
本地大语言模型部署 4 小时踩坑 & 解决笔记,微调接近 GPT-4 的路子
本地大语言模型部署 4 小时踩坑 & 解决笔记,微调接近 GPT-4 的路子
2025 年 09 月 02 日 18:01
anything LLM、ollama、qwen 2.5、、Gemma3、魔塔社区、GGUF、Hugging Face、连接超时、AI 幻觉、自问自答、提示词优化、轻量级微调、GPT-4、缓存清理
笔记摘要
我搞本地大语言模型部署,最开始用伪数据根本白费劲,数据没调用起来,离目标差老远。后来从 anythingLLM 入手,先更新软件解决旧版难用的问题,结果又遇连接超时、ollama更新不了、模型自问自答停不下来这些破事。折腾半天,靠重装、换清华源、改 model file 配置搞定了基础问题,还发现拼多多买的 GGUF 格式模型没法微调,最后在魔塔社区下了 Hugging Face 格式的qwen 2.5 和Gemma 3 4B 模型。现在不仅解决了模型幻觉和识别问题,还制定了从提示词优化到轻量级微调、再用 API 对比的计划,目标是把模型提到 GPT4 水平,4 小时虽然累但问题都没卡死,还学了不少东西。
开局就碰壁:旧数据没用,软件先更新
最开始我以为之前攒的伪数据能用上,结果根本没调用起来,模型跟没喂东西一样。没办法只能从头来,先搞 anything LLM—— 这玩意儿是智能体和大模型本地部署的嫁接工具,旧版本难用到爆,必须更!更新后页面舒服多了,对模型的兼容度也高了,这步算没白干。
连环坑来了:连接超时 + ollama更不了
更新完 anything IOM,点开历史列表跑旧模型,直接报错(说白了就是连超时了)。查了下是之前没装好,环境配置有隐藏问题,只能重装。结果重装时欧拉玛又掉链子,拉模型失败,才发现这玩意儿四个月没更了!原网站还 403 进不去,最后靠清华源和 GitHub 才更完欧拉玛。
新模型能用了,但它自己聊嗨了
欧拉玛更完,终端里调用命令查模型在不在,在就重装了个千问 2.5 latest。刚开始卡得要死,删了缓存才正常输出。问它 “你是谁” 还好好的,说自己是阿里云的模型,结果后面全乱了 —— 我问 “你好”,它自己跟自己聊北京天气;再测,又开始讲编程,停都停不下来,只能按 Ctrl+C 打断。改提示词让它别多话,结果它还给我扯爱情,我真是服了!
解包路走死,改配置才救场
搜了下,这是 AI 幻觉 + 不会终止对话,有人说要解包调映射字符 ID 或终止 ID,但我这千问 2.5 是 GGUF 格式,根本没法解包,纯纯绕远路。问 AI,它让我调结束编码权重,可我操作不了啊!最后 AI 说改 model file,给了段代码,把模型名、系统提示词、算法设置都写进去,重装一遍居然好了!就是第一次调用得等十几分钟,取消重开几次才正常。
anything LLM 又抽风:认旧模型不认新的
前面问题解决了,回头用 anythingLLM,又提示连接超时,好不容易不超时了,它说找不到我要的模型 —— 我建的是qwen2.5 latest,它非得找我早删了的 “my 千问 latest”,明显是缓存没清干净。试了重开软件、配调用 ;LM、删 config.json、关进程重启电脑,全没用!去论坛看,好多人遇这情况,有人说新开窗口,我试了也不行,结果隔了十几分钟自己好了,搞不懂。
发现宝藏平台:魔塔社区救了微调的命
中间闲得逛网页,发现个叫 ModelScope(中文魔塔社区)的免费平台,里面全是开源模型包。之前在拼多多买的 GGUF 格式,只能给小白用,想微调根本不可能,魔塔社区里有 Hugging Face 格式的模型,这才是能调的专业货!我下了qwen 2.5 7B(中文好还支持深度思考,能替掉难用的 deep sk RE)和谷歌的Gemma 3 4B(英文的,用来跟千问对比练手)。
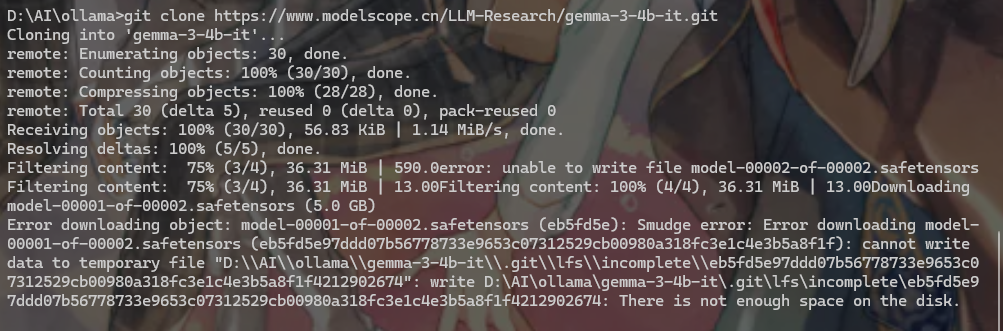
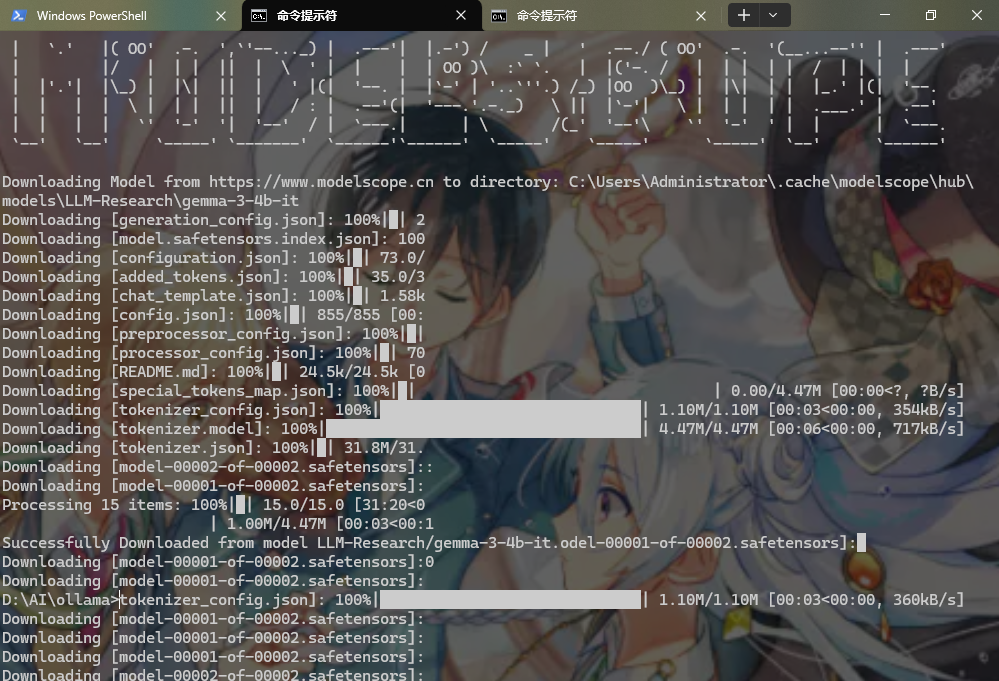
模型格式 & 下载踩点:SDK 比 Git 靠谱多了
本地部署模型就三种格式:Hugging Face 多文件的,能解包能微调,最适合我;GGUF 整包的,没法解包;欧拉玛镜像的,外网下得慢死。魔塔社区有两种下载方式,我先试 Git,结果 10GB 的文件老中断,换成它自家的 SDK,支持断点传输,断了也能续,太香了!用 SDK 下完qwen2.5,之前的 AI 幻觉和 anything LLM 认不出模型的问题,居然一起解决了,拼多多那模型是真坑。
冲 GPT4 的路子:从简单到复杂分三步
我问 AI,有完整提示词了,加进系统提示词算不算微调?还想进一步提升到 GPT4 水平该咋弄?AI 说第一步先搞提示词工程,不算微调但见效快,让模型学 GPT4 的回答逻辑,比如分点、避幻觉,还得补点高质量案例(我找了 GPT4 的学科解释、编程、算法回答当模板);第二步搞轻量级微调,用 LoRA 或 QLoRA,得写代码加对话数据、补知识提推理能力,AI 给了段代码但不全,得自己补;第三步全量微调,效果最好但要多 GPU 多内存(没钱),我这 3B-10B 的模型扛不住,先不搞。
接下来要干的三件事:部署 + 优化 + 对比
现在就等剩下的模型下完,先把提示词优化了 —— 补个 AI 能懂的框架、加三个 GPT4 优质案例、写清训练逻辑,塞系统提示词里就能提思考能力;然后用 LoRA 和 AI 给的代码,在 Hugging Face 模型里改,提升推理和对话能力,我 32GB 显卡跑 3B-7B 的模型够了;最后拉个免费 API 模型,把我调好的提示词扔进去,看看不同体量模型效果差多少。
要点回顾
1. 最开始遇到的核心问题是啥?
之前弄的伪数据根本没被调用,模型没达到预期效果,等于白忙活。
2. 解决问题的第一步是啥?
先更 anything LLM,这工具是本地部署的关键,更完页面优化了,模型兼容度也高了,还顺带解决了部分连接问题。
3. ollama更新时卡在哪?怎么解决的?
原网站 403 进不去,拉模型失败,最后用清华的源和 GitHub 才更成功。
4. 模型自问自答最关键的解决办法是啥?
改 model file 配置,把模型信息、系统提示词、算法设置写进去,重装模型就好了,调结束编码权重那套我用不了,因为文件格式不对。
5. 为啥选qwen2.5 和 Gemma 3 4B?
千问 2.5 是中文的,支持深度思考,能替掉 deep sk R1;Gemma 3 是谷歌的英文模型,俩放一起能对比着练微调,为后面冲 GPT-4 做准备。
6. 魔塔社区最香的点是啥?
有 Hugging Face 格式的模型,能微调,还能用 SDK 断点下载大文件,比 Git 靠谱太多,解决了我之前调不了模型的大难题。
7. 冲 GPT4 分哪几步?先干哪步?
分提示词工程、轻量级微调、全量微调三步,先干提示词工程,简单见效快,先让模型学 GPT4 的回答逻辑。
8. 这 4 小时都干了啥?值吗?
收集数据、解决连接超时 / AI 幻觉 / 缓存问题、学模型格式知识、下模型、定计划,虽然累,但没遇到解决不了的问题,还学了不少东西,太值了。
待办事项
-
等剩下的模型下载完,完成本地部署
-
优化提示词:补 AI 框架、加 GPT-4 优质案例、写训练逻辑
-
用 LoRA 和代码搞轻量级微调,提升模型知识覆盖和推理能力
-
拉免费 API 模型,对比不同体量模型的效果
-
监控模型性能,慢慢往 GPT-4 的水平靠
-
把 Gemma3 4B 也部署好,跟qwen2.5 对比测试
感谢浏览和学习,作者:鱼油YOU,转载请注明原文链接:https://www.cnblogs.com/OmegaYOU3/p/19070526,或者可以➕主播WX:OmegaAnimeman_desu;QQ:3819054512

 浙公网安备 33010602011771号
浙公网安备 33010602011771号