实习Learning记录(五)——《Recursive Regularization for Large-scale Classification with Hierarchical and Graphical Dependencies》阅读笔记
《Recursive Regularization for Large-scale Classification with Hierarchical and Graphical Dependencies》阅读笔记
Abstract
层次分类中的两个关键挑战是利用类标签之间的层次依赖关系来提高性能,同时维护跨大型层次结构的可伸缩性。在这篇文章中,我们提出了一个正则化的大尺度层次分类框架来解决这两个问题。具体来说,我们将类标签之间的层次依赖关系合并到参数的正则化结构中,从而鼓励层次结构中邻近的类共享相似的模型参数。此外,我们将我们的方法扩展到类标签之间的依赖关系以图的形式编码的场景,而不是以层次结构的形式。为了实现大规模的训练,我们开发了一个并行迭代优化方案,该方案可以处理拥有数十万类和数百万实例的数据集,并学习兆兆字节的参数。我们的实验表明,与其他竞争方法相比,该方法有了持续的改进,并在基准数据集上取得了最先进的结果。
Introduction
在本文中提出了这种方法,即支持向量机(SVM)和逻辑回归(LR)的递归正则化框架。它利用类与子类之间的依赖关系来定义模型参数规范化的联合目标;共享相同父节点的兄弟节点的模型参数被规则化为公共父节点。直观地说,它基于这样一种假设:层次结构中相邻的类在语义上彼此接近,因此共享相似的模型参数。请注意,这个模型比完全贝叶斯模型要简单,在这些模型中,依赖关系以更丰富的形式建模,同时控制高斯模型中的均值和协方差。该方法的简单性使其比完全贝叶斯方法更容易扩展。
Method
结构风险最小化框架规定选择f最小化经验风险的组合基于训练数据集和一个正则化项惩罚。通常预测函数f的复杂性是由一个未知的参数化设置的参数w,然后估计的学习过程。估计参数ˆw由
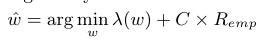
其中Remp为训练数据集上的经验风险或损失,λ(w)为正则化项,C是控制拟合给定训练实例和f复杂性之间的权衡的参数。
创新点
引入正则化项
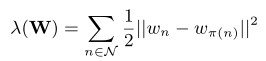
这种正则化的递归形式(利用欧几里得范式)使节点的参数与其父节点的参数相似。
直观地说,它对层次依赖关系进行建模,因为它鼓励层次结构中相邻的参数彼此相似。这有助于类利用来自附近类的信息,同时估计模型参数,并帮助在层次结构中共享统计强度。使具有很少训练实例的类能够汇集信息,以及从具有大量训练实例的类中获取信息,从而在训练实例有限的情况下产生更好的分类模型。
从而能够解决使用有限的训练示例学习独立的模型(每个类标签一个模型)可能会由于过度拟合而导致性能不佳的问题。
思考
就是这种引入正则化项的思路非常好,引入了层次依赖关系,判断相似,共享参数,使用有限的训练示例导致的过拟合问题。这为之后的层次文本分类模型都提供了思路,大部分都是直接引用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号