索引数据结构
一、索引数据结构
通过数据结构与算法可视化网站,插入一组相同的数据对比不同数据结构的区别。
二叉树
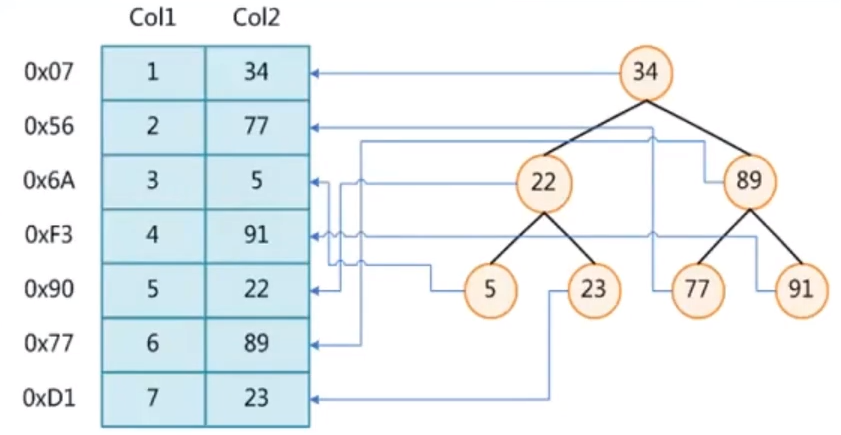
插入一组数据【2、4、6、8、66、88、130】

缺点:偏移太严重
红黑树
插入一组数据【2、4、6、8、66、88、130】
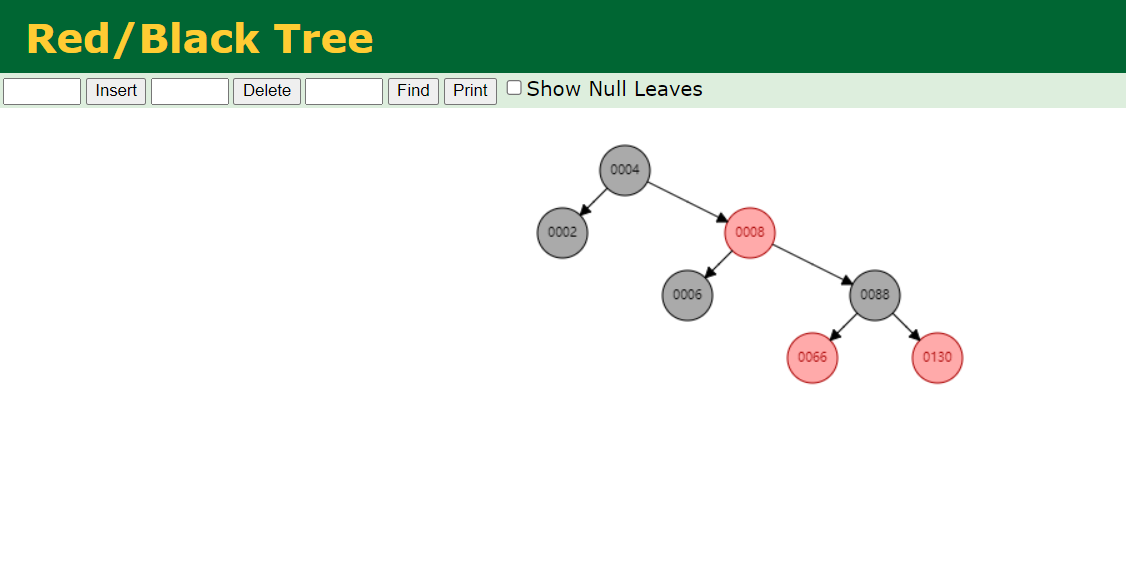
缺点:层级太多
B-Tree
- 叶节点具有相同的深度,叶节点的指针为空;
- 所有索引元素不重复;
- 节点中的数据索引从左到右递增排列;
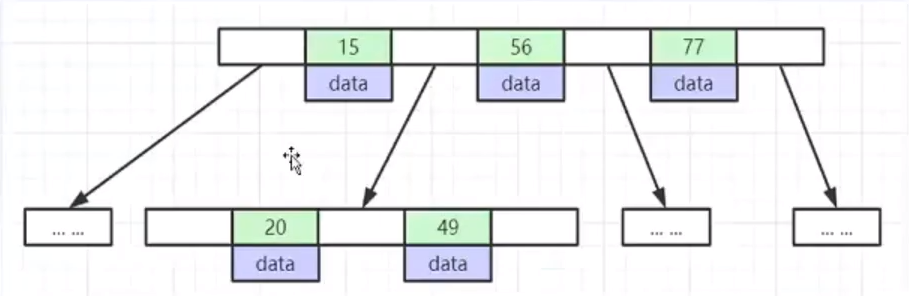
插入一组数据【2、4、6、8、66、88、130】

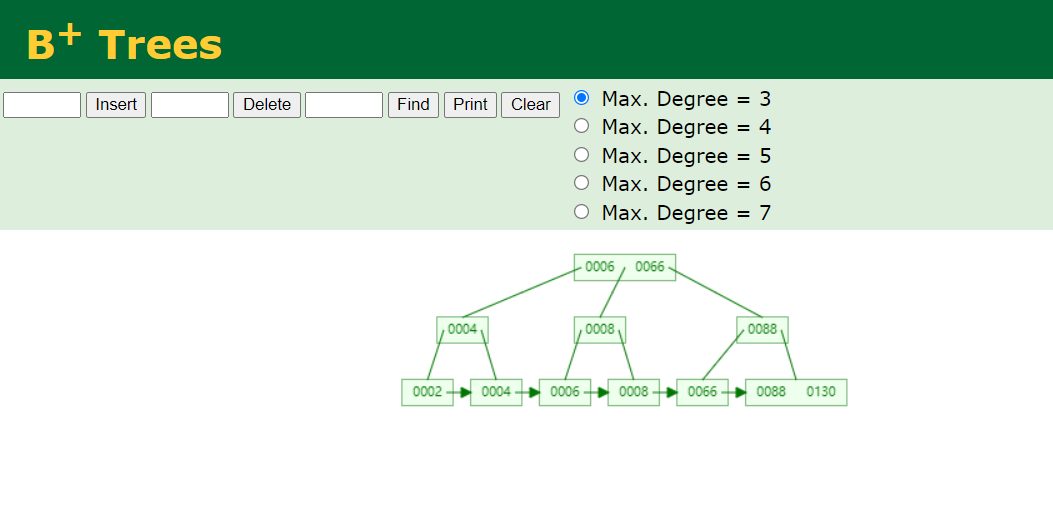
B+Tree
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引;
- 叶子节点包含所有索引字段;
- 叶子节点用指针连接,提高区间访问的性能;
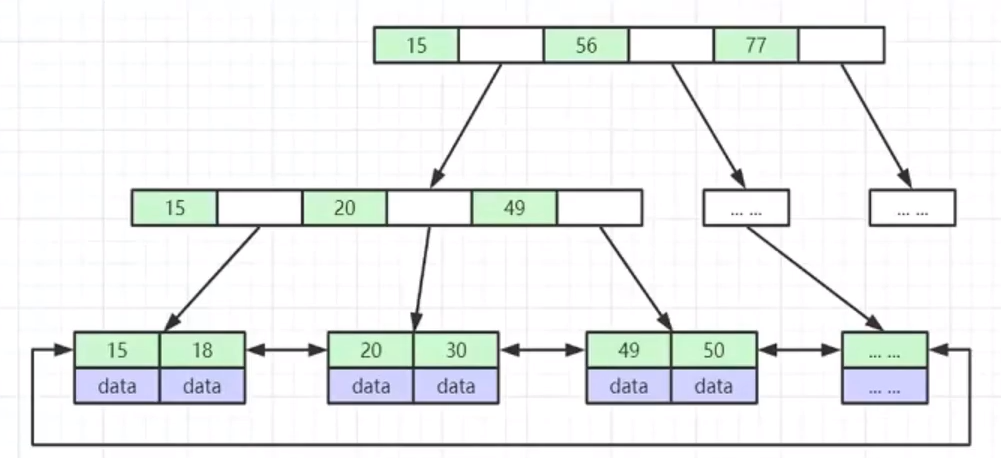
插入一组数据【2、4、6、8、66、88、130】
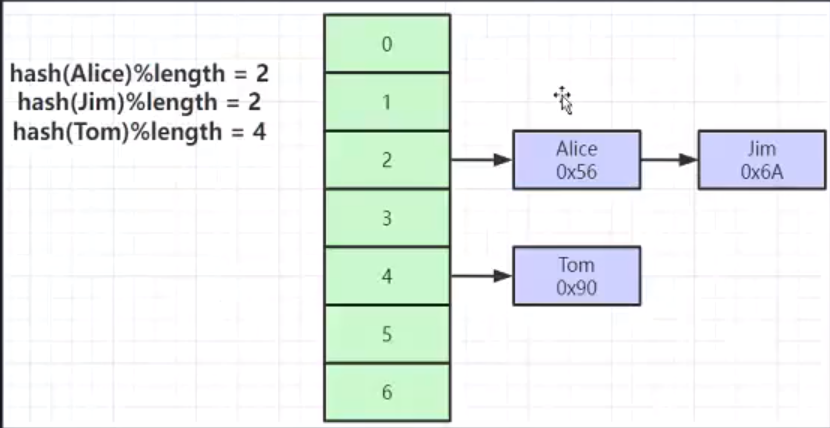
HASH
- 对索引的key进行一次hash计算就可以定位出数据存储的位置;
- 很多时候Hash索引要比 B+树索引更高效;
- 仅能满足"=","IN",不支持范围查询;
- HASH冲突问题;
二、存储引擎存储数据结构对比
MYISAM存储引擎索引的存储结构
- .frm:表结构文件
- .MYD:表的数据文件
- .MYI:索引文件
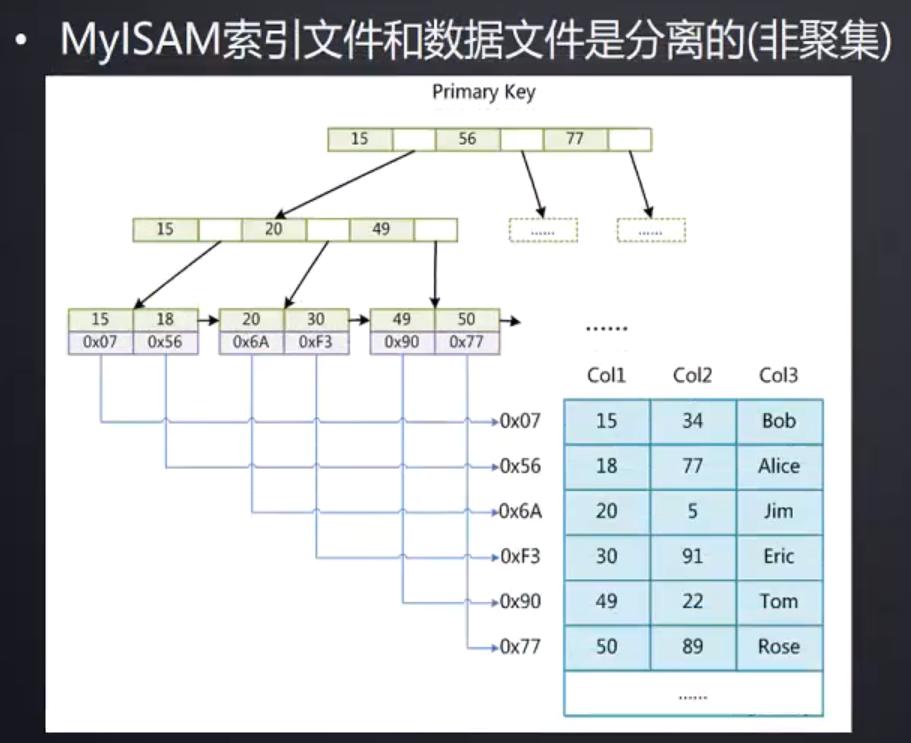
索引和数据分开存储
查询带有索引的数据,先定位索引元素,date存放着索引所在行的磁盘文件地址,根据磁盘文件地址去加载数据文件中的字段。
INNODB存储引擎
- .frm:表结构文件
- .ibd:表的索引和数据文件
表数据文件本身就是按B+Tree组织的一个索引结构文件
聚集索引-叶节点包含了完整的数据记录
为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
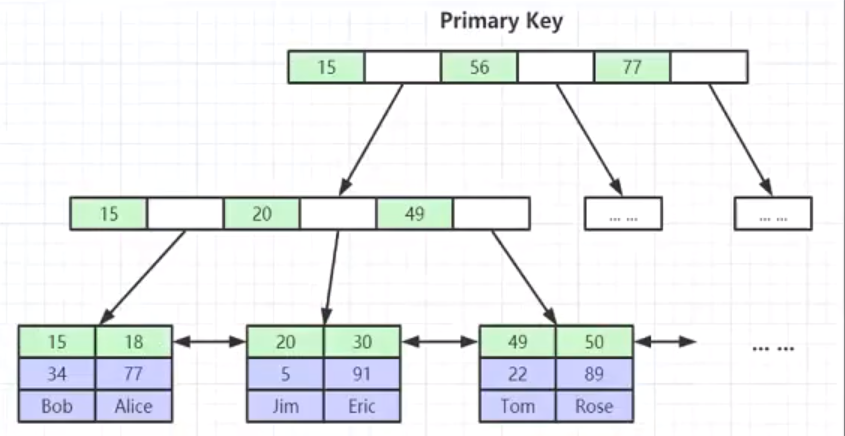
主键索引存储数据:叶子节点存放着索引所在行其它所有列的数据。
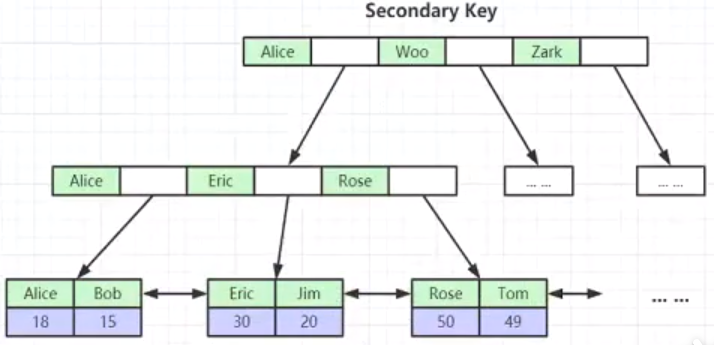
二级索引:先定位主键,再根据主键查找数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号