Unity URP 程序化生成草地
TODO:文章写的还是有点乱,有时间可以再整理整理。
这是一篇学习草地生成内容的文章,并非实际业务实现!并非实际业务实现!并非实际业务实现!方法和内容仅供学习和交流使用。
GPU Driven:
Unity Open Day 北京站-游戏专场:GPU-Driven实现移动端大规模氛围 NPC 渲染
UE5渲染技术简介:Nanite篇
初次尝试GPU Driven —— 大范围植被渲染
从零开始的 GPU Driven 管线——GPU Culling篇
开发世界草地渲染
大世界中地面植被(这里主要是草地)的渲染,通常是开发世界类游戏中的重要画面表现,如何在合理的内存和性能限制下,生成数英亩的草地,渲染和单个叶片的动画技术,以及让数十万叶片看起来非常自然,是一个非常有趣且有挑战的问题。通常来说,草片的实现方法有三种(这里只介绍不同的原理,至于通用的LOD,各种剔除部分的优化,因为是通用的所以不做说明)。
- 一类是基于面片alpha剔除实现的,最常见的方法是用单个(公告板 (Billboarding)技术)或多个面片交叉渲染。优势就是开销比较小,但缺陷也很明显,由于只是数个面片,空间表现力不足,俯视角观察也很不真实。在星穹铁道的翁法罗斯部分场景(如小奇美拉的区域)中,则是用N个不同高度大面片进行不同阈值的alpha测试(类似毛发的多层渲染实现),实现了密集而立体的草地,且即使从俯视角看也很好看,虽然超近距离就露馅了。
- 另一类是构建真实的几何草片模型,针对大规模渲染的问题,通过GPU Instance来在一个DrawCall中绘制。通常是比前一种方法效果更好的移动端大规模草解决方案。
- 最后一类是基于Geometry shader的程序化草地,主要思路就是在GS中通过单一顶点直接生成每一根草的几何模型,不少3A作品是用此方法实现的草地(如对马岛之魂),但这种方法对移动端来说通常过于昂贵了(更不说Metal都不支持几何着色器)。
笔者这里实现的主要是基于Geometry shader和Compute Shader的程序化草地生成,使用GPU Driven Pipeline创建和生成草地,CPU负责地形分割。
程序化生成草地
笔者参考以下文章及自己的一点点理解简单实现了下这部分。
【Unity Shader】使用Geometry Shader进行大片草地的实时渲染
利用GPU实现无尽草地的实时渲染
功能
- 自定义草(细长条状植被)表现效果。
- 支持风的模拟,可调风向,强度,波浪态模拟。
- 支持自定义距离LOD。
可调节参数:
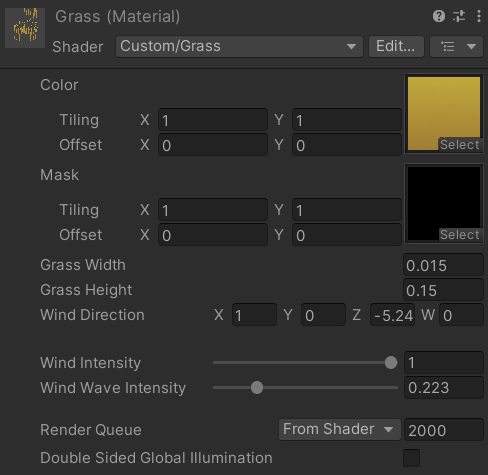
实现:
生成草的顶点数据(根据不同的LOD,有1到5个面片的顶点构造情况),目前草的视锥剔除有问题,根部不在视野内就会把整颗草都清除掉:

然后获取平面大小和位置,在平面上随机生成N个根顶点,效果如下:

但此时草的网格都是向着一个方向的,所以添加一些随机生长的效果,包括随机方向和随机长度。

再加入一些模拟风的效果:

改个色,也蛮好看的:

程序化草 Shader 代码
Shader "Custom/Grass"
{
Properties {
_Color ("Color", 2D) = "white" {}
_Mask ("Mask", 2D) = "white" {}
_Width ("Grass Width", Float) = 0.5
_Height ("Grass Height", Float) = 0.5
_WindDirection ("Wind Direction", Vector) = (1, 0, 0, 0)
_WindIntensity ("Wind Intensity", Range(0.0, 1.0)) = 0.5
_WindWaveIntensity ("Wind Wave Intensity", Range(0.0, 1.0)) = 0.5
}
SubShader {
Tags { "RenderType"="Opaque" "RenderPipeline"="UniversalPipeline" }
Cull Off
HLSLINCLUDE
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
CBUFFER_START(UnityPerMaterial)
float4 _BaseMap_ST;
float4 _BaseColor;
float _Width;
float _Height;
float4 _WindDirection;
float _WindIntensity;
float _WindWaveIntensity;
//float4 _ExampleDir;
//float _ExampleFloat;
CBUFFER_END
ENDHLSL
Pass {
Name "Example"
Tags { "LightMode"="UniversalForward" }
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma geometry geom
struct Attributes {
float4 positionOS : POSITION;
};
struct v2g {
float4 vertex : SV_POSITION;
float2 uv : TEXCOORD0;
};
struct g2f {
float4 vertex : SV_POSITION;
float2 uv : TEXCOORD0;
};
TEXTURE2D(_Color);
SAMPLER(sampler_Color);
TEXTURE2D(_Mask);
SAMPLER(sampler_Mask);
float2 random(float2 st)
{
return (frac(sin(st) * 1000) - 0.5) * 2.0;
}
v2g vert(Attributes IN) {
v2g OUT;
OUT.vertex = IN.positionOS;
return OUT;
}
float CalculateDistanceInWindDirection(float4 leftDownPos)
{
float2 position = leftDownPos.xz;
float2 windDir = _WindDirection.xz;
float2 normalizedWindDir = normalize(windDir);
float2 projection = dot(position, normalizedWindDir) * normalizedWindDir;
float distance = length(projection);
return distance;
}
[maxvertexcount(30)]
void geom(point v2g IN[1], inout TriangleStream<g2f> triStream){
g2f tri[3];
int lod = 0;
int lodCount = 5 - lod;
half uvStep = 1.0 / (half)lodCount;
float2 randomf2 = normalize(random(float2(IN[0].vertex.x, IN[0].vertex.z)));
float2 norWind = normalize(float2(_WindDirection.x, _WindDirection.z));
float4 grassTangent = float4(normalize(float3(randomf2.x, 0.0, randomf2.y)), 1.0);
float height = _Height * 0.5 + _Height * abs(randomf2.x) * 0.5;
float width = _Width;
// 计算向前还是向后倾倒,以及倾倒程度.
float cross_product = norWind.x * randomf2.y + norWind.y * randomf2.x;
float4 normal = float4(-randomf2.y, 0., randomf2.x, 1.0);
if(cross_product > 0){
normal = -normal;
}
float4 leftDownPos = IN[0].vertex;
float t = _Time.y;
float baseDegree = 1.57;
float degreeAdd = -0.3 * abs(cross_product) * (abs(sin(_WindWaveIntensity * t + -CalculateDistanceInWindDirection(leftDownPos))) * _WindIntensity + (1. - _WindIntensity));
// float degreeAdd = -0.3;
float4 ldPos = leftDownPos - float4(0., 1., 0., 1.) * height * sin(baseDegree - degreeAdd) - normal * height * cos(baseDegree - degreeAdd);
for(int i = 0; i < lodCount; ++i){
// ldPos = ldPos + float4(0., 1., 0., 1.) * height * sin(baseDegree - degreeAdd) + normal * height * cos(baseDegree - degreeAdd);
ldPos = ldPos + float4(0., 1., 0., 1.) * height * sin(baseDegree - degreeAdd)
+ normalize(_WindDirection) * height * cos(baseDegree - degreeAdd);
tri[0].vertex = ldPos;
tri[0].vertex = TransformObjectToHClip(tri[0].vertex);
tri[0].uv = float2(0., i * uvStep);
// tri[1].vertex = ldPos + grassTangent * width + float4(0., 1., 0., 1.) * height * sin(baseDegree) + normal * height * cos(baseDegree);
tri[1].vertex = ldPos + grassTangent * width + float4(0., 1., 0., 1.) * height * sin(baseDegree)
+ normalize(_WindDirection) * height * cos(baseDegree);
tri[1].vertex = TransformObjectToHClip(tri[1].vertex);
tri[1].uv = float2(1., (i + 1) * uvStep);
// tri[2].vertex = ldPos + float4(0., 1., 0., 1.) * height * sin(baseDegree) + normal * height * cos(baseDegree);
tri[2].vertex = ldPos + float4(0., 1., 0., 1.) * height * sin(baseDegree)
+ normalize(_WindDirection) * height * cos(baseDegree);
tri[2].vertex = TransformObjectToHClip(tri[2].vertex);
tri[2].uv = float2(0., (i + 1) * uvStep);
triStream.Append(tri[0]);
triStream.Append(tri[2]);
triStream.Append(tri[1]);
triStream.RestartStrip();
tri[2].vertex = ldPos + grassTangent * width;
tri[2].vertex = TransformObjectToHClip(tri[2].vertex);
tri[2].uv = float2(1., i * uvStep);
triStream.Append(tri[0]);
triStream.Append(tri[1]);
triStream.Append(tri[2]);
triStream.RestartStrip();
baseDegree += degreeAdd;
}
}
half4 frag(g2f IN) : SV_Target {
half4 color = SAMPLE_TEXTURECUBE(_Color, sampler_Color, saturate(IN.uv));
half4 mask = SAMPLE_TEXTURECUBE(_Mask, sampler_Mask, saturate(IN.uv));
clip(mask.a - 0.01);
return color;
}
ENDHLSL
}
}
}
GPU Driven(这个是GPU Driven吗?存疑!)
什么是GPU Driven?GPU Driven指将部分在CPU中处理的流程(通常是大量的可并行的操作),如遮挡剔除,视锥剔除,合批等在GPU上处理。包括UE5的Nanite也用了GPU Driven来实现性能可观的大场景高精度渲染。
还是之前的场景,当我将草的数量提升到10,000,000后,帧率暴跌到只有20多帧,再加上之前说的根部不在视野内就会把整颗草都清除掉的问题,是时候需要解决一下这些问题了。
打开性能分析工具,可以看到GPU和CPU耗时都在37ms上下(峰值是进行了一次Edit窗口的渲染,可忽略),CPU几乎全程在等GPU(Gfx.WaitForPresentOnGfxThread耗时34ms),所以后续的主要优化方向就是让GPU尽量少做计算。
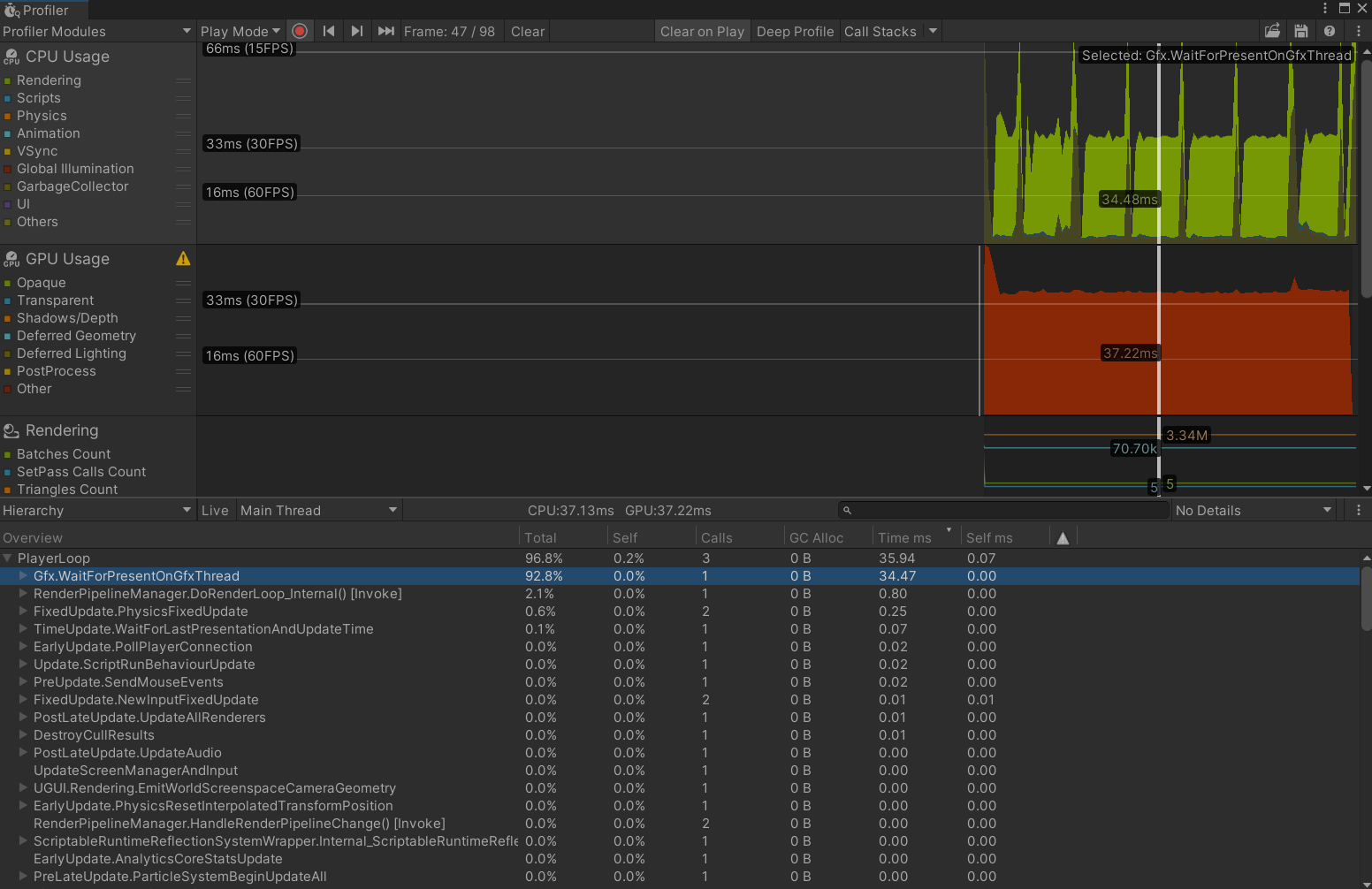
CPU视锥剔除
先处理错误剔除的问题,Unity默认启用CPU Driven的视锥剔除功能,即当mesh的包围盒完全立刻视锥体后,就不会提交该对象进行渲染,而我们的程序草在提交时只有CPU端生成的一系列根顶点,所以在根顶点移除视锥后,连带着叶顶点也被剔除了。所以第一步是确保视锥剔除在GPU进行。这里暴力一点,直接将Mesh Renderer的包围盒设置在相机视锥体内。
void Update()
{
Vector3 pos = Camera.main.transform.position + Camera.main.transform.forward * Camera.main.nearClipPlane;
gameObject.GetComponent<MeshRenderer>().bounds = new Bounds(pos, Vector3.one);
}
至此,性能就更差了。
GPU视锥剔除
在Profiler里面可以看到,Render.mesh消耗了大量的时间,每帧传输一千万个顶点太极限了,因为不管看不看得见,这10,000,000根草都会进行渲染,性能非常差。用CPU去筛选需要哪部分的点也不是非常好的选择,毕竟数量太大了,所以考虑从GPU中生成和处理根顶点,然后直接输入渲染管线。

先计算相机视锥体在ZX平面上的投影,假设相机只会绕Y轴旋转(先假设简单情况)。
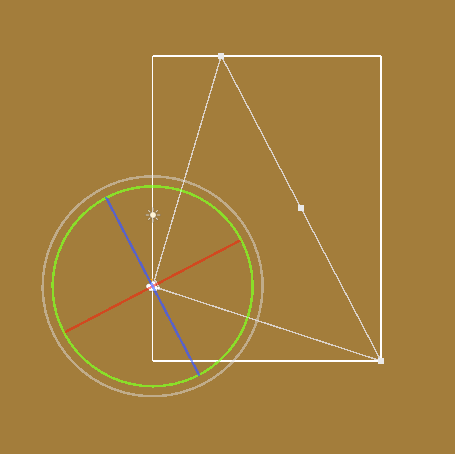
计算对齐到单元格的投影,每个单元格内生成一个随机位置的顶点。如此,现在可以在任意位置表现大量的草(因为是在GPU中生成处理的,也就没有65535的限制了)。

由于浮点数的精度问题,导致Compute Shader生成的标准位置(最终位置=标准位置+偏移)可能有微小区别🫠(下图,表现即画面中一部分草会瞬移),但这一点点微小区别在计算偏移的伪随机数时会明显放大这个误差。解决方法是在Compute Shader里面做一个纠正。

[numthreads(64,1,1)]
void CSMain (uint3 id : SV_DispatchThreadID)
{
if (id.x > (uint)grassCount)
return;
float posX = posC.x + id.x / col * subBlockSize;
float posZ = posC.z + id.x % col * subBlockSize;
//posX = floor((posX + subBlockSize / 2.) / subBlockSize) * subBlockSize; // 解决草瞬移问题
//posZ = floor((posZ + subBlockSize / 2.) / subBlockSize) * subBlockSize;
float2 offset = random(float2(posX, posZ));
vertexBuffer[id.x] = float3(posX + offset.x, 0.0, posZ + offset.y);
}
还有一个问题,不管是远处的草还是近处的草,都使用的是相同的单元格划分,但是在远处的草并不需要“种”的如此密集。
这部分我们用四叉树划分渲染区域处理,四叉树划分在C#脚本中处理,这个很方便,然后对每个划分出的区块在Compute shader中生成顶点。

对不同LOD区域生成不同密度的根节点。感觉效果不是很好,LOD变化时非常突然。

先把咱不同LOD生成草的密度设置为相互的倍数(原先笔者首先的是线性的,LOD0如果密度为间隔0.2生成一根,LOD3就是0.6生成一根),设置为倍数的好处是从LOD1到LOD0时只是新增了一部分草,而不是又重新生成了一批草,反之亦然。所以就可以根据距离对会变化的草(会变化是指两个LOD之间不一样的草)的高度做插值了(通过对外圆和内圆插值实现)。
插值了效果还是很差,因为渲染范围是对齐边界随相机移动,虽然每个最小单元格都是世界坐标对齐的,但大的单元格却没有对齐,步进起来就LOD中心会跳变,导致距离插值跳变,根据插值调整的草片大小就很奇怪了。所以应该以世界坐标构建区块,而不是以相机坐标。(先假设为直角三角形,方便计算),效果好了很多。当前LOD新增或消失的草不会影响到已经生成的草。

由于是基于世界空间构造的区块,所以会有不在视锥体内的块也会被渲染,这部分可以提前剔除掉,即不在视锥范围内的块无需继续划分也无需渲染(通过三角形和四边形是否相交判断,方法是即不存在在四边形中的三角形顶点,也不存在在三角形中的四边形顶点,说明不相交,这种方法并不严谨,因为一旦出现内部交叉就无法判断了【如两个矩形呈十字交叉】,不过在当前的场景下已经够用了,AABB是否在包围盒内判断)。
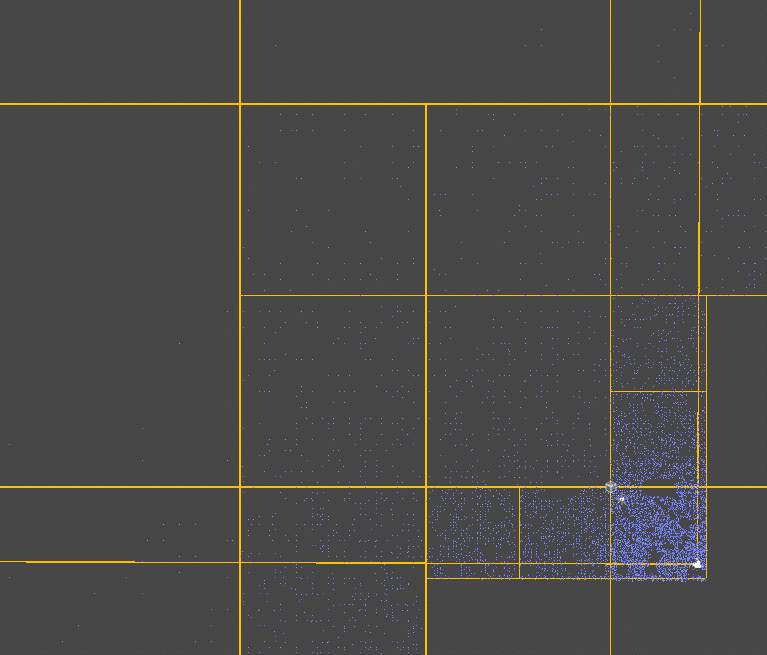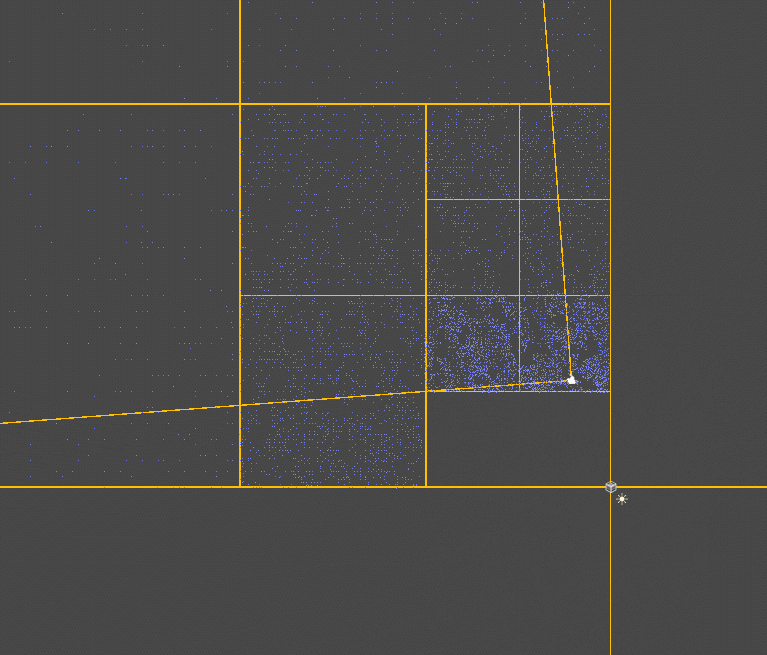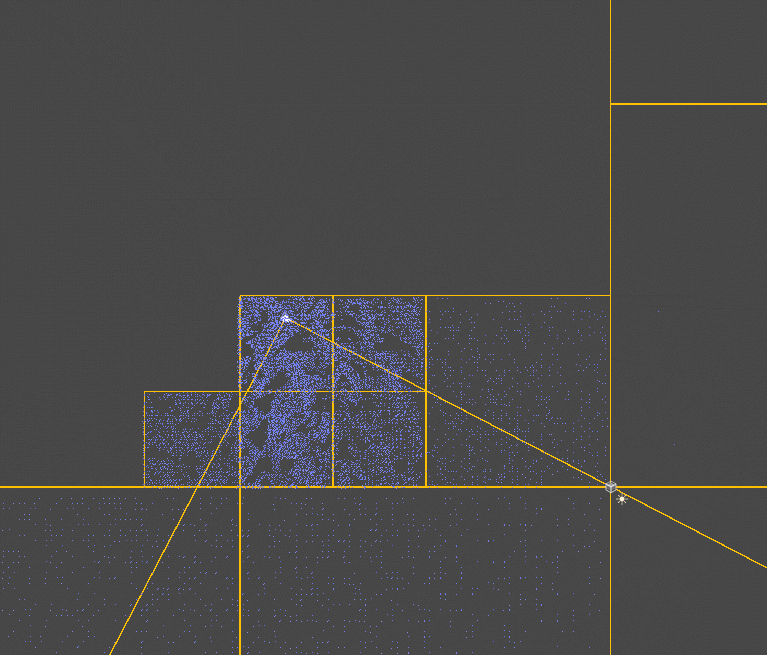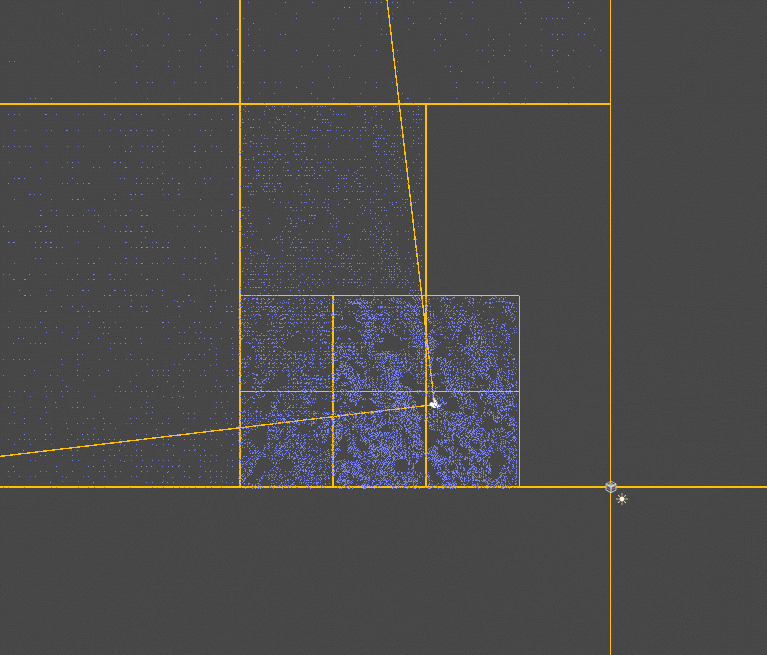
此处省略一系列修改(因为我也不记得改了啥了),照着终焉花海调了一下效果(这里压缩了一下),还可以对草片的颜色增加一些随机(如题图):

ok就这么多了,地形就不加了,之后就是整理整理。

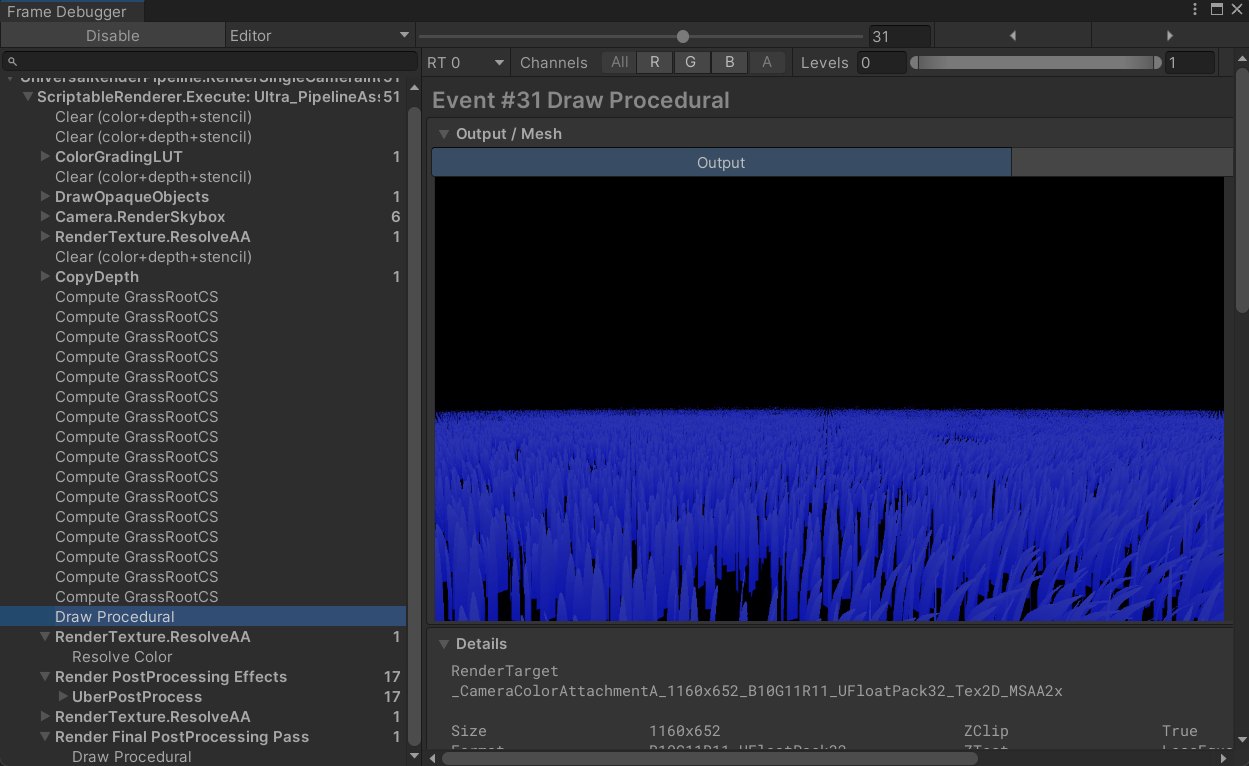
DrawCall一次可以完成所有草的渲染,实测草的数量大概在20~30w之间变化,就是CS每个地块都得调用一次。
视锥剔除(以草片为单位)
之前的视锥剔除是以地块为单位的,这里还可以以草地为单位再次进行一次视锥剔除。能想到两种方法:
1.所有顶点全部生成,但是视锥外的顶点额外标记,能够节省一部分GS(效果存疑?毕竟有遮掩机制)。
2.计算每个地块生成的草片数量,这样由于草片数量在CS执行完前不确定,GPU无法异步执行了,而且计数操作还需要保证为原子操作。
视锥剔除前渲染线程大概是1.3ms,CPU操作0.1ms(计算各种空间数据,处理地面分块)。
Compute Shader调用100w次需要3.414ms。
视锥剔除前渲染线程大概是3.6m,视锥剔除(对不在视锥的设置.y为-1.0f,然后在GS中丢弃该顶点)后大概是3.3ms。
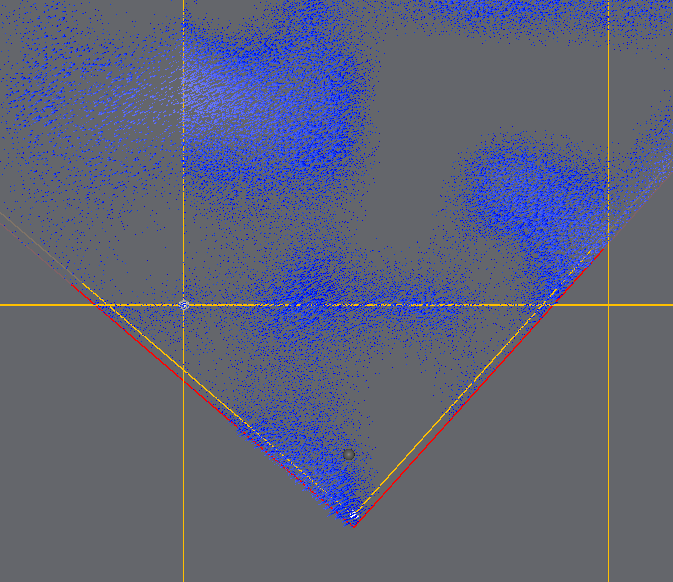
红线是剔除边界,比视锥略大,因为我们没有草片的AABB,而草片位置会随机偏移,所以预留一些空间确保草片不会突然出现在视线内,仅通过视锥剔除就能够剔除30%到40%的草(粗略估计,因为剔除只是减少GS和FS,顶点并没有减少不好统计少了多少,后续可能会统计一下)。
遮挡剔除
浅谈Unity实现大地图游戏地块加载策略
遮挡剔除实现的主要是对在视锥体中但被其他物体遮挡的物体进行整体剔除(区别于像素尺度的遮挡剔除,如zbuffer,early-z,pre-z,这里是在物体尺度上进行的),通常都是用AABB进行判断,此类方法有:
- 离线剔除:PVS(潜在可见集),属于预处理方法,对相机能到达的位置进行分块,预计算每个块中能够被相机看到的物体(或不能被看到的物体)。
- 在线剔除:HiZ,用深度缓冲构建类似MipMap的缓冲集。
- 在线剔除:软光栅遮挡剔除,待了解。
这里用HiZ实现遮挡剔除,参考【Unity】使用Compute Shader实现Hi-z遮挡剔除(Occlusion Culling)。
indirect draw:貌似是对于多个GPU渲染命令,同时提交给GPU,然后GPU自行一条一条执行,不太明白。
有以下步骤:
1.首先获取到深度纹理,Unity中可以获取到当前帧的深度纹理,这个深度纹理是在ShodowPass中获取的,所以是当前帧的深度。
2.生成对应的HizMap,先创建一个存放所有MipMap的纹理,然后将当前深度纹理绘制到该纹理的上部分区域。
这里给一个在阅读各种资料中发现的规律,对大量的内容或对象进行渲染加速,一个重要的思路就是先找到一个能够代表多个对象(后续需要处理的)某个信息的方法,然后根据该方法开始在空间上划分所有对象,然后通过对象集来快速判断是否符合要求,以此达到快速抛弃不符合要求的对象的目标,如背面剔除(法线锥体加速),HiZ,BVH等各种空间划分检测方法。用不那么白话的描述就是,"通过空间聚合与代表性信息预计算,实现批量剔除与高效调度"。
草地阴影和光照
暂时未实现。
问题:草不能太密,不然浮点精度问题就会导致通过MOD筛选的float值错误
暂时未解决。
如何处理超远距离
超远距离下就不需要渲染草地了(毕竟渲染了也看不到),设置一个最大距离渲染,当相机远平面大于最大渲染距离时用最大渲染距离生成根顶点。同时,对远距离的草为了和不渲染的区域过渡更自然,对每个草片的高度和宽度都需要按距离缩放。

近距离被错误剔除
因为笔者对齐是向下取整的,所以在相机在渲染区域上方时会被错误剔除掉,这里通过处理上和右边界时上上取整处理。
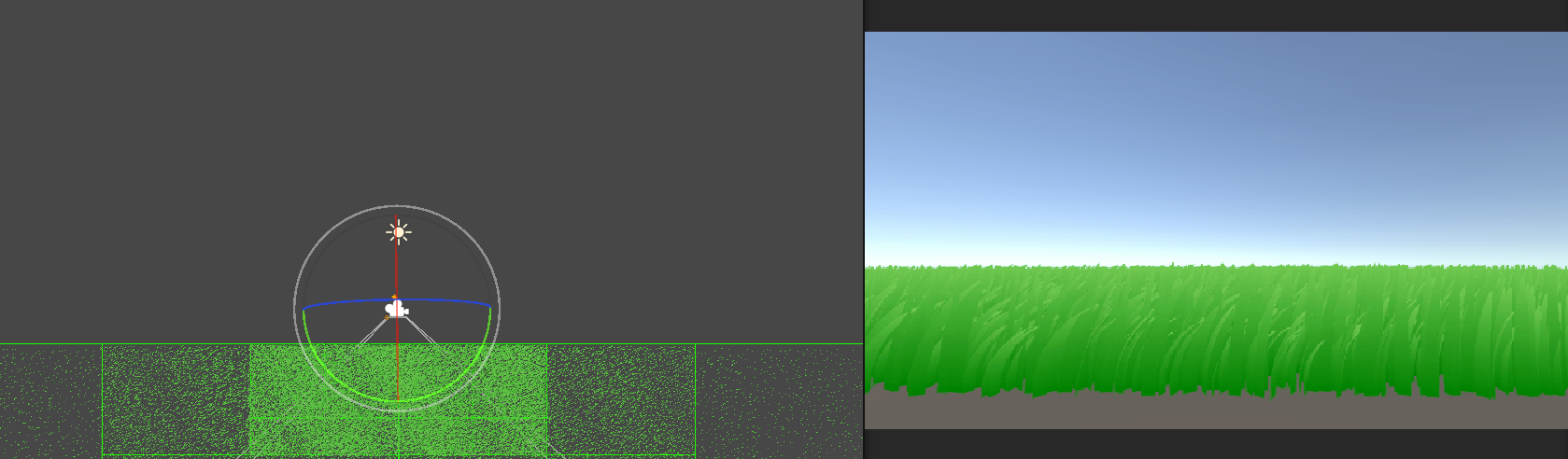
其他优化
how this game renders millions of blades of grass
如BOTW近距离用模型草GPU Instance,远距离用广告牌2D草,且靠近玩家密度更高。
关于几何着色器
之前使用过但忘了,这里回忆一下。我对着色器的看法:几何着色器。
复习一下知识点,如果有几何着色器,那么顶点变换就会推迟到几何着色器中进行🤔。
几何着色器
Shader "Custom/GemoShaderSample"
{
Properties {
_BaseMap ("Example Texture", 2D) = "white" {}
_BaseColor ("Example Colour", Color) = (0, 0.66, 0.73, 1)
_ExtrusionFactor ("Extrusion Factor", float) = 0.5
//_ExampleFloat ("Example Float (Vector1)", Float) = 0.5
}
SubShader {
Tags { "RenderType"="Opaque" "RenderPipeline"="UniversalPipeline" }
Cull Off
HLSLINCLUDE
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
CBUFFER_START(UnityPerMaterial)
float4 _BaseMap_ST;
float4 _BaseColor;
float _ExtrusionFactor;
//float4 _ExampleDir;
//float _ExampleFloat;
CBUFFER_END
ENDHLSL
Pass {
Name "Example"
Tags { "LightMode"="UniversalForward" }
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma geometry geom
struct Attributes {
float4 positionOS : POSITION;
float2 uv : TEXCOORD0;
float3 normal : NORMAL;
};
struct v2g {
float3 normal : NORMAL;
float4 vertex : SV_POSITION;
};
struct g2f {
float4 vertex : SV_POSITION;
float surfaceDist : TEXCOORD0;
};
TEXTURE2D(_BaseMap);
SAMPLER(sampler_BaseMap);
v2g vert(Attributes IN) {
v2g OUT;
OUT.vertex = IN.positionOS;
OUT.normal = IN.normal;
return OUT;
}
[maxvertexcount(12)]
void geom(triangle v2g IN[3], inout TriangleStream<g2f> triStream) {
g2f OUT;
// 计算中心点
float4 barycenter = (IN[0].vertex + IN[1].vertex + IN[2].vertex) / 3;
float3 normal = (IN[0].normal + IN[1].normal + IN[2].normal) / 3;
// 添加新三角形
for(int i = 0; i < 3; i++) {
int next = (i + 1) % 3; // 第 69 行
OUT.vertex = TransformObjectToHClip(IN[i].vertex);
OUT.surfaceDist = 0;
triStream.Append(OUT);
OUT.vertex = TransformObjectToHClip(barycenter + float4(normal, 0.0) * _ExtrusionFactor);
OUT.surfaceDist = _ExtrusionFactor;
triStream.Append(OUT);
OUT.vertex = TransformObjectToHClip(IN[next].vertex);
OUT.surfaceDist = 0;
triStream.Append(OUT);
triStream.RestartStrip();
}
//原三角形加入
for(int i = 0; i < 3; i++)
{
OUT.surfaceDist = 0;
OUT.vertex = TransformObjectToHClip(IN[i].vertex);
triStream.Append(OUT);
}
}
half4 frag(g2f IN) : SV_Target {
half res = IN.surfaceDist + (1.0 - _ExtrusionFactor) - 0.5;
half3 color = half3(0.6, 0.6, 0.8) * res;
return half4(color, 1.0);
}
ENDHLSL
}
}
}
关于计算着色器
在Unity中创建一个默认的CS,其代码如下:
// Each #kernel tells which function to compile; you can have many kernels
#pragma kernel CSMain
// Create a RenderTexture with enableRandomWrite flag and set it
// with cs.SetTexture
RWTexture2D<float4> Result;
[numthreads(8,8,1)]
void CSMain (uint3 id : SV_DispatchThreadID)
{
// TODO: insert actual code here!
Result[id.xy] = float4(id.x & id.y, (id.x & 15)/15.0, (id.y & 15)/15.0, 0.0);
}
- kernel:CS至少需要一个核才能被执行。
- RWTexture2D:
RW声明一个可读可写的纹理。 - [numthreads(8,8,1)]:设置的线程的数量,在C#中的
Dispatch(0, 256 / 8, 256 / 8, 1)是线程组的数量,即我们的CS在每个线程组中启用了64个线程,共启用了(256 / 8) * (256 / 8)个线程组,这样恰好每个线程组处理一个64*64大小的像素块。每个线程处理一个像素。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号