Python 爬虫实例
下面是我写的一个简单爬虫实例
1.定义函数读取html网页的源代码
2.从源代码通过正则表达式挑选出自己需要获取的内容
3.序列中的htm依次写到d盘
#!/usr/bin/python
import re
import urllib.request
#定义函数读取html网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
#从源代码通过正则表达式挑选出自己需要获取的内容
def getImg(html):
reg = r'href="(.*?\.htm)"'
imgre = re.compile(reg)
implist = re.findall(imgre,html)
#序列中的htm依次写到d盘
x = 0
for imgurl in implist:
urllib.request.urlretrieve(imgurl, 'D:\htm\%s.htm' % x)
x += 1
html = getHtml("http://www.10086.cn/hb/index_270_719.html")
html = html.decode('utf-8')
print(getImg(html))
运行程序结果:
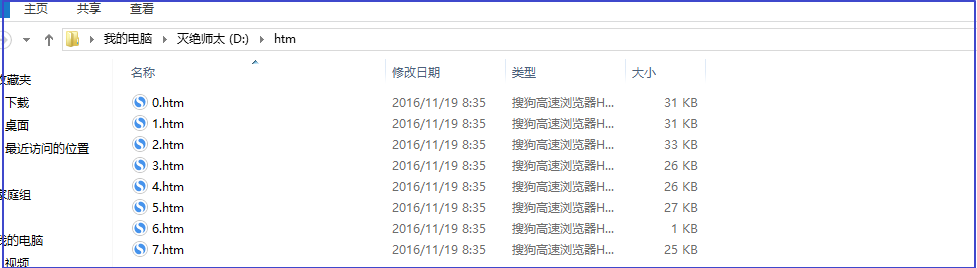
作者:奔跑的金鱼
声明:书写博客不易,转载请注明出处,请支持原创,侵权将追究法律责任
个性签名:人的一切的痛苦,本质上都是对自己无能的愤怒
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号