FAFU 专业技能考核题目模拟题解析(仅供参考)
排序


思路:
直接做一次排序 然后特判一下即可
需要注意输出格式是在每个数前输出空格
排序推荐直接使用c++的sort函数
需要下面这两句引入
#include <algorithm>
using namespace std;
代码:
#include "stdio.h"
#include <algorithm>
using namespace std;
int main(){
int a[1005],b[1005], n, i, j, k, m, t, aver=0;
FILE *fp;
if((fp=fopen("sort.in", "r")) != NULL ){
fclose(fp); //存在的话,要先把之前打开的文件关掉
freopen("sort.in", "r", stdin);
//freopen("sort.out", "w", stdout);
}
scanf("%d", &n);
for( i=0; i<n; i++){
scanf("%d", &a[i]);
aver += a[i];
}
aver = (int)(1.0*aver/n + 0.5) ;
//********************************************************
//为a数组从小到大排序
sort(a,a + n);
k = 0;//记录到哪个位置 大于平均数
for(i = 0; i < n; i++){
if(a[i] <= aver){
printf(" %d",a[i]);
}
else { //此时大于平均数 要逆序输出
k = i;
break;
}
}
//开始逆序输出
for(i = n-1;i >= k;i--){
printf(" %d",a[i]);
}
//========================================================
return 0;
}
哈夫曼树(比较难)
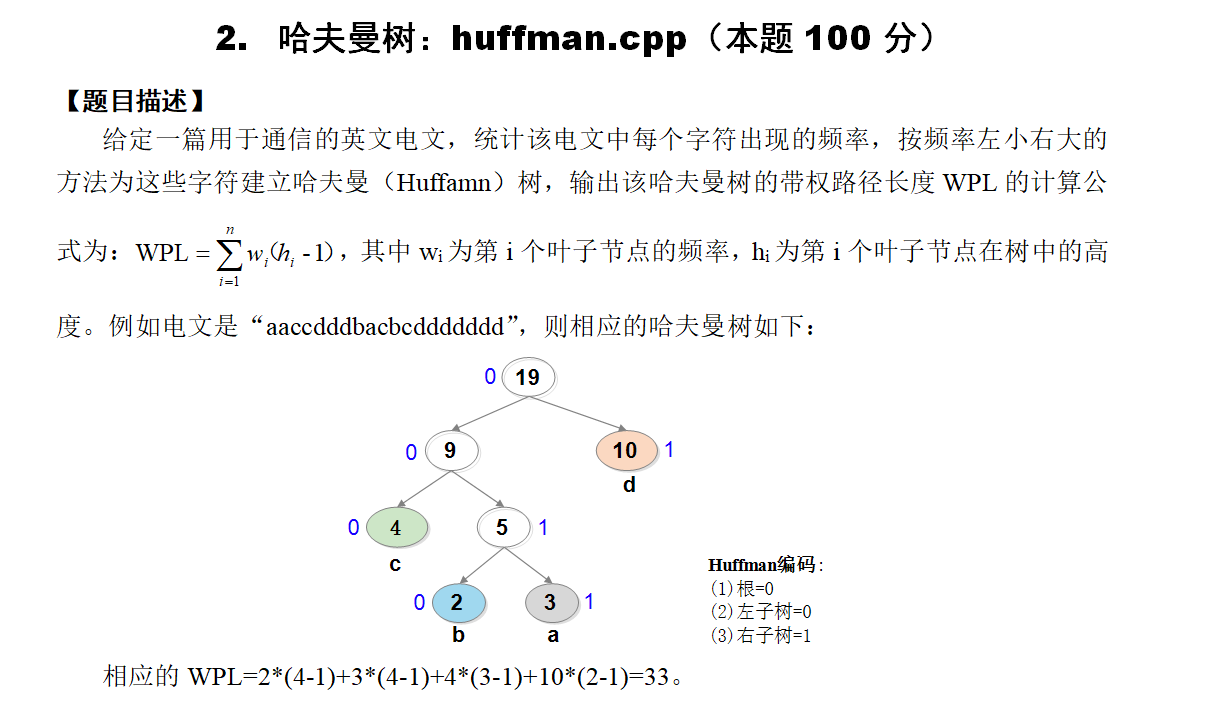

思路:
最麻烦的地方在于构建数结构 哈夫曼的思维是每次取列表中两个值最小的合并 合并后的值加入列表
通过使用优先队列的小根堆结构 可以比较方便的实现
使用pair结构保存节点的值和节点的下标
优先队列会默认按照pair的first值排序 省去一部分代码
树结构创建好后 就很简单了 从根节点遍历递归即可
代码:
#include "stdio.h"
#include <queue>
#define x first
#define y second
using namespace std;
typedef pair<int,int> PII;
priority_queue<PII,vector<PII>,greater<PII> >q; //小根堆
const int N0=1000;
const int inf=10000000;
struct node1{
int w, lch, rch, parent;
}ht[2*N0];
int n=0, root, WPL=0;
void readData(){
int i;
int num[256]={ 0 };
char ch;
while( (ch=getchar())!=EOF ){
num[ch]++;
}
for( i=0; i<=255; i++ ){
if( num[i] ){
n++;
ht[n].w=num[i];
}
}
root=2*n-1;
}
//********************************************************
void create_ht(){
int i;
for(i = 1;i <= n;i++){
PII p = {ht[i].w,i};
q.push(p);
}
//每次从优先队列中取两个最小值出来
while(!q.empty() && q.size() > 1){
auto q1 = q.top();
q.pop();
auto q2 = q.top();
q.pop();
n++;
ht[n].w = q1.x + q2.x; //构建节点并添加到优先队列中
ht[n].lch = q1.y;
ht[n].rch = q2.y;
q.push({ht[n].w,n});
}
root = n;
}
//========================================================
void doWPL( int root, int high ){
//********************************************************
if(ht[root].lch ==0 && ht[root].rch == 0){ //没有左儿子以及右儿子 说明递归到底部 根据公式计算值
WPL += ht[root].w * (high - 1); //计算值
return ;
}
if(ht[root].lch != 0){ //如果有左儿子
doWPL(ht[root].lch,high + 1);
}
if(ht[root].rch != 0){ //如果有右儿子
doWPL(ht[root].rch,high + 1);
}
//========================================================
}
int main(){
FILE *fp;
if((fp=fopen("huffman.in", "r")) != NULL ){
fclose(fp); //存在的话,要先把之前打开的文件关掉
freopen("huffman.in", "r", stdin);
//freopen("huffman.out", "w", stdout);
}
readData();
create_ht();
doWPL( root, 1 );
printf("%d\n", WPL);
return 0;
}
最短距离


思路:
Dijkstra算法步骤:
- 定义一个dist距离数组 dist[起点] = 0 ,dist[其他点] 全部初始化为 INF
- 循环n-1次 每次找未使用的距离最近的点(和1号点的距离) 用该点去更新他能去的边的距离 即更新dist数组的值
由于我们要记录使用状态 需要一个额外数组记录使用状态 (做完才发现给了used数组 ==)
代码:
#include "stdio.h"
#include<iostream>
#include<algorithm>
#define maxint 10000
using namespace std;
int n,used[31],map[31][31];
bool st[31];
int dist[50]; // dist[n] = 起点到点 n 的最短距离
void ini( ){
int i,j;
scanf("%d", &n);
for( i=1; i<=n; i++){
for( j=1; j<=n; j++){
scanf("%d", &map[i][j]);
if( map[i][j] == 0 ){
map[i][j]=maxint;
}
}
}
}
void Dijkstra(){
//********************************************************
for(int i = 0;i < 50 ;i++){
dist[i] = maxint; //其他距离都初始化为理论上的无穷大
}
dist[1] = 0; //起点到起点的距离为0
int i,j;
for(i = 0;i < n - 1;i++){ //遍历 n-1次
int t = -1;
for(j = 1;j <= n;j++){
//每次找未使用的距离最近的点
if(!st[j] && (t == -1 || dist[t] > dist[j])){
t = j;
}
}
// 根据该点去更新他能去的边的距离
for(j = 1;j <= n;j++){
//如果是不可达到的点
//map[t][j] 为 maxint 便不会更新dist[j]的值
dist[j]=min(dist[j],dist[t] + map[t][j]);
}
//使用该点后记录状态为被使用
st[t] = true;
}
printf("%d",dist[n]); //根据dist数组的含义 直接输出dist[n]即可
//========================================================
}
int main(){
FILE *fp;
if((fp=fopen("dist.in", "r")) != NULL ){
fclose(fp); //存在的话,要先把之前打开的文件关掉
freopen("dist.in", "r", stdin);
//freopen("dist.out", "w", stdout);
}
ini();
Dijkstra();
return 0;
}
路径回溯

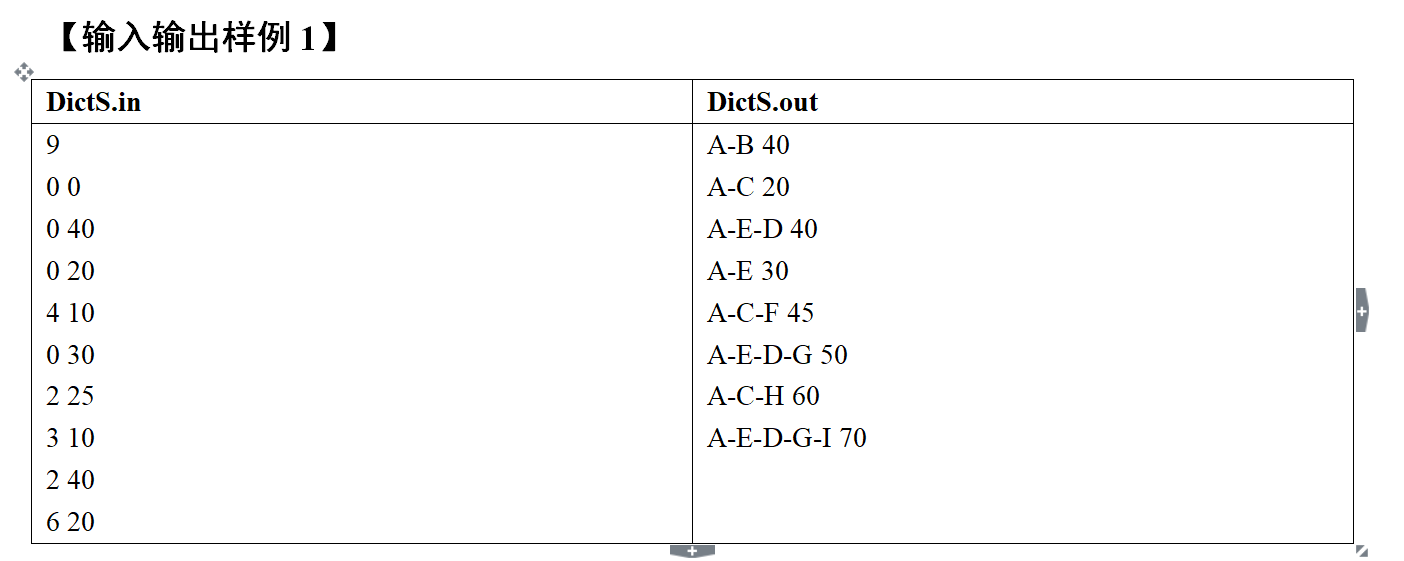
思路:
这种回溯问题 大部分都可以通过栈来保存 然后输出栈即可(做到了逆序输出)
代码:
#include "stdio.h"
#include <stack>
using namespace std;
int n, pre[26][2];
char station[26]={'A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'};
void ini(){
int i;
scanf("%d", &n);
for(i=0; i<n; i++){
scanf("%d%d", &pre[i][0], &pre[i][1]);
}
}
void Pathway(){
//********************************************************
stack<int>s; //定义一个栈
int i;
//由于题目A必是起点 所以直接从B开始循环 即 i = 1开始
for(i = 1;i < n;i++){
int distance = 0; //距离
int x = i;
while(x != 0){ //根据pre数组循环到起点A 并通过栈保存中间的路径
distance += pre[x][1];
s.push(x);
x = pre[x][0];
}
//输出路径 起点必是A 我们直接输出
printf("A");
while(!s.empty()){
int temp = s.top();
s.pop();
printf("-%c",station[temp]);
}
//路径输出完毕输出距离
printf(" %d\n",distance);
}
//========================================================
}
int main(){
FILE *fp;
if((fp=fopen("DictS.in", "r")) != NULL ){
fclose(fp); //存在的话,要先把之前打开的文件关掉
freopen("DictS.in", "r", stdin);
//freopen("DictS.out", "w", stdout);
}
ini();
Pathway();
return 0;
}
数据库查询

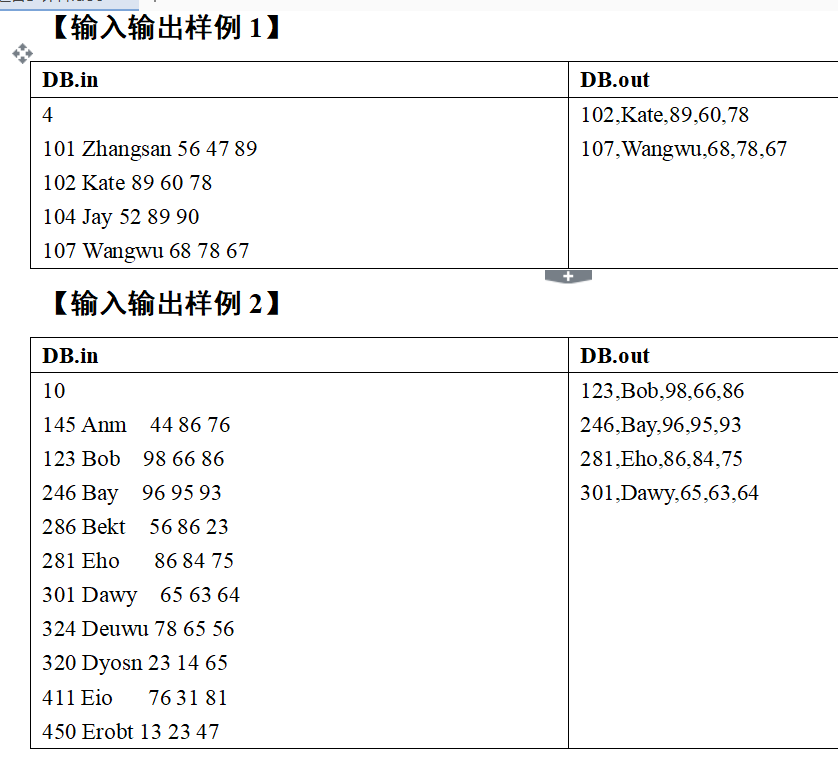
思路:
说白了就是结构体排序 直接为sort自定义排序规则即可实现
代码:
#include <stdio.h>
#include <stdlib.h>
#include <algorithm>
using namespace std;
#define SIZE 100
int n;
struct Grade_table{
int no_stu; /* the number of student*/
char name[20]; /* the name of student*/
int maths;
int english;
int computer;
};
struct Grade_table grade[SIZE];
//自定义排序规则
bool cmp(Grade_table &a,Grade_table &b){
//按照学号从小到大排序 即使用 <
return a.no_stu < b.no_stu;
}
void ini( ){
int i;
scanf("%d",&n);
for(i=0;i<n;i++){
scanf("%d %s %d %d %d",&(grade[i].no_stu),grade[i].name,&(grade[i].maths),&(grade[i].english),&(grade[i].computer));
}
}
void select2(){
//********************************************************
sort(grade,grade + n,cmp);
//遍历输出即可
int i;
for(i = 0;i < n;i++){
if(grade[i].computer >= 60 && grade[i].english >= 60 && grade[i].maths >= 60){
printf("%d,%s,%d,%d,%d\n",grade[i].no_stu,grade[i].name,grade[i].maths,grade[i].english,grade[i].computer);
}
}
//========================================================
}
int main(){
FILE *fp;
if((fp=fopen("DB.in", "r")) != NULL ){
fclose(fp); //存在的话,要先把之前打开的文件关掉
freopen("DB.in", "r", stdin);
//freopen("DB.out", "w", stdout);
}
ini();
select2();
return 0;
}
模拟进程调度算法

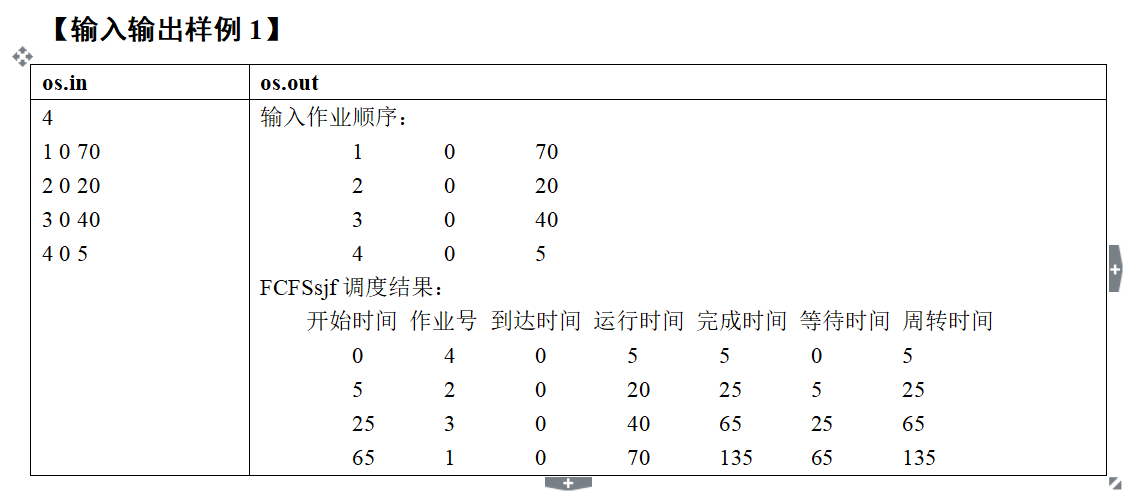
思路:
还是一题结构体排序问题 只是稍微复杂了点
根据题意我们优先根据进程到达时间从小到大排序
如果两者时间相同时根据运行时间从小到大排序
#include <stdio.h>
#include <stdlib.h>
#include <algorithm>
using namespace std;
struct Job_type{
int no; //作业号
int tb; //作业开始时间(分)
int tr; //运行时间(分)
}x;
Job_type job[36];
int n;
bool cmp(Job_type &a,Job_type &b){
if(a.tb != b.tb){ //如果时间不同就按照时间排序
return a.tb < b.tb;
}
else { //否则按照运行时间排序
return a.tr < b.tr;
}
}
void load(){
int i,j;
scanf("%d", &n);
for( i=0; i<n; i++){
scanf("%d", &job[i].no);
scanf("%d", &job[i].tb);
scanf("%d", &job[i].tr);
}
printf("输入作业顺序:\n");
for(i=0;i<n;i++){
printf("\t%d\t%d\t%d\n",job[i].no,job[i].tb,job[i].tr);
}
}
void fcfs_sjf(){
//********************************************************
sort(job,job + n,cmp); //直接进行一个序的排
//========================================================
printf("FCFSsjf调度结果:\n");
printf(" 开始时间 作业号 到达时间 运行时间 完成时间 等待时间 周转时间\n");
//********************************************************
//遍历输出即可
int i;
int time = 0; //记录当前时间
for(i = 0;i < n;i++){
Job_type t = job[i]; //节省代码量。
//周转时间 等于 完成时间 - 到达时间
printf("\t%d\t%d\t%d\t%d\t%d\t%d\t%d\n",time,t.no,t.tb,t.tr,time + t.tr,time - t.tb,time + t.tr - t.tb);
// 当前时间 加上该进程运行时间
time += t.tr;
}
//========================================================
}
int main(){
FILE *fp;
if((fp=fopen("os.in", "r")) != NULL ){
fclose(fp); //存在的话,要先把之前打开的文件关掉
freopen("os.in", "r", stdin);
//freopen("os.out", "w", stdout);
}
load();
fcfs_sjf();
return 0;
}
平均分

思路:
输入没有给数据长度 我们需要做循环读取操作
同时题目要求保留整数部分即可 所以不用做四舍五入的特殊操作
代码:
#include <stdio.h>
void average(){
//********************************************************
int i,j,k;
int len = 0; //记录长度
int sum = 0; //记录总和
int aver = 0; //平均值
while(scanf("%d",&i) != EOF){ //循环读取数据 直到文件末尾
sum += i;
if(i > 100 || i < 0){
aver = -1;
break;
}
len++;
}
if(aver != -1){
aver = sum / len;
}
printf("%d",aver);
//========================================================
}
int main(){
FILE *fp;
if((fp=fopen("average.in", "r")) != NULL ){
fclose(fp); //存在的话,要先把之前打开的文件关掉
freopen("average.in", "r", stdin);
//freopen("average.out", "w", stdout);
}
average();
return 0;
}
字典回溯


思路:
和上面那题回溯完全一致 用栈即可。。
#include "stdio.h"
#include <stack>
using namespace std;
struct dictionary{
int index;
char last_char;
}dict[36];
int n;
void ini(){
int i;
scanf("%d", &n);
for(i=0; i<n; i++){
scanf("%d %c", &dict[i].index, &dict[i].last_char);
}
}
void OutputWord(){
//********************************************************
stack<char> s; //定义一个栈
int i;
for(i = 0;i < n;i++){
int k = i;
while(k != -1){
s.push(dict[k].last_char);
k = dict[k].index;
}
while(!s.empty()){
char c = s.top();
s.pop();
printf("%c",c);
}
printf("\n");
}
//========================================================
}
int main(){
FILE *fp;
if((fp=fopen("DictS.in", "r")) != NULL ){
fclose(fp); //存在的话,要先把之前打开的文件关掉
freopen("DictS.in", "r", stdin);
freopen("DictS.out", "w", stdout);
}
ini();
OutputWord();
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号