

深度学习-人脸识别-数据集和制作
一、 公共数据集
1.Labeled Faces in the wild Home(LFW)
很多公司号称识别率高达99%,是基于这个数据库。数据集合偏小,此时用一个在大量数据上预训练过的模型,在这个数据集合上测试。并且验证数据包含训练数据。
2. CASIA-FaceV5
包含500个人的照片,每个人5张,共2500张照片。照片size:height 480,width 640。需要自行划分训练集测试集。内部还需要再整理(有些文件夹包含俩个人)
由于每一类的样本只有5张照片,数量太小,所以分类难度不大,进一步做优化的空间很小,仅适用于简单的练手。

介绍出处:https://blog.csdn.net/yyyerica/article/details/86757211 叁y 写了训练测试
3.CASIA-3D FaceV1
以下是数据集介绍(谷歌翻译,特别讨厌中国人的网站写英文且不提供原版中文) 数据集下载
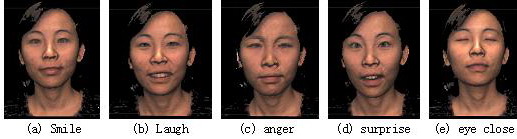
在2004年8月至2004年9月之间,我们使用非接触式3D数字化仪Minolta Vivid 910收集了一个3D人脸数据库,其中包括对46人的123次扫描,如图1所示。在建立数据库的过程中,我们不仅考虑姿势,表情和光照的单一变化,而且考虑光照,表情和姿势下的表情的组合变化,如图2,图3和图4所示。对于戴着眼镜的受试者,我们将另外收集戴着眼镜的扫描件。因此,每个人包含37或38次扫描。并且从每次扫描中,还生成一个2D彩色图像和一个3D面部三角化表面。我们旨在建立一个完整的3D人脸数据库,并进一步推动它成为测试3D人脸识别算法或其他算法的公共平台。
图1捕获CASIA 3D人脸数据库的场景
图2 CASIA 3D人脸数据库的照度变化
图3 CASIA 3D人脸数据库的表情变化
图4 CASIA 3D人脸数据库的姿势变化



4.VGGFace2
数据量比较大。有亚洲人,有欧美人.一般硬件跑起来 。下载压缩包40多G 。 解压500G 。商业应用还需要增样
5.mscebel1m
微软推出的数据集合,有一百万个人的人脸。但是整理出来标注好的只有60G压缩包图像.
6.极视角汇总的人脸数据集合
原链接失效。这边从出处 引入。极视角,是国内一家做视觉平台的公司,经常会整理某个领域论文,数据等资料。感兴趣可以微信搜索。
|
数据集 |
描述 |
备注 |
获取方式 |
|
哥伦比亚大学的公众人物脸部数据集,包含有200个人的58k+人脸图像 |
非限制场景下的人脸识别 |
链接:http://pan.baidu.com/s/1qYzDU7i 密码:fvja |
|
|
由香港中文大学汤晓鸥教授实验室公布的大型人脸识别数据集。包含有200K张人脸图片,人脸属性有40多种 |
主要用于人脸属性的识别 |
链接:http://pan.baidu.com/s/1o79BfWe 密码:4bo9 |
|
|
包含了1000多人的10000多张照片,每个人包括了不同表情,光照,姿态和年龄的照片。 |
通用人脸库 包含通用测试标准 |
链接:http://pan.baidu.com/s/1nvmmPK1 密码:snyi |
|
|
包含了将近13000张人脸图片,均采自网络。 |
人脸对齐 |
链接:http://pan.baidu.com/s/1kU4X6Az 密码:et35 |
|
|
包含了1521幅分辨率为384x286像素的灰度图像。 每一幅图像来自于23个不同的测试人员的正面角度的人脸。 |
人脸检测 |
链接:http://pan.baidu.com/s/1mh7Du0w 密码:eygl |
|
|
5k+人脸,超过13,000张人脸图像 |
标准的人脸识别数据集 |
链接:http://pan.baidu.com/s/1bpMyYcv 密码:mkhw |
|
|
该数据集所选用的人脸照片来自于两部比较知名的电视剧,《吸血鬼猎人巴菲》和《生活大爆炸》。 |
非限制场景下的人脸识别 |
链接:http://pan.baidu.com/s/1geQKw6n 密码:o92j |
|
|
该数据集中包含了来自68个人的40000张照片,其中又包括了每个人的13种姿态条件,43种光照条件和4种表情下的照片 |
非限制场景下的人脸识别 |
链接:http://pan.baidu.com/s/1o7S7YUQ 密码:jya4 |
|
|
1,595个人,3,425段视频 |
非限制场景下的人脸识别 |
链接:http://pan.baidu.com/s/1jIRAybW 密码:c27o |
|
|
该数据集包含了来自500个人的2500张亚洲人脸图片. |
非限制场景下的人脸识别 |
链接:http://pan.baidu.com/s/1bpIvkLp密码:o0ty |
|
|
该数据集采集了200个人在不同状态下(不同的神情,装扮,发型等)的人脸照片。 |
非限制场景下的人脸识别 |
链接:http://pan.baidu.com/s/1o7FaN3s 密码:0jz1 |
|
|
包含了来自123个人的4624张人脸图片 |
非限制场景下的人脸识别 |
链接:http://pan.baidu.com/s/1c1N2CLi 密码:ra7b |
|
|
包含:IMDb中20k+个名人的460k+张图片 和维基百科62k+张图片, 总共: 523k+张图片 |
名人年龄、性别 |
链接:http://pan.baidu.com/s/1hsQs8qK 密码:g74g |
|
|
2845张图片中的5171张脸 |
标准人脸检测评测集 |
链接:http://pan.baidu.com/s/1bCHtds密码:2os1 |
|
|
10k+人脸,提供双眼和嘴巴的坐标位置 |
非限制场景下的人脸识别 |
链接:https://pan.baidu.com/s/1i5y7IOP 密码:qiwn |
|
|
213张图像,10个人。每个人为一组,每一组都含有7种表情,每种表情大概有3,4张样图。 |
非限制场景下的人脸识别 |
链接:https://pan.baidu.com/s/1hrICsVq 密码:klve
|
二、自己制造数据集
这边举自己做明星人脸样本方法(老师传授)。以下逐步介绍
2.1 数据源
百度或者其它搜索引擎 选择 “图片”搜索,输入明星名字。
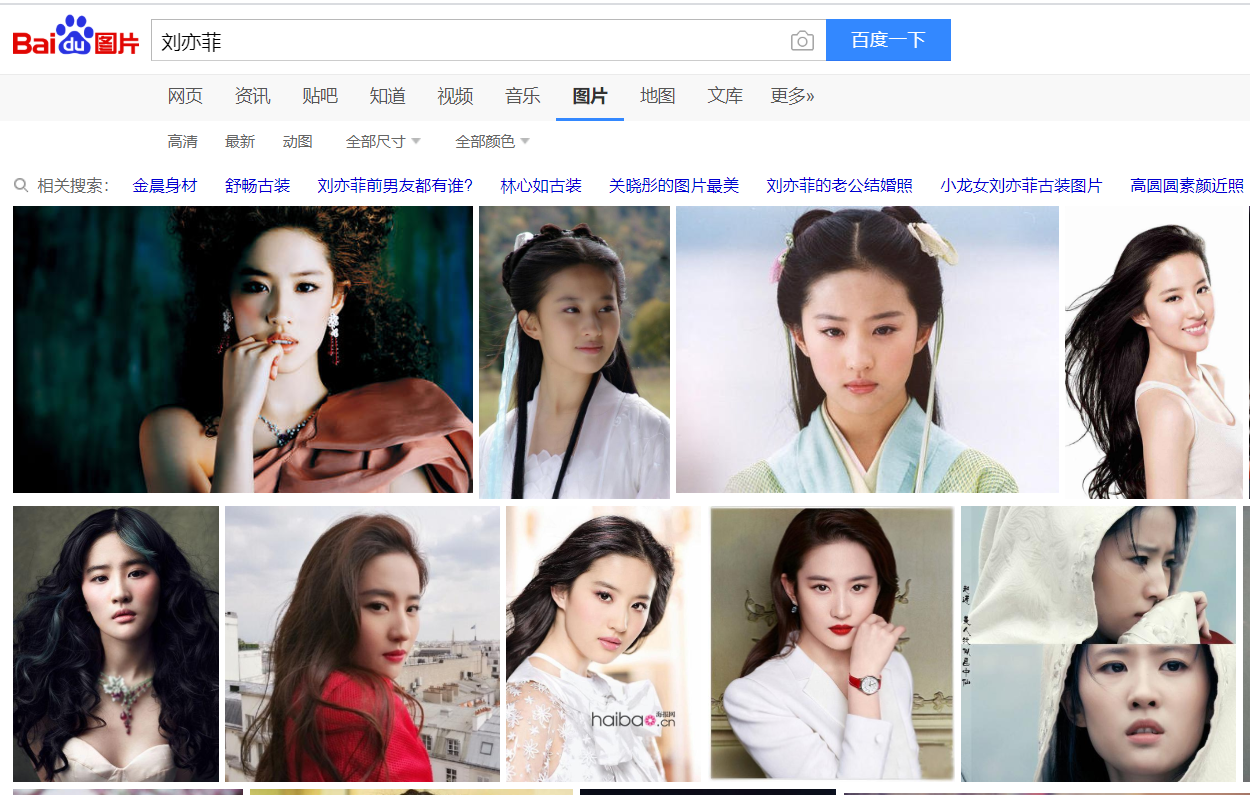
2.2 图片存储
拖拉鼠标选中你要的图片,然后右键“另存为”。选择本地文件夹
2.3 数据预筛选
去除非图片类型数据。其次去除非目标人物人脸。
2.4 人脸框选
如果没有训练好的人脸检测模型。需要下载标注助手,逐个框选人脸。
如果已经有训练好的人脸检测模型。 使用mtcnn,自动标注所有图片。然后人工过滤数据集合。
2.5数据生成
框选的时候可以是人脸最小外接框。但是处理的时候为了保持人脸一致。一般取最长边,另外以便从中心开始按最长边扩展。保持长宽比例一致。
按照文件夹名称,确定标签;按照图片顺序重命名图片名称 为 标签名_1,标签名_2 。以此生成人脸数据。这样处理之后,就能得到小规模明星人脸库。
三、硬件准备
如果上面自己制作的小规模数据。现在的一般性硬件都能跑。但是大规模数据跑起来非晶。这时候可以借助google Colab ,提供的免费云硬件。最好使用谷歌云盘存储环境和数据。避免每次登陆
Colab,环境都要重新配置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号