Hadoop学习笔记(七):初识spark
1. spark的安装:
a). 首先复制一台虚拟机出来(复制任意一台master和slave即可),然后将其ip修改为192.168.XX.200,并将其hostname更改为c(hostnamectl set-hostname c)。然后再/etc/hosts文件中添加对本机的解析。最后重启网络服务。
b). 到官网下载spark(spark.apache.org,记住要下载对应hadoop版本的,这里下载的是spark-2.1.1-bin-hadoop2.7.tgz),并上传至/usr/local目录,然后解压,重命名为spark。
2. spark的运行模式:
a) local模式
b) standalone模式
c) yarn模式
d) mesos模式
3. 进入到spark目录下,执行命令:
./bin/spark-submit --class org.apache.spark.examples.SparkPi ./examples/jars/spark-examples_2.11-2.1.0.jar 10000
该命令表示提交一个spark例子程序,后边的10000表示10000个任务,该程序可以计算圆周率,最后的数字越大最后计算出来的结果越精确。提交任务后可以在宿主机输入IP地址:4040进行查看(该程序结束后,就不能访问该页面了)
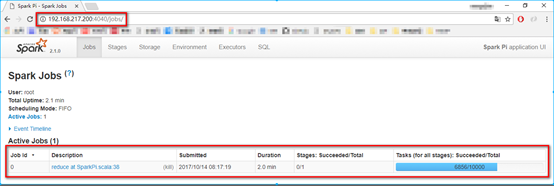
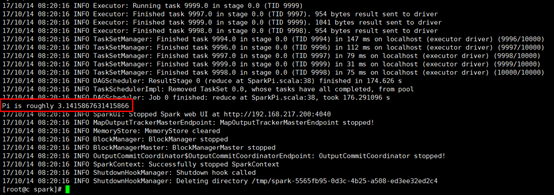
4. 等该任务执行结束后,观察执行结果:
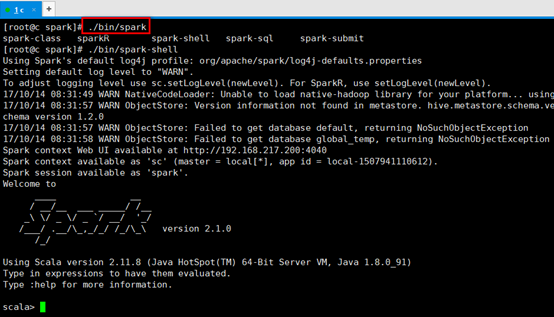
5. 进入spark-shell命令模式,输入:./bin/spark-shell
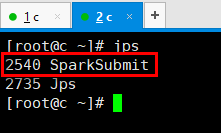
新打开一个连接窗口,输入命令jps,可以看到又启动了一个SparkSubmit服务:
6. spark-shell里敲的命令可以转换为一个job,通过SparkSubmit提交给spark,最后的结果在spark-shell里进行展示。
7. RDD(简言RDD就是一个数据集合,分布式存放,可以理解为里边装了一条条的数据)
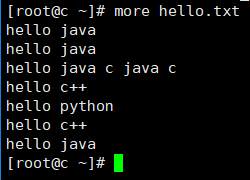
8. 在root目录下创建hello.txt文件,内容如下:
9. 执行val lineRDD = sc.textFile(“/root/hello.txt”)命令,其中,sc为ScalaContent对象,其Scala的上下文对象,从结果可以看出来,该命令的执行结果为一个RDD数组,数组里边的元素为String类型。

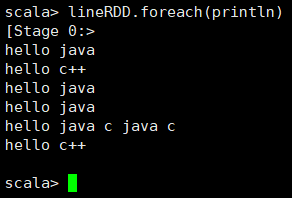
10. 遍历得到的数组,输入命令:lineRDD.foreach(println)观察结果
11. 执行lineRDD.collect命令,将lineRDD转换成一个Array

12. 执行val wordRDD = lineRDD.flatMap(line => line.split(" "))命令,将lineRDD里的每一个单词进行拆分。

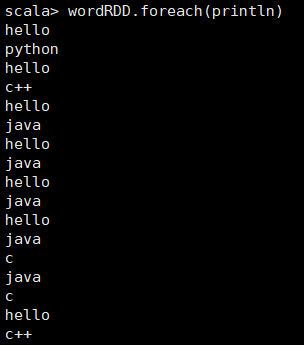
13. 执行wordRDD.foreach(println),查看wordRDD内容:
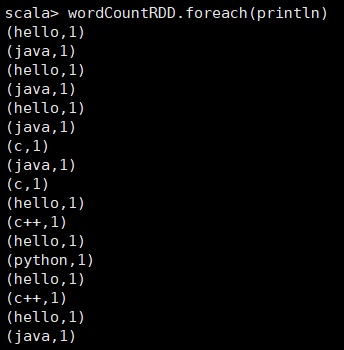
14. 执行val wordCountRDD = wordRDD.map(word => (word, 1))命令,该命令是遍历wordRDD里的每一个元素,并将该元素变成一个元组(key-value格式,key为该单词,value为1),然后输入wordCountRDD.foreach(println)观察其内容:
15. 执行var resultRDD = wordCountRDD.reduceByKey((x, y) => x + y)命令,熟悉MapReduce的应该知道,该命令相当于MapReduce中reduce的缩减过程,即通过key进行缩减,将相同key的value值(即x和y)进行相加,然后作为一个新的元组,进行下一次的reduce操作。遍历resultRDD进行结果的查看:
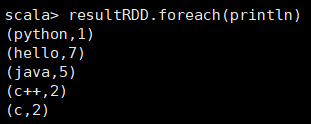
16. 上面所有的操作可以用一句scala语句来实现:

17. 去到输出目录查看,这个应该很眼熟了:
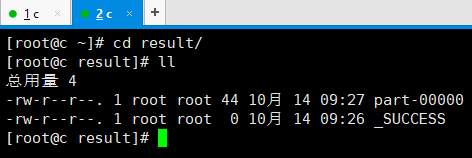
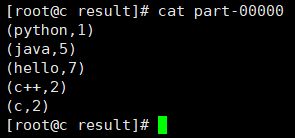
18. 查看结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号