Sql语句的知识积累
SELECT T1.ManagerName Manager,T2.* FROM platform.dbo.Bonus_Amazon_ManagerTarget T1 WITH(NOLOCK) OUTER APPLY ( SELECT Income=SUM(Income), AfnIncome= SUM(AfnIncome), InstockQTY=SUM(InstockQTY), InstockCost=SUM(InstockCost), InboundQTY=SUM(InboundQTY), InboundCost=SUM(InboundCost), NotCount=SUM(NotCount), NotCountCost=SUM(NotCountCost), ActualInCount=SUM(ActualInCount), ActualInCountCost=SUM(ActualInCountCost), TotalCost=SUM(TotalCost), Rate=SUM(Rate), ThirtySalesQty=SUM(ThirtySalesQty), DOI=SUM(DOI), SyncTime=MAX(SyncTime) FROM Formal_Amazon.dbo.Report_Stockup_AmazonShop WHERE Manager LIKE '%'+T1.ManagerName+'%' ) T2 WHERE T1.DataYear=DATEPART(YEAR,GETDATE()) AND T1.DataMonth=DATEPART(MONTH,GETDATE())
1、outer apply,主要是为了追加字段。该写法不适合复杂的sql查询,但有时候也是一个查询的解决方案,作为写SQL语句,应该要了解的一个写法
2、sql server中的datediff与dateadd,效率相差很大。datediff会破坏索引。具体操作可以写两条sql语句,
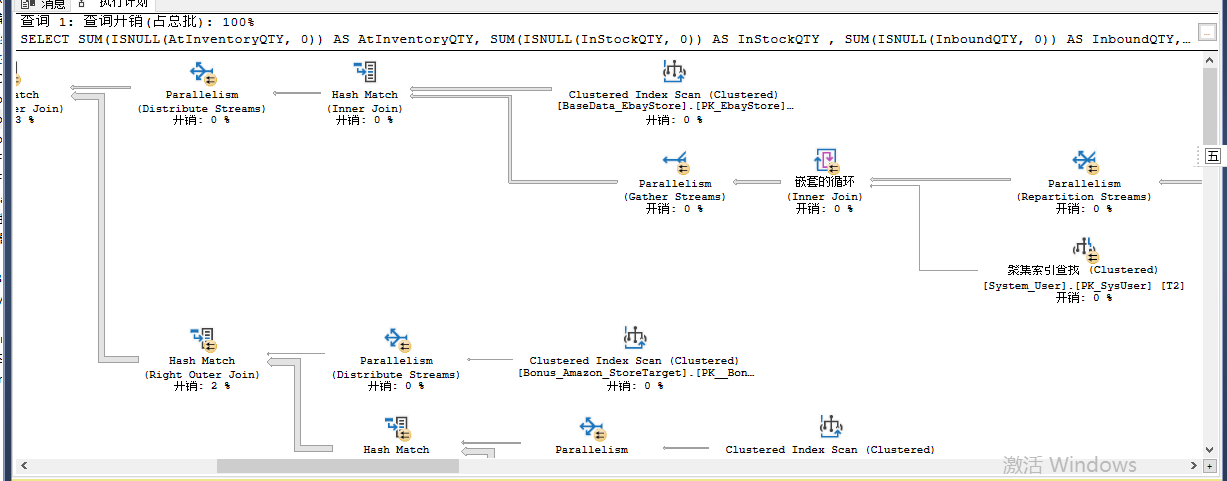
然后通过“显示估计的执行计划”来看执行效率 (PS:显示估计的执行计划,是优化sql非常重要的一个手段。ssms一般都会有,反正我的v18.5是有的)
3、数据库,存储过程处理事务的示例:
CREATE PROCEDURE [dbo].[Proc_Update_ReplenishmentApply_SCMDockingReceivNo] AS BEGIN SET NOCOUNT ON; BEGIN TRY BEGIN TRANSACTION tr; IF EXISTS ( SELECT * FROM tempdb.dbo.sysobjects WHERE id = OBJECT_ID( N'tempdb..#SCMDockingReceivNoInfo') AND type = 'U' ) DROP TABLE #SCMDockingReceivNoInfo; CREATE TABLE #SCMDockingReceivNoInfo ( StockPileID NVARCHAR(100) , DockingReceivNo NVARCHAR(100) , EstimateTime DATETIME , ActualTime DATETIME ); INSERT INTO #SCMDockingReceivNoInfo ( StockPileID , DockingReceivNo , EstimateTime , ActualTime ) SELECT DISTINCT s2.StockPileID , ISNULL( s1.DockingReceivNo, s1.ShipmentID) , s1.EstimateTime , s1.ActualTime FROM [SCM].Tidebuy_SCM.dbo.View_Platform_Delivery s1 JOIN [SCM].Tidebuy_SCM.dbo.View_PlatformDeliveryQuery s2 ON s2.DeliveryID = s1.ID AND ISNULL( s2.StockPileID , '') <> '' WHERE s1.IsDisabled = 0 AND s1.CreateTime > '2020-01-01'; UPDATE a SET a.SCMDockingReceivNo = b.DockingReceivNo , a.SCMEstimateTime = b.EstimateTime , a.SCMActualTime = b.ActualTime FROM Report_ReplenishmentApply a JOIN #SCMDockingReceivNoInfo b ON b.StockPileID = a.ApplyNumber WHERE a.AuditStage = 1030 AND ISNULL(a.ApplyNumber, '') <> '' COMMIT TRANSACTION tr; END TRY BEGIN CATCH ROLLBACK TRANSACTION tr; SELECT 0 AS result; END CATCH; SET NOCOUNT OFF; END; GO
存储过程写的挺多的,但很少在存储过程写事务。一般都是通过ORM自带的事务,在VS代码端做处理。
4、常见的通过sql语句给表添加字段的方法:ALTER TABLE Warehouse_Warehouse ADD EnableStatus BIT
5、sql语句将查出来的数据集,针对某一列进行拼接,然后显示成一个字符串
SELECT LogisticsNO = ( SELECT LogisticsNO + ',' FROM SCM.Tidebuy_SCM.dbo.View_Provider_Logistics_Batch t3 WITH (NOLOCK) WHERE t3.BatchID = t1.SCMBatchId AND t3.LogisticsNO IS NOT NULL FOR XML PATH('') )
一般与outer apply联合使用。比如店铺和运营的表,一个店铺对应多个运营人员。界面显示时,运营人员列就可以这样拼接出来,
6、非聚集索引创建,有前后之分。放在前面的,是经常使用的。如果放后面,查询该列时,不会走索引(据说)
7、
COLLATE Chinese_PRC_CS_AI用来区分大小写的,例如:
T1.SellerSKU COLLATE Chinese_PRC_CS_AI = inventory.SKU COLLATE Chinese_PRC_CS_AI
用来判断T1.SellerSKU与inventory.SKU在区分大小写的情况下,是否相等
类似的还有COLLATE Chinese_PRC_CI_AI,作用是不区分大小写。具体可以网上查查,还有很多这种函数
8、会破坏索引的函数有:is null、ISNULL(有人说,不会破坏。这需要再证实一步)、OR、DateDiff
select * from table where time is null 这种会破坏
select * from table where isnull(time,getdate())='2021-12-01' 这种不会破坏
写SQL语句时如果用上了某一个,就会造成对应列的索引无效。例如:Id为主键,是聚合索引,
select * from table where Id=1 or Id=2 没有 select * from table where Id in (1,2) 好
9、sql server分组之后取最新一条数据
SELECT * FROM
(SELECT B2BOrderId,ReceiveDate,MessageType,ROW_NUMBER() OVER(PARTITION BY B2BOrderId ORDER BY ReceiveDate DESC) AS lastReceive
FROM dbo.VidaxlEmail WHERE B2BOrderId>0) T WHERE T.lastReceive=1
ROW_NUMBER() OVER(PARTITION BY…… Order By……) 这个语法的解释是“部分分组再排序”。用处比较多
上面的sql是取出某表中,重复数据的最新记录。但还可以用于查出多余的重复记录。例如:
SELECT * FROM dbo.Warehouse_Inventory WHERE Id IN ( SELECT t.Id FROM ( SELECT *,ROW_NUMBER() OVER(PARTITION BY CompanyId,WarehouseId,SKU,PmsSKU,InStockQTY,TokenGroupId ORDER BY Id ASC) 'NewSort' FROM dbo.Warehouse_Inventory WHERE CompanyId =2 ) t WHERE t.NewSort>1 )
ROW_NUMBER() OVER(……)可以与很多函数搭配。常见的面试题,取出第30-40条记录,Id不连续。也是用的ROW_NUMBER() OVER(Order by Id Asc)
其他的可以网上查查,与之组合使用的是挺多的
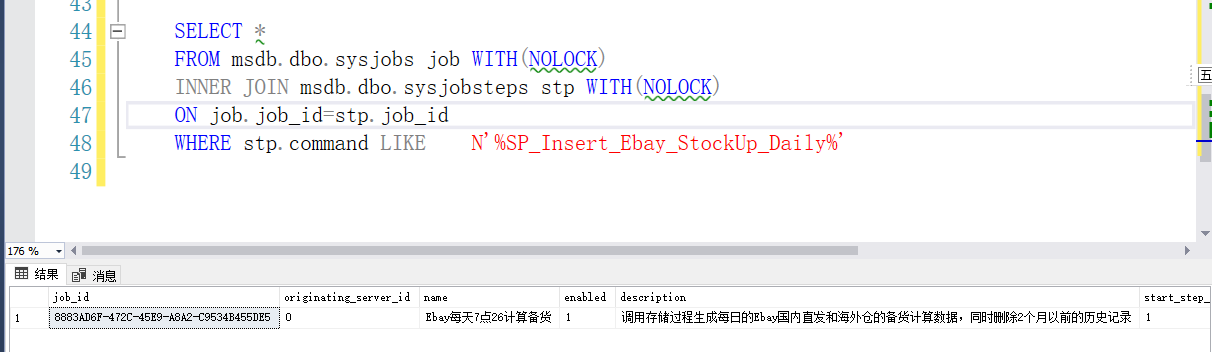
9、已知存储过程,查找调用的作业位置
SELECT * FROM msdb.dbo.sysjobs job WITH(NOLOCK) INNER JOIN msdb.dbo.sysjobsteps stp WITH(NOLOCK) ON job.job_id=stp.job_id WHERE stp.command LIKE N'%SP_Insert_Ebay_StockUp_Daily%'
10、已知道表,查找当前数据库下的视图或者存储过程是否用到了该表:
SELECT DISTINCT OBJECT_NAME(id) FROM syscomments WHERE id IN ( SELECT id FROM sysobjects WHERE type IN ('V','P') ) AND text LIKE '%Amazon_ImmediatelySaleReport%'
如果是同数据库下面,可以直接选中表,查找依赖项,可以看到调用的视图或存储过程。但如果跨数据库了,则该sql可能更方面
比如Amazon_ImmediatelySaleReport是在Formal_Amazon数据库下,但Formal_Ebay下某个视图跨库调用了这个表,所以需要在Formal_Ebay下执行这个sql。能查出对应的视图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号