Python爬取网易云音乐歌单
1 # -*- coding:utf-8 -*- 2 3 import requests,os 4 from bs4 import BeautifulSoup 5 6 print( 7 ''' 8 -------------------------------------- 9 10 网易云音乐歌单下载 11 12 by:冷溪凌寒 13 V 1.0 14 -------------------------------------- 15 ''' 16 ) 17 18 search=input("请输入歌单ID:") 19 url="https://music.163.com/playlist?id="+search # 歌单地址 20 headers = { 21 'Referer': 'https://music.163.com/', 22 'Host': 'music.163.com', 23 'cookie':'',#自己获取 24 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 25 'user-agent':''#自己获取 26 } 27 s = requests.session() # 保持已登录状态 28 format = '{0:<10}\t{1:{3}<10}\t{2:<10}' # 输出规则 29 30 def get_list(): # 获取歌单列表 31 try: 32 response = s.get(url, headers=headers).content # 获取网页 33 soup = BeautifulSoup(response, 'html.parser') # html格式 34 lis = list(soup.find('ul')) # 寻找ul标签 35 father_list = [str(soup.find('h2').string)] # 获取歌单名字到表[0] 36 for i in lis: 37 son_list = [] 38 son_list.append(str(len(father_list)) + '.') # 序号 39 son_list.append(i.a.string) # 歌曲名称 40 son_list.append(str(i.a.get('href'))[str(i.a.get('href')).find('=') + 1:-1] + str(i.a.get('href'))[-1]) # 歌曲链接 41 father_list.append(son_list) # 添加到列表 42 43 except: 44 print("\n\t歌曲链接输入错误") # 错误情况 45 exit('ERROR!') 46 47 print("从'{}'中找到了{}条歌曲".format(str(soup.find('h2').string), len(father_list) - 1)) 48 return father_list 49 50 51 def mkdir(dir):#创建文件夹 52 dir = dir.translate({ord(i): None for i in '/\\:*?"<>|'}) # 将 /\:*?"<>| 文件不能命名的符号去除 53 54 isExists=os.path.exists(dir)#判断是否创建了文件夹 55 if not isExists: 56 os.makedirs(dir)#创建文件夹 57 print("创建文件夹'%s',将图片放入'%s'文件夹内。"%(dir,dir)) 58 else: 59 print("已经有'%s'文件夹,将图片放入'%s'文件夹内。"%(dir,dir)) 60 61 62 def download(list):#根据歌曲列表下载歌曲 63 print('---------------------------------------------------------------------------------------------------') 64 print('序号 歌曲名称 歌曲链接') 65 for i in list: 66 if list.index(i)==0: 67 continue 68 else: 69 i[1] = i[1].translate({ord(i): None for i in '/\\:*?"<>|'}) # 将 /\:*?"<>| 文件不能命名的符号去除 70 71 print(format.format(i[0], i[1], 'http://music.163.com/song/media/outer/url?id=' + i[2] + '.mp3', chr(12288))) # 排版 72 song_url = "https://link.hhtjim.com/163/" + i[2] + ".mp3" # 外链地址 73 song = requests.get(song_url).content # 获取歌曲源 74 75 with open(list[0] +'/'+ i[1] + '.mp3', 'wb') as f: # 写入文件夹 76 f.write(song) 77 f.close() 78 79 print('---------------------------------------------------------------------------------------------------') 80 print('下载结束!') 81 82 83 music_list=get_list() # 获取歌单列表 84 85 mkdir(music_list[0]) # 创建文件夹 86 87 download(music_list) # 通过歌单列表下载音乐
cookie与user-agent获取方法:
登录后进入https://music.163.com/
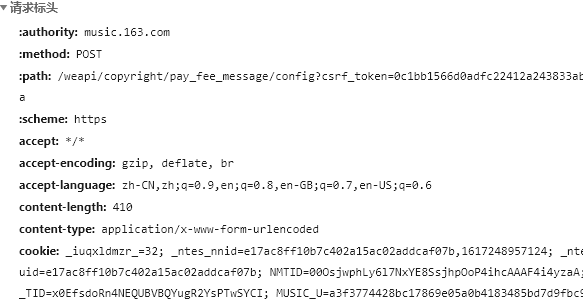
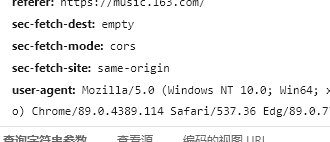
找到后写入代码中即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号