重大国际化合作:Mozilla Data Collective与OpenCSG携手托管中文高质量数据集
在人工智能发展的核心驱动力——高质量数据领域,一项具有行业标志性意义的合作正式公布。Mozilla 基金会旗下、致力于构建可信 AI 数据基础设施的 Mozilla Data Collective,与开源大模型生态社区 OpenCSG(开放传神)达成战略合作。

OpenCSG × Mozilla 数据出海:科学与技术破解大模型数据瓶颈
即日起,由 OpenCSG 构建并持续迭代发布的高质量中文预训练数据集(包含Chinese FineWeb Edu系列、smoltalk-chinese、chinese-cosmopedia),将在 Mozilla Data Collective 平台上进行托管与全球分发。这一合作不仅提升了数据集的全球可达性,也意味着 OpenCSG 在中文大模型核心数据层面的能力,开始被纳入国际非营利数据基础设施体系之中。
在大模型时代,模型能力的上限正越来越多地取决于预训练数据的质量与结构。相较英文语料,中文大模型长期面临的并非“数据规模不足”,而是高质量数据比例偏低、数据来源与版权边界不清晰,以及优质语料难以被系统性沉淀和复用。这些问题叠加在一起,逐渐构成了中文大模型持续演进中的关键瓶颈。
也正因为如此,单次数据集的发布并不足以解决问题,真正重要的是是否具备长期、稳定、可迭代地建设高质量中文数据的能力。
中文数据新基线:打造可复用预训练数据底座
Chinese FineWeb Edu 是由 OpenCSG 发布的高质量中文大模型预训练数据集系列,面向学术研究与工业级模型训练场景。与以往以“规模优先”为导向的数据集不同,该系列从设计之初便将数据质量的可控性与一致性作为核心目标。
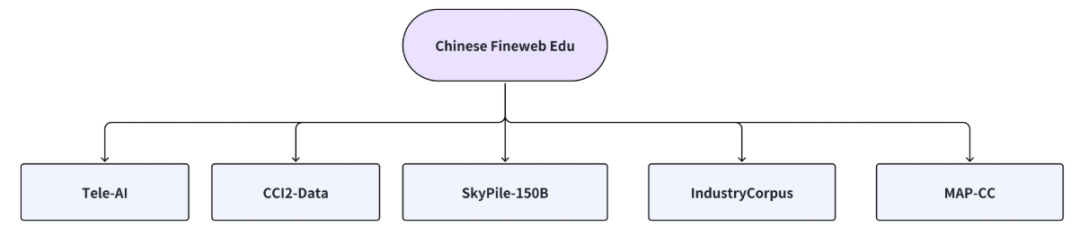
在具体实践中,OpenCSG 通过自动化算法与规则体系相结合的方式,对海量中文语料进行持续的清洗、去重与分类,重点保留教育性强、知识密度高、语言质量稳定的内容。这使得数据集在覆盖万亿级 Token 规模的同时,仍然能够保持相对稳定的结构与分布特征。
随着 v1 与 v2 版本的连续发布,Chinese FineWeb Edu 已不再是一次性的成果展示,而逐渐演变为一个可被验证、可被复用的中文预训练数据基线。
OpenCSG角色升级:科学与技术从开源社区到数据基建提供者
围绕中文大模型生态建设,OpenCSG 长期深耕模型、数据与平台能力的协同发展。从最初的开源模型与代码协作社区出发,逐步扩展至对数据资产的系统化治理与工程化管理,其角色也随之从“参与者”向“基础设施提供者”延伸。
Chinese FineWeb Edu 的持续建设,正体现了这种转变背后的能力基础:不仅能够构建高质量数据集,更能够长期维护其质量、版本与使用边界,并将其纳入开放协作的体系之中。
中文数据全球共享:入驻Mozilla,惠及全球开发者
Mozilla Data Collective 是 Mozilla 基金会发起的非营利性数据基础设施项目,其核心目标是在尊重数据主权的前提下,为 AI 发展提供安全、透明、合规的数据托管与分发机制。这一定位决定了,其合作对象不仅需要具备数据产出能力,更需要在数据治理与开源实践方面具备长期可信度。
在此次合作中,Mozilla Data Collective 提供全球化的数据托管与分发基础设施,而 OpenCSG 则完全保留 Chinese FineWeb Edu 数据集的所有权与许可决策权。这种清晰的分工,使高质量中文数据能够在尊重创作者与社区利益的前提下,被全球研究者与开发者持续使用,也体现了 Mozilla Data Collective 对 OpenCSG 综合能力的认可。
尾声:共建面向全球 AI 生态的中文数据基础设施
对于中文 AI 社区而言,这次合作的意义并不局限于一项数据集的上线,而在于展示了一种可持续的路径:高质量中文数据可以通过非营利基础设施进入全球 AI 生态,同时又不被单一商业平台所垄断。
OpenCSG 以 Chinese FineWeb Edu 为代表的高质量中文数据集体系,已被全球高校、科研机构及科技企业广泛采用,是支撑中文 NLP 研究与大模型产业落地的核心数据基础,从顶尖高校 AI 实验室到企业级生产环境,它持续为大模型预训练、指令微调与领域适配等关键环节提供可靠支撑,推动研究成果向规模化应用高效转化;在学术领域,该数据集已被 100 + 篇论文引用,多次入选 NeurIPS、ACL 等国际顶会及 Nature 子刊、JMLR 等权威期刊,成为验证中文语言模型泛化能力、知识建模效率与跨语言迁移效果的代表性基础资源。
与此同时,OpenCSG 通过开源数据、评分模型及完整的数据处理工具链,向社区输出可复用的数据治理方法论,持续降低高质量数据的构建与评估门槛,推动中文 AI 生态从 “模型参数竞争” 转向更加理性、可持续的 “数据基础设施建设” 阶段。
-
高校与研究机构:斯坦福大学(Stanford)、清华大学(Tsinghua)、中国人民大学高瓴人工智能学院、上海人工智能实验室(Shanghai AI Lab)、北京智源研究院(BAAI)、鹏城实验室 、 西班牙国家级超算中心 (BarcelonaSupercomputingCenter)、Mozilla Data Collective等。
-
企业应用:英伟达(NVIDIA)、苹果公司(Apple Inc.)、美团、蚂蚁集团、面壁智能(ModelBest)、中国移动、中国联通等。
如果说模型决定了 AI 的能力上限,那么 OpenCSG 所关注的,是如何让高质量的中文数据与模型,成为可以被长期使用和持续信任的公共能力。Mozilla Data Collective 与 OpenCSG 围绕 Chinese FineWeb Edu 的合作,正是这一能力正在走向国际化基础设施体系的重要一步。
关于OpenCSG
从社区到产业:OpenCSG打造AI模型新基础设施
国产开源生态的推动力不可忽视。以 OpenCSG 社区为代表的国产 AI 社区,正成为大模型时代关键的基础设施提供者与技术创新策源地。OpenCSG作为全球第二大的大模型生态社区,仅次于HuggingFace。其背后的核心平台CSGHub提供强大的大模型资产管理能力,为模型训练和部署提供从模型、数据集、代码到 AI 应用的 一站式托管、协作与共享服务。
截至目前,OpenCSG 社区已汇聚超过 20万个高质量开源 AI 模型,覆盖 NLP、CV、语音、多模态等多个核心方向,为研究机构、企业用户和开发者提供了坚实的数据与算力支持。
OpenCSG 正在推动形成具有中国特色的开源大模型生态闭环,不仅赋能科研机构与企业创新,也让中国 AI 开发者在全球模型生态中拥有更多自主性与话语权。
关于MOZILLA
Mozilla基金会是全球知名的非营利组织,致力于维护互联网的开放性、安全性与公平性。其发起的Mozilla Data Collective项目,旨在构建一个符合道德标准的数据经济基础设施,使数据的创作者、拥有者及社区能够完全掌控其数据的许可、访问与价值分配,从而挑战当前数据控制权集中的行业现状,为AI发展提供更丰富、更负责任的数据来源。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号