一个小技巧,让电子书阅读体验翻倍!
 如果你看电子书,这篇文章应该能帮到你。
如果你看电子书,这篇文章应该能帮到你。
如果你看电子书,这篇文章应该能帮到你。
我平时有读书的习惯(也偶尔看看网文),但我发现大部分书都没「加个空格」,对于我这个习惯了加空格的人来说,阅读体验很不好。
什么是加个空格?
简单来说,就是在中文和英文(和数字)之间,加一个空格。
为什么应该加个空格?
直接看一个段落,没加空格 vs 加个空格:

不知道你喜欢哪种,我反正选「加了空格」的 🤔。
其实这是一种很常见的规范。很多工具都会在显示内容时,自动加个空格(这种行为也叫中英混排优化)。
就比如手机上的微信,输入中英文混排的文字,发送出去后,显示时会自动添加空隙(可以理解为加了个空格):

不过,我发现电脑上的微信还没做这个功能,所以你看到的是这样的:

所以,我写文章时,会用工具自动优化排版;网上冲浪时,也会用浏览器插件优化网页排版(详见我的另一篇文章:Markdown 排版规范)。
那么读电子书时,肯定也是能优化就优化,下面就介绍几个优化方法,原理也很简单:使用正则。
下面我会详细介绍下步骤(保姆级教程)。
优化电子书排版的原理
这里介绍下原理,方便读者理解。
当然,你不看原理,直接拿来用也是可以的。
所谓正则,可以理解为是一种搜索工具。
例如,你有一篇文章,里面有很多手机号,你想将所有手机号都搜出来。
靠自己一行行去看太麻烦了,我们不妨利用手机号的规律:开头可能是 13,15,18 等数字,都是 11 位数字。
根据这个规律,就能编写出合适的正则,然后用这个正则去搜索文章即可。
不懂怎么写正则也没关系,直接让 AI 代写即可(想了解更多正则,问 AI 自学也行)。
使用电子书编辑工具
那我们如何用正则来优化排版呢?
很简单,用正则搜索出中文后跟英文字符的情况,然后替换为〝中文 空格 英文〞即可。
接下来我们来实操下。
首先,得有一本电子书。电子书类型,无外乎就这几种:TXT,EPUB,MOBI 等。
然后下载电子书编辑器,例如 Calibre(或 Sigil),然后将书籍导入(可以直接拖动文件到该软件窗口)。
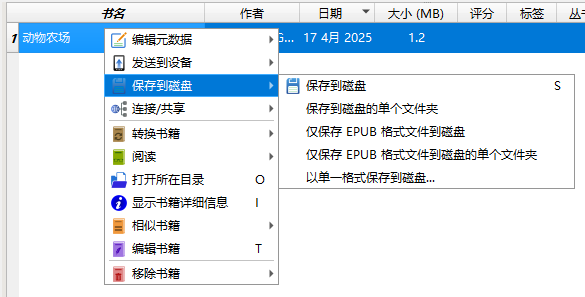
然后,选中书籍,点击右上角的「编辑书籍」:

随便打开一个左侧的文件(打开文件后,才能搜索)。
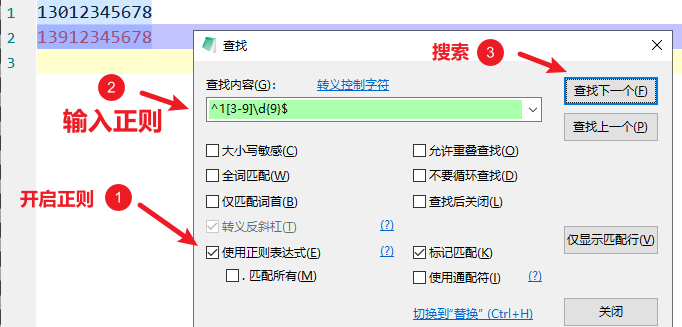
按下 Ctrl + F,打开搜索框,然后勾选 "正则表达式":

在「查找」一栏输入下面的正则表达式,用来查找中文 + 英文(数字):
([\u4e00-\u9fa5])([a-zA-Z0-9])
你可以先试着点击「查找」,可以看到确实找到了一个中文 + 英文的情况:
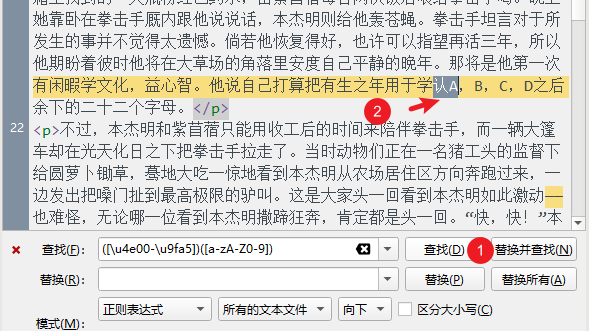
然后在「替换」一栏输入以下正则,然后点击替换:
\1 \2
替换后效果如下:

注:
\1 表示第一个字符,\2 表示第二个字符,中间有个空格,所以替换后就表示加个空格- Calibre 用的是 python 正则,所以用
\1 表示(有的编辑器用的是$1 )
同理,在「查找」一栏输入下面的正则表达式,用来查找英文在前,中文在后的情况:
([a-zA-Z0-9])([\u4e00-\u9fa5])
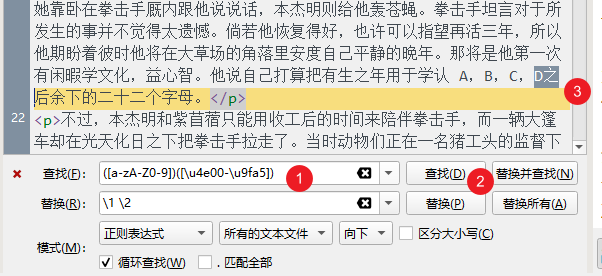
然后也是一样用 \1 \2 替换即可。
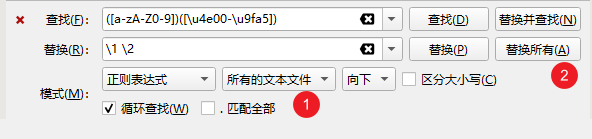
一个个去查找、替换实在的太麻烦了,我们可以直接替换所有文件,一步到位:
替换完后,可以保存书籍:

然后可以重新导出,在手机或电脑上阅读:
说了这么多,其实步骤都很简单,小结下:
- 将书籍导入编辑器
- 点击「编辑书籍」
- 打开任意一个文件,按下 Ctrl + F 打开搜索框
- 用
([\u4e00-\u9fa5])([a-zA-Z0-9]) 查找 中文 + 英文 的情况 - 用
([a-zA-Z0-9])([\u4e00-\u9fa5]) 查找 英文 + 中文 的情况 - 用
\1 \2 替换 - 勾选「全部文件」,然后替换所有
- 保存并导出书籍
如果你想处理 英文与数字之间(如 MacBookPro15 → MacBookPro 15),可用以下正则:
([a-zA-Z])([0-9])
使用 Python 脚本优化
你可能会说刚刚的步骤还是太复杂了,有没更简单粗暴的方法呢?
有的兄弟,有的。
我们可以用 Python 脚本,一行命令解决!
下面是我问 AI 要到的 Python 脚本:
import zipfile
import os
import re
import tempfile
import shutil
from bs4 import BeautifulSoup, NavigableString
# 该脚本处理 EPUB 文件:在中文和英文、数字之间添加个空格,以改善阅读体验。
def process_text(text):
# 处理中文与字母/数字之间的边界
text = re.sub(r'([\u4e00-\u9fff])([a-zA-Z0-9]+)', r'\1 \2', text)
text = re.sub(r'([a-zA-Z0-9]+)([\u4e00-\u9fff])', r'\1 \2', text)
# 处理字母与数字之间的边界
text = re.sub(r'([a-zA-Z]+)(\d+)', r'\1 \2', text)
text = re.sub(r'(\d+)([a-zA-Z]+)', r'\1 \2', text)
return text
def process_html(content):
"""处理 HTML 内容"""
soup = BeautifulSoup(content, 'html.parser')
for element in soup.find_all(string=True):
if isinstance(element, NavigableString) and element.strip():
new_text = process_text(element)
element.replace_with(new_text)
return str(soup)
def process_epub(input_file, output_file):
"""处理 EPUB 文件"""
with tempfile.TemporaryDirectory() as tmp_dir:
# 解压EPUB文件
with zipfile.ZipFile(input_file, 'r') as zip_ref:
zip_ref.extractall(tmp_dir)
# 处理所有HTML/XHTML文件
for root, _, files in os.walk(tmp_dir):
for file in files:
if file.lower().endswith(('.html', '.xhtml')):
file_path = os.path.join(root, file)
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
modified_content = process_html(content)
with open(file_path, 'w', encoding='utf-8') as f:
f.write(modified_content)
# 重新打包EPUB
with zipfile.ZipFile(output_file, 'w', zipfile.ZIP_DEFLATED) as zip_out:
for root, _, files in os.walk(tmp_dir):
for file in files:
file_path = os.path.join(root, file)
arcname = os.path.relpath(file_path, tmp_dir)
zip_out.write(file_path, arcname)
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser(description='在 EPUB 文件中添加空格')
parser.add_argument('input', help='输入 EPUB 文件路径')
parser.add_argument('output', help='输出 EPUB 文件路径')
args = parser.parse_args()
process_epub(args.input, args.output)
print(f"处理完成!输出文件:{args.output}")
使用方法:
- 先在 Python 官网 下载安装 Python
- 安装依赖库:
pip install beautifulsoup4 - 运行脚本:
python epub_space.py input.epub output.epub
此脚本后续在 GitHub 上维护:https://github.com/Peter-JXL/UserScript/
此外,如果每次都输入这样一行命令去处理书籍,还是太麻烦。
为此,我用了第三方工具 Quicker,获取文件名,然后拼接 Python 命令,然后执行:
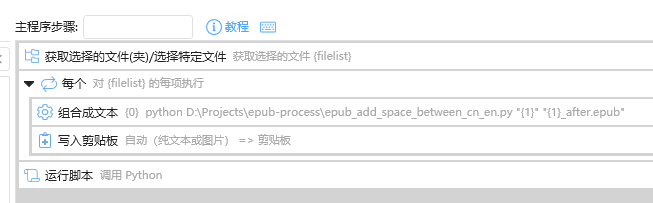
这样,即可一键完成操作。
扩展延伸
除了 Quicker,还可以用 reg 等方式,拼接 Python 命令,添加右键菜单,一键完成转换,由于懒 这里就不演示了。
除了 Python,你也可以用 JS、Java、C# 等编程语言来实现,怎么方便怎么来,有不懂的问 AI 即可。
比较遗憾的是,目前 AI 客户端还不支持处理该种文件格式,不能直接丢给 AI 处理(以 AI 的发展速度来看,应该也快支持了)
最后
AI 真的很强,本文提到的正则表达式 以及 Python 脚本,都是我问 AI 得到的。
如果是让我自己写,拖延个 200 年也不是不可能 😂
希望本文能帮到你,让你阅读电子书体验更棒 ~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号