HDFS
大数据
大数据 (Big Data)指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据主要解决,海量数据的采集、存储和分析计算问题。
1、核心组件
(1) HDFS(Hadoop Distributed File System)
用途:
分布式文件系统,用于海量数据存储。
将大文件分割为块(Block,默认128MB/256MB),分散存储在多台机器上。
高容错性(副本机制)、高吞吐量(适合批处理)。
关联:
为所有其他组件(如MapReduce、Hive、HBase)提供底层存储支持。
与YARN协作时,数据本地化(Data Locality)优化计算效率。
(2) MapReduce
用途:
批处理计算框架,用于并行处理大规模数据集。
分两个阶段:Map(数据分片处理)和 Reduce(结果汇总)。
适合离线计算(如日志分析、ETL)。
关联:
依赖HDFS存储输入/输出数据。
依赖YARN(Hadoop 2.x之后)进行资源调度。
(3) YARN(Yet Another Resource Negotiator)
用途:
集群资源管理与任务调度。
负责分配CPU、内存等资源,协调多个计算框架(如MapReduce、Spark)的运行。
包含两个核心组件:
ResourceManager:全局资源调度。
NodeManager:单节点资源监控。
关联:
替代Hadoop 1.x的JobTracker,解耦资源管理和计算框架。
为Spark、Flink等第三方计算引擎提供资源调度支持。
2、特点
- 大量
- 高速
- 多样
- 低价值密度

HDFS
HDFS Hadoop分布式文件系统(Hadoop Distributed File System)是Hadoop项目的核心子项目,为大数据提供可扩展且可靠的存储。
- HDFS设计用来存储大文件,对海量小文件的存储不太适用;
- HDFS本身是分布式文件系统,运行在应用层(用户空间),而非内核空间;
- HDFS遵循“一次写入,多次读取”模型,文件一旦写入,无法直接修改已存在的内容(如覆盖某段数据)。从Hadoop 2.x开始,通过append操作可在文件末尾追加数据;
- 不支持挂载,并通过系统调用进行访问,只能使用专用接口访问,如命令行工具,API;
HDFS架构
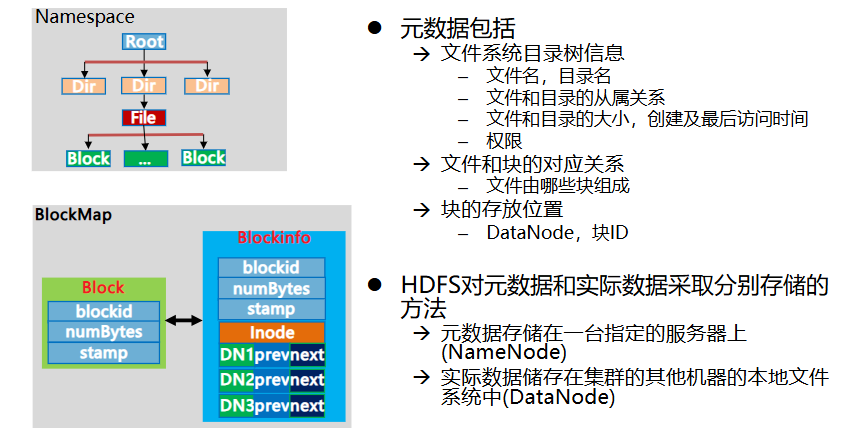
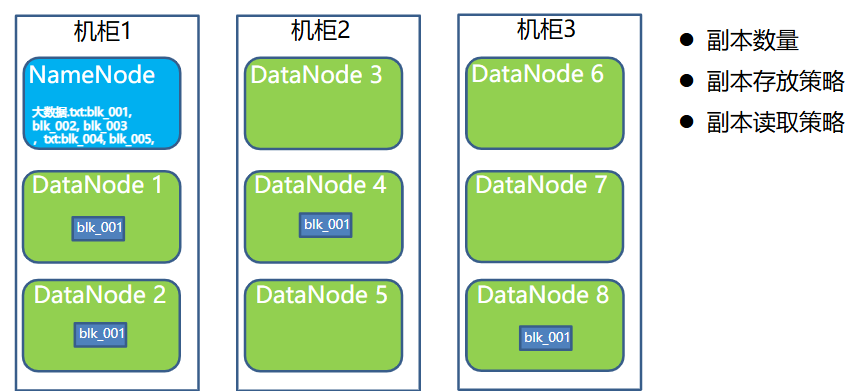
- Namenode:NN节点(能够接受用户请求并帮它决定到哪存储的节点),存储文件的元数据,如文件名,文件目录结构,(生成时间、副本数文件权限),以及每个文件的块列表和块所在的DataNode等。
- DataNode:DN节点,根据NameNode的调度存储和检索数据,并且定期向NameNode发送他们所存储的块(block)的列表
- Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份
- Client:Client包括命令行、应用程序、Web管理界面等。Client是用户和HDFS的交互手段。用户通过Client与名字节点、数据节点进行通信,访问HDFS文件系统
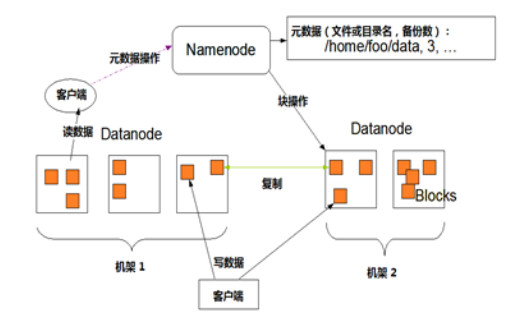
HDFS相关概念
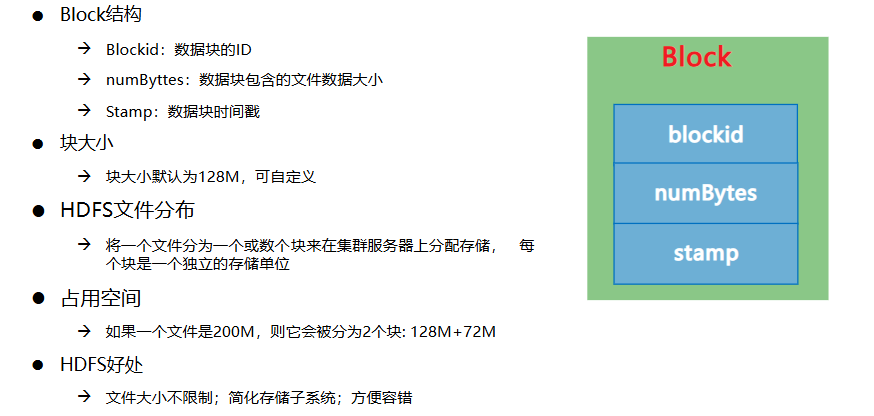
- Block数据块
- HDFS的元数据和实际数据
- NameNode
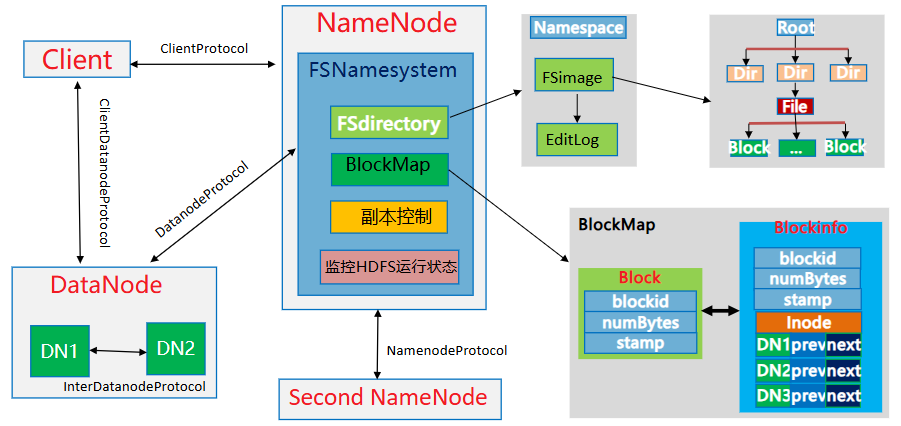
-
Second NameNode

-
DataNode
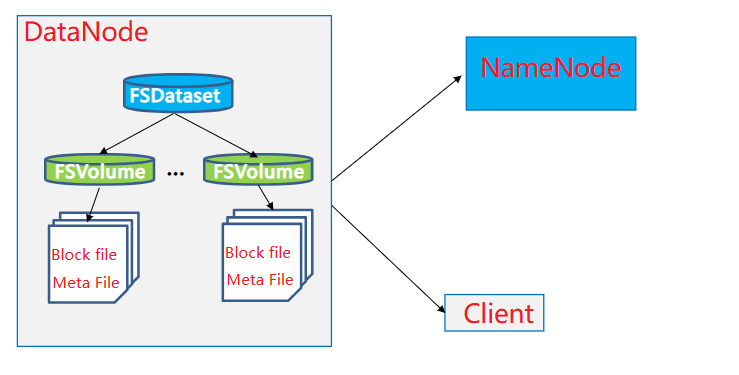
- HDFS名字节点与数据节点数据块关系
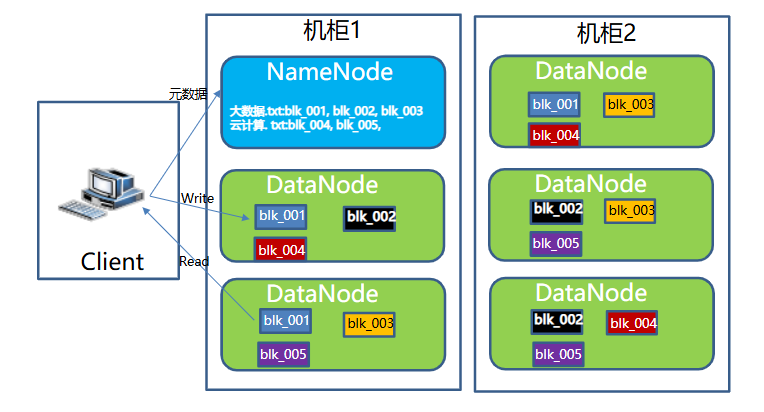
- HDFS启动过程

- HDFS读数据流程

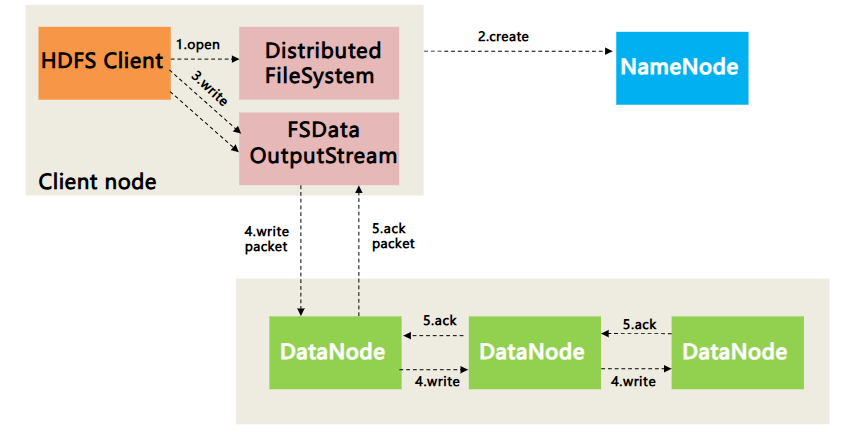
- HDFS写数据流程
HDFS特性
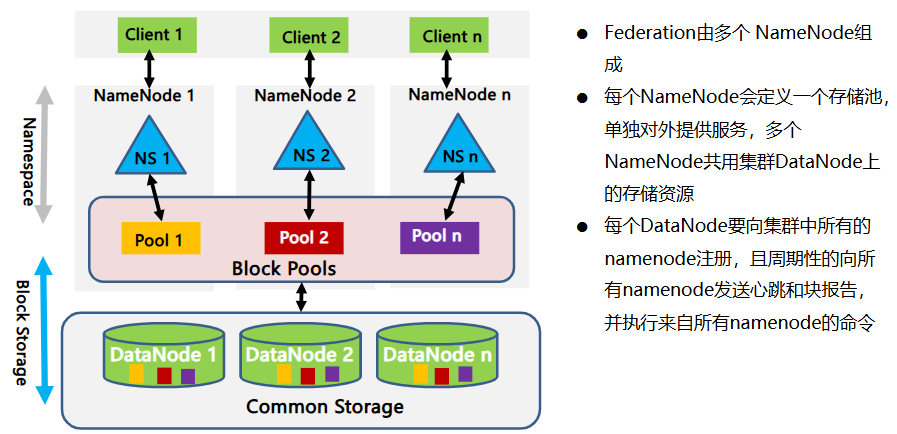
- 联邦 (Federation)
- 副本
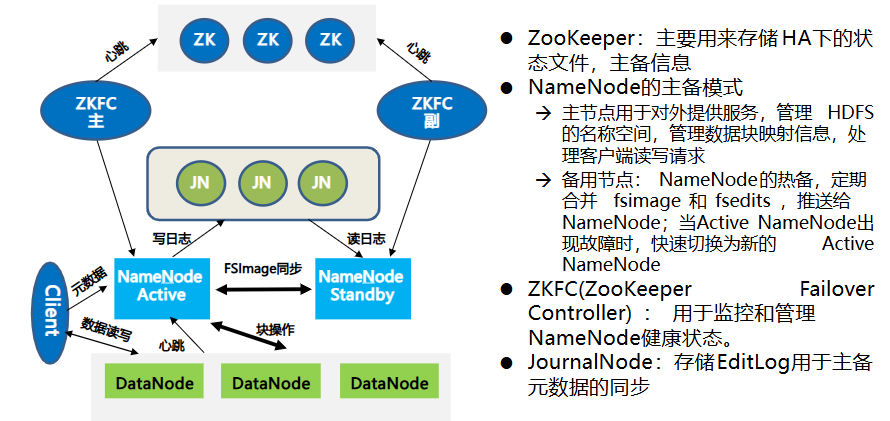
- HA
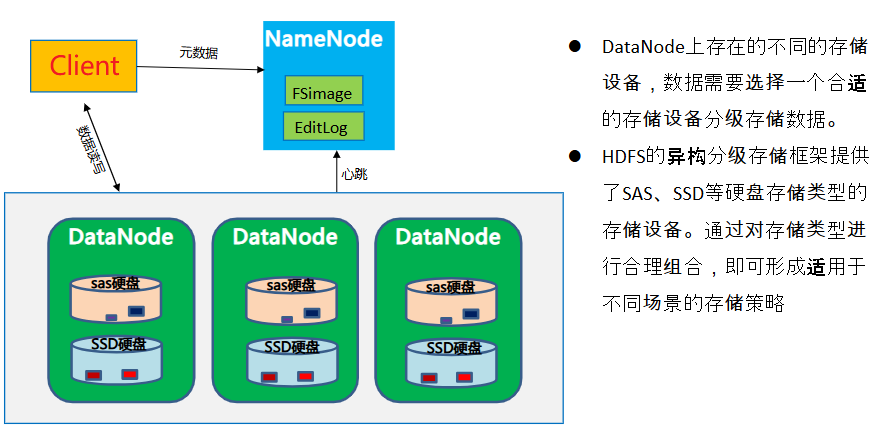
- 分级存储
- 健壮机制


 浙公网安备 33010602011771号
浙公网安备 33010602011771号