Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models(综述)
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models(综述)
[2503.16419v3.pdf]
[2503.16419_zh_CN.pdf]
CoT, Chain of Thought:一种通过将复杂问题分解成更长、更详细的推理步骤链来引导大型语言模型,从而解决更具挑战性任务的增强版思维链方法。
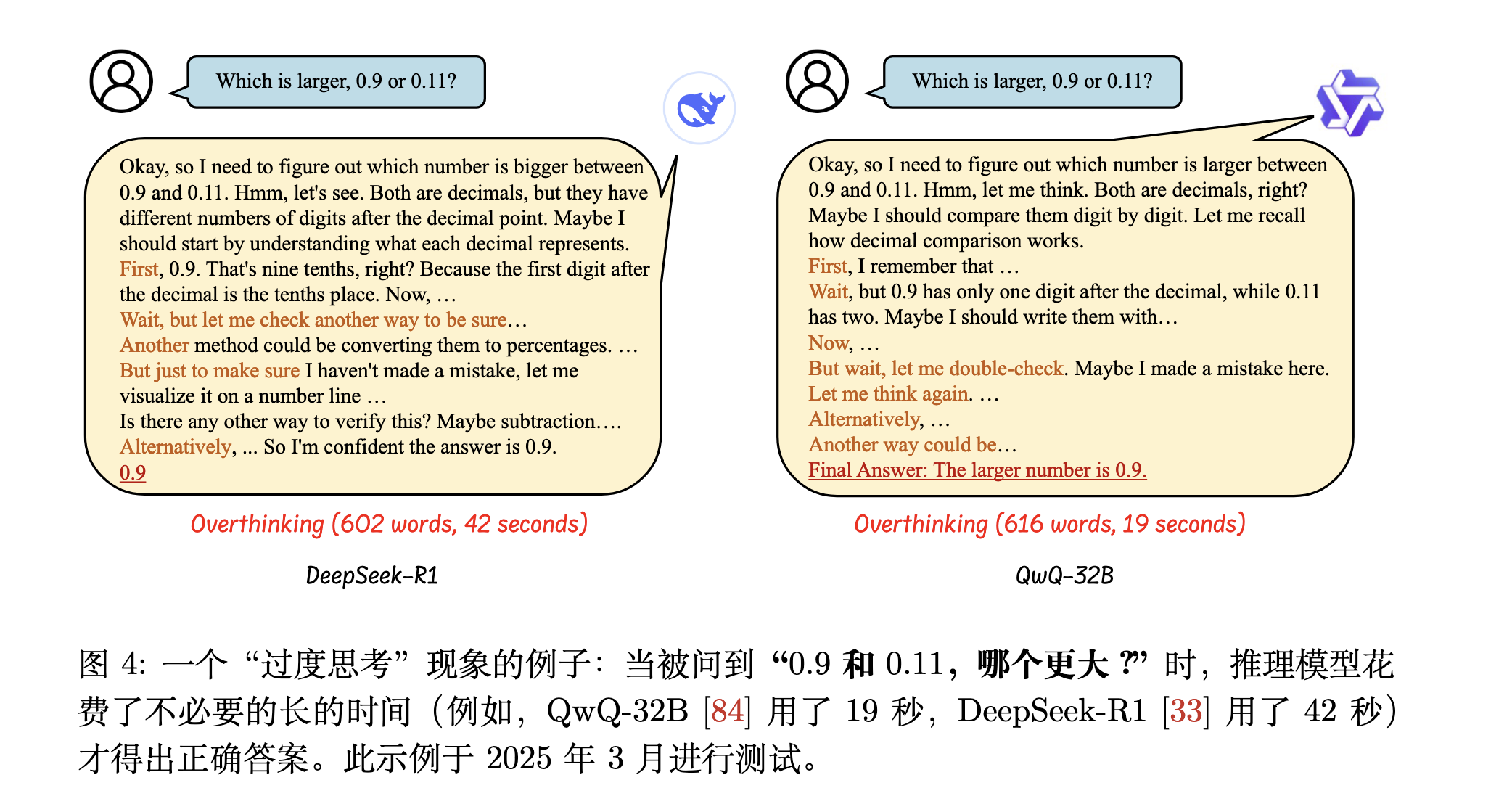
Overthinking 指的是长链 CoT 推理模型中生成过于详细或不必要的复杂推理步骤的情况,最终降低了它们的问题解决效率。
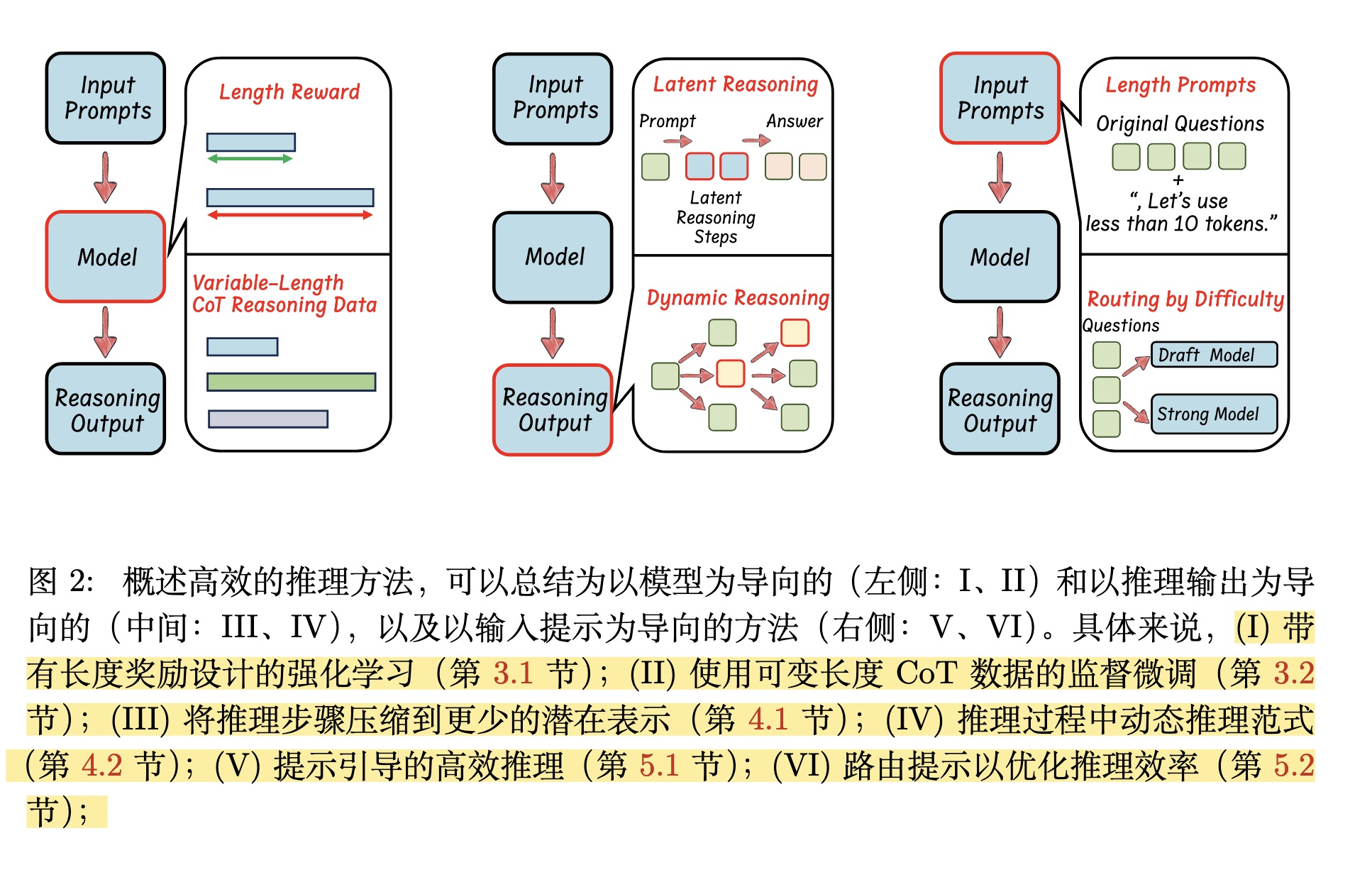
CoT模型的优化方向主要有两个:模型压缩和高效推理 模型压缩 (Model Compression):关注的是“模型瘦身”。它通过量化、KV-Cache压缩等技术,把模型本身变小或减少它在运行时占用的内存,目的是让模型能在更轻量级的硬件上运行,加快推理速度。这是一种静态的优化。 高效推理 (Efficient Reasoning):关注的是“思维减负”。它不改变模型的大小,而是优化模型生成答案的过程。通过减少不必要的“思考”步骤(例如,在思维链中去掉冗余环节),让模型更快地得出智能、简洁的答案。这是一种动态的优化。 |
高效推理 (Efficient Reasoning)可以从三个方向优化:
Model
Reasoning Output
Input Prompts
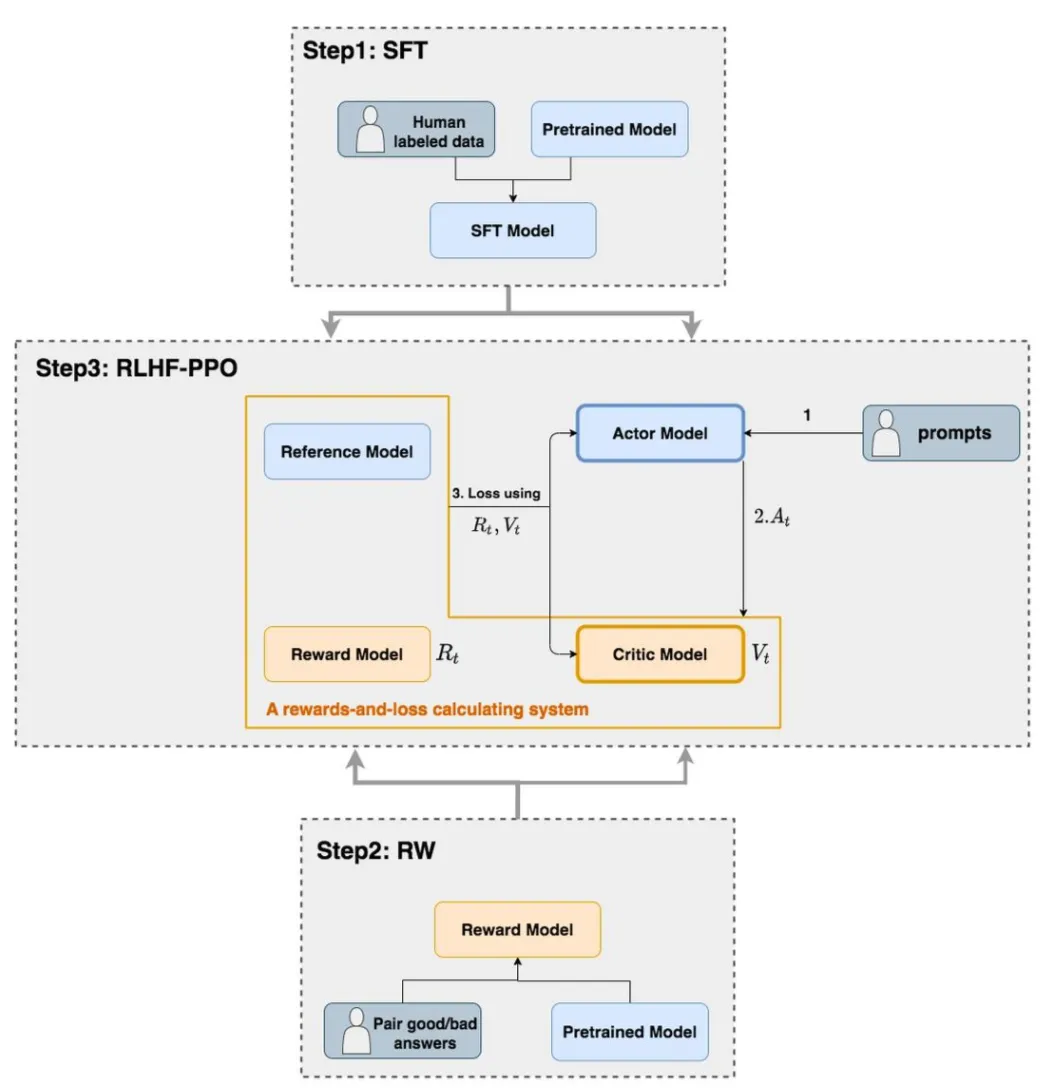
RLHF(基于人类反馈的强化学习) 过程中,LLM 一般先进行 SFT 监督微调(Step 1),再进行 RL 强化学习微调(Step 2,3)
从模型的角度来看,这些工作专注于对 LLM 进行微调,以提高其简洁高效推理的内在能力。两种优化方式:
带有长度奖励设计的强化学习,倾向于在强化学习RL过程中微调模型
使用可变长度 CoT 数据的监督微调,倾向于在监督微调SFT过程中微调模型
|
|
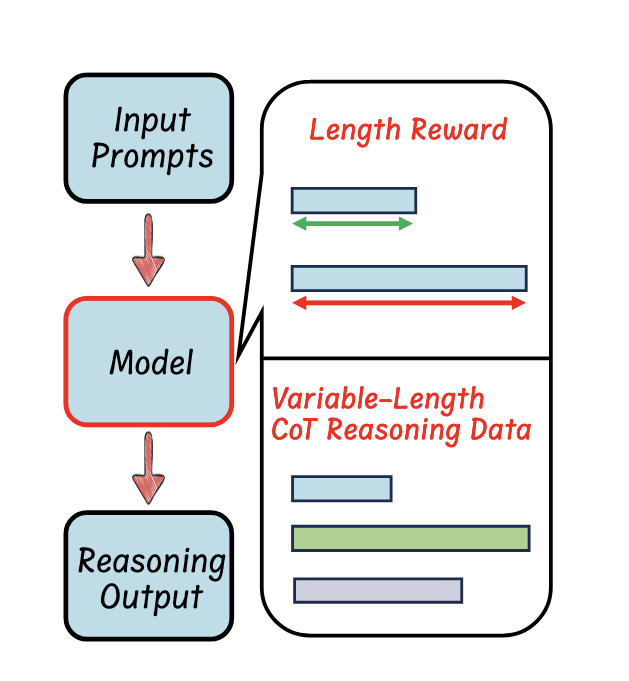
在RL中加入长度奖励(Length Reward),引导它生成简洁的推理。
以前,模型训练的时候主要关注答案是否正确(准确性奖励)、格式是否规范(格式奖励)。现在研究人员给它加了一个新的「考核指标」——推理长度(长度奖励)。
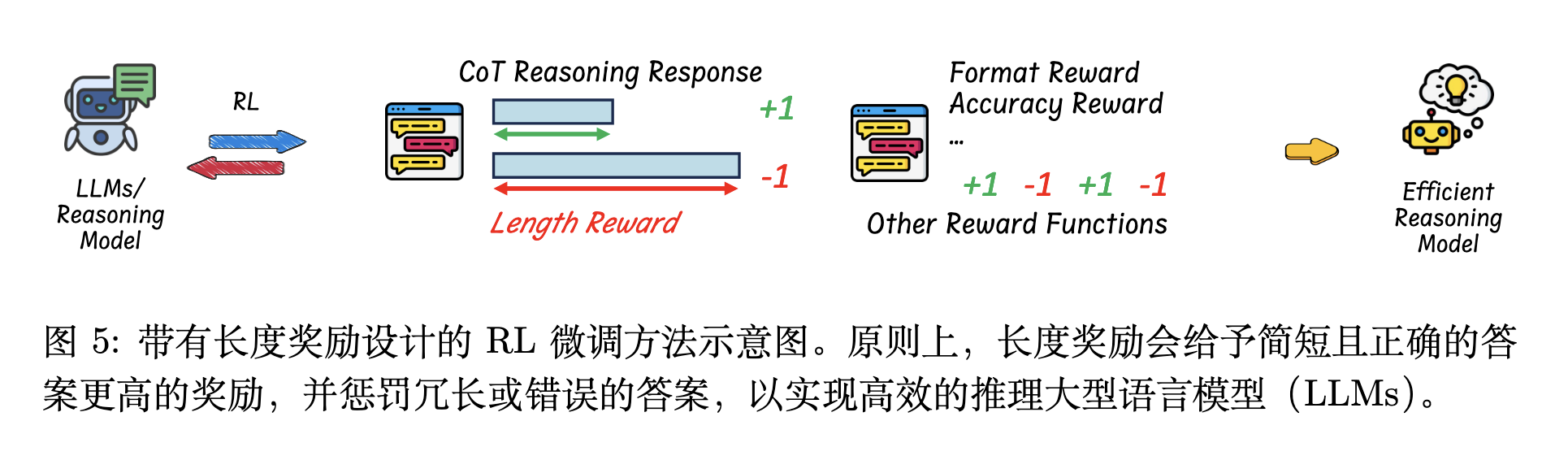
奖励函数通常是这样的:
模型为了获得更多奖励,就会在保证答案准确的同时,尽量少用token。
下表是相关工作提出的Length Reward

这个过程分为两步:
构建一个可变长度的 CoT 推理数据集(长 / 短推理步骤的数据集,可以保持模型回答复杂问题和简单问题的准确性)
用这个数据集微调模型:让模型学习如何在保证答案正确的前提下,用更简短、更紧凑的步骤来思考和推理。
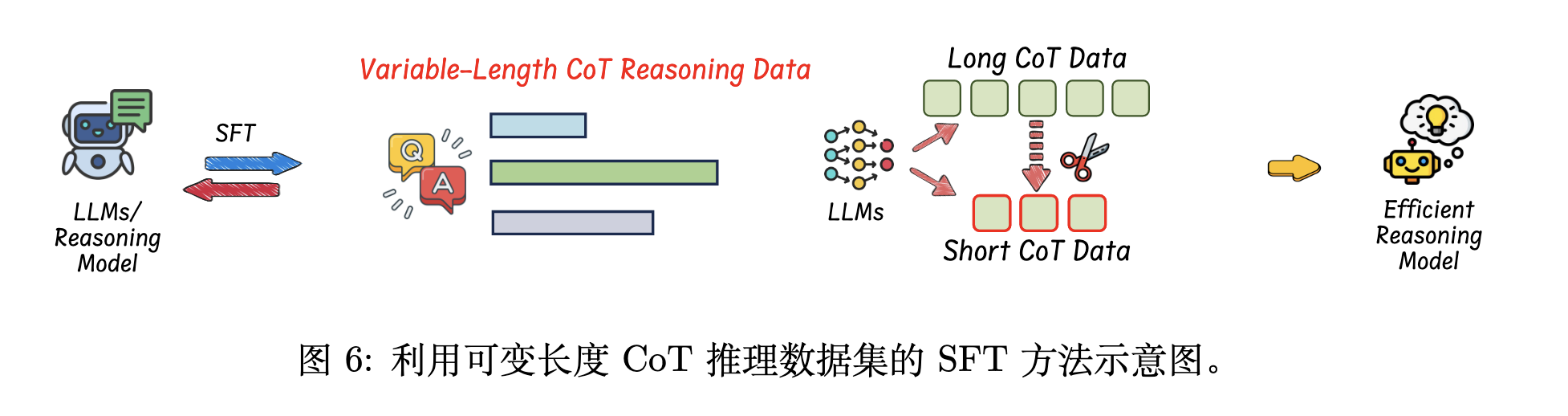
长 CoT 数据可以用问题prompt提示预训练的推理模型来收集,而对于短 CoT 数据,有两种方式构建:
事后推理压缩 (Post-inference Compression)
思路:先生成一个完整详细的推理,然后再将其“压缩”变短。
方法:包括直接丢弃推理过程、使用GPT-4等强模型重写精炼、或根据语义重要性删减步骤。
优点:可以得到非常简洁的推理链。
推理过程中获取压缩数据 (In-inference Compression)
思路:在生成时就直接引导或强制模型输出简短的推理。
方法:包括用“n步内解决”等提示词限制、设定“Token预算”、生成多个路径后选择最短的、或融合不同模型参数来控制长度。
优点:生成的短推理更符合模型自身逻辑,使后续训练更有效。
核心的微调方法也有两种:
标准微调 (Standard Fine-Tuning)
方法:这是最直接的方式,使用常规技术(如全量微调或LoRA)在准备好的数据集上训练模型,让模型直接学习如何进行简短推理。
特点:“一步到位”地让模型适应新数据。
渐进式微调 (Progressive Fine-Tuning)
方法:这是一种更平滑的“课程式”训练,在微调过程中逐步地引导模型减少思考步骤。
特点:通过“循序渐进”的方式(例如,从长推理数据慢慢过渡到短推理数据,或动态调整模型参数)来培养模型高效思考的习惯,过程更稳定。
从输出的推理步骤的角度来看,这些工作专注于修改输出范式,以增强大型语言模型(LLMs) 简洁高效推理的能力。
其核心思想是将冗长的文字版推理步骤(CoT)压缩成更紧凑的“潜在表示”(Latent Representations),即在模型的“隐藏思考空间”中进行推理,而不是完全依赖显式的文字输出。通常这些方法可以分为两类:训练 LLMs 使用潜在表示进行推理或使用辅助模型。
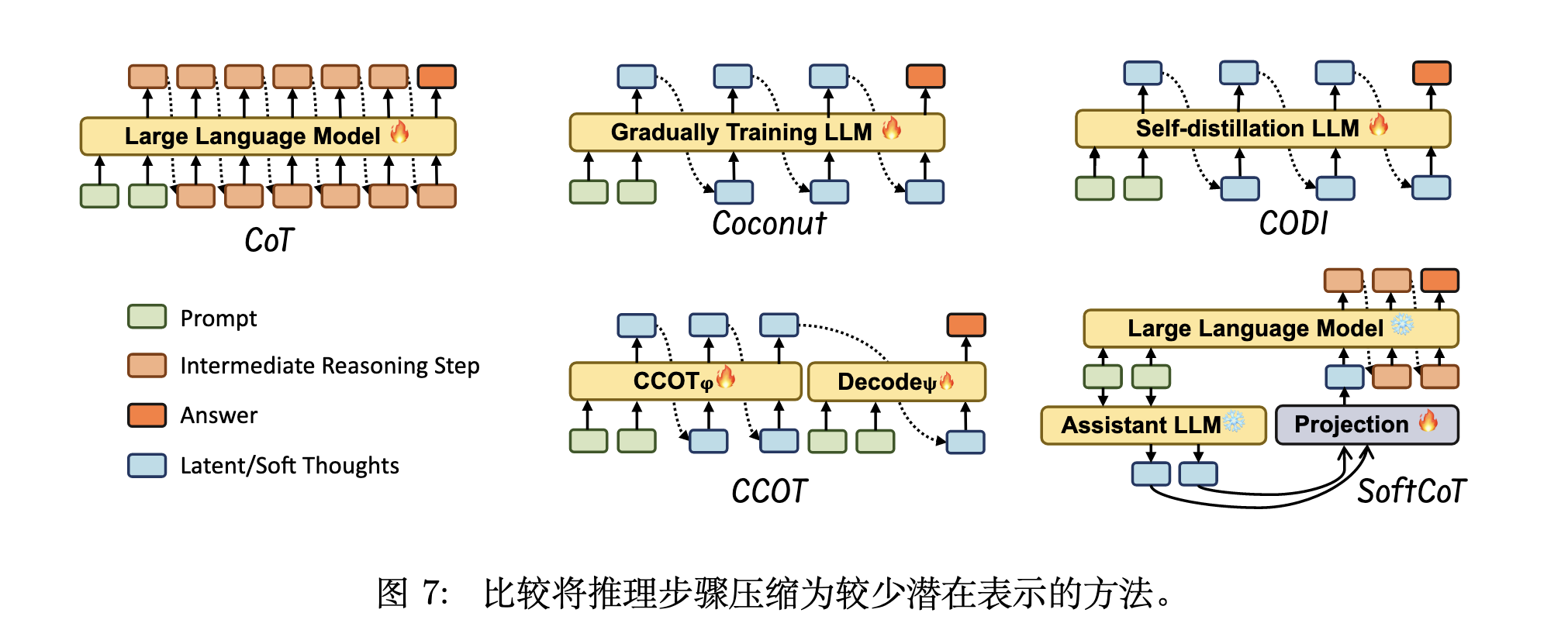
Coconut: 将推理步骤的最终隐藏状态作为连续的潜在表示,并将其迭代地作为下一阶段的输入嵌入,通过渐进式训练来优化推理链的紧凑性。
CODI: 采用自蒸馏框架,通过对齐显式文本推理与内部隐藏激活,使模型能够仅在潜在空间中执行高效的隐式推理。
CCOT: 采用模块化设计,通过一个编码器将完整CoT中的关键信息节点压缩为紧凑的潜在“沉思标记”,再由一个解码器利用这些标记生成最终推理。
SoftCoT:通过一个外部辅助模块为特定任务生成潜在的“软思维”嵌入,并将其注入一个冻结的大型语言模型的输入空间,从而在不改变主模型参数的情况下有效引导其推理路径。
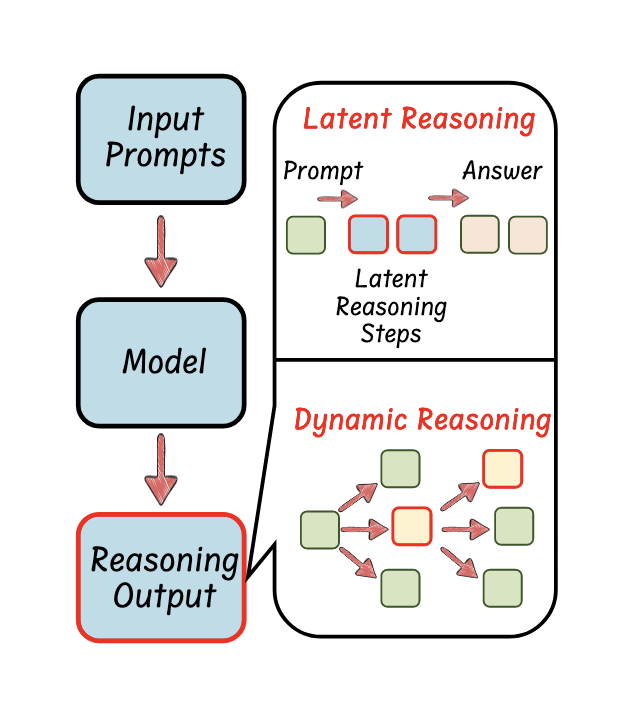
在推理过程中修改推理范式,动态调整推理策略也是提高效率的关键。动态推理会根据每个问题的具体情况,按需生成推理步骤。
修改推理范式:对现有推理流程、推理结构或推理思维链的组织方式、执行顺序或信息表达形式进行重新设计或调整,从而达到更高的效率、更好的准确性或更强的泛化能力。
测试时动态推理(Test-Time Reasoning):无需训练,利用各种推理策略来生成更长、质量更高的 CoT 响应。主要推理策略包括Best-of-N、束搜索(Beam Search)、蒙特卡洛树搜索(MCTS)等,策略的标准包括基于奖励的推理、基于置信度的自适应推理、基于一致性的选择性推理等。
基于摘要的动态推理(Summarization-Based Reasoning):需要训练,通过总结中间推理过程来提升推理效率。

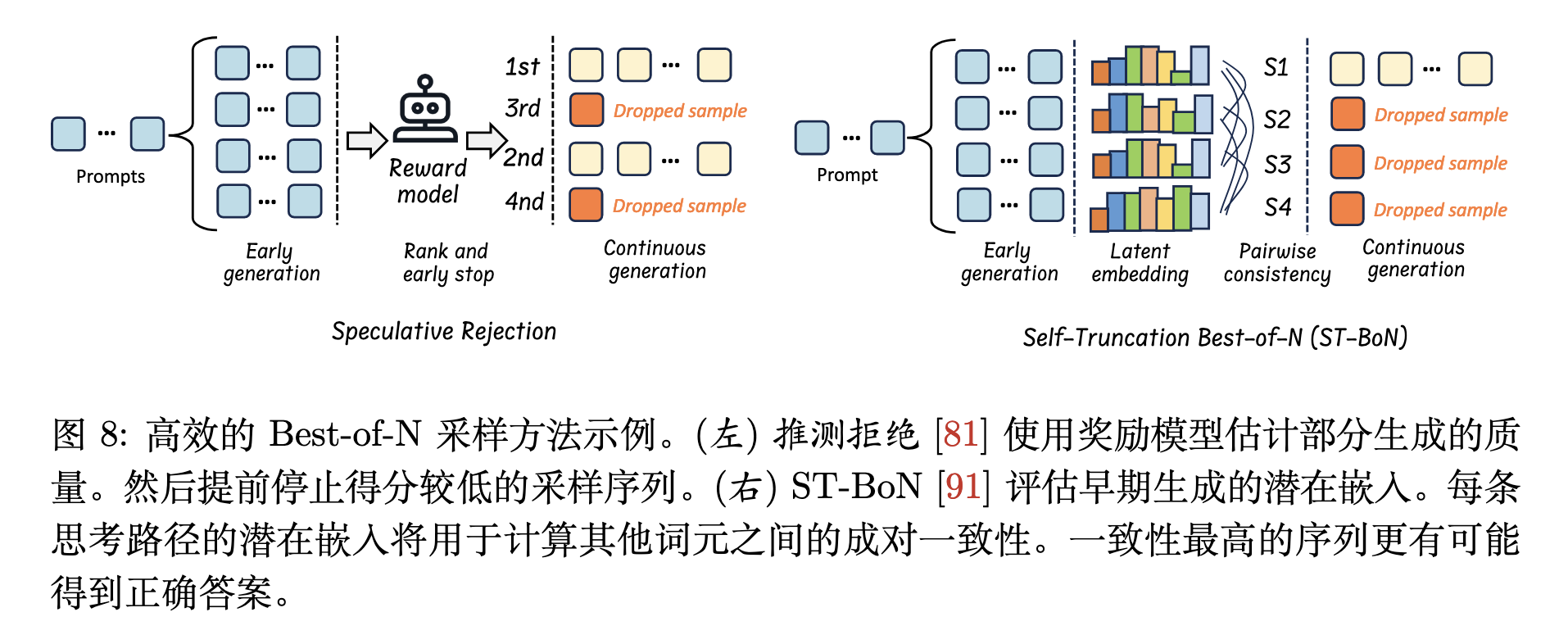
Speculative Rejection通过奖励模型提前终止低质量推理路径;或ST-BoN利用嵌入一致性选择最优路径,其核心思想是。
从输入提示的角度来看,这些工作的重点是通过施加长度约束,或根据输入提示的特性来引导大型语言模型(LLM),以实现简洁高效的推理。
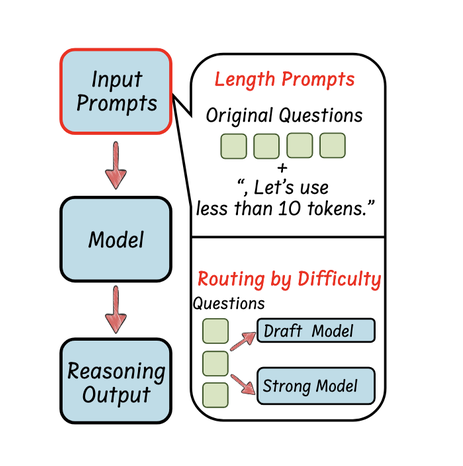
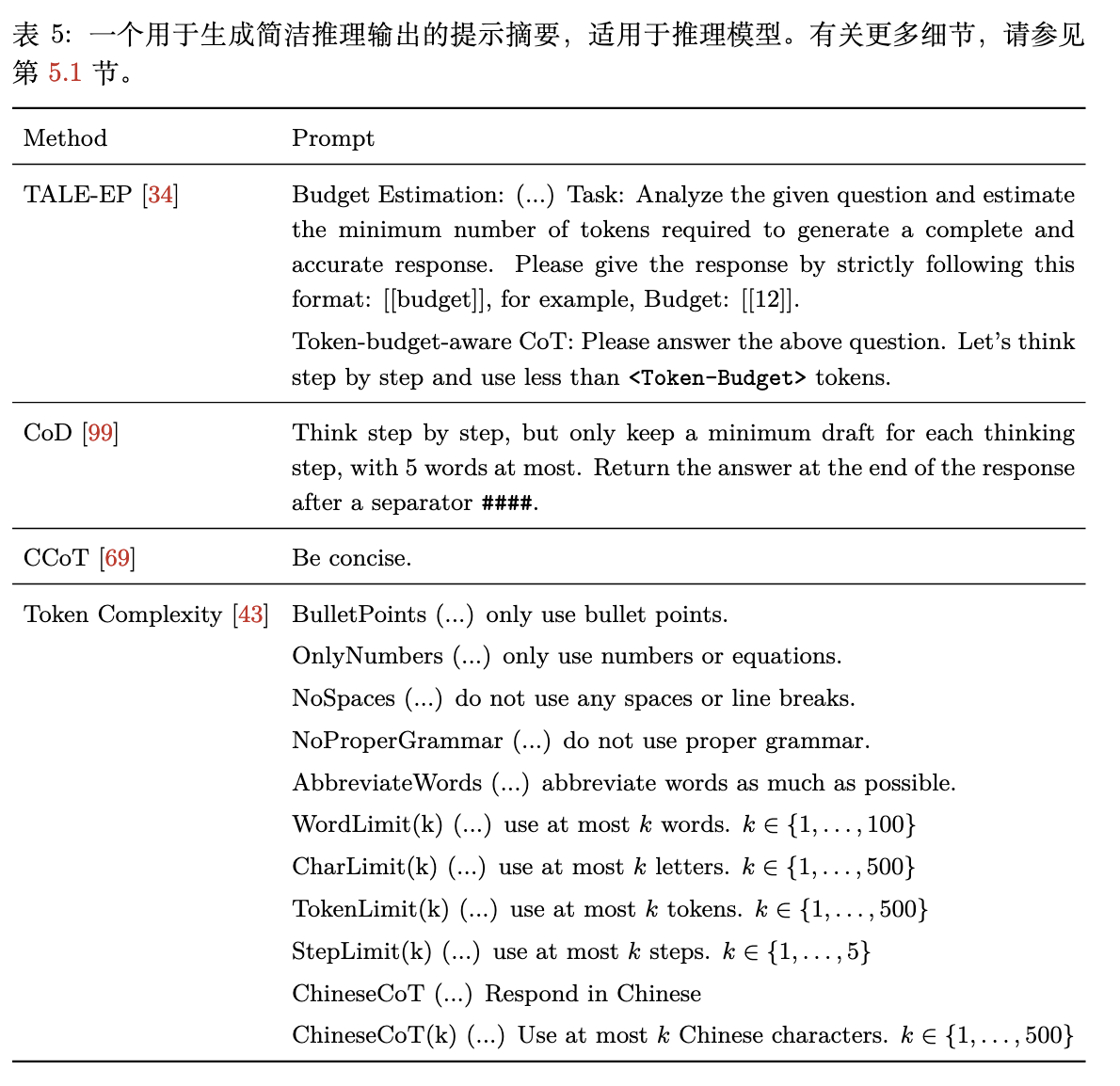
通过变化提示强制简洁推理:
设置“token预算” (Token-Budget):在提示中明确规定模型生成的答案(包括推理过程)不能超过多少个词元(Token)。
限制每一步的长度 (Chain-of-Draft):模仿人类只记录关键点的习惯,要求模型“一步步思考,但每一步只保留最多五个词的草稿”。
使用通用压缩指令 (如 CCoT):在提示中简单直接地加入“要简洁”(be concise)之类的命令,或者“用十个词以内回答”。研究发现,虽然这种方法有效,但推理的准确性和压缩程度之间存在固有的权衡关系。
提示后微调 (Fine-tuning after Prompting):
这是一个两步法:首先,利用上述的提示技巧来收集大量高质量的、简短的推理数据。然后,用这些数据来对模型进行监督微调(SFT)。
经过这样训练出的模型,不仅本身就具备了高效推理的能力,而且在处理复杂问题时,通常比那些仅在推理时依赖提示的模型表现更出色。
用户提供的提示可以从简单任务到困难任务不等。高效的推理路由策略会根据查询的复杂性和不确定性动态确定语言模型如何处理这些查询。
理想情况下,推理模型可以自动将简单的查询分配给速度快但推理能力较弱的大规模语言模型,同时将复杂的查询引导至速度慢但更强推理能力的大规模语言模型。
关键在于用什么标准来判断一个问题的难易程度。文中介绍了以下几种主要方法:
训练一个专门的“路由器” (Training a Classifier):训练一个轻量级的、独立的分类器模型,它的唯一任务就是快速判断输入问题的复杂度,然后像交通指挥一样,将问题“路由”到最合适的后端大模型。
利用模型自身的“不确定性” (Uncertainty):不依赖外部路由器,而是让大模型自己来判断“我有没有把握回答这个问题”。如果模型感到“不确定”,就主动将问题转交给一个更强大的模型。
其他:Claude 3.7 Sonnet 混合推理模型能够分配更多时间用于需要深入分析的复杂推理任务,最终产生更好的结果。
此外,论文中还提到了实现高效推理的其他方法:
使用更少的数据训练推理模型
通过蒸馏和模型压缩实现小型语言模型的推理能力

 浙公网安备 33010602011771号
浙公网安备 33010602011771号