Day 9:Python 字符串和正则介绍总结
好像那里都是字符串?随手敲打键盘,网上copy一个句子,打开浏览器搜索什么。那么字符串的处理就很重要了。下面介绍基本字符串操作和一点儿正则表达。
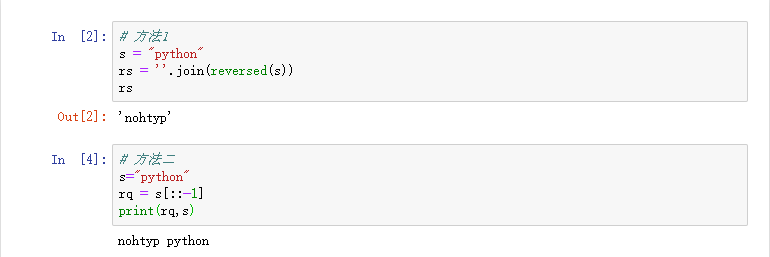
反转字符串 reversed(s) or s[::-1]
字面意思,把一个字符串按相反的顺序写出:
字符串切片操作[start:end:step]
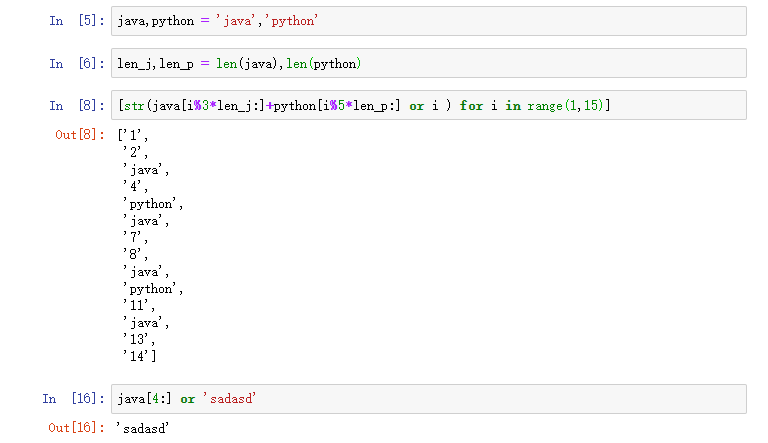
例子:生成1到15的序列,并在满足条件的索引处,替换为‘java’或者是‘python’
串联字符串 join
常常会使用到用固定的符号来串联一个字符串

分割字符串 split
有的时候我们获得了一个大的字符串,里面包含了各种数据,或者是一组数据,就想把他们分开,使用split方法。
split和join可以看作是在一定程度上的互逆操作。

替换 replace
字符串替换,使用replace方法。

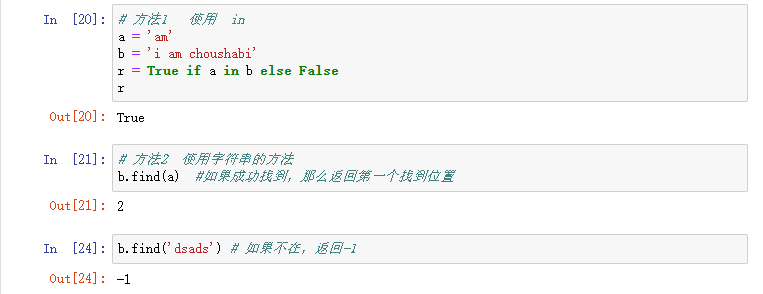
子句判断 find or in
判断一个字符串是否是另一字符串的一部分,内部函数就是两个len,然后走一个for循环就好。
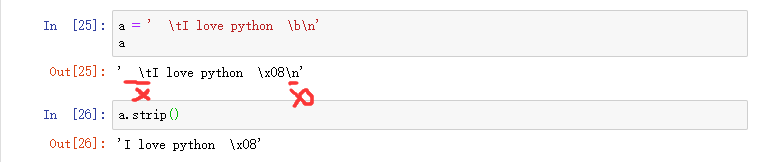
去空格 s.strip()
去空格,去头尾的空格,以达到清洗字符串。使用strip方法,清理字符串开头和结尾的空格和制表符
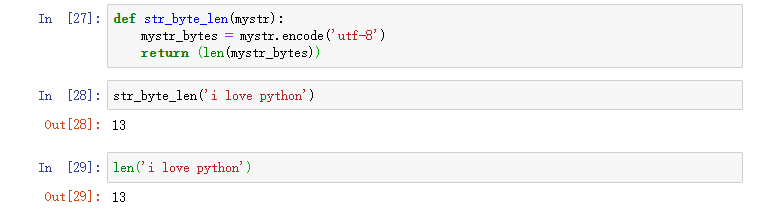
字符串的字节长度 len()
encode方法对字符串编码后,
最近看了深夜食堂,红尘世间,我裂开了
正则表达式
处理简单的字符串操作,用自带的封装办法即可达到目的,但是稍微复杂那么一点点,使用正则表达式是明智的选择,简洁强大。
re
使用正则表达式第一步,导入re模块
import re
首先,认识常用的元字符:
.匹配除 "\n" 和 "\r" 之外的任何单个字符。^匹配字符串开始位置$匹配字符串中结束的位置*前面的原子重复 0 次、1 次、多次?前面的原子重复 0 次或者 1 次+前面的原子重复 1 次或多次{n}前面的原子出现了 n 次{n,}前面的原子至少出现 n 次{n,m}前面的原子出现次数介于 n-m 之间( )分组,输出需要的部分
再认识常用的通用字符:
\s匹配空白字符\w匹配任意字母/数字/下划线\W和小写 w 相反,匹配任意字母/数字/下划线以外的字符\d匹配十进制数字\D匹配除了十进制数以外的值[0-9]匹配一个 0~9 之间的数字[a-z]匹配小写英文字母[A-Z]匹配大写英文字母
正则表达式,常会涉及到以上这些元字符或通用字符,下面通过 14 个细分的与正则相关的小功能,讨论正则表达式。
search第一个匹配串
即find(),找出第一个匹配项的位置

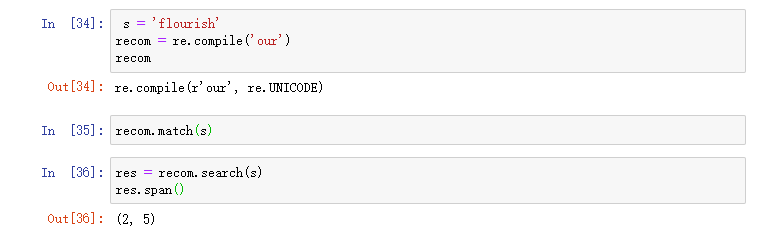
match与search不同
- match 在原字符串的开始位置匹配
- search 在字符串的任意位置匹配
match想做的事就是在开头就find,最高效,啊抓到你了!
比如,字符串 ourselves,ours 才能 match 到 our
finditer 匹配迭代器
finditer方法,返回所有子串匹配位置的 一个 迭代器。通过返回的对象 re.Match,使用它的方法 span 找出匹配位置。
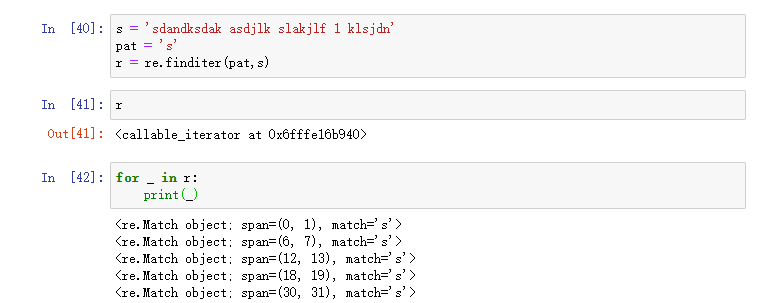
findall所有匹配
findall 方法能查找出子串的所有匹配。
下面例子,想要找出所有的数字
\d 匹配一位数字 [0-9],+ 表示匹配数字前面的一个原子 1 次或多次。

但是有个问题是,日期9.7我显然不想让他们分开,怎恶魔版?修改正则表达式。
匹配浮点数和整数
?表示前一个字符匹配 0 或 1 次.?表示匹配小数点(.)0 次或 1 次
匹配浮点数和整数,第一版正则表达式:r'\d+\.?\d+',图形化演示,此正则表达式的分解演示:


1去哪里了?没有匹配全,所以正则表达式还要改。
正则难点之一,需要考虑全面、足够细心,才可能写出准确无误的正则表达式。
匹配不到1的原因是:r'\d+\.?\d+',后面的 \d+ 表示至少有一位数字,因此,整个表达式至少会匹配两位数。
重新修改正则表达式,将最后的 + 后修改为 *,表示匹配前面字符 0 次、1 次或多次。


成功!
匹配正整数
题:写出匹配所有正整数的正则表达式。
如果这样写:^\d*$,会匹配到 0,所以不准确。
如果这样写:^[1-9]*,会匹配 1. 串中 1,不是完全匹配,体会 $ 的作用。
正确写法:^[1-9]\d*$,正则分解图:


re.I 忽略大小写(I 大写的i)
re.I 是方法的可选参数,表示忽略大小写。
如下,找出字符串中所有字符 t 或 T 的位置,不区分大小写。

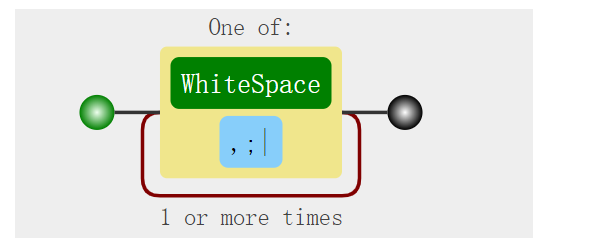
split 分割单词
对于比较复杂的分割:

正则字符串为:[,\s;|]+,\s 匹配空白字符,正则分解图,如下:
sub 替换匹配串
正则模块,sub 方法,替换匹配到的子串:

compile 预编译
到这个时候上面出现了几次compile,你是否有疑惑过,为什么指派pat的时候有时候用compile而常常不用?
如果要用同一匹配模式,做很多次匹配,可以使用 compile 预先编译串。
栗子:从一系列字符串中,挑选出所有正浮点数。
正则表达式为:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$,字符 a|b 表示 a 串匹配失败后,才执行 b 串,正则分解图见下:


案例-捕获
正则模块中,根据某个模式串,匹配到结果。
待爬取网页的部分内容如下所示,现在想要提取 <div> 标签中的内容。
content = ''' <h>ddedadsad</h> <div>graph</div> <div>math</div>'''
如果正则匹配串写做 <div>.*</div>:
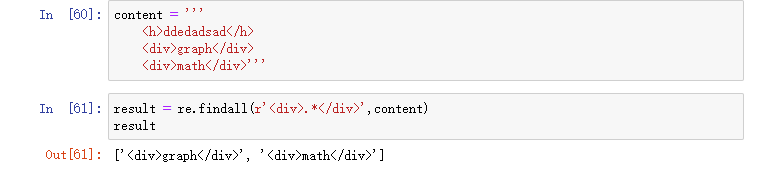
如果我们不想保留字符串最开始的 <div> 和结尾的 </div>,那么,就需要使用一对 () 去捕获。
正则匹配串修改为:<div>(.*)</div>,只添加一对括号。

- 看到结果中已经没有开始的
<div>,结尾的</div>仅使用一对括号,便成功捕获到我们想要的部分。 (.*)表示捕获任意多个字符,尽可能多地匹配字符,也被称为贪心捕获(.*)的正则分解图如下所示,.表示匹配除换行符外的任意字符。

看另一种捕获方法:
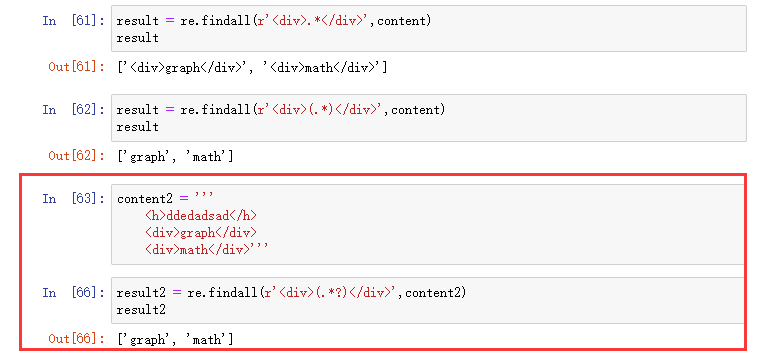
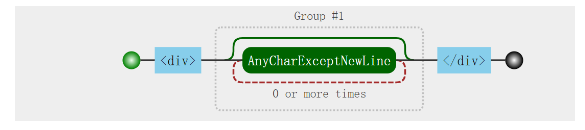
匹配模式串 (.*?),被称为非贪心捕获。正则图中,虚线表示非贪心匹配。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号