中国大学综合排名
1、导包
from pyecharts.charts import Map, Bar, Pie
from pyecharts import options as opts
from pyecharts.render import make_snapshot
import pandas as pd
from snapshot_selenium import snapshot
2、数据清洗
# 读取数据
df = pd.read_excel("./xlsx/中国大学综合排名2021.xlsx")
# 打印前5条数据
print(df.head())
# 查看表格数据类型
print(df.dtypes)
# 查看表格数据描述
print(df.describe())
# 查看表格缺失数据
print(df.isnull().sum())
# 填充某一列缺失数据
# 填充升/降数据,以填充0为例:
df["升/降"].fillna(0, inplace=True)
# 再次查看表格缺失数据
print(df.isnull().sum())
# 一次性填充所有缺失数据
df.fillna(0, inplace=True)
# 把数据的统计信息给打印出来
print(df.describe())
# 统计所有排名未改变的学校
print(df[df["升/降"] == 0])
# 统计前50名中排名下降的学校
print(df.loc[(df["排名"] < 50) & (df["升/降"] < 0), :])
3、数据可视化
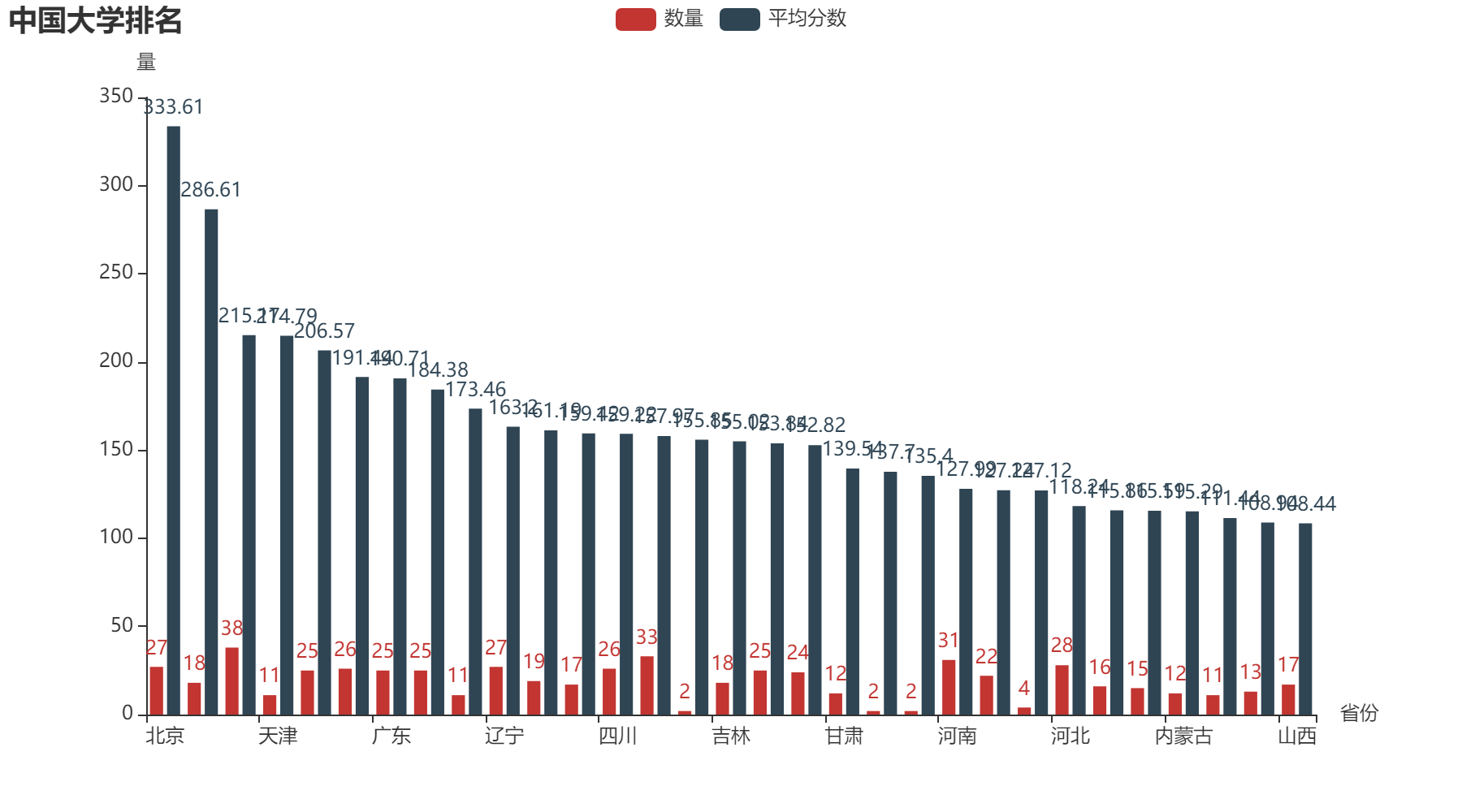
1. 各省市大学数量和平均分柱状图(横向)
# 统计各省市大学数量
df_counts = df.groupby('省市')['学校名称'].agg("count")
# 各省市大学平均分排序
df_means0 = df.groupby('省市')['总分'].agg("mean")
df_means = df_means0.round(2) # 保留两位小数点
df1 = pd.concat([df_counts, df_means], axis=1) # 重点concat数据连接axis=1按列
df1.columns = ['数量', '平均分'] # 重点设置groupby里面的行标题
df1.sort_values(by=['平均分'], ascending=False, inplace=True) # 使用平均分进行排序
# 把数据转为list类型,做图形
d1 = df1.index.tolist()
d2 = df1["数量"].values.tolist()
d3 = df1["平均分"].values.tolist()
# 各省市大学数量和平均分柱状图(横向)
bar = (
Bar(init_opts=opts.InitOpts(bg_color="white"))
.add_xaxis(d1)
.add_yaxis("数量", d2)
.add_yaxis("平均分数", d3)
.set_global_opts(title_opts=opts.TitleOpts(title="中国大学排名"),
yaxis_opts=opts.AxisOpts(name="量"),
xaxis_opts=opts.AxisOpts(name="省份"))
)
make_snapshot(snapshot, bar.render("./html/ChinaBarX.html"), "./img/ChinaBarX.png")
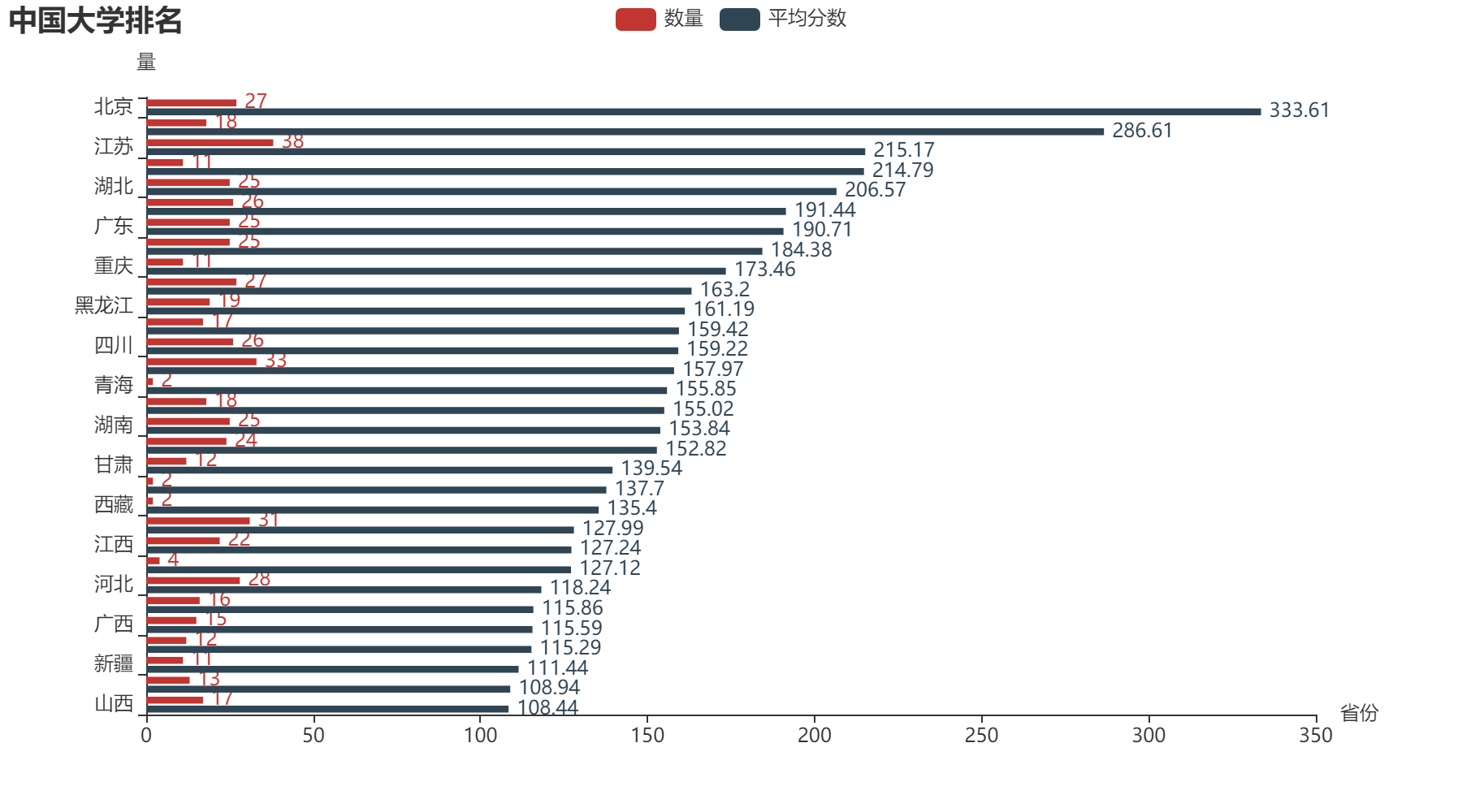
2. 各省市大学数量和平均分柱状图(纵向)
df1.sort_values(by=['平均分'], ascending=True, inplace=True) # 使用平均分进行排序
d1 = df1.index.tolist()
d2 = df1["数量"].values.tolist()
d3 = df1["平均分"].values.tolist()
bar = (
Bar(init_opts=opts.InitOpts(bg_color="white"))
.add_xaxis(d1)
.add_yaxis("数量", d2)
.add_yaxis("平均分数", d3)
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position='right'))
.set_global_opts(title_opts=opts.TitleOpts(title="中国大学排名"),
yaxis_opts=opts.AxisOpts(name="量"),
xaxis_opts=opts.AxisOpts(name="省份"))
)
make_snapshot(snapshot, bar.render("./html/ChinaBarY.html"), "./img/ChinaBarY.png")
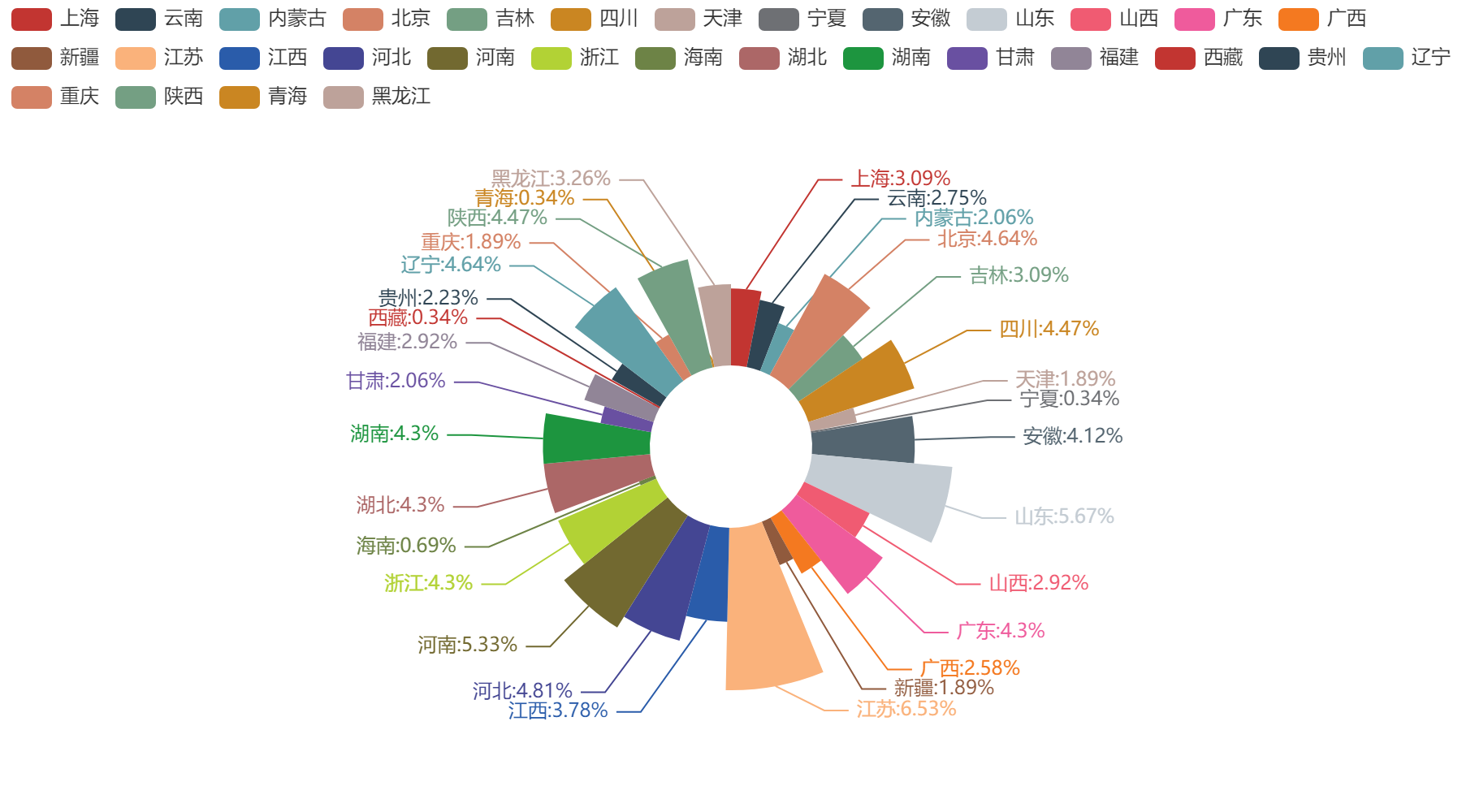
3. 各省市大学数量玫瑰图
city = df_counts.index.tolist()
num = df_counts.values.tolist()
# radius=["20%", "60%"] 饼图的半径,数组的第一项是内半径,第二项是外半径
# center=["50%", "55%"] 饼图的中心(圆心)坐标,数组的第一项是横坐标,第二项是纵坐标
# rosetype="radius" 是否展示成南丁格尔图,通过半径区分数据大小,有'radius'和'area'两种模式。
pie = (
Pie(init_opts=opts.InitOpts(bg_color="white"))
.add("", [list(z) for z in zip(city, num)], radius=["20%", "60%"], center=["50%", "55%"], rosetype="radius")
.set_series_opts(label_opts=opts.LabelOpts(formatter='{b}:{d}%'))
)
#
make_snapshot(snapshot, pie.render("./html/meiguiPie.html"), "./img/meiguiPie.png")
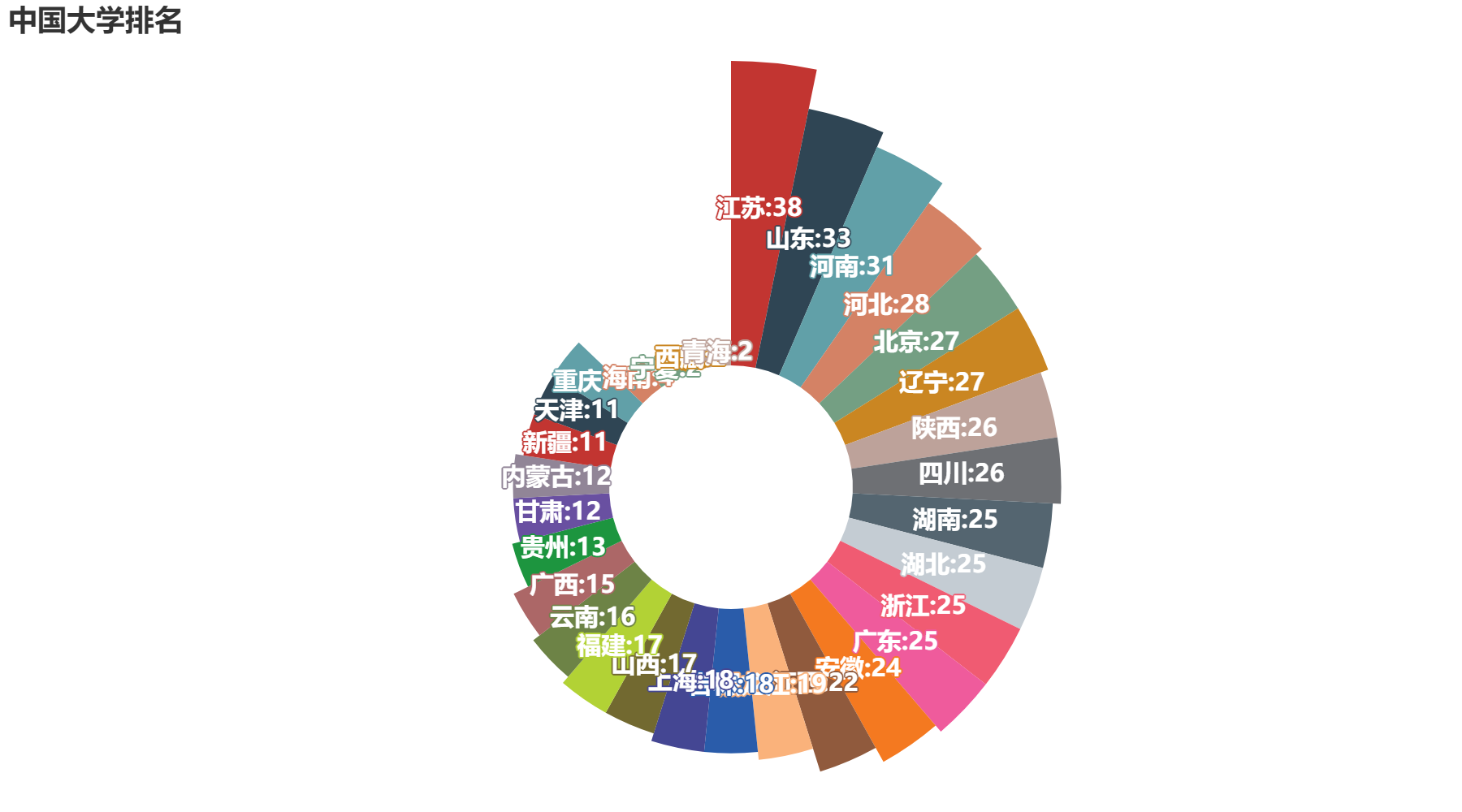
4. 各省市大学数量南丁格尔玫瑰图
df_counts.sort_values(ascending=False, inplace=True)
pro = df_counts.index.tolist()
nums = df_counts.values.tolist()
piendge = (
Pie(init_opts=opts.InitOpts(bg_color="white"))
.add("", [list(z) for z in zip(pro, nums)], radius=["30%", "105%"], center=["50%", "60%"], rosetype="area")
.set_global_opts(title_opts=opts.TitleOpts(title="中国大学排名"), legend_opts=opts.LegendOpts(is_show=False))
.set_series_opts(
label_opts=opts.LabelOpts(is_show=True, position="inside", formatter='{b}:{c}', font_weight="bold",
font_size=15))
)
make_snapshot(snapshot, piendge.render("./html/NdgePie.html"), "./img/NdgePie.png")
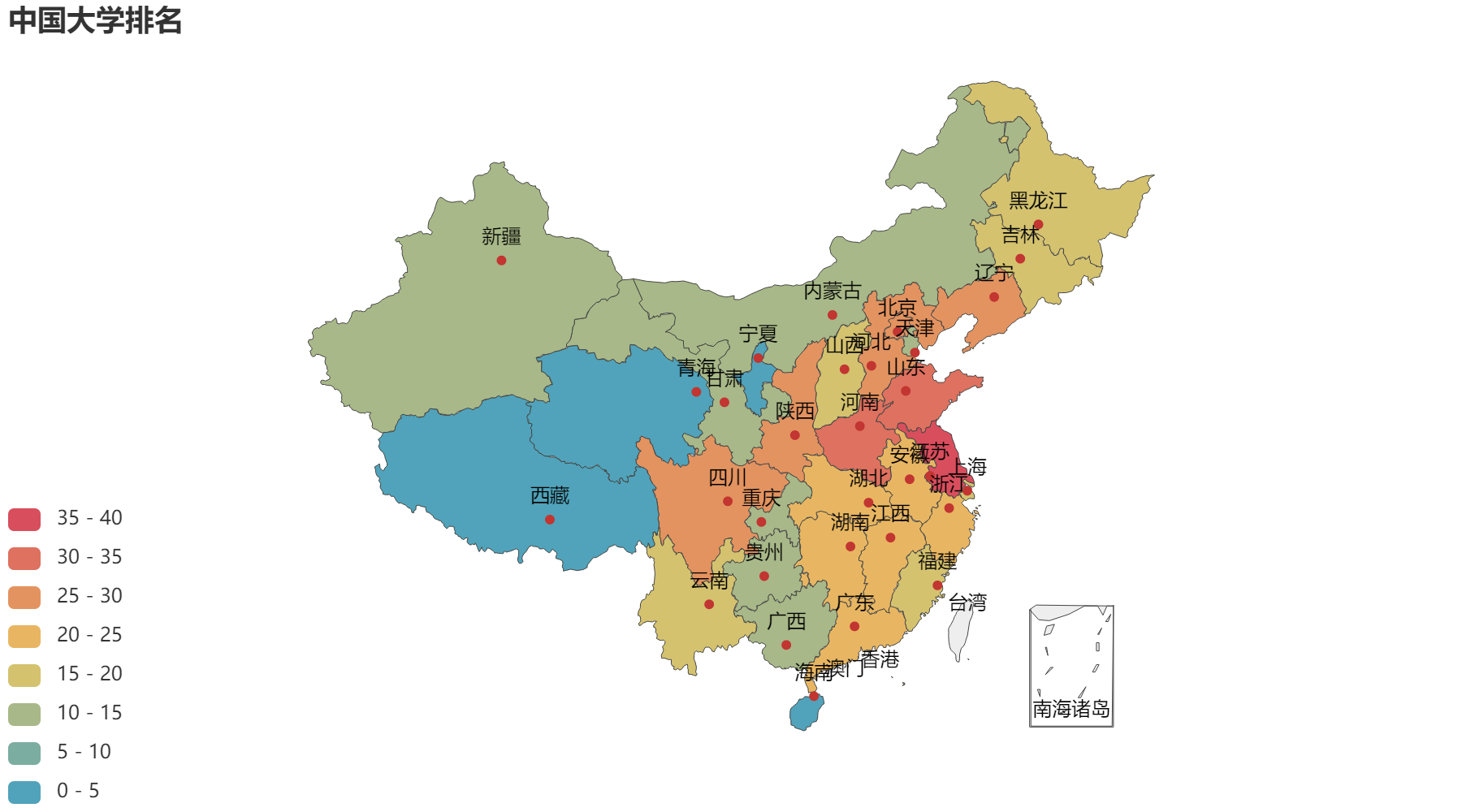
5. 中国大学排名地图
citys = df_counts.index.tolist()
res = df_counts.values.tolist()
map = (
Map(init_opts=opts.InitOpts(bg_color="white"))
.add("", [list(z) for z in zip(citys, res)], "china")
.set_global_opts(title_opts=opts.TitleOpts(title="中国大学排名"),
visualmap_opts=opts.VisualMapOpts(is_show=True, max_=40, split_number=8, is_piecewise=True))
)
make_snapshot(snapshot, map.render("./html/ChinaMap.html"), "./img/ChinaMap.png")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号