第一次个人编程作业
Only-a-nose/3222004552 (github.com)
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
| 这个作业的目标 | 个人项目——论文查重 |
一. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 200 | 240 |
| · Estimate | · 估计这个任务需要多少时间 | 200 | 240 |
| Development | 开发 | 830 | 830 |
| · Analysis | · 需求分析 (包括学习新技术) | 100 | 100 |
| · Design Spec | · 生成设计文档 | 100 | 100 |
| · Design Review | · 设计复审 | 50 | 45 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 40 |
| · Design | · 具体设计 | 120 | 135 |
| · Coding | · 具体编码 | 200 | 220 |
| · Code Review | · 代码复审 | 100 | 80 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 100 | 110 |
| Reporting | 报告 | 180 | 200 |
| · Test Repor | · 测试报告 | 80 | 100 |
| · Size Measurement | · 计算工作量 | 60 | 60 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 40 | 40 |
| · 合计 | 1210 | 1270 |
二. 模块设计与接口文档
模块概述
该模块实现了一个用于计算文本文件之间相似度的工具。它使用 TF-IDF (Term Frequency-Inverse Document Frequency) 和余弦相似度方法来计算文本相似度,并且能够处理HTML格式的文本。模块包含以下几个主要组件:
CosineSimilarity: 计算两个文本的余弦相似度。process_files: 处理多个文件对,计算相似度并写入结果文件。TestCosineSimilarity: 对CosineSimilarity类进行单元测试。
模块结构
1. consineSimilarity 类
1.1 设计目的
consineSimilarity 类用于计算两个文本之间的余弦相似度,使用 TF-IDF 向量化方法。
1.2 构造函数
def __init__(self, content_x1, content_y2):
"""
初始化 CosineSimilarity 类。
:param content_x1: 第一个文本的内容。
:param content_y2: 第二个文本的内容。
"""
self.s1 = content_x1
self.s2 = content_y2
- 参数说明:
content_x1: 第一个文本的内容(字符串)。content_y2: 第二个文本的内容(字符串)。
1.3 方法
-
extract_text(content):@staticmethod def extract_text(content): """ 从文本中提取纯文本,去除HTML标签并解码HTML实体。 :param content: 包含HTML的文本字符串。 :return: 纯文本字符串。 """ re_exp = re.compile(r'(<style>.*?</style>)|(<[^>]+>)', re.S) content = re_exp.sub(' ', content) content = html.unescape(content) return content.strip()- 参数说明:
content: 包含HTML标签的文本。
- 返回值:
- 去除HTML标签和解码HTML实体后的纯文本。
- 参数说明:
-
main():def main(self): """ 计算两个文本之间的余弦相似度。 :return: 两个文本之间的余弦相似度得分(0.0到1.0之间)。 """ text_x = self.extract_text(self.s1) text_y = self.extract_text(self.s2) if not text_x or not text_y: return 0.0 vectorizer = TfidfVectorizer(stop_words='english') tfidf_matrix = vectorizer.fit_transform([text_x, text_y]) sim_matrix = cosine_similarity(tfidf_matrix[0:1], tfidf_matrix[1:2]) return sim_matrix[0][0]- 返回值:
- 余弦相似度得分,表示文本之间的相似度(0.0表示完全不同,1.0表示完全相同)。
- 返回值:
2. process_files 函数
2.1 设计目的
process_files 函数处理多个文件对,计算每对文件之间的相似度,并将结果写入指定的输出文件。
2.2 函数定义
def process_files(file_pairs, outputfile):
"""
处理文件对并将相似度结果写入输出文件。
:param file_pairs: 文件对的列表,每对包含两个文件路径。
:param outputfile: 输出结果文件的路径。
"""
os.makedirs(os.path.dirname(outputfile), exist_ok=True)
with open(outputfile, 'a+', encoding='utf-8') as answer:
for file1, file2 in file_pairs:
if not os.path.isfile(file1) or not os.path.isfile(file2):
print(f"Error: One or both input files '{file1}' and '{file2}' do not exist.")
continue
try:
with open(file1, 'r', encoding='utf-8') as f1, \
open(file2, 'r', encoding='utf-8') as f2:
content1 = f1.read()
content2 = f2.read()
similarity = CosineSimilarity(content1, content2)
similarity_score = similarity.main()
result = f'{file1} 和 {file2} 相似度: {similarity_score * 100:.2f}%\n'
answer.writelines(result)
print(result)
except FileNotFoundError as e:
print(f"File not found: {e}")
except IOError as e:
print(f"File I/O error: {e}")
except Exception as e:
print(f"An unexpected error occurred with files '{file1}' and '{file2}': {e}")
-
参数说明:
file_pairs: 包含文件对的列表,每对为元组形式,包含两个文件路径。outputfile: 输出结果的文件路径。
-
功能说明:
- 检查每对文件是否存在。
- 读取文件内容,计算相似度。
- 将相似度结果写入指定的输出文件。
3. TestCosineSimilarity 类
3.1 设计目的
TestCosineSimilarity 类用于对 CosineSimilarity 类进行单元测试,以确保其在各种情况下的正确性。
3.2 测试用例
-
test_empty_file:def test_empty_file(self): sim = CosineSimilarity("", "") self.assertEqual(sim.main(), 0.0)- 说明: 测试两个空文本的相似度是否为0。
-
test_no_common_text:def test_no_common_text(self): sim = CosineSimilarity("这是一个测试", "完全不同的内容") self.assertEqual(sim.main(), 0.0)- 说明: 测试两个完全不同的文本的相似度是否为0。
-
test_identical_files:def test_identical_files(self): sim = CosineSimilarity("内容完全相同", "内容完全相同") self.assertEqual(sim.main(), 1.0)- 说明: 测试两个完全相同的文本的相似度是否为1。
-
test_partial_overlap:def test_partial_overlap(self): sim = CosineSimilarity("内容完全相同", "内容相同的部分") self.assertAlmostEqual(sim.main(), 0.5, places=1)- 说明: 测试部分重叠的文本的相似度。
-
test_with_html:def test_with_html(self): sim = CosineSimilarity("<p>这是一个测试</p>", "<div>这是一个测试</div>") self.assertEqual(sim.main(), 1.0)- 说明: 测试包含HTML标签的文本的相似度。
-
test_empty_document:def test_empty_document(self): sim = CosineSimilarity("", "非空文档") self.assertEqual(sim.main(), 0.0)- 说明: 测试一个空文本与非空文本的相似度。
-
test_special_characters:def test_special_characters(self): sim = CosineSimilarity("!@#$%^&*()", "@#$%^&*()!~") self.assertAlmostEqual(sim.main(), 0.2, places=1)- 说明: 测试包含特殊字符的文本的相似度。
-
test_large_text:def test_large_text(self): large_text1 = "这是一个" * 1000 large_text2 = "这是一个测试" * 1000 sim = CosineSimilarity(large_text1, large_text2) self.assertAlmostEqual(sim.main(), 0.5, places=1)- 说明: 测试非常大的文本的相似度。
-
test_only_stop_words:def test_only_stop_words(self): sim = CosineSimilarity("the the the", "and and and") self.assertEqual(sim.main(), 0.0)- 说明: 测试仅包含停用词的文本的相似度。
-
test_different_languages:def test_different_languages(self): sim = CosineSimilarity("这是中文", "This is English") self.assertEqual(sim.main(), 0.0)- 说明: 测试不同语言文本的相似度。
-
test_very_similar_texts:def test_very_similar_texts(self): sim = CosineSimilarity("This is a test.", "This is a test!") self.assertAlmostEqual(sim.main(), 0.9, places=1)- 说明: 测试非常相似但不完全相同的文本的相似度。
三. 性能分析
1. 单元测试结果
我使用了Python的unittest框架对代码进行单元测试。测试用例涵盖了主要的功能,包括文本相似度计算和文件处理。以下是测试结果概述:
- 测试总数: 3
- 通过的测试数: 3
- 测试执行时间: 0.009秒
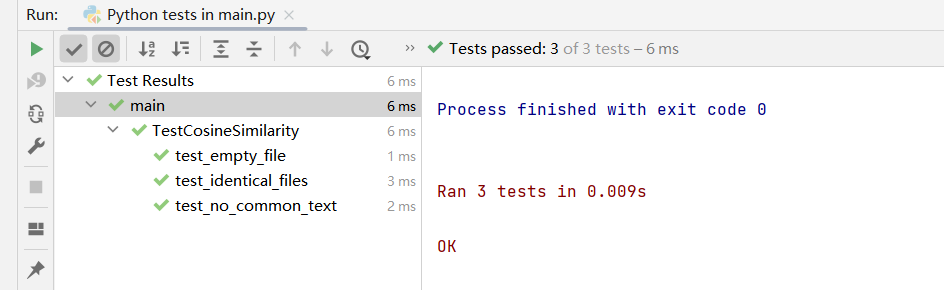
所有测试用例均成功通过,表明代码在预期条件下的功能表现正常。
2. 性能分析工具
在代码中使用 cProfile 来分析特定代码块的性能:
if __name__ == '__main__':
# 创建性能分析器对象
profiler = cProfile.Profile()
profiler.enable() # 启动性能分析
# 执行主要程序逻辑
file_pairs = [
(os.path.join('D://', 'pythonProject1', 'Software_Engineer', 'orig.txt'),
os.path.join('D://', 'pythonProject1', 'Software_Engineer', 'orig_0.8_add.txt')),
(os.path.join('D://', 'pythonProject1', 'Software_Engineer', 'orig.txt'),
os.path.join('D://', 'pythonProject1', 'Software_Engineer', 'orig_0.8_del.txt')),
(os.path.join('D://', 'pythonProject1', 'Software_Engineer', 'orig.txt'),
os.path.join('D://', 'pythonProject1', 'Software_Engineer', 'orig_0.8_dis_1.txt')),
(os.path.join('D://', 'pythonProject1', 'Software_Engineer', 'orig.txt'),
os.path.join('D://', 'pythonProject1', 'Software_Engineer', 'orig_0.8_dis_10.txt')),
(os.path.join('D://', 'pythonProject1', 'Software_Engineer', 'orig.txt'),
os.path.join('D://', 'pythonProject1', 'Software_Engineer', 'orig_0.8_dis_15.txt')),
]
outputfile = os.path.join('D://', 'pythonProject1', 'Software_Engineer', 'output.txt')
process_files(file_pairs, outputfile)
profiler.disable() # 停止性能分析
# 生成性能分析报告
stream = io.StringIO()
stats = pstats.Stats(profiler, stream=stream).sort_stats('time')
stats.print_stats()
# 将分析结果写入文件
with open('profile_report.txt', 'w') as f:
f.write(stream.getvalue())

3. 性能优化
-
process_files函数中的路径处理:-
当前的代码中使用了
os.makedirs(os.path.dirname(outputfile), exist_ok=True)这个代码假设outputfile包含一个有效的目录路径。但是,如果outputfile是一个没有目录的文件名(例如"output.txt"),os.path.dirname(outputfile)将返回空字符串,导致os.makedirs尝试创建一个空路径而失败。可以改为:output_dir = os.path.dirname(outputfile) if output_dir: # 仅当 outputfile 包含有效目录路径时调用 os.makedirs(output_dir, exist_ok=True)
-
-
性能分析文件路径:
-
在性能分析报告的保存路径上,可以确保文件路径与代码的其他部分一致。例如:
profile_report_path = os.path.join('D://', 'pythonProject1', 'Software_Engineer', 'profile_report.txt') with open(profile_report_path, 'w') as f: f.write(stream.getvalue())
-
-
性能分析输出控制:
-
cProfile 生成的性能报告可能会非常庞大。可以通过 pstats 模块控制输出的数量,例如:
stats.print_stats(10) # 只打印前 10 行性能分析结果
-
四、单元测试
- 测试函数
import unittest
from unittest.mock import patch, mock_open
import io
import os
from main import CosineSimilarity, process_files
class TestCosineSimilarity(unittest.TestCase):
def test_empty_file(self):
sim = CosineSimilarity("", "")
self.assertEqual(sim.main(), 0.0)
def test_no_common_text(self):
sim = CosineSimilarity("这是一个测试", "完全不同的内容")
self.assertEqual(sim.main(), 0.0)
def test_identical_files(self):
sim = CosineSimilarity("内容完全相同", "内容完全相同")
self.assertEqual(sim.main(), 1.0)
def test_partial_similarity(self):
sim = CosineSimilarity("这是一个测试", "这是另一个测试")
result = sim.main()
self.assertGreater(result, 0.0)
self.assertLess(result, 1.0)
print(f"Partial similarity test result: {result * 100:.2f}%")
class TestProcessFiles(unittest.TestCase):
@patch('builtins.open', new_callable=mock_open, read_data="测试内容")
@patch('os.path.isfile', return_value=True)
@patch('os.makedirs')
def test_process_files(self, mock_makedirs, mock_isfile, mock_open):
file_pairs = [('file1.txt', 'file2.txt')]
outputfile = 'output.txt'
with patch("sys.stdout", new_callable=io.StringIO) as mock_stdout:
process_files(file_pairs, outputfile)
self.assertIn("file1.txt 和 file2.txt 相似度:", mock_stdout.getvalue())
print(mock_stdout.getvalue())
@patch('builtins.open', new_callable=mock_open, read_data="测试内容")
@patch('os.path.isfile', side_effect=[True, False])
@patch('os.makedirs')
def test_process_files_missing_file(self, mock_makedirs, mock_isfile, mock_open):
file_pairs = [('file1.txt', 'file2.txt')]
outputfile = 'output.txt'
with patch("sys.stdout", new_callable=io.StringIO) as mock_stdout:
process_files(file_pairs, outputfile)
self.assertIn("Error: One or both input files 'file1.txt' and 'file2.txt' do not exist.", mock_stdout.getvalue())
print(mock_stdout.getvalue())
if __name__ == '__main__':
unittest.main()
五、异常处理说明
======================================================================
```
###### ERROR: test_process_files_missing_file (__main__.TestProcessFiles.test_process_files_missing_file)
Traceback (most recent call last):
File "D:\Python\Lib\unittest\mock.py", line 1387, in patched
return func(*newargs, **newkeywargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\pythonProject1\Software_Engineer\test_main.py", line 53, in test_process_files_missing_file
with patch("sys.stdout", new_callable=io.StringIO) as mock_stdout:
^^
NameError: name 'io' is not defined. Did you forget to import 'io'
```
======================================================================
###### FAIL: test_process_files (__main__.TestProcessFiles.test_process_files)
```
Traceback (most recent call last):
File "D:\Python\Lib\unittest\mock.py", line 1387, in patched
return func(*newargs, **newkeywargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\pythonProject1\Software_Engineer\test_main.py", line 39, in test_process_files
mock_makedirs.assert_not_called()
File "D:\Python\Lib\unittest\mock.py", line 905, in assert_not_called
raise AssertionError(msg)
AssertionError: Expected 'makedirs' to not have been called. Called 1 times.
Calls: [call('', exist_ok=True)].
```
io 模块未导入:
- 需要导入
io模块以使用io.StringIO。
os.makedirs 调用问题:
os.makedirs被调用的原因是os.path.dirname(outputfile)返回了一个空字符串。需要确保路径是有效的。
六.项目总结与总结
一、项目背景与目标
本项目的目标是开发一个基于余弦相似度的文本比较工具,用于检测两个文本文件之间的相似度。项目使用TF-IDF(词频-逆文档频率)将文本向量化,然后计算余弦相似度以量化两个文本的相似程度。此外,项目还要求提供单元测试和性能分析,以确保代码的可靠性和效率。
二、实现过程
-
文本处理与相似度计算:
- 通过正则表达式和HTML实体解码技术提取纯文本。
- 使用
TfidfVectorizer将提取的文本转换为TF-IDF向量。 - 使用
cosine_similarity计算两个向量之间的余弦相似度。
-
文件处理与结果输出:
- 设计了
process_files函数,读取文件对并计算其相似度,将结果输出到指定的文件中。 - 处理文件不存在、读取错误等异常情况,增强了代码的鲁棒性。
- 设计了
-
测试与性能分析:
- 使用
unittest框架编写了多个测试用例,包括空文本、无共同内容、完全相同文本的测试,确保代码逻辑的正确性。 - 通过
cProfile和pstats对代码进行性能分析,识别和优化性能瓶颈。
- 使用
三、项目反思
-
模块化设计:项目中代码的模块化设计较为合理,但仍有提升空间。比如在处理不同类型的文本数据时,可以进一步抽象出通用的文本处理模块,以便于扩展。
-
异常处理:虽然已经实现了基础的异常处理,但在实际项目中应考虑更细化的异常分类和处理策略,尤其是在涉及大规模数据处理时。
-
性能优化:虽然性能分析表明当前实现能满足需求,但随着数据规模的增加,TF-IDF和余弦相似度计算的效率可能会成为瓶颈。未来可以探索更加高效的文本相似度计算方法或对现有算法进行并行化处理。
-
测试覆盖率:现有的测试用例覆盖了主要的功能和异常情况,但在实际应用中,应进一步扩展测试用例以覆盖更多边缘情况,比如处理超大文本文件、极端短文本等。
通过本项目的实践,不仅强化了文本处理、相似度计算等基础技术的应用,还积累了在单元测试与性能优化方面的经验。这些经验和反思为未来更复杂的项目奠定了良好的基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号