机器学习基本概念
概念
机器学习
- 一个计算机程序在完成任务T之后,获得经验E,其表现效果为P,如果任何T的性能表现,即用以衡量的P,随着E的增加而增加,可以称其为机器学习。
- 根据已知的数据,学习出一个数学函数,使其能够具有更强的预测能力。
数据挖掘
应用机器学习技术来挖掘海量数据,帮助我们发现此前并非立见端倪的模式。
假设空间
由训练集的属性和属性值确定。 存在一个与训练集一致的“假设集合”,称之为“版本空间”。
归纳偏好
机器学习算法在学习过程中对某种类型假设的偏好,称为“归纳偏好”。
机器学习类型
根据训练期间接受的监督数量和类型分类
有监督学习
有训练集无标签,分类或回归任务
Logistic Regression、SVM、Neural Networks、k-Nearest Neighbors、Linear Regression、Decison Trees、Random Forest
无监督学习
有训练集无标签,聚类、聚类、降维、可视化、关联规则、时间序列分析
聚类算法、K-Means、Hierarchical Cluster Analysis、最大期望值算法、可视化和降维、主成分分析、核主成分分析、LLE、t-SNE、关联规则、Apriori
半监督学习
深度信念网路
强化学习
观察环境,执行操作并获得回报,或以负面回报的形式获得惩罚
根据系统是否可以从传入的数据流中进行增量学习分类
批量学习
无法增量学习,必须使用所有可用的数据进行训练
训练时间长,耗费大量计算资源
在线学习
适应不断变化的数据的速度
接收持续的数据流同时对数据流的变化快速自主的做出反应
输入不良数据,系统性能可能下降
根据如何泛化分类
基于实例的学习
example,系统先完全记住学习示例,后根据相似度度量方式将其泛化到新的实例
基于模型的学习
构建示例模型,然后使用该模型进行预测
如果模型对于训练集很少出错,但是泛化误差度高,说明过度拟合。
机器学习流程

- 特征提取:基于任务或先验去除无用特征
- 表示学习:通过深度模型学习高层语义特征,如何自动从数据中学习好的表示。
模型评价指标
对于分类问题,常见的评价标准有正确率、准确率、召回率和F值等。
- 均方根误差 Root Mean Square Error(RMSE)
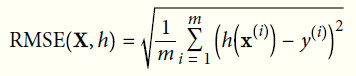
- RMSE通常是回归任务的首选性能指标。
- 均方误差(MSE)
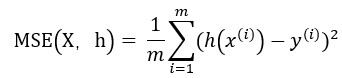
- 平均绝对误差 Mean Absolute Error(MAE)
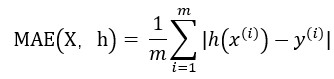
- 与MAE相比,RMSE对异常值更敏感。
机器学习中较活跃的四大应用领域
数据挖掘
发现数据之间的关系
案例:血糖值预测、有无糖尿病预测
计算机视觉
像人一样看懂世界
案例:
| 输入 | 模型 | 输出 | |
| 图像分类 | 原始图像 | 机器学习模型 | 类别 |
| 目标检测 | 原始图像 | 机器学习模型 | label |
| 语义分割 | 原始图像 | 机器学习模型 | label |
自然语言处理
像人一样看懂文字
案例:
| 输入 | 模型 | 输出 | |
| 文本分类 | 一篇新闻 | 机器学习模型 | 类别 |
| 自动生成文本摘要 | 一篇文章 | 机器学习模型 | 摘要 |
| 翻译 | 一句英文 | 机器学习模型 | 一句中文 |
| 问答 | query+text | 机器学习模型 | 答案 |
| 人机对话 | 一句话 | 机器学习模型 | 一句话 |
| image to text | image | 机器学习模型 | text |
机器人决策
像人一样具有决策能力
案例:
- End to End级自动驾驶

- 玩赛车游戏

- 机器人开门


 浙公网安备 33010602011771号
浙公网安备 33010602011771号