副本和纠删码
分类
按照存储的结构存储可以分为集中式存储和分布式存储
- 集中式存储
传统集中式存储采用控制器+硬盘柜的方式,通过冗余的双控制器提供数据管理和读写能力(也有超过2个控制器的多控存储,多见于高端存储),通过控制器自带的硬盘槽位或扩展硬盘柜提供存储空间,如下图。
集中式存储的硬盘数据保护多采用RAID技术,比如RAID5、RAID6、RAID10等 - 分布式存储
分布式存储为了实现更灵活的扩展性和更大的存储规模,采用无中心的组网方式,每个存储节点都可以同时提供计算和存储资源。它们通过内部交换机互联起来,基于分布式存储软件提供统一的存储资源池。比如1个节点是200TB容量,那么5个节点就是1000TB容量,并可以扩展到数千个节点EB级别的容量,所以更适合用在海量数据的场景下。

副本和纠删码
- 多副本
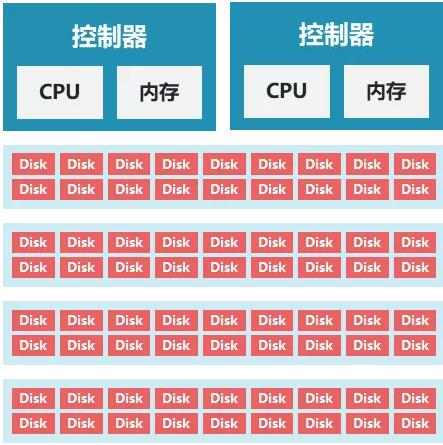
多副本,顾名思义就是多个数据副本,简单来说就是一个数据拷贝多份完全一样的副本,分别存放在多个不同节点上。比如我们常用的3副本(如下图所示)就是将A这个数据拷贝了3份,分别存放在节点1、3、4上,这三个节点是在整个集群中随机选择的,下一个B数据有可能就放在节点1、2、4上了。
我们来看下多副本的数据保护效果,很明显,当节点1和3同时故障时,节点4上仍然会保存有A数据。以此类推,我们可以知道,N副本技术可以允许N-1个节点同时故障数据不丢失。如果是硬盘故障,只要故障硬盘的范围不超过N-1个节点,数据也不会丢失,比如节点1坏了3块盘、节点3坏了4块盘,数据仍然不会丢失。 - 纠删码
纠删码的英文全称是Erasure Code,所以有时我们也会简称为EC。纠删码顾名思义是一种纠正数据丢失的校验码,大家可以把它类比成一个方程组。我们如果知道4个数a、b、c、d,就可以通过2个不同的公式算出2个校验数据x和y,把6个数据一起保存起来,那么当a、b、c、d其中1个或2个数据丢失的话,就可以通过剩余的2个值和计算公式,反推出丢失的2个数据。比如:
已知:a+b+c+d=x=10,a+2b+3c+4d=y=20,c=2,d=1
那么:a+b=7,a+2b=10,则a=4,b=3
当然以上计算只是一个简化的方案,目的是帮助大家理解,真正存储中用的校验方式会比这个复杂得多,但效果是类似的。
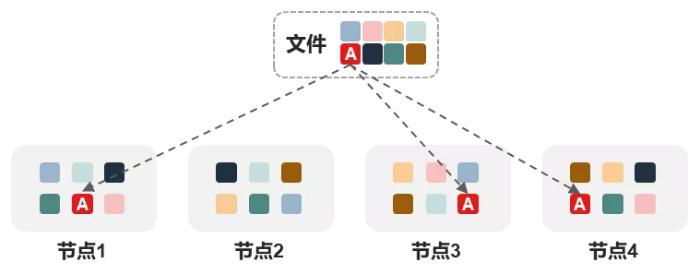
如果我们用M+N表示纠删码的话,以上就是一个4+2的纠删码方案,数据会被切分成4个相同大小的分片,并通过校验算法生成2个同样大小的校验分片P和Q。比如32KB的数据会被切成4个8KB的分片,再生出2个8KB的分片,总计48KB数据。当6个数据分片生成后,它们会被随机存到6个不同的节点上(如下图所示)。

和多副本一样,我们来看下4+2纠删码的数据保护效果。从上图可以看出,当任意2个节点故障时,数据是不会丢失的,因为只会丢失2个数据分片,还是可以反算出来的。当然如果同时故障了3个节点,4+2的纠删码是无能为力的,就像1个方程有2个未知数怎么也解不出来一样。而且4+2纠删码也可以允许2个节点内任意个数硬盘故障时,数据不丢失。比如节点1、节点2分别故障了5块硬盘,也完全不会有影响,因为每一组4+2分片都有4个分片还在,数据还是可靠的。
多副本和纠删码对存储节点有什么要求?
多副本和纠删码对分布式存储的节点数量和硬盘配置都有一定要求,主要是2点:
-
N个副本至少需要N个节点才能部署,比如3副本至少需要3个存储节点,而M+N纠删码至少需要(M+N)个节点,比如4+2纠删码至少需要6个节点,当然这只是最低要求,上限并没有限制,另外也不会有倍数比例的要求,比如3副本并不要求一定是6个、9个节点,5个、7个节点也可以;
-
每个节点的硬盘数量和单盘容量建议相同,因为如果不同的话,就会出现水桶的短板效应,两个节点,一个节点配置8TB硬盘,一个节点配置4TB硬盘,8TB硬盘只能当4TB硬盘用,因为每个节点的数据保存容量是随机分布、几乎相同的。
什么是M+N:1纠删码?
除了常见的M+N纠删码之外,我们还经常见到一种M+N:1的纠删码,这是一种特殊的纠删码技术,我们称之为亚节点纠删码。
这种技术的出现是为了满足小规模集群的部署要求,我们举个例子,有一个用户采购了3个分布式存储节点,因为节点数量比较少,他可选的数据冗余策略就只有3副本和2+1纠删码(2副本暂不考虑,后文我们来详细说明原因)。选择3副本的话,存储的空间利用率就只有33%了,如果我们再考虑其他因素,比如硬盘标称值的差异、系统预留空间、热备空间的话,可用空间可能只有26%左右,这对于很多看重容量的用户来讲是比较难以接受的。但如果我们选择2+1纠删码呢,问题出现了,2+1纠删码只能允许1个分片数据丢失,当集群中2个节点分别故障1块硬盘的时候,数据就丢失了!
在实际使用场景下,2块硬盘同时故障的情况虽然比较少见,但概率也并不算低,因为很多用户在1块硬盘故障时可能并没有发觉。这段时间存储就是在极其危险的状态下运行,任何硬盘出问题都会导致集群数据丢失,很显然,2+1纠删码的方案并不好。
基于以上原因,4+2:1的纠删码出现了。为什么叫亚节点纠删码呢,因为默认的纠删码是按照节点来分配数据的,但4+2:1只会按照硬盘来分配数据,它把3个节点当6个节点用,每个节点选择2块硬盘,整个集群选择6块不同的硬盘来存放4+2总计6个分片数据(如下图所示)。
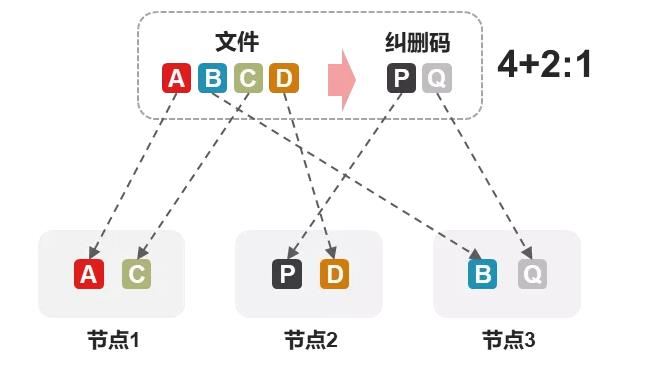
我们看到,4+2:1相比2+1纠删码,虽然能容忍节点故障数量仍然是1个,但它可以允许2个节点分别故障1块硬盘(总计故障2块硬盘)而数据不丢失。而实际情况下,硬盘故障的概率是远远低于整个节点故障的,所以4+2:1还是非常可靠的,而且它的空间利用率远高于3副本。当然如果你担心的是2个节点同时故障,那你只能选择3副本了。
类似于4+2:1,也存在8+2:1、16+2:1等亚节点纠删码,这里我们就不多讨论了。
对比


在可用容量上,纠删码的优势是较大的,比如4+2纠删码的利用率是66%,但3副本只有33%,两者差了2倍,8+2纠删码更可以做到80%,这一局纠删码完胜!
-
在读写性能上,多副本往往会更高,因为纠删码在写入时涉及数据校验,而且可能会产生写惩罚,在读取时更会横跨多个节点。比如4+2纠删码在读取1个数据时,需要从4个节点分别读取4个分片再进行拼接,任何1个节点时延过高,都会对性能造成很大影响。而多副本只需要读取1个完整的分片即可,不涉及节点的数据拼接。这两者的性能差异在小块IO时会较为明显,但如果IO块比较大的话,比如1MB,那么两者的性能差距就会逐渐缩小,因为这时候写惩罚较少,纠删码也能很好发挥多个节点并发的优势,这一局多副本略胜一筹!
-
在重构性能上,多副本也会有明显优势,因为不涉及数据校验,只是单纯的数据拷贝,所以速度比较快。而纠删码的重构涉及反向校验的计算过程,所需要的读写数据量和CPU计算消耗都会更大,这一局多副本同样略胜一筹!(说明:重构指的是存储硬盘故障后的数据恢复过程,把故障硬盘的数据恢复到正常的硬盘上,保证数据的完整性)
-
在可靠性上,多副本和纠删码的故障冗余程度往往差别不大,比如3副本和4+2纠删码都可以允许任意2个节点故障而数据不丢失。但我们也需要注意两点,一是多副本的重构性能往往比纠删码更快,所以硬盘故障恢复也更快,会带来一些可靠性上的优势。二是纠删码可以采用+3、+4的策略来容忍更多节点故障,而且空间利用率并不会太低,但如果多副本采用4副本、5副本的话代价就太大了,所以这一点上纠删码有优势。这一局两者难分伯仲!
-
综合来看,如果用户更关注性能,尤其是小IO的场景,多副本往往是更好的选择,如果用户更关注可用容量,而且是大文件场景的话,纠删码会更合适。
应该具体选择什么规格的纠删码和多副本?
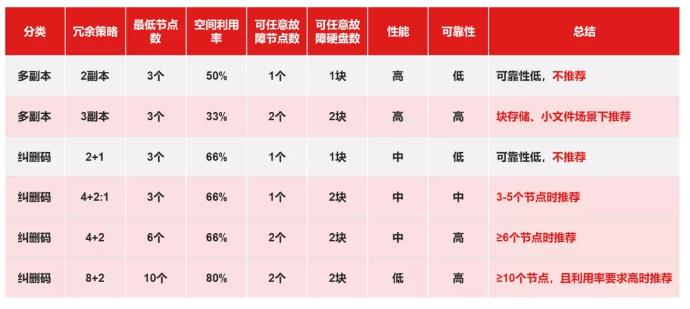
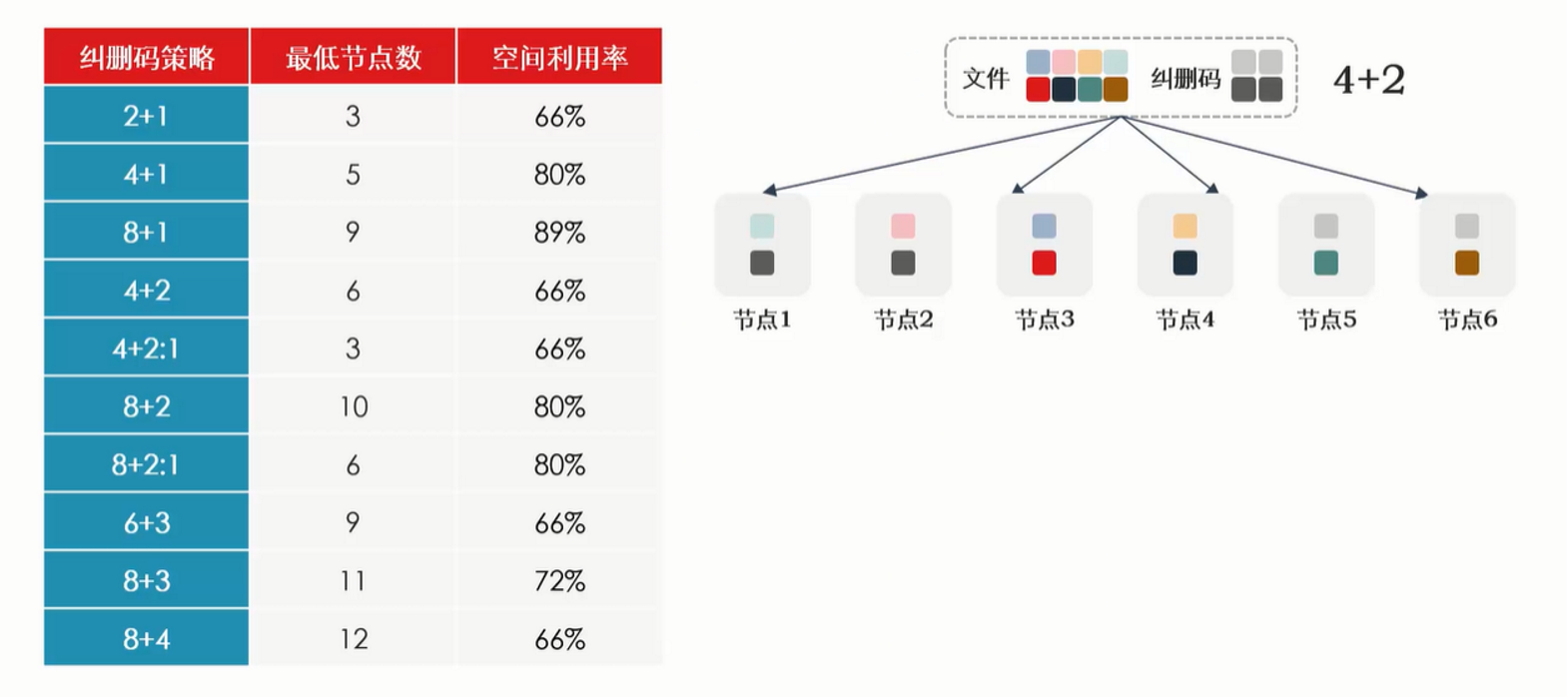
常见的多副本和纠删码策略如下表,我们逐个分析:
-
2副本:
不推荐!不推荐!不推荐!重要的事情说3遍,因为真的很危险!可能很多用户看重了2副本还不错的空间利用率(50%),同时性能也非常好,但选择存储的底线很多时候往往是数据的可靠性,千万不能因小失大。2副本只能允许任意1块硬盘故障,一旦1块硬盘故障后,整个集群就处于岌岌可危的状态,任何问题都可能导致所有数据全部丢失。而想想硬盘每年1%-2%的平均故障率,整个集群可能有上百块硬盘,你还想每年都担惊受怕好几次吗?所以除了开发测试场景,完全不担心数据丢失这种情况外,忘了2副本吧,它真的很危险! -
3副本:
如果你要选择多副本,那么2副本太危险,4副本太浪费空间,所以3副本是最好的选择。它除了空间利用率低一点之外就没有其他缺点了,在容量要求不高的时候其实成本还是可以接受的。在块存储、小文件的场景建议采用这种方案。 -
2+1纠删码:
同样不推荐,理由和2副本一样,太危险了,而且有4+2:1纠删码这个处处比它好的方案在,为什么还要多看2+1纠删码一眼呢。 -
4+2:1纠删码:
当集群节点数量不足6个,没法用4+2的情况下,4+2:1亚节点纠删码无疑是最好的选择,它既可以允许任意2块硬盘故障数据不丢失,空间利用率也和2+1完全相同。 -
4+2纠删码:
当集群节点数≥6个时,4+2纠删码是不错的选择,因为它可以容忍任意2个节点的硬盘故障数据不丢失,空间利用率也很高(66%)。 -
8+2纠删码:
当集群节点数≥10个,而且看重空间利用率大于性能时,8+2纠删码也是一个选择,它的空间利用率高达80%,但注意性能可能不理想。
综上所述,当你选择了多副本,3副本几乎是唯一的选项,当你选择了纠删码,可以根据集群的节点数量进行选择,3-5个节点时选择4+2:1,≥6个节点时选择4+2,如果你更看重空间利用率,而且不要求高性能的情况,也可以考虑8+2纠删码。
除此之外,可能会有人问,5+2、8+3、16+2等纠删码可不可以用呢?实际上,因为计算机二进制的特点,M+N纠删码的M我们往往取2的幂次方,比如2、4、8、16,这样切片的效率更高,所以5+2这类纠删码很少会用。
8+3、8+4这类纠删码虽然比+2更可靠,但因为同时故障3个、4个节点的概率太低了,由此带来的性能性下降并不划算,所以也很少使用。16+2的优势是空间利用率比较高(89%),但性能也较低,所以如果用户的集群规模比较大,对空间利用率要求极高,而且可以容忍一定性能下降的话,16+2或16+2:1在少数场景下也是会被使用的。
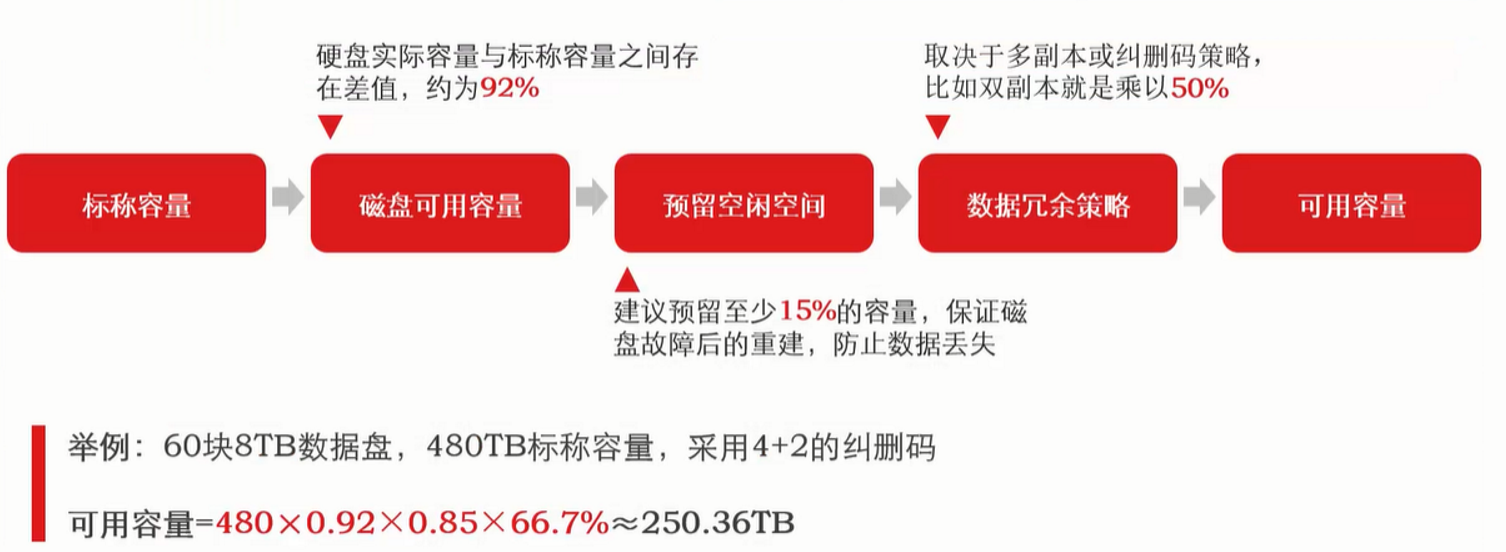
空间的利用率怎么算
CF22050存储设备为4控制器,且配置外接存储硬盘柜,当前为96块2.4T SAS硬盘,在完成raid部署后可提供170TB容量
96*2.4*75%=172
使用showpd –c –p –devtype NL,显示free为77929,假如做raid6的话,最多能划出多少可用空间?
free为77929。如果你是6+2的Raid6,2个校验位+6个数据位,所以可用的数据为75%。那么可分配的空间为77929*75%=58,446.75GB=57TB。
参考和转载至

 浙公网安备 33010602011771号
浙公网安备 33010602011771号