“考古”早期自然语言对话程序——ELIZA
“考古”早期自然语言对话程序——ELIZA
前言
在我小时候读书时,班里曾流行过一个新奇的玩具——《答案之书》(也可以叫《解答之书》)。那是一本颇浪费纸张的书,书很厚但每页的内容却只有寥寥数字,在心中默念你的疑问,再随便翻开书,翻开的那一页上所呈现的语句就是书给出的答案,很有占卜的味道,书中的很多语句也是摸棱两可的。

歌德曾说:“读一本好书,就是和许多高尚的人谈话。”那时的确有过想着以对话为目的连续翻着书里的内容,偶尔运气好,书里翻到的回复和我的问法都对的上,就会有种交流的错觉。
在语言大模型流行的今天,这种想法已经很容易实现了,去和大模型对话就行了,交流自然,给出的答案还能更靠谱。自然语言处理是人工智能的一大领域,也是比较吸引大众的一大领域,可能是因为“图灵测试”的提出,也可能是大家多少都怀着和我小时候一样的、对非人之物交流的好奇。
能和人进行“交流”的程序在如今已经不足为奇了。很多游戏也开始将语言大模型融入到NPC中,让玩家能更自由地与其互动。

不过今天我们不聊大模型,我们来看看被认为是世上最早(论文的时间是1966年)的聊天机器人——ELIZA,在深度神经网络还没起色的时候是怎么使用基于规则的程序来实现“交流”的呢。这里先附上个人实现的可以在Unity中运行的基于C#复刻的ELIZA的Demo,里面还有尝试实现的中文对话版本,只不过规则写的比较糟糕,但还是能聊的 (对话规则是用英文版翻译的,所以比较突兀
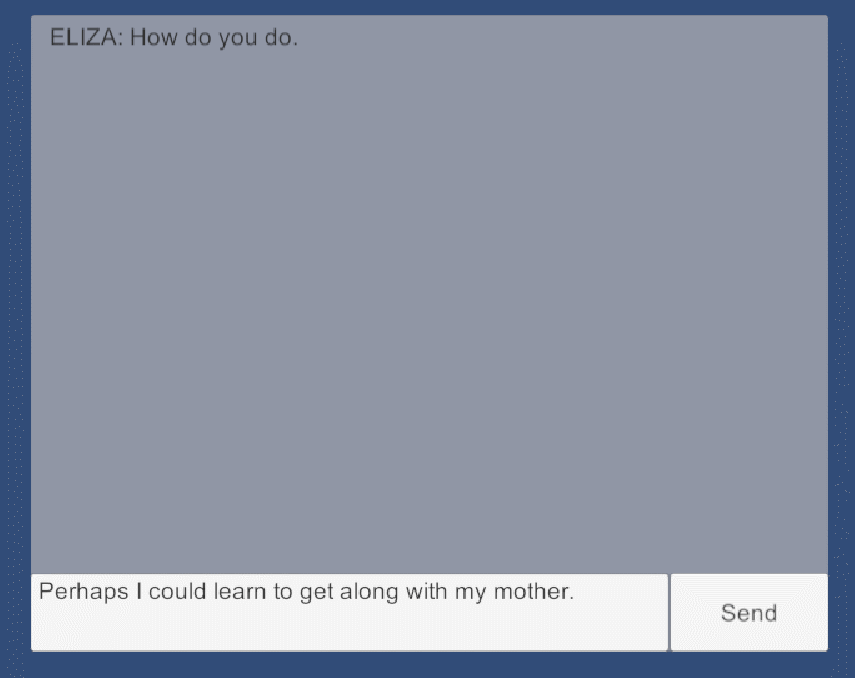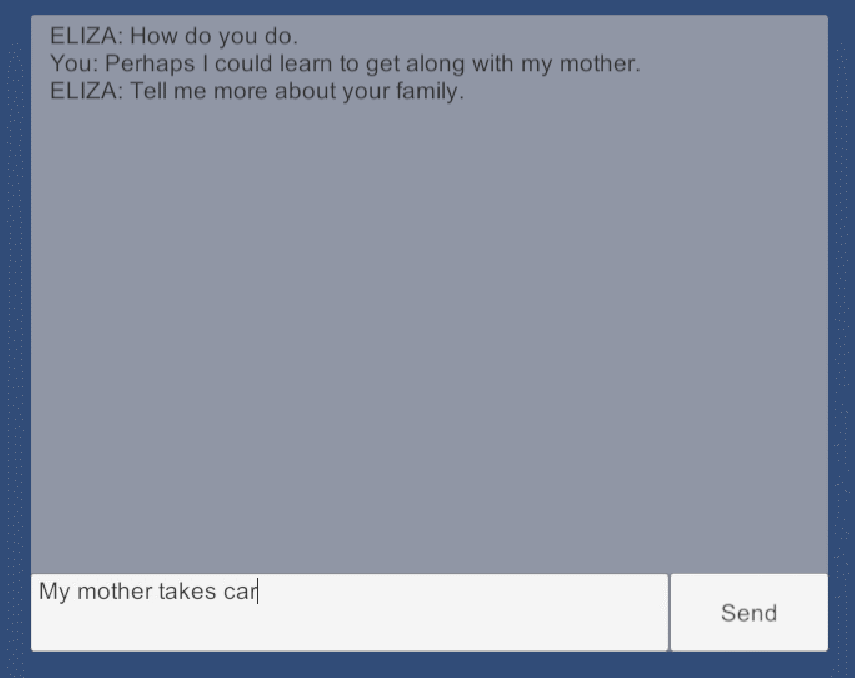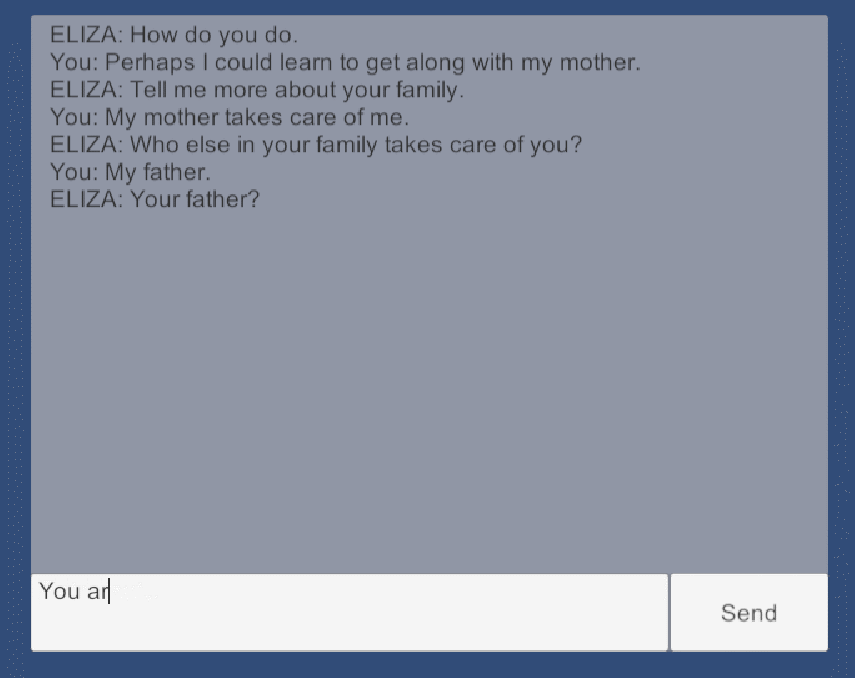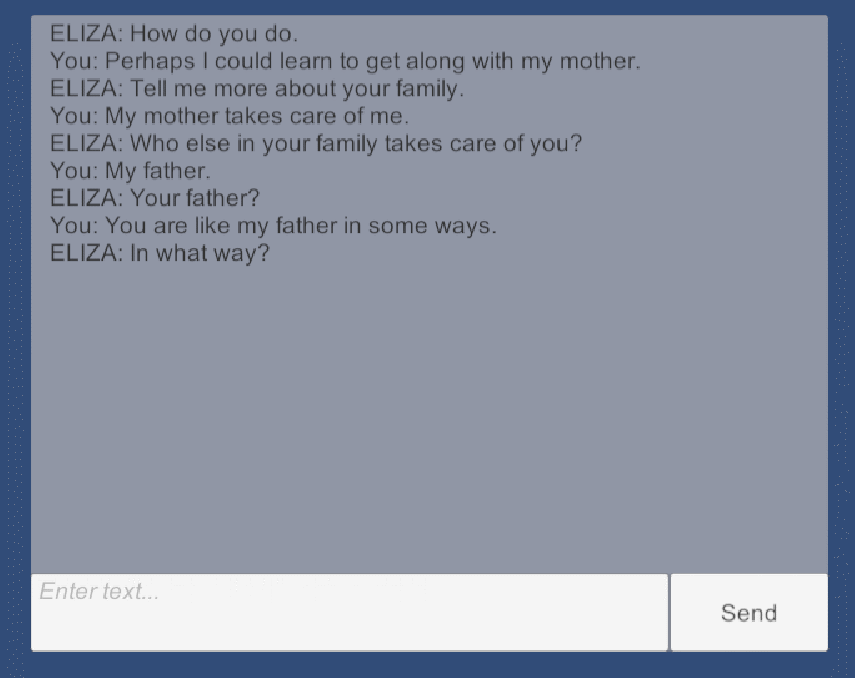
ELIZA程序
ELIZA 程序由约瑟夫·魏岑鲍姆设计,程序名字来自《卖花女》(别名《皮格马利翁》)中的人物伊莉莎(Eliza),故事中,一语音学家与其朋友打赌用街头卖花女伊莉莎作实验,通过6个月的语音和仪态训练,将其改造成仿佛出身名门的大小姐。
ELIZA 程序其实也一样,它完全不了解用户的输入语句,但能根据关键词捕捉、相关语句分解、规则模板重组来回复出一句像模像样的话。它的整体逻辑并不复杂,但它可以通过替换相关规则来作出不同风格或者不同语言的回复,原版 ELIZA 中最出名的便是心理医生风格的。
下面来看看它的大致执行逻辑。假设我们输入了一句:
Do you remember my name? We just chatted last week.
ELIZA 首先会对输入语句按句末标点符号进行截断,当前输入语句便成了两句话,ELIZA 会先逐一处理语句,直到成功为止,何谓“处理”、何谓“成功”我们后文再说。总之,当前 ELIZA 得到的输入是第一句:
Do you remember my name?
接着,它会对去除多余标点、统一变小写。有时还需要将语句中部分词语进行替换,这些是人为指定的,例如,将 you're 改成 you are,将 i'm 改成 i am。当前我们的语句并不需要这类变化,简单地去标点、改小写就行:
do you remember my name
然后,ELIZA 开始从左到右挨个匹配关键词,并按照事先赋予的各个关键词的优先级进行大致排序。之所以说是大致排序,是因为论文中作者只是简单地用一个容器的头/尾插入来区分优先级的大于/小于,省去了排序步骤。具体步骤就是,当一个词语的优先级大于当前容器首个词语的优先级时,就从头部插入,让新词语成为新的首元素;当小于时,就尾部插入:
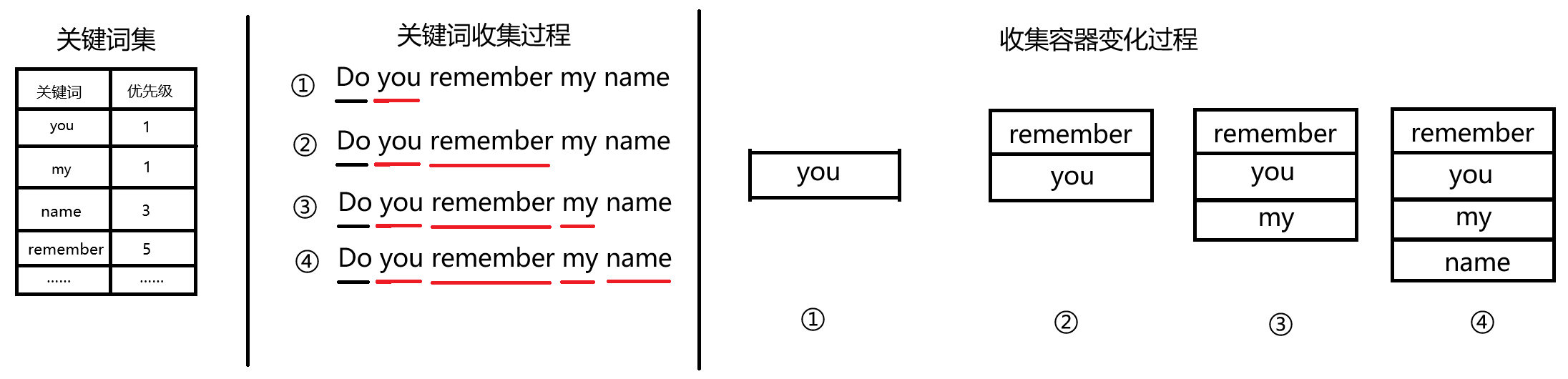
在关键词匹配的过程中还有关键词相关的同义词替换的过程,这也是事先设定好的,例如,我们会关注关键词 sad(伤心),而输入可能是: I am unhappy。unhappy与sad本应视为相同,我们如有事先设定 sad 和 unhappy 是同义词,就会将输入里的 unhappy 改成 sad,这样就能捕获到关键词了,省去了再设置unhappy为关键词。
每个关键词都有数个分解规则,分解规则可以看作是对关键词所在语句的句型划分。假设关键词 remember 有两个分解规则:
关键词: remember 5
分解规则: (……)i remember(……)
分解规则: (……)do you remember(……)
每个规则会拆分并提取输入语句中的部分字符,do you remember my name 明显符合第二个分解规则,它就会被这么划分:
()do you remember(my name),其中 [0]: 空字符串;[1]: my name
分解之后,还需要对分解出来的字符串进行一些后处理替换,它们大多是人称代词上的变化,例如,将 you 改成 me、my 改成 your 等。当前划分得到的字符串就会变为:
[0]: 空字符串;[1]: your name
就是运用重组规则了,重组规则与分解规则相关联,每个分解规则都可以有多个重组规则,至于要用哪个,取决于你的设计,在原版ELIZA中是采取了逐个使用的方式,这次用第一条,下次再需要时,就用第二天……全用用完后就返回第一条。假设 (……)do you remember(……) 有如下5种重组规则:
关键词: remember 5
分解规则: (……)do you remember(……)
重组规则: Did you think I would forget (1)?
重组规则: Why do you think I should recall (1) now?
重组规则: What about (1)?
重组规则: goto what
重组规则: You mentioned (1)?
这些重组规则所写的语句就是ELIZA的回复,但可以看到有些语句中有 (n) 的元素,这就是说要将 (n) 换成分解规则中划分出的 [n] 字符串。第四条重组规则也有点奇怪 goto what,这是在说要跳转到 what 关键词的分解重组方式去。以第一条重组规则为例,最终重组出的语句就是ELIZA给出的回复:
Did you think I would forget your name?
当然,这是在一切都顺利的情况下,来看看大体流程吧:
可以看出,在不顺利的情况下,还有用来兜底的“记忆语句”和“默认回复”。所谓记忆语句其实是一个特殊的分解规则,所以它也与某个关键词绑定,但这个特殊分解规则匹配成功时,重组的语句并不作为返回语句而是存储到记忆语句合集里,并继续找到常规的分解规则作为正常回复。
也就是说这种需要记忆的场合,其实就是一次性执行了两次分解规则,一次得到的特殊结果存储下来,当遇到“听不懂”的话时搬出来岔开话题用;另一次得到的常规规则用来这次回复。
正如ELIZA论文里提到的那样,它更像是个翻译处理机器,它虽不智能,但却能用很少的代码就伪装出了智能的假象。它的智能表现完全取决于关键词、分解规则、重组规则等的设计,而这些可以独立出来成为可替换的部分,因此,它的“理解”能力是可以自由扩展的。下面就来尝试用 C# 实现 ELIZA。
代码实现
规则文本的设计参考了 https://github.com/thesephist/eliza?tab=readme-ov-file
ELIZA 中很多逻辑都与字符串的处理相关,稍显麻烦的地方在于句式的分解匹配和同义词等的替换,所幸正则表达式能极大地帮助我们。
规则文本
我们将关键词规则等可替换的文本都写在一个txt文件中,每行开头都加上标签:,方便后续进行读取
# ======================================
# 初始问候(initial)
# ======================================
initial: How do you do.
initial: Please tell me your problem.
initial: I'm here to listen—feel free to share what's on your mind.
# ======================================
# 告别语(final)
# ======================================
final: Goodbye.
final: Thank you for talking to me.
final: Take care of yourself, and feel free to reach out anytime.
# ======================================
# 默认回应(default)
# ======================================
default: I'm not sure I understand. Could you say more?
default: Can you elaborate on that thought a bit more?
default: That's interesting—would you mind explaining further?
# ======================================
# 预处理替换(pre)
# ======================================
pre: dreamt dreamed
pre: dreams dream
pre: maybe perhaps
pre: you're you are
pre: i'm i am
# ======================================
# 后处理替换(post)- 人称转换&语义适配
# ======================================
post: myself yourself
post: yourself myself
post: i you
post: you I
post: my your
post: i'm you are
# ======================================
# 同义词组(synon)- 语义关联
# ======================================
synon: belief|feel|think|believe|wish
synon: cannot|can't|can not
synon: desire|want|need
synon: sad|unhappy|depressed|sick
# ======================================
# 关键词规则(key)- 优先级&分解逻辑、重组逻辑
# ======================================
key: my 2
decomp: &(.*)\bmy\b(.*)
reasmb: Lets discuss further why your (1).
reasmb: Earlier you said your (1).
reasmb: But your (1).
reasmb: Does that have anything to do with the fact that your (1)?
key: i
decomp: (.*)\bi am\b(.*)
reasmb: Is it because you are (1) that you came to me?
reasmb: How long have you been (1)?
reasmb: Do you believe it is normal to be (1)?
reasmb: Do you enjoy being (1)?
decomp: (.*)\bi\b \b@cannot\b(.*)
reasmb: How do you think that you can't (1)?
reasmb: Have you tried?
reasmb: Perhaps you could (1) now.
reasmb: Do you really want to be able to (1)?
decomp: (.*)\bi am\b(.*)\b@sad\b(.*)
reasmb: I am sorry to hear that you are (2).
reasmb: Do you think that coming here will help you not to be (2)?
reasmb: I'm sure it's not pleasant to be (2).
reasmb: Can you explain what made you (2)?
初始问候(initial)、告别语(final)、默认回应(default)无需进一步说明,单纯的语句而已。预处理替换(pre)和后处理替换(post)都意味着将前者改为后者,例如:pre: dreamt dreamed 就是将 dreamt 改为 dreamed。
同义词组(synon)都是一个词后面更着数个词,意为后面的词都与第一个词同义,例如:synon: desire|want|need 意为 want、need 都是 desire的同义词。
key(关键词)很好理解,如果关键词后有接数字的,就是采用该数字作为其优先级,没有数字的就采用默认优先级。decomp(分解规则)后面接的那一串就是正则表达式,正则表达式(正则表达式测试网站: https://regex101.com/r/loNR8V/1 )可以很好地进行字符串匹配和划分,可以用括号自定义需要被划分成一块的内容,方便后续代码中处理,例如:
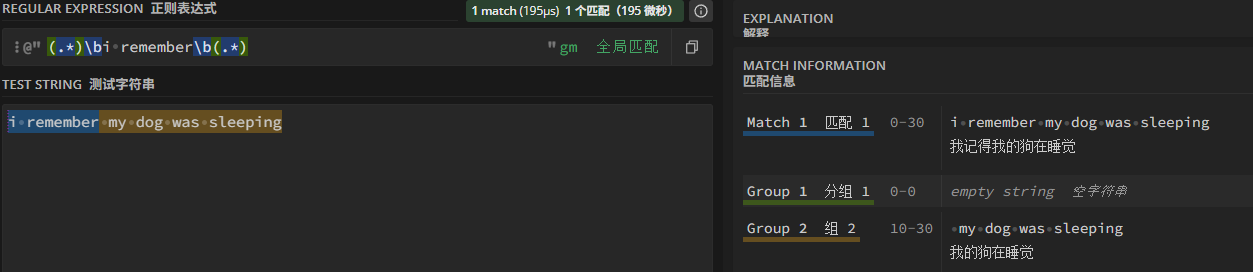
有个分解规则前方带着一个 &,这个就是用作记忆语句匹配的标记,它所重组的语句会被存入记忆合集中。
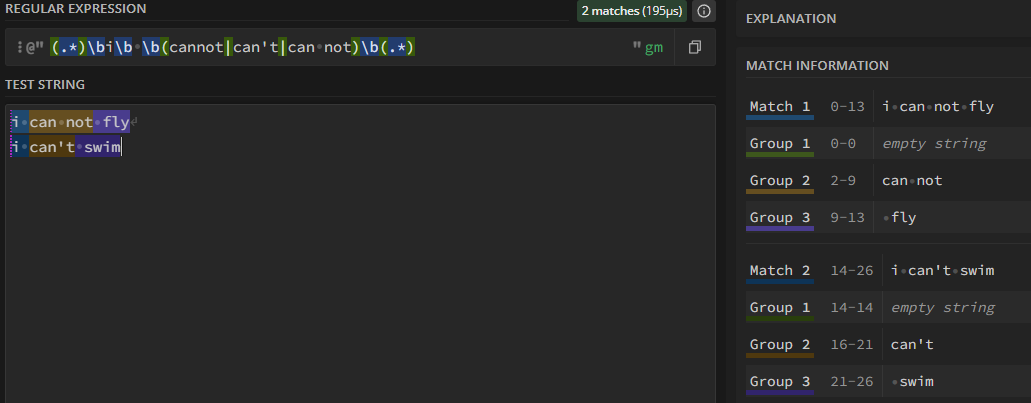
但有一些奇怪的词,它们的前面带着 @,这是在说该词具有同义词,要进一步处理。但为了简化逻辑,这里确保 @ 后接的是 synon: 后的第一个词(主词)。例如:synon: cannot|can't|can not,它的相关同义词使用就应该像这样:(.*)\bi\b \b@cannot\b(.*),而不是 (.*)\bi\b \b@can't\b(.*)。
这样一来,在代码里它就会被处理成这样的正则表达式:(.*)\bi\b \b(cannot|can't|can not)\b(.*),如此一来就能匹配多个词了:
至于重组规则就很简单了,其中的 (n) 还是和之前说的相似,意为正则表达式所捕获到的所有分组中的下标,重组规则中的 (0) 就是分解规则中第一个括号所捕获的内容,(1) 就是第二个括号捕获的内容,以此类推,但注意同义词也算一个括号。
下面就是正式代码的实现了。
ElizaStyle
我们用 ElizaStyle_SO 类将规则文本的内容转化为真正的规则。先用两个简单的类来表达关键词:
public class ElizaKeyword
{
public string word; //关键词字符串
public int priority; //优先级
public List<KeywordRule> ruleList; //规则
public ElizaKeyword(string keyword, int priority)
{
word = keyword;
this.priority = priority;
ruleList = new List<KeywordRule>();
}
}
public class KeywordRule
{
public string decomp; // 原始decomp正则表达式(含@同义词标记+可能的记忆标记)
public string processedDecomp; // 初始化处理后的最终正则(无记忆标记+同义词替换完成)
public List<string> reasmbList; // 重组规则
[NonSerialized] public int reasmbIndex = 0;
}
来看看我们需要准备的变量:
public class ElizaStyle_SO : ScriptableObject
{
[SerializeField] private TextAsset textAsset; //规则文本
public Dictionary<string, ElizaKeyword> keywords = new(); //关键字合集
[Header("对话规则")]
public List<string> initialGreetings = new(); // initial: 初始问候
public List<string> finalFarewell = new(); // final: 告别语
public List<string> defaultReply = new(); // default: 无法理解时的回复
[Header("文本替换规则")]
[SerializeField] private string synonMarker = "@"; // 同义词标记(默认@)
public Dictionary<string, string> preReplacements = new(); // pre: 输入预处理替换
public Dictionary<string, string> postReplacements = new(); // post: 输出后处理替换
[Header("记忆配置")]
public string memoryDecompMarker = "&"; // 记忆标记(默认&)
public int maxMemoryCount = 10; // 记忆语句合集的大小
public int memoryCallInterval = 3; //调用记忆的间隔
}
同义词的记录使用字典存储的,字典的键为每个词,值为处理后的正则字符串。这么做的目的是为了图方便,只需要在原本的写法上套个括号,就是一个表达同义词的正则表达式了。例如 synon: belief|feel|think|believe|wish,它加入字典就是这样的:
synonymGroups
key: belief
value: (belief|feel|think|believe|wish)
key: feel
value: (belief|feel|think|believe|wish)
key: think
value: (belief|feel|think|believe|wish)
……
记忆语句相关的还有两个变量:maxMemoryCount 是记忆语句合集的大小,记忆语句合集会用一个队列表示,队列大小达到了 maxMemoryCount,此时又要入队新的记忆语句,就会将队首的元素出队再入队。memoryCallInterval 是调用记忆的间隔,并不是每次没得到关键词时都调用记忆,而是经过了memoryCallInterval次后才调用记忆 (更拟人些
完整的 ElizaStyle 类如下,它并没有什么复杂的逻辑,九成都是对字符串的拆分、替换以及正则表达式的拼凑:
using System;
using System.Collections.Generic;
using System.Text.RegularExpressions;
using UnityEngine;
[CreateAssetMenu(fileName = "Eliza_", menuName = "BW_Agent/ElizaStyle")]
public class ElizaStyle_SO : ScriptableObject
{
public const string GOTO_PREFIX = "goto ";
private static string synonymPattern;
[SerializeField] private TextAsset textAsset; //规则文本
public Dictionary<string, ElizaKeyword> keywords = new(); //关键字合集
[Header("对话规则")]
public List<string> initialGreetings = new(); // initial: 初始问候
public List<string> finalFarewell = new(); // final: 告别语
public List<string> defaultReply = new(); // default: 无法理解时的回复
[Header("文本替换规则")]
[SerializeField] private string synonMarker = "@"; // 同义词标记(默认@)
public Dictionary<string, string> preReplacements = new(); // pre: 输入预处理替换
public Dictionary<string, string> postReplacements = new(); // post: 输出后处理替换
[Header("记忆配置")]
public string memoryDecompMarker = "&"; // 记忆标记(默认&)
public int maxMemoryCount = 10; // 记忆语句合集的大小
public int memoryCallInterval = 3; //调用记忆的间隔
private void OnEnable()
{
InitAllRules();
}
/// <summary>
/// 解析文本中的所有规则(含同义词替换处理)
/// </summary>
private void InitAllRules()
{
if (textAsset == null)
{
Debug.LogError($"[{nameof(ElizaStyle_SO)}] 未指定TextAsset!");
return;
}
// 同义词字典:键=任意同义词,值=带单词边界+转义的完整正则字符串
Dictionary<string, string> synonymMap = new();
synonymPattern = $@"\b{Regex.Escape(synonMarker)}(\w+)\b";
var lines = textAsset.text.Split(new string[]{"\n","\r"}, StringSplitOptions.RemoveEmptyEntries);
ElizaKeyword currentKeyword = null;
KeywordRule currentRule = null;
string trimmedLine, tag, contentPart;
for (int i = 0, colonIndex; i < lines.Length; ++i)
{
trimmedLine = lines[i];
if (string.IsNullOrEmpty(trimmedLine))
continue;
colonIndex = trimmedLine.IndexOf(':');
if (colonIndex == -1)
continue;
tag = trimmedLine[..colonIndex].Trim();
contentPart = trimmedLine[(colonIndex + 1)..].Trim();
// 解析不同标签的规则
switch (tag)
{
case "initial":
initialGreetings.Add(contentPart); // 初始问候
break;
case "final":
finalFarewell.Add(contentPart); // 告别语
break;
case "default":
defaultReply.Add(contentPart); // 无法理解时,默认回复
break;
case "pre":
ParseReplacementLine(contentPart, preReplacements); // 输入预处理替换
break;
case "post":
ParseReplacementLine(contentPart, postReplacements); // 输出后处理替换
break;
case "synon":
ParseSynonymLine(contentPart, synonymMap); // 解析同义词(无需传递字典,直接操作成员变量)
break;
case "key":
ParseKeyLine(contentPart, ref currentKeyword, ref currentRule); // 关键词
break;
case "decomp":
ParseDecompLine(contentPart, ref currentKeyword, ref currentRule, synonymMap); // 分解规则(无需传递synonymGroups)
break;
case "reasmb":
currentRule?.reasmbList.Add(contentPart);; // 重组规则
break;
}
}
}
/// <summary>
/// 查找关键词
/// </summary>
public ElizaKeyword GetKeyword(string lowerWord)
{
if (string.IsNullOrEmpty(lowerWord))
{
return null;
}
keywords.TryGetValue(lowerWord, out var res);
return res;
}
/// <summary>
/// 解析同义词组:每个同义词都作为键,值为完整正则字符串
/// </summary>
private void ParseSynonymLine(string contentPart, Dictionary<string, string> synonymMap)
{
string rootWord = contentPart[..contentPart.IndexOf("|")];
string finalRegex = $@"({contentPart})";
synonymMap[rootWord] = finalRegex;
}
/// <summary>
/// 处理decomp中的@同义词标记:直接从synonymMap取正则字符串
/// </summary>
private string ProcessSynonymInDecomp(string decompWithoutMarker, Dictionary<string, string> synonymMap)
{
if (string.IsNullOrWhiteSpace(decompWithoutMarker) || string.IsNullOrEmpty(synonMarker))
{
return decompWithoutMarker;
}
// 匹配@+任意同义词(支持多词/特殊字符)
return Regex.Replace(decompWithoutMarker, synonymPattern, match =>
{
string targetWord = match.Groups[1].Value.Trim();
return synonymMap.TryGetValue(targetWord, out string regexStr) ? regexStr : match.Value; // 直接从字典取正则字符串,无则返回原始标记
}, RegexOptions.IgnoreCase);
}
/// <summary>
/// 解析decomp规则(含记忆标记移除+同义词替换)
/// </summary>
private void ParseDecompLine(string contentPart, ref ElizaKeyword currentKeyword, ref KeywordRule currentRule, Dictionary<string, string> synonymMap)
{
if (currentKeyword != null)
{
// 移除记忆标记,得到纯decomp
string decompWithoutMarker = contentPart;
if (!string.IsNullOrEmpty(memoryDecompMarker) && contentPart.StartsWith(memoryDecompMarker))
{
decompWithoutMarker = contentPart[memoryDecompMarker.Length..];
}
// 替换@同义词标记,生成最终正则(无需传递字典)
string processedDecomp = ProcessSynonymInDecomp(decompWithoutMarker, synonymMap);
// 创建规则,保存原始decomp和处理后正则
currentRule = new KeywordRule
{
decomp = contentPart, // 原始decomp(含记忆标记,不修改)
processedDecomp = processedDecomp, // 最终匹配用的正则
reasmbList = new List<string>()
};
currentKeyword.ruleList.Add(currentRule);
}
}
// 两词替换
private void ParseReplacementLine(string contentPart, Dictionary<string, string> targetDict)
{
int spaceIndex = contentPart.IndexOf(" ");
string original, replacement;
if (spaceIndex != -1)
{
original = contentPart[..spaceIndex];
replacement = contentPart[(spaceIndex + 1)..];
targetDict.TryAdd(original, replacement);
}
}
// 将文本中的关键词与其优先级(如有)提取
private void ParseKeyLine(string contentPart, ref ElizaKeyword currentKeyword, ref KeywordRule currentRule)
{
string[] keyParts = contentPart.Split(" ", StringSplitOptions.RemoveEmptyEntries);
if (keyParts.Length != 0)
{
string keyword = keyParts[0];
int priority = 0; // 默认优先级
if (keyParts.Length > 1) // 如果被分成了两部分,说明有设置优先级
{
int.TryParse(keyParts[1], out priority);
priority = Math.Max(0, priority);
}
if (keywords.ContainsKey(keyword))
{
currentKeyword = keywords[keyword];
currentKeyword.priority = priority;
}
else
{
currentKeyword = new ElizaKeyword(keyword, priority);
keywords.Add(keyword, currentKeyword);
}
currentRule = null;
}
}
}
Eliza
接下来就是用于输入语句处理、生成回复的Eliza类了,里面同样有很多用于处理字符串与正则表达式的逻辑,就稍稍说下实现上值得一提的部分内容。(更多可以看代码的注释)
首先是论文中提到的那个既可以在头部插入也可以在尾部插入的神秘的栈,虽说不知道作者当时是怎么实现这个数据结构的,但现在我们有现成的LinkedList(链表) 可以做到。
在Eliza类中,我打算兼容中文输入分析,于是使用了 JiebaNet,这是一个第三方库,主要作用是将中文语句拆分成像英语一样的,用空格隔开的模样,这样就可以复用处理英文的方式来处理中文。例如:
原句:
我今天想早点睡觉。
Jieba分词后:
我 今天 想 早点 睡觉。
JiebaNet 在 Visual Studio 中可以下载(项目中已经包含了),但记得要用net40下的动态链接库。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text.RegularExpressions;
using JiebaNet.Segmenter;
[Serializable]
public class Eliza
{
// 预编译标点正则
private static readonly Regex PunctuationRegex = new(@"[,.?!;:\""()\[\]]", RegexOptions.Compiled);
// 句末标点拆分句子
private static readonly string[] sentenceSeparators = new string[] { ".", "。", "!", "!", "?", "?", ";", ";", ",", "," };
public ElizaStyle_SO style;
private LinkedList<ElizaKeyword> keyDeque = new(); // 关键词收集器
private JiebaSegmenter jieba; // 结巴分词器
private Queue<string> memoryQueue = new(); // 记忆容器
private int memoryCallCounter; //记忆请求调用次数,当达到style.memoryCallInterval时尝试调用记忆语句
private bool isChineseMode = false; // 是否启用中文模式
private Random random = new(); // 随机数生成器
public Eliza(ElizaStyle_SO style, JiebaSegmenter jieba)
{
this.jieba = jieba;
this.style = style;
memoryCallCounter = style.memoryCallInterval;
}
/// <summary>
/// 核心响应函数(集成所有规则)
/// </summary>
public string Respond(string input)
{
if (!string.IsNullOrWhiteSpace(input) && style != null)
{
isChineseMode = MostlyChinese(input); // 判断输入是否是中文
if(isChineseMode)
{
input = string.Join(" ", jieba.Cut(input)); // 是中文就用jieba进行分词
}
var processedInputs = PreprocessInput(input); // 预处理输入
foreach(var processedInput in processedInputs) // 挨句寻找关键词
{
ReadInput(processedInput);
string keywordResponse = TryGetKeywordResponse(processedInput); //获取匹配成功的关键词的重组回复
if (!string.IsNullOrEmpty(keywordResponse))
{
return keywordResponse;
}
}
string memoryResponse = TryGetMemoryResponse(); //尝试获取记忆语句
if (!string.IsNullOrEmpty(memoryResponse))
{
return memoryResponse; // 调用记忆
}
}
return GetDefaultReply();// 默认回应
}
/// <summary>
/// 应用输入预处理:去标点→转小写→pre替换→压缩空格
/// </summary>
private IEnumerable<string> PreprocessInput(string input)
{
string[] rawSentences = input.Split(sentenceSeparators, StringSplitOptions.RemoveEmptyEntries);
foreach (string rawSent in rawSentences)
{
string trimmedSent = rawSent.Trim();
string noPunct = PunctuationRegex.Replace(trimmedSent, " "); // 去标点
string lowerCase = noPunct.ToLowerInvariant(); // 转小写
string withPre = ApplyReplacements(lowerCase, style.preReplacements); // pre替换
string compressed = Regex.Replace(withPre, @"\s+", " ").Trim(); // 压缩空格
if (!string.IsNullOrEmpty(compressed))
{
yield return compressed; // 返回当前预处理后的句子,暂停迭代等待下一次请求
}
}
}
/// <summary>
/// 通用替换方法(支持pre/post规则)
/// </summary>
private string ApplyReplacements(string text, Dictionary<string, string> replacements)
{
if (replacements == null || replacements.Count == 0)
{
return text;
}
// 按空格拆分文本为单词数组
string[] words = text.Split(' ', StringSplitOptions.RemoveEmptyEntries);
// 遍历每个单词,查找替换字典,命中则替换,未命中保留原词
for (int i = 0; i < words.Length; ++i)
{
if (replacements.TryGetValue(words[i], out string replacement))
{
words[i] = replacement;
}
}
return string.Join(" ", words); // 用空格重组单词
}
/// <summary>
/// 读取输入时集成同义词规则(synon)
/// </summary>
private void ReadInput(string processedInput)
{
keyDeque.Clear(); // 清空双端队列
if (!string.IsNullOrWhiteSpace(processedInput) && style != null && style.keywords != null)
{
var words = processedInput.Split(' ', StringSplitOptions.RemoveEmptyEntries);
ElizaKeyword keyword;
for(int i = 0; i < words.Length; ++i)
{
keyword = style.GetKeyword(words[i]);
if (keyword != null)
{
if (keyDeque.Count == 0)
{
keyDeque.AddFirst(keyword);// 队列空,直接插入(顶部)
}
else if (keyword.priority > keyDeque.First.Value.priority)// 比较新关键字与当前顶部元素的优先级
{
keyDeque.AddFirst(keyword);// 新关键字优先级更高 → 插入顶部(优先匹配)
}
else
{
keyDeque.AddLast(keyword);// 新关键字优先级更低或相等 → 插入底部(延后匹配)
}
}
}
}
}
private string TryGetKeywordResponse(string inputWords)
{
ElizaKeyword currentKey;
string response;
while (keyDeque.Count > 0)
{
currentKey = keyDeque.First.Value; // 取出顶部元素(不删除,先尝试匹配)
response = GetReasmb(currentKey, inputWords);
if (!string.IsNullOrEmpty(response))
{
keyDeque.RemoveFirst();// 匹配成功,移除当前顶部元素(避免重复匹配)
return response;
}
else
{
keyDeque.RemoveFirst();// 匹配失败,移除当前顶部元素,尝试下一个
}
}
return null;
}
/// <summary>
/// 尝试获取记忆语句用以回复
/// </summary>
private string TryGetMemoryResponse()
{
if (memoryQueue.Count != 0)
{
if (++memoryCallCounter >= style.memoryCallInterval)
{
memoryCallCounter = 0;
return memoryQueue.Dequeue();
}
}
return null;
}
/// <summary>
/// 生成回应(使用处理后的正则匹配)
/// </summary>
private string GetReasmb(ElizaKeyword keyword, string inputWords)
{
if (keyword != null && keyword.ruleList != null && style != null)
{
bool saveToMemory;
string reasmbResult;
var ruleList = keyword.ruleList;
for(int i = 0; i < ruleList.Count; ++i)
{
// 判断是否需要存入记忆(根据原始decomp是否含记忆标记)
saveToMemory = ruleList[i].decomp.StartsWith(style.memoryDecompMarker);
// 直接使用初始化时处理好的正则进行匹配
if (MatchDecomp(ruleList[i].processedDecomp, inputWords, out List<string> matchGroups))
{
reasmbResult = ProcessReasmb(ruleList[i], matchGroups);
if (!string.IsNullOrEmpty(reasmbResult))
{
if (saveToMemory) //如果是记忆语句,则加入到记忆容器中,并继续查找其他重组规则
{
while (memoryQueue.Count >= style.maxMemoryCount)
{
memoryQueue.Dequeue();
}
memoryQueue.Enqueue(reasmbResult);
continue;
}
return reasmbResult;
}
}
}
}
return null;
}
/// <summary>
/// 正则匹配(直接使用处理后的正则)
/// </summary>
private bool MatchDecomp(string processedDecomp, string inputWords, out List<string> matchGroups)
{
matchGroups = new List<string>();
if (string.IsNullOrWhiteSpace(processedDecomp) || string.IsNullOrWhiteSpace(inputWords))
return false;
Match match = Regex.Match(inputWords, processedDecomp, RegexOptions.IgnoreCase);
if (!match.Success)
return false;
string groupValue; // 收集所有捕获分组(索引从1开始,索引0为完整字符串)
for (int i = 1; i < match.Groups.Count; ++i)
{
groupValue = match.Groups[i].Value.Trim();
//每个分组都进行后处理替换
matchGroups.Add(ApplyReplacements(groupValue, style.postReplacements));
}
return true;
}
/// <summary>
/// 根据重组规则,获取重组语句
/// </summary>
private string ProcessReasmb(KeywordRule rule, List<string> matchGroups)
{
List<string> reasmbList = rule.reasmbList;
if (reasmbList == null || reasmbList.Count == 0)
{
return null;
}
string reasmb = reasmbList[rule.reasmbIndex];
rule.reasmbIndex = (rule.reasmbIndex + 1) % reasmbList.Count;
if (reasmb.StartsWith(ElizaStyle_SO.GOTO_PREFIX, StringComparison.OrdinalIgnoreCase))
{
string targetKey = reasmb[ElizaStyle_SO.GOTO_PREFIX.Length..].Trim().ToLowerInvariant();
if (style.keywords.TryGetValue(targetKey, out ElizaKeyword targetKeyword))
{
// 合并所有分组为字符串,传递给goto目标
string gotoInput = string.Join(" ", matchGroups.Where(g => !string.IsNullOrEmpty(g)));
return GetReasmb(targetKeyword, gotoInput);
}
return null;
}
// 用处理后的分组内容替换 (n) 标记
return Regex.Replace(reasmb, @"\((\d+)\)", match =>
{
if (int.TryParse(match.Groups[1].Value, out int groupIndex) &&
groupIndex >= 0 && groupIndex <= matchGroups.Count)
{
return isChineseMode ? matchGroups[groupIndex].Replace(" ","") : matchGroups[groupIndex];
}
return match.Value;
});
}
public string GetInitialGreeting()
{
return style.initialGreetings[random.Next(style.initialGreetings.Count)];
}
public string GetFinalFarewell()
{
return style.finalFarewell[random.Next(style.finalFarewell.Count)];
}
private string GetDefaultReply()
{
return style.defaultReply[random.Next(style.defaultReply.Count)];
}
/// <summary>
/// 判断字符串主要是中文还是英文
/// </summary>
/// <param name="text">待判断的字符串</param>
/// <returns> true 说明以中文为主,false 说明以英文 为主</returns>
public static bool MostlyChinese(string text)
{
char c;
int chineseCount = 0, englishCount = 0;
for(int i = 0; i < text.Length; ++i)
{
c = text[i];
if (c >= 0x4E00 && c <= 0x9FA5)
{
chineseCount++;
}
else if ((c >= 'A' && c <= 'Z') || (c >= 'a' && c <= 'z'))
{
englishCount++;
}
}
return chineseCount > englishCount;
}
}
尾声
由于 ELIZA 绝大多数逻辑都是字符串与正则表达式的匹配拼凑,这次并没有讲太多代码。我们也了解到了 ELIZA 的智能程度不在于它的代码,而是规则设计,更像是心理学上的巧妙作用。约瑟夫也在论文中提及:人类倾向于对符合交互预期的回应赋予 “智能” 属性 —— 即使程序无任何理解能力,仅重复、重组用户输入或按规则回应,也能让人类产生 “被理解” 的错觉。智能的核心是 “理解” 而非 “回应”,像ELIZA可模拟智能的外在行为,但无内在认知的模拟,算不上真正的智能。
有意思的是,游戏中的人工智能反而更应当注重这种表层的模仿,而非真实智能的实现,这一点在《Game AI Pro》系列书籍中时有提及。与其做一个能真正思考的NPC,不如做一个看起来能思考的NPC,二者对于玩家来说都是一样的,而后者对开发者来说却更容易些。之前提到,玩家会去“宽容”地脑补NPC的智能,当你做好了这种“表面工作”,你的AI在玩家眼里也会聪明起来。
《雨世界》的开发者就曾在2016年的GDC演讲上提到过游戏中使用细腻的生成式动画所带来的好处:“玩家会看到一个生物做出了一些有趣的事情,而这不一定是预设的行为。玩家会从所发生的事情中推断出:‘哦!这个生物在生我的气!’虽然事实并非如此,但因为所有元素(行为动画)都清晰可见,这就为每个生物都赋予了一定的个性。这非常有趣。”

更早些的还有2005年的《Façade》,这是最早的一批可自由输入对话与NPC交流的游戏,这个游戏NPC的对话也是基于规则的回复。而当NPC遇到无法理解的话语时,他们不会明说“我听不懂”,而是用他们丰富的面部表情表露出不解的意味,留给了玩家脑补的空间。(b站上也这个游戏的游玩视频:https://www.bilibili.com/video/BV1Us41117Qw)

这一点也是个人觉得游戏人工智能有趣的地方,开发者需要做好一个魔术师而非一个魔法师。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号