:堆管理器向操作系统要内存
sys_brk / sys-mmap:执行系统调用
堆管理器是如何工作的
三个关键词
arena
内存分配区,可以理解为堆管理器所持有的内存池
操作系统 --> 堆管理器 --> 用户
物理内存 --> arena --> 可用内存
堆管理器与用户的内存交易发生于arena中,可以理解为堆管理器向操作系统批发来的有冗杂的内存库存,堆管理器再将内存零售给用户
一个进程由多个线程组成,所以可以有多个arena
进程对操作系统来说是资源分配的基本单位。每创建一个进程,操作系统就会创建一个虚拟内存来描述结构,并且分配一个进程号。
线程就是把一个进程分成n份(近似)同时进行。类比肽链的生成。
主线程在data段的上方申请了堆,堆这个段会将他申请的这部分内存组合成一个arena。这个分配区会有一个arena对应的控制结构来描述这个分配区的相关信息
chunk
(以下图均为上方低地址,下方高地址)
allocated_chunk
用户申请内存的单位,也是堆管理器管理内存的基本单位,malloc返回的指针指向一个chunk的数据区域
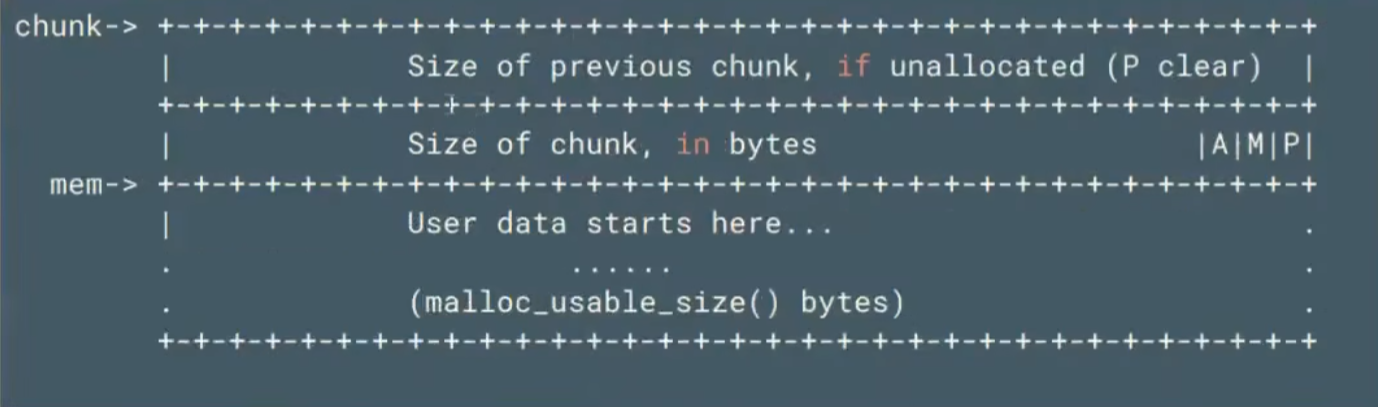
chunk是我们直接malloc得到的一块内存单位,是内存分配的最小单位。
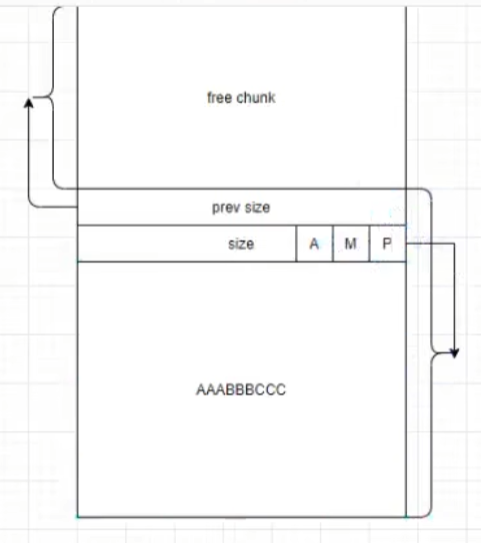
malloc的chunk包含头部会有两个字长的控制信息和数据体。由于至少有两个字长的控制信息,所以chunk大小至少为两个字长(32位下8字节,64位下16字节)
prev_size: 与之物理相邻的上一个chunk。如果上一个是free_chunk,则记录free_chunk的大小。
size: 记录了整个chunk,包含数据体和控制信息,的大小
在size的低三比特,会有控制字段。由于chunk的大小不能小于8字节,所以记录chunk大小的二进制数后三位一定是0。 于是可以将这三个0利用起来,对应的控制信息分别是A M P。A代表是否是主线程arena分配的, M代表是否是mmap的,P代表上个是否是free_chunk(放到fastbin中的freechunk P依旧是 1)
当free掉这段区域的时候,这段chunk的结构会发生改变,但并不会直接消失,而是在堆管理器中,以备用户的不时之需。因为用户free的内存来自堆管理器,也归还给堆管理器。目的是减少使用系统调用的次数,提高效率( 同setbuf(stdin, 0) )
分配过程实例
在64位系统下,我们通过malloc申请0x100大小的空间,gdb调试得到堆地址如下
int main(){
void* ptr = malloc(0x100);
free(ptr)
}
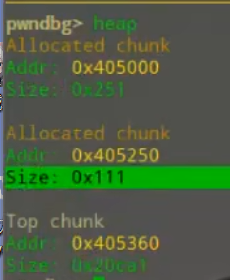
由于其他两个堆是程序分配给输入和输出的缓冲区。但为什么分配的空间是0x111?
我们考虑这里的控制信息结构。size部分因为包含了控制信息,所以是0x100 + 0x08 * 2 = 0x110。 A=0,M=0, P=1。由于AMP是size部分的低三位,程序在读取size的时候,会直接读取整个字长,导致得到的数字最低位是1,最终是0x111。
也就是说,64位系统下,堆地址的末尾一定是0或8。而AMP部分会相应增长1/2/4或其组合。
指针域指向的是数据区

系统分配的0x21000大小的堆空间,这就是arena
在图1中可以看到,有一个top chunk。它的大小是arena中剩下的所有空间。由于chunk是堆管理的最小单位,所以分配剩下的空间也要用chunk结构管理起来
prev size复用
假设malloc了一段0x20的空间,结构如下

现在将其free掉,还到了堆管理器中
然后又malloc一段0x20的空间。此时堆管理器会寻找有没有合适的free_chunk。如果有就用这一段,如果没有再找操作系统要。所以我们得到的仍然是这段chunk
那如果malloc一段0x28的空间呢? 我们仍然得到的是这块空间,并且将紧邻下方的prev size用于空间的扩充
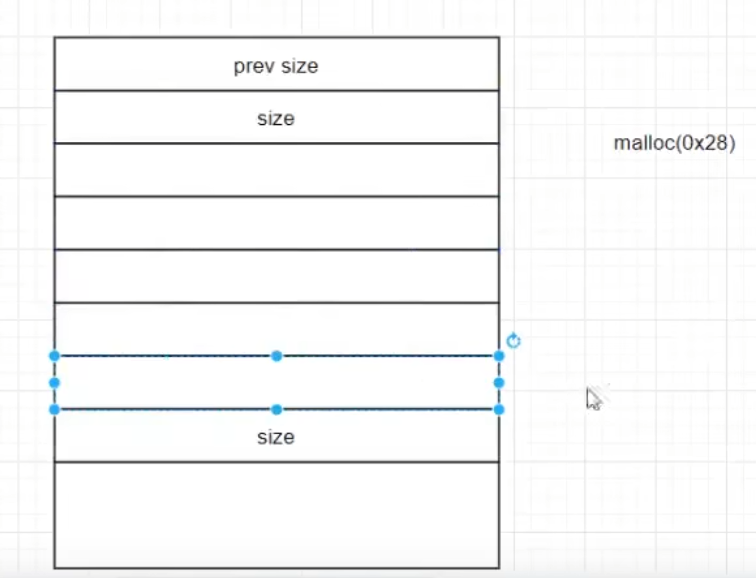
因为这段既然已经作为allocated chunk了,下方的prev size就失去了作用
所以malloc(0xn8) 和 malloc(0xn0) 所分配到的空间是一模一样的,都会造成prev size复用
物理链表与逻辑链表
物理链表
通过prev size可以连续获得上一个free chunk的大小。这一个个的prev size就形成了一个物理链表
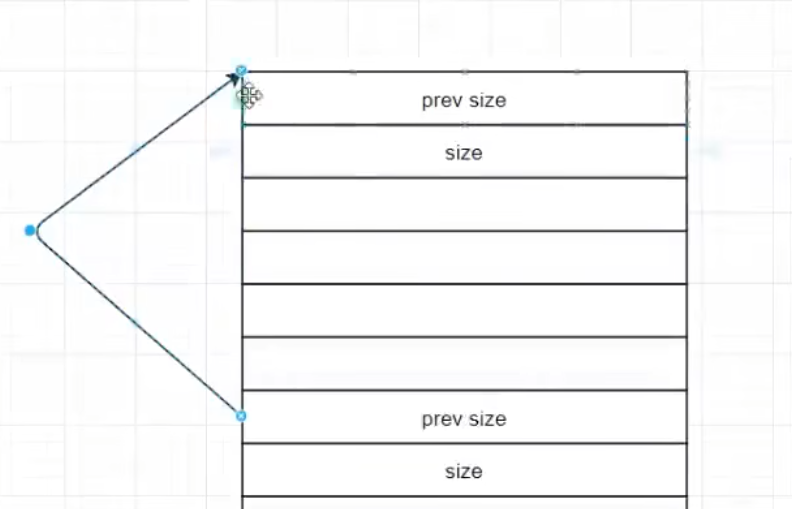
逻辑链表
free_chunk
small_free_chunk & unsorted_bin_free_chunk
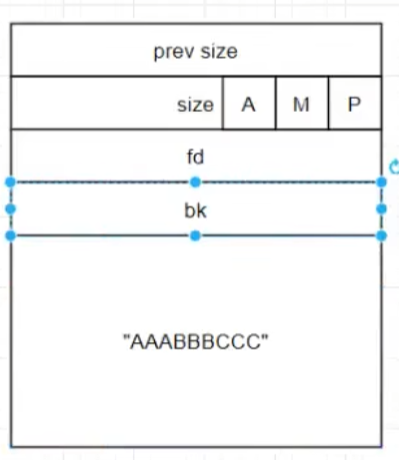
比起malloc_chunk多了两个指针fd(forward)和bk(backward)。这两个指针将不同的free_chunk连接成一个逻辑链表
这个P记录了前一个 chunk是否是malloc_chunk。如果是0则是free_chunk, 反之为malloc_chunk。因为在释放chunk的时候,会检查P是否为0。如果是0的话代表前面一个chunk也是一个free_chunk,不是in-use状态中。
此时free当前chunk,会产生两个物理相邻的free_chunk,此时就不 需要两个控制结构了,于是就会和上方的free_chunk合并起来。即size大小变化,数据区没有抹除掉。
fast_bin_free_chunk
只有fd没有bk了

为了保证速度,fastchunk不会合并
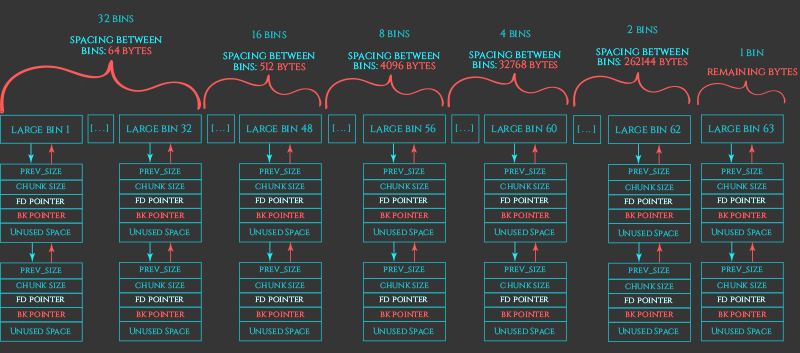
large_bin_free_chunk
会多两个控制字段

chunk在glibc中的实现

top chunk
本质上就是一个没有被bin管理起来的庞大的free_chunk。一个arena只有一个top_chunk,所以由arena管理。所以free掉与top_chunk相邻的chunk的时候,会直接发生合并。
bin m
管理 arena 中空闲 chunk 的结构。
以数组的形式存在,数组元素为相应大小的chunk链表的链表头
存在于 arena 的 malloc_state 中
unsorted bin
是双向链表
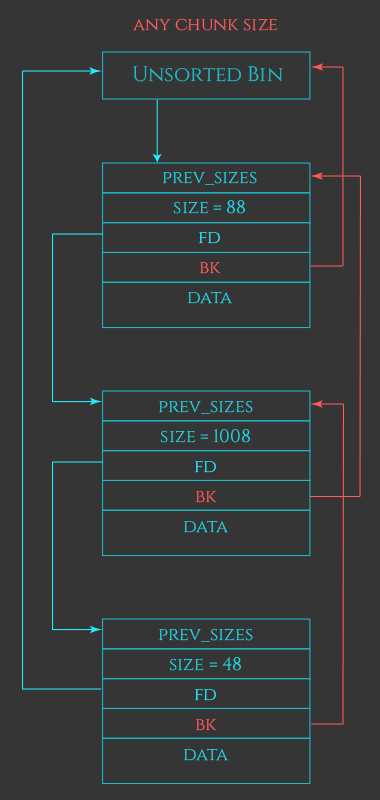
当malloc一个很大的chunk的时候,会先查找unsorted bin,再找large bins。如果都没有的话就会发生合并。物理相邻的unsorted free chunk就会合并。
fast bins
是单向链表。除了fast bins 和 tcache都是双向链表
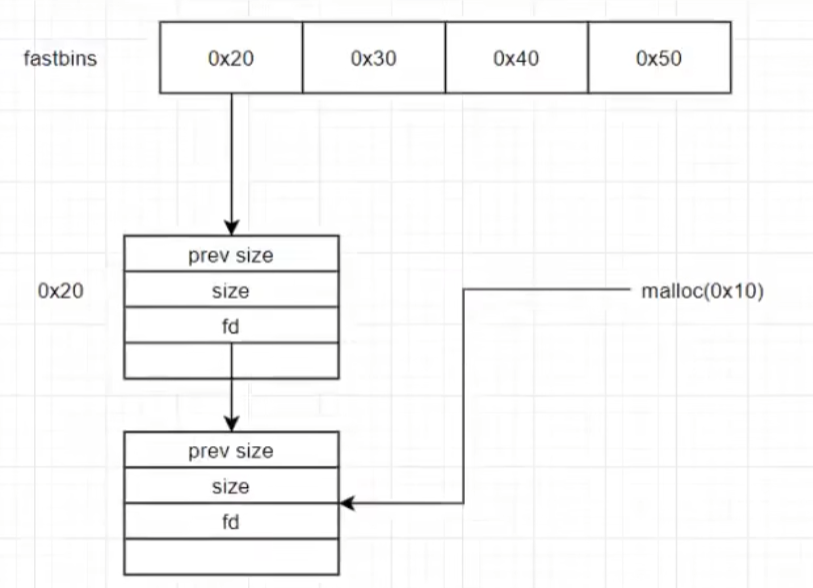
用fd不断指向前方free_chunk构成逻辑链表。逻辑链表把同类的free_chunk串起来,然后放进回收站里
相邻的freechunk整合形成物理链表
注意malloc指向的是数据区,而fd指向的是真正的chunk头
fastbin和smallbin的大小由重叠。其实smallbin是可以变成fastbin的。但此时bk没有作用
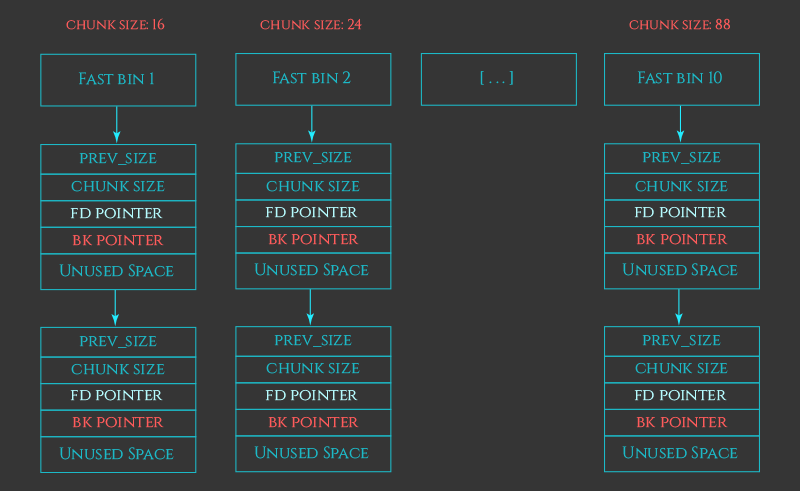
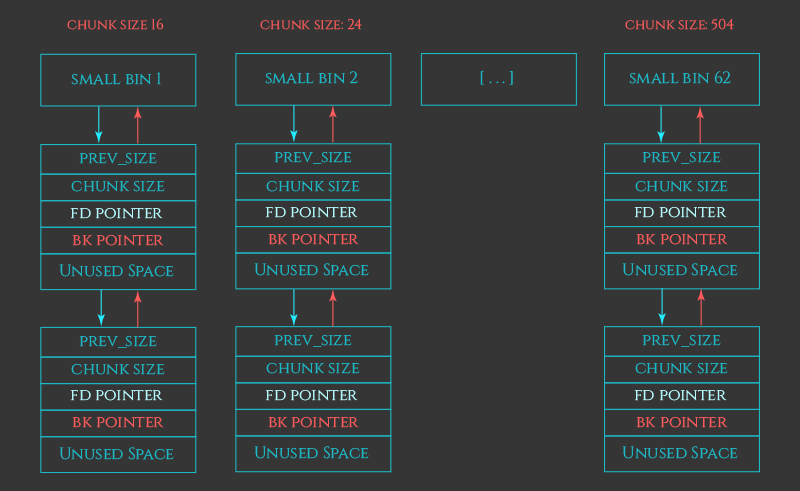
small bins
large bins
tcache
tcache可以看作是一个super fastbin。也就是说速度比super fastbin
tcache的工作模式和fastbin类似,也是一个单向链表。在freechunk存放在fastbin之前,会优先存放在tcache。并且tcache也会存放一些特定范围的bins
2.26和2.27的libc中,tcache没有double free检查。后面就有了
fastbin比起tcache多了一个检查:列入fastbin的chunk的大小是否符合规定
总结
首先,对于不同chunk的大小分配到不同的bin中,若大小为16、24、32、40、48、56、64 Bytes 的 free chunks则进入fast bin,其余的进入unsorted bin中
其次,进入到unsorted bin中的free会根据用户的需求进行分类,若未存在满足需求的会触发unsorted合并(合并后如若还没有,则再向操作系统申请),分类后小的chunk进入small bin(64~504),大的进入large bin(504~无限大)
有些PPT上有的东西不想写了
具体看
https://bailan2.github.io/2021/08/14/Pwn-Heap 堆工作介绍/#Bin
学的是同一个PPT
First-Fit Algorithm
大于fast_bins的空间申请的时候,首先找unsorted_bin。没找到的话,就会触发unsorted_bin遍历,将其该合并的合并,该归类的归类。归类后再去small_bins和large_bins中去寻找。如果还没有找到的话就只能从top_chunk中划分了
在unsorted bin中寻找的过程
由于其FIFO性质,我们从头部开始遍历,向尾部依次寻找,一个一个比对里面的unsorted_bin_free_chunk与malloc的大小。只要出现了一个大小大于malloc的空间的free_chunk,就立马将其空间分配给用户。
如果在unsorted_bin中找到chunk比malloc的大,那么分配后剩下的空间形成last_remainder_chunk。它会填入相关的控制字段后,重新列入unsorted_bin中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号