

数据结构之链表
链表(list)
如下图所示即为普通的单链表结构:

一、概念
N个节点(node)离散分配、彼此通过指针相连、每个节点只有一个前驱节点和一个后驱节点,首节点没有前驱节点,尾节点没有后续节点
专业术语:
- 首节点:存放第一个有效数据的节点
- 尾节点:存放最后一个有效数据的节点
- 头节点:首节点之前的那个节点,头节点并不存放有效数据, 目的主要是为了方便对链表的操作
- 头指针:指向头节点的指针变量
- 尾指针:指向尾节点的指针变量
优点:不受个数限制
二、链表的分类
- 按指针域分:
单链表:每个节点只有一个指针域
双链表:每个节点有两个指针域
- 按循环分:
循环链表:能通过任何一个节点找到其它所有节点
非循环链表:不能通过任何一个节点找到其它所有节点
三、链表参数
当使用一个函数对链表进行操作的时候,只需要传递头指针给函数即可。
三.五、数组和链表的选择
若线性表需要频繁查找,很少插入和删除操作时,宜采用顺序存储结构,反之;
若线性表中的元素个数变化较大或者根本不知道有多大时,最好用单链表结构,反之。
四、非循环单链表基本操作
- 初始化(创建链表):声明一个结构体类型,内涵数据域和指针域两个成员。
- 遍历:根据最后一个节点指针域是否为NULL判断
- 判断空/满
- 求长度
- 插入元素:
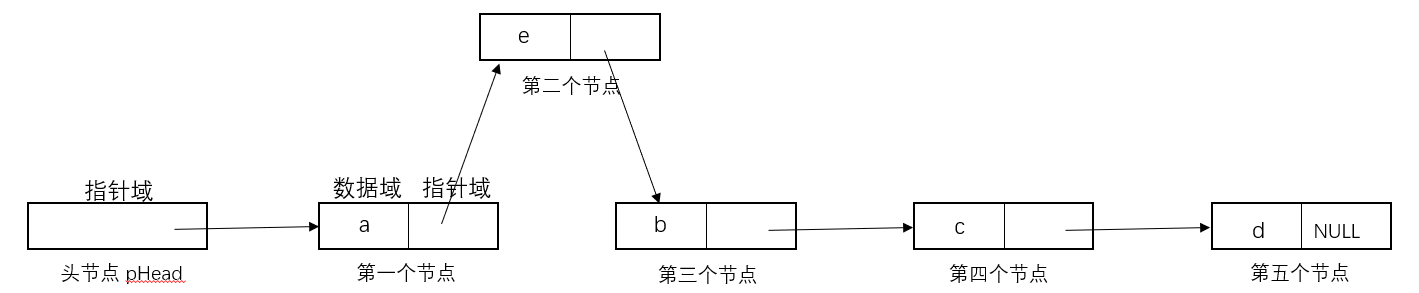
- 删除元素:
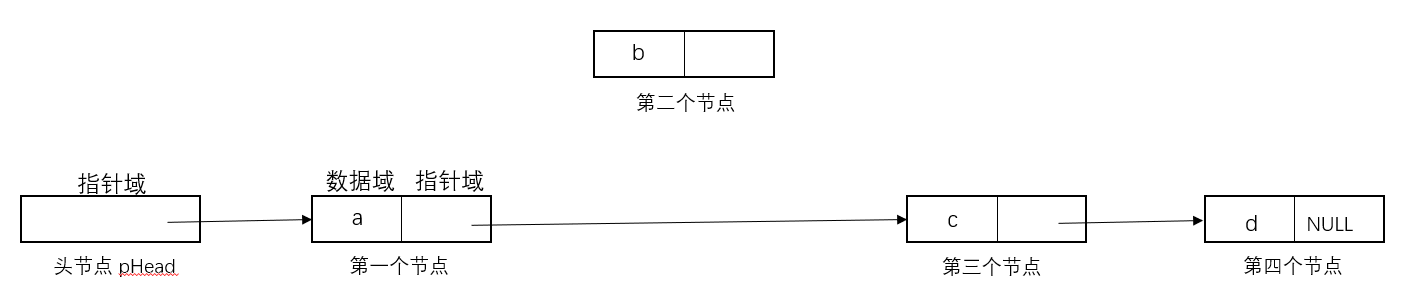
#include<stdio.h> #include<malloc.h> #include<stdlib.h> typedef struct Node { int data;//数据域 struct Node *pNext;//指针域 }NODE,*PNODE; PNODE create_list(); int is_empty(PNODE pHead); int length_list(PNODE); int insert_list(PNODE,int,int); int delete_list(PNODE,int,int*); void sort_list(PNODE); void traverse_list(PNODE pHead); int main() { int len,val; PNODE pHead = NULL;//头指针,重要成分之一 pHead=create_list();//创建一个非循环单链表 traverse_list(pHead);//遍历输出链表 len=length_list(pHead); printf("长度为%d\n",len); sort_list(pHead); traverse_list(pHead); insert_list(pHead,4,99); traverse_list(pHead); delete_list(pHead,4,&val); traverse_list(pHead); printf("删除的元素是%d\n",val); return 0; } PNODE create_list() { int len; int i,val;//val是中间存储用的 PNODE pHead,pTail,pNew;//头指针,尾指针总是指向尾节点的 pHead=(PNODE)malloc(sizeof(NODE));//为头指针分配内存 if(pHead==NULL) { printf("内存分配失败,程序结束"); exit(-1); } pTail=pHead; pTail->pNext=NULL;//确保len是0的时候,结尾是空指针 printf("请输入链表节点个数 len=\n"); scanf("%d",&len); for(i=0;i<len;i++) { printf("请输入存储的第%d个数据:",i+1); scanf("%d",&val); pNew=(PNODE)malloc(sizeof(NODE));////不用一次性分配太多内存 if(pNew==NULL) { printf("内存分配失败,程序结束"); exit(-1); } pNew->data=val;//1优先处理好新节点的data和pNext pNew->pNext=NULL; pTail->pNext=pNew;//2连接两个节点 pTail=pNew;//3永远指向尾指针 } return pHead; } void traverse_list(PNODE pHead) { PNODE p=pHead->pNext; while(p!=NULL)//遍历直至尾节点的指针域为NULL,注意是p不是p->pNext { printf("%d ",p->data); p=p->pNext; } printf("\n"); return; } int is_empty(PNODE pHead) { if(pHead->pNext==NULL) return 1; return 0; } int length_list(PNODE pHead) { PNODE p=pHead->pNext; int len=0; while(p!=NULL) { len++; p=p->pNext; } return len; } void sort_list(PNODE pHead) { int i,j,t; int len=length_list(pHead); PNODE p,q; for(i=0,p=pHead->pNext;i<len-1;i++,p=p->pNext) { for(j=i+1,q=p->pNext;j<len;j++,q=q->pNext) { if(p->data>q->data) { t=p->data; p->data=q->data; q->data=t; } } } return; } int insert_list(PNODE pHead,int pos,int val) { int i=0; PNODE p,pNew; p=pHead; while(p!=NULL && i<pos-1) { p=p->pNext; i++; } if(p==NULL || i>pos-1)//后者是用来防止pos<1的情况,而前者是防止pos大于节点个数 return 0; pNew=(PNODE)malloc(sizeof(NODE)); if(pNew==NULL) exit(-1); pNew->data=val; pNew->pNext=p->pNext; p->pNext=pNew; return 1; } int delete_list(PNODE pHead,int pos,int *val) { int i=0; PNODE p,q; p=pHead; while(p!=NULL && i<pos-1) { p=p->pNext; i++; } if(i>pos-1 || p==NULL) return 0; q=p->pNext; *val=q->data; p->pNext=p->pNext->pNext; free(q);//注意释放内存 q=NULL;//然后零中间的指针置空 return 1; }
五、循环单链表简单描述
和非循环单链表相比,不同的地方就是让尾节点的指针域指向首节点。然后为了方便两个链表的链接或者同时访问到尾节点和首节点,可以用一个尾指针来指向尾节点来代替头结点的作用,然后取消掉非循环单链表的头结点。
六、循环双链表简单描述
和非循环单链表相比,不同的地方就是指针域要分为两部分,左指针域和右指针域,左指向前驱节点,右指向后驱节点,仅仅在插入删除操作有区别,而其它求长度、获得元素等无区别。
typedef struct Node { int data; struct Node *pPrior; //指向前驱节点 struct Node *pNext; //指向后驱节点 }NODE,*PNODE;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号