花三年时间整理出的向量数据库最佳实践
AI 时代,各种 AI Infra 都离不开向量数据的存储、检索。而做向量场景的 PoC,每次都要重新算一遍内存、选一遍索引、调一遍参数……
OceanBase 有两位不愿意透露姓名的大佬——序风、舸灏,在最近三年支持了无数 AI 场景的向量数据库 PoC(Proof of Concept)工作,有着究极丰富的向量数据库运维和调优经验。
这篇文章,是他们第一次把压箱底的向量数据库运维经验总结拿出来,在社区公众号为大家进行分享。文中包含了使用向量数据库时,需要考虑的方方面面。希望大家在阅读之后,都能把向量数据库用得更加顺畅~

欢迎大家关注 OceanBase 社区公众号 “老纪的技术唠嗑局”。在这里,我们会持续为大家更新与 #AI 和 #Data 相关的技术内容~
本文涵盖了:向量索引选型、内存与 CPU 规划、磁盘空间估算、分区设计、索引参数配置、混合查询调优、性能验证方法与实测数据、常见性能问题排查等等。
适用于向量数据库 PoC 评估、向量索引类型选择、租户资源规划和查询性能调优。
本文的前置阅读材料是《浅入了解向量数据库》。这篇前置文章没有阅读门槛,浅显易懂,适合大家对 AI 时代永远离不开的向量数据库进行一个“浅入了解”。
上篇:向量构建设计实践
【选型与规划】 这一部分会讲清楚:什么场景选什么索引、内存 CPU 磁盘怎么算、表怎么建、参数怎么配。读完你能独立完成一次向量 PoC 的资源规划。
1. 索引选型
开篇就给结论:选型不靠经验,靠两条数据——数据规模和内存预算。
快速决策树如下:
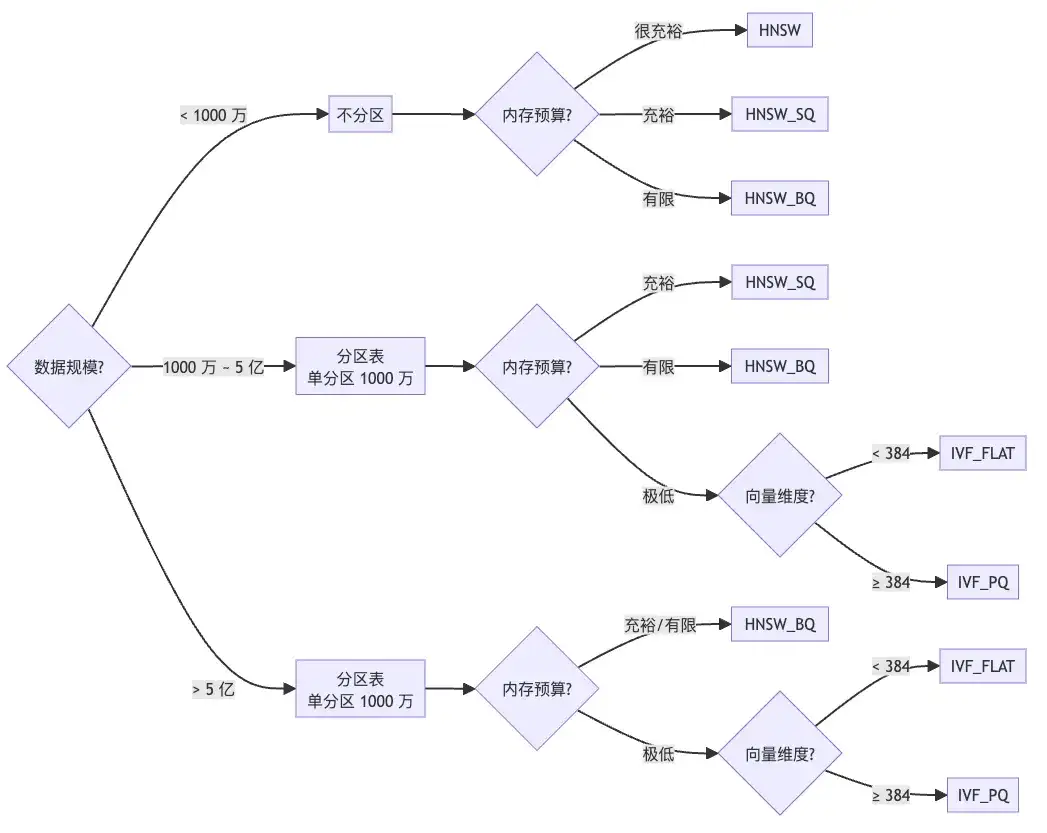
内存预算可以根据后文中的“资源规划”部分的估算方法确认。
上图的决策逻辑简述:数据规模 < 1000 万不分区,1000 万 ~ 5 亿和 > 5 亿均做分区(单分区 1000 万)。< 5 亿且内存充裕选 HNSW 或 HNSW_SQ,内存有限选 HNSW_BQ;> 5 亿统一选 HNSW_BQ。内存极低时按维度选 IVF——维度 < 384 选 IVF_FLAT,≥ 384 选 IVF_PQ。
注意:
- 如果需要接近 100% 召回,可以使用 HNSW —— 但是在大规模数据下的内存成本会比较高,基本无法承受,退而求其次可选 HNSW_SQ 和 HNSW_BQ。
- HNSW_BQ 要求维度 ≥ 384, IVF_PQ 要求维度 ≥ 128, 达不到这个维度要求,也不是完全不能用这两个索引,但有可能召回率比预期低,和用户数据特征强相关。
- 单分区 1000 万向量并不是强制要求,这个大小是出于维护性和性能的折衷考虑,通常来说,同样数据量下,分区越少性能越好,但是单分区向量越多,为了达到同样的召回率,需要的构建参数会越大,且分区级重建的时间就越长,通常建议大数据量下单分区控制在 500 万~2000 万向量,特别注意,单个分区的向量数不能超过 5000 万。
| 案例场景 | 推荐方案 | 详细章节 |
|---|---|---|
| 384 维,亿级,geohash 过滤 | HNSW_SQ 或 HNSW_BQ,按 geohash 分区 | 第 4 章(分区设计)、第 6 章(混合查询) |
| 1024 维,十亿级,多维过滤 | HNSW_BQ,skill_id 一级分区,doc_id 二级分区 | 第 4 章(二级分区) |
| 768 维,千万~亿级 | HNSW_SQ 或 HNSW_BQ | 第 1 章(索引选型) |
| 任意维度,十亿级,只增不删 | IVF_PQ | 第 1 章(IVF 选型)、第 2 章(容量规划) |
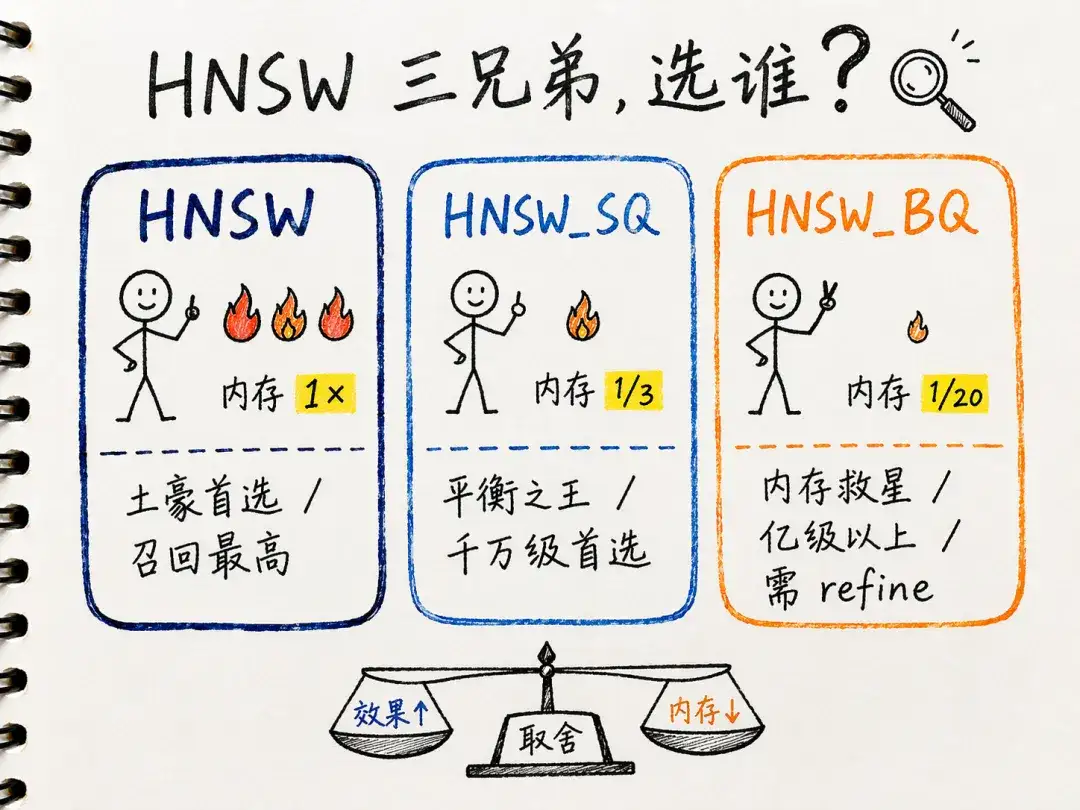
1.1. HNSW 系列
HNSW 系列索引是内存索引,查询时需要长驻内存,注意它不是缓存,无法像 KV Cache 那样临时换出。在重建时会有一段时间内存中存在新旧两份索引。
| 类型 | 内存(相对 HNSW) | 召回率 | 查询性能 | 适用场景 |
|---|---|---|---|---|
| HNSW_SQ | 1/4 ~ 1/3 | 略低于 HNSW | 最高 | 千万级首选,性能和内存的平衡点 |
| HNSW_BQ | 1/20 | 低于 SQ,需 refine 补偿 | 中高 | 亿级以上,内存有限时的唯一选择 |
如果内存成本足够,HNSW_SQ 是大多数场景下的最佳选择。 HNSW_BQ 的极致量化(RapidQ)让索引本身极小,但查询时需要从磁盘捞原始向量做重排,因此磁盘性能对其性能有一定影响,TopK 越大影响越明显。
可通过降低 refine_k 减少磁盘读取量(见 6.4 节),磁盘性能对 BQ 查询的影响详见 2.3.2 节。
1.2. IVF 系列
IVF 索引常驻磁盘,内存占用极低,适合内存预算极度有限的场景。
| 类型 | 查询性能 | 构建速度 | 召回率 | 适用场景 |
|---|---|---|---|---|
| IVF_FLAT | 较慢 | 快 | 高 | 内存紧张但维度不高(<384),低维度下原始向量本身不大,磁盘读取代价可控 |
| IVF_PQ | 比 FLAT 快 | 慢 | 略低 | 维度高(≥384)、内存极度紧张、可接受周期性重建 |
如果大家要拿多种不同的向量数据库对比性能,则一定要注意区分索引类型:比如 OceanBase 的 HNSW / HNSW_SQ / HNSW_BQ 是内存索引,OceanBase 的 IVF 系列是磁盘索引(disk-based index)。磁盘索引的 RT 通常比内存索引高数倍,这点各家是都一样的。
千万要注意的是:不能单纯按照索引名称对比性能,而要按照实际的 内存 / 磁盘 索引类型来对比。
例如:OceanBase 的 IVF 系列是磁盘索引(disk-based index),应对标 Milvus 的 DiskANN 等磁盘索引。
再例如:OceanBase 的 HNSW_SQ / HNSW_BQ 是内存索引,应对标 Milvus 的 IVF 索引。
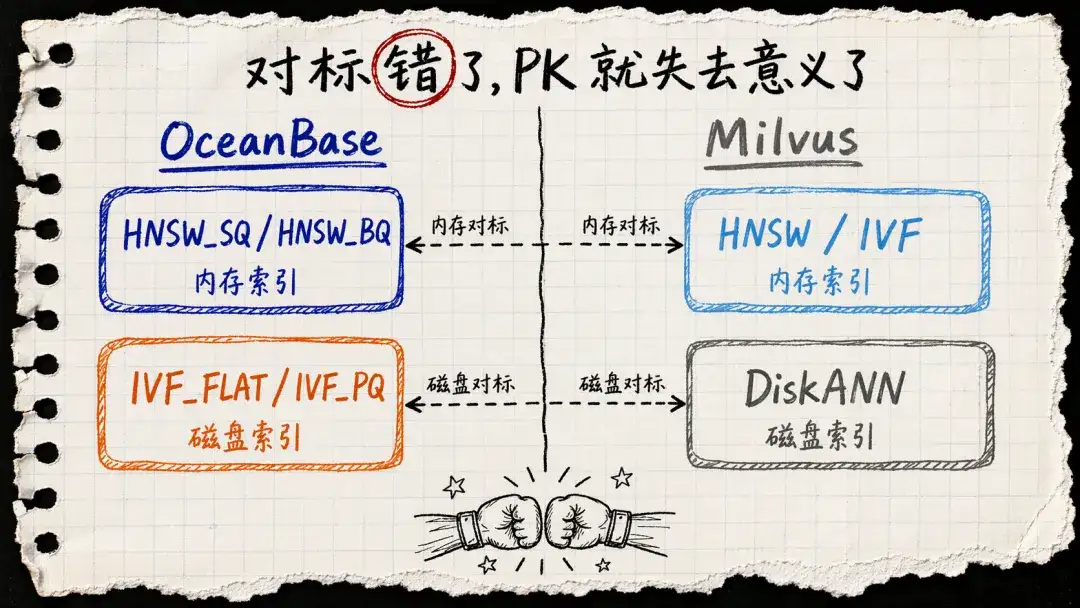
为了尽量不偏离主题,这里就不再放诸如“在同等成本下,OceanBase IVF 磁盘索引性能优于 Milvus DiskANN”之类的性能对比数据和结论了~
总之:不同的向量数据库之间进行性能对比测试,不能只看索引名字,还要看索引类型。对标错了,PK 结果就没意义。
注意:
- IVF 系列索引,在 OceanBase 4.6.0 版本以前都不支持堆表的分区表。
- IVF_PQ 使用 l2 距离时需额外缓存预计算结果,构建时使用的内存远超 cosine / inner_product,大规模场景优先用 cosine 距离。
- IVF 系列索引,随表创建索引后写入数据,相当于暴力搜索,完全没有向量索引的性能优势,这是因为这种场景下没有机会给索引计算聚类中心,要在写完数据后重建 IVF 索引。(从 OceanBase 4.6.0 版本开始,已禁止随表创建 IVF 索引)
2. 资源规划
PoC 报方案前最怕被反问“内存够不够、机器买几台”——这一章给你一个最直观的算法,包含内存、CPU、磁盘三个维度。
2.1. 内存估算与规划
2.1.1. 估算方法与速查
OceanBase 自带了向量索引内存估算函数 dbms_vector.index_vector_memory_advisor,可根据索引类型、数据规模和参数计算所需向量内存(vector memory):
-- 1 亿条 384 维向量,单分区最多 1000 万条
SELECT dbms_vector.index_vector_memory_advisor(
'HNSW_BQ', 100000000, 384, 'FLOAT32',
'M=32, TYPE=HNSW_BQ, ef_construction=400, distance=cosine, refine_type=SQ8',
10000000
);
参数依次是:索引类型、总数据量、维度、数据类型、索引参数(同创建索引的参数)、单分区最大行数。 注意最后一个参数,它是预估最大分区的向量数量,在分区表场景下如果不填,函数按全量数据估算单分区,算出来的内存值是明显偏大的。
速查参考:下表是不同维度向量,不同数据规模的估算结果。估算按照单分区 1000 万行向量,租户内存的 50% 可用于向量索引(默认配置),构建采用 64 并发。
1024 维(最常见,text-embedding-3-large、bge-large 等):
| 数据规模 | 推荐索引 | 分区 | 向量内存(单副本) |
|---|---|---|---|
| 100 万 | HNSW_SQ | 不分区 | 2.7 GB |
| 500 万 | HNSW_SQ | 不分区 | 14.2 GB |
| 1000 万 | HNSW_SQ | 不分区 | 28.4 GB |
| 3000 万 | HNSW_BQ | 3 分区 | 构建需要 34.4 GB,运行时 17.2 GB |
| 5000 万 | HNSW_BQ | 5 分区 | 构建需要 45.9 GB,运行时 28.7 GB |
| 1 亿 | HNSW_BQ | 10 分区 | 构建需要 74.6 GB,运行时 57.4 GB |
| 4.5 亿 | HNSW_BQ | 45 分区 | 构建需要 275.5 GB,运行时 258.3 GB |
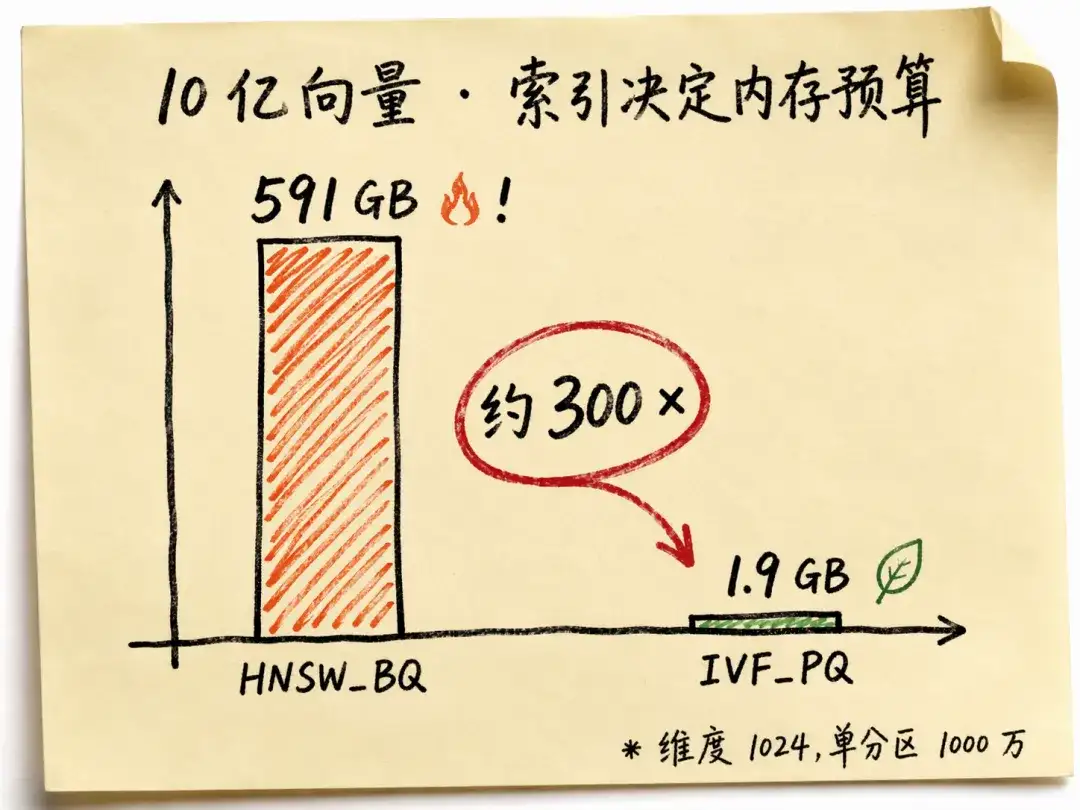
| 10 亿 | HNSW_BQ | 100 分区 | 构建需要 591.2 GB,运行时 574.0 GB |
| 10 亿 | IVF_PQ | 100 分区 | 构建需要 6.3 GB,运行时 1.9 GB |
768 维(text-embedding-3-small、bge-base 等):
| 数据规模 | 推荐索引 | 分区 | 向量内存(单副本) |
|---|---|---|---|
| 1000 万 | HNSW_SQ | 不分区 | 22.6 GB |
| 1 亿 | HNSW_BQ | 10 分区 | 构建需要 67.8 GB,运行时 53.8 GB |
| 4.5 亿 | HNSW_BQ | 45 分区 | 构建需要 256.2 GB,运行时 242.2 GB |
| 10 亿 | HNSW_BQ | 100 分区 | 构建需要 552.2 GB,运行时 538.2 GB |
| 10 亿 | IVF_PQ | 100 分区 | 构建需要 4.8 GB,运行时 1.4 GB |
同样是 10 亿向量、单分区 1000 万:HNSW_BQ 构建峰值 591.2 GB,IVF_PQ 运行时 1.9 GB——内存差距约 300 倍。 这就是为什么内存预算决定了索引选型。
注意:
- 向量内存估算函数计算的是单副本下的内存用量。租户内存 = 向量内存 ÷ ob_vector_memory_limit_percentage(默认 50%,即 ×2)。该参数不建议超过 60%,否则内存稍高的场景容易触发限流。
- 表内值为单副本向量内存。每个副本独立加载索引,3 副本部署时总向量内存需要 × 3。
- BQ 的构建需要含 SQ 构建缓存,索引完成后释放,降到运行时水平。规划租户按构建需要来。
- IVF_PQ 内存极低,但查询延迟比 BQ 高一个量级。选它是因为内存实在不够,不是因为它快。
2.1.2. HNSW 内存详解
HNSW 构建时的内存和运行时的内存不一样,特别是 BQ,差别很大。以千万级 768 维为例:
| 索引类型 | 构建时内存 | 运行时常驻 | 说明 |
|---|---|---|---|
| HNSW | 76.3 GB | 76.3 GB | 全量常驻,不释放 |
| HNSW_SQ | 22.6 GB | 22.6 GB | 量化后常驻,约 HNSW 的 1/3 |
| HNSW_BQ | 22.6 GB | 5.4 GB | 构建时需要 SQ 缓存,完成后只剩 BQ 索引 |
多节点集群:12 亿 1024 维 HNSW_BQ,构建时单副本峰值内存约 1716 GB(BQ 构建依赖 SQ 缓存,峰值与 HNSW_SQ 相当;构建完成后运行时降至约 689 GB)。按构建峰值规划:3 副本时租户内存需要 (1716 × 3) ÷ 0.5 ≈ 10296 GB。单机 768 GB 的话,单 Zone 要 14 台,3 Zone 共 42 台。
注意: 以上为单分区独立构建时的峰值内存。 分区表场景下,系统按分区依次构建,内存使用峰值 ≈ 构建中的分区构建内存 + 已完成分区的运行时内存。所以总体 HNSW_BQ 相比 HNSW_SQ 还是有内存成本优势的。
2.1.3. IVF 内存详解
IVF 索引常驻磁盘,常驻内存几乎可以忽略。以千万级 768 维为例:
| 索引类型 | 索引参数 | 构建时内存 | 运行时常驻 |
|---|---|---|---|
| IVF_FLAT | nlist=3000 | 3.4 GB | 13.2 MB |
| IVF_PQ (cosine) | nlist=3000, m=384 | 3.4 GB | 14.3 MB |
| IVF_PQ (l2) | nlist=3000, m=384 | 5.0 GB | 1.7 GB |
l2 距离下 IVF_PQ 的常驻内存是 cosine 的 120 倍——因为 l2 要额外缓存预计算结果。
2.2. CPU 与 NUMA 对向量查询的影响
相比普通 SQL 查询对 CPU 的消耗,向量搜索的瓶颈主要在 内存带宽,以及 CPU 支持的 SIMD 指令集,当然 CPU 主频也有一定的影响。
所以核数不是越多越好:特别是 64 核以后,每核分到的内存带宽减少、L3 cache 抢得厉害,继续增加核数,在实际测试中已经不会有收益,甚至可能因为跨 NUMA 访问导致查询性能的劣化。
Intel cpu 代际差异:8 代表现最好,9 代稍差,7 代差距就比较大。(不同厂商 BIOS 和散热方案不一样,仅供参考)
核数不是越多越好。 向量搜索的瓶颈是内存带宽和 SIMD 指令,超过 64 核之后,跨 NUMA 访问和 L3 cache 争抢会让性能不升反降。
2.3. 磁盘空间与查询性能
2.3.1. 空间估算
以下是向量索引占用磁盘空间的粗略值,不包括主表和其他索引。注意:索引里面和主表里面现在都存储了向量,但是索引表上的向量是量化过的。
| 索引类型 | 磁盘估算 |
|---|---|
| HNSW | 约等于原始向量大小 * 1.2 |
| HNSW_SQ | 约等于原始向量大小 * 1.2 / 3 |
| HNSW_BQ | 约等于原始向量大小 * 1.2 / 20 |
| IVF_FLAT | 约等于原始向量大小 |
| IVF_PQ | 约等于原始向量大小 / 8 |
原始向量大小计算公式:行数 × 维度 × 4 字节,例如 1 亿 384 维 float32 = 144 GB。
2.3.2. 对查询的影响
当 KVCache 不足以放下表上所有数据时,磁盘性能会对查询性能产生影响。
- IVF 系列:查询时要从磁盘读取向量,做距离计算,磁盘性能直接影响查询性能。
- HNSW_BQ:refine 阶段也要从磁盘把原始向量捞回来重算距离。TopK 越大,要 refine 的候选越多,磁盘性能直接影响查询性能。
- HNSW_SQ:索引查询都在内存里完成,但需要回表取标量列,数据量只跟 LIMIT 和投影行长有关。大部分情况下查 Top100 几乎无感,查 Top1000 可能会有感知,总体来说受影响小。
总的来说,几种索引算法受磁盘性能影响的程度:HNSW_SQ < HNSW_BQ < IVF/IVF_PQ。
3. 重要配置项说明
3 个参数,调与不调差距可能是 QPS 翻倍。复制粘贴前请先看每一项的解释。
以下是大规模向量场景最常调整的参数及推荐值:
-- 1. 并行构建采样精度(千万级 5000,亿级 10000,十亿级以上 100000)
ALTER SYSTEM SET _px_object_sampling = 10000;
-- 2. 向量索引内存占比(默认自适应 50%,内存不够可手动调高到 60%)
ALTER SYSTEM SET ob_vector_memory_limit_percentage = 50;
-- 以下参数在跑 vectordbench 时不需要修改,实测时可能会用到
-- 3. 查询策略(4.6.0 起默认 LATENCY_FIRST,老版本默认 RECALL_FIRST)
ALTER SYSTEM SET ob_vector_search_strategy = 'LATENCY_FIRST';
每个参数为什么调整:
- _px_object_sampling:默认采样太低,并行构建时各线程分到的数据量不匀。调大后负载更均匀,构建更快。
- ob_vector_memory_limit_percentage:默认自适应在租户 > 8GB 时最多给向量索引 50%。内存不够时手动调高,注意不能超过 60%。
- ob_vector_search_strategy:LATENCY_FIRST 优先快速返回,RT 相对稳定;RECALL_FIRST 优先保证召回,部分查询可能明显变慢。
4. 表结构与分区设计
表怎么建、分不分区、分多少区——这一章答完三个问题。
4.1. 分区设计
同时满足以下两条,建议分区:
- 数据量千万级以上
- 查询条件里有明确的标量列能用来裁剪分区(geohash、category_id、skill_id 之类)
这两条同时成立,分区效果最好。如果数据量大但没有适合裁剪的列,用主键做 hash or key 分区也可以。
目标单分区:500 万 ~ 2000 万行。
上限:单分区超过 2000 万后索引构建变慢、标量查询遇到 bad case 的概率更高。另外当前版本单个分区不能超过 5000 万向量。
下限:单分区太小了也不行。50 万和 100 万向量的 HNSW 索引,查询开销几乎相同,但小分区的结果汇总 rerank 会把延迟拖上去。 理论上看,P 个分区的搜索复杂度是 P × log(N/P),远大于单图的 log(N)——每个分区独立搜索后再汇总,对数级问题变成了线性叠加。
结论:在满足 500-2000 万的前提下,分区越少越好。
分区数速查:
| 总数据量 | 分区数 | 单分区量 |
|---|---|---|
| 5000 万 | 5-10 | 500-1000 万 |
| 1 亿 | 10-20 | 500-1000 万 |
| 4.5 亿 | 25-45 | 1000-1800 万 |
| 7.5 亿 | 45-75 | 1000-1700 万 |
| 10 亿 | 50-100 | 1000-2000 万 |
数据倾斜:按最大分区的预估量来选索引参数和内存。比如 4.5 亿 45 分区,如果最大分区有 2000 万而其他只有 500 万,参数按 2000 万定。可以适当增加分区数削峰,但尽量遵守上文分区越少越好。
4.2. 建表示例
一级分区(384 维,亿级,按 geohash 过滤):
CREATE TABLE htl_image_recall (
id bigint(20) NOT NULL AUTO_INCREMENT,
hotelid int(11) DEFAULT NULL,
geohash varchar(100) NOT NULL,
picturename varchar(500) DEFAULT NULL,
picturevector VECTOR(384) DEFAULT NULL,
auditpicturetypeid int(11) DEFAULT NULL,
PRIMARY KEY (id, geohash),
KEY idx_hotelId (hotelid) BLOCK_SIZE 16384 LOCAL,
KEY idx_geohash (geohash) BLOCK_SIZE 16384 LOCAL
) ORGANIZATION HEAP ROW_FORMAT = COMPRESSED
partition by key(geohash) partitions 45;
二级分区(两个维度过滤,如 skill_id + doc_id):
CREATE TABLE iop_knowledge (
_id varchar(200),
doc_id varchar(100),
skill_id varchar(100),
search_vec vector(1024),
UNIQUE KEY idx_id (_id, skill_id, doc_id) LOCAL
) ORGANIZATION HEAP
partition by key(skill_id) partitions 30
subpartition by key(doc_id) subpartitions 4;
- 每个二级分区都是独立的向量索引。
- 每个二级分区数据量同样控制在 500 万 ~ 2000 万。
- 分区键尽量短 —— 多个 varchar(4000) 作为主键和分区键 可能导致创建索引报“Specified key was too long”。
4.3. “稀疏”的向量列
一张表有多个向量列,某列只有少部分行有值,如果条件允许,把非空行拆到独立小表。虽然向量索引只索引非空值,但大表的分区扫描开销照样很高。
实测:主表 9 亿行,768 维列仅 2600 万行有值。大表上查 RT 21ms,拆到小表后降到 3ms 以内。 9 亿行的主表查 21ms,拆出非空 2600 万行到独立小表后降到 3ms——延迟下降 7 倍。 向量列稀疏时,大表分区扫描的隐藏开销远比想象高。
5. 索引创建与参数配置
这一章是参数手册:HNSW 系列、IVF 系列的每个参数含义、推荐值、常见误用。建议收藏。
OceanBase 做了同步索引,写入立即可见,代价是 DML 过程中需要维护增量索引。需要较高写入 QPS 时,建议用分区表分摊压力。
因此强烈建议全量数据导入后再创建索引,不要先建再导,特别是当同时创建了全文,向量,json 索引后再导入数据,会慢。
5.1. 创建索引
并行度设租户 CPU 的 2 倍。32c 租户设 64。举例:
-- HNSW_BQ
CREATE/*+ PARALLEL(64) */ VECTOR INDEX idx_vec
ON htl_image_recall(picturevector)
WITH (distance=cosine, type=hnsw_bq, m=32, ef_construction=400);
-- HNSW_SQ
CREATE/*+ PARALLEL(64) */ VECTOR INDEX idx_vec
ON htl_image_recall(picturevector)
WITH (distance=cosine, type=hnsw_sq, m=32, ef_construction=400);
-- IVF_PQ
CREATE/*+ PARALLEL(64) */ VECTOR INDEX idx_vec
ON htl_image_recall(picturevector)
WITH (distance=cosine, type=ivf_pq, lib=OB, m=192, nlist=3000, nbits=8,
sample_per_nlist=256) BLOCK_SIZE=1048576;
5.2. 两个容易混淆的参数
- IVF_PQ 的 m 是量化后的向量维度(取原始维度的 1/2),和 HNSW 的 m(邻居数)是两个完全不同的东西。
- HNSW_BQ 的 ef_construction 不能沿用在 HNSW 或 ES 里常见的 160 —— BQ 量化有精度损失,需要更大的候选集来补偿。千万级分区设 300-400,追求极高召回设 800 + m=64 + refine_k=20。
5.3. HNSW 系列参数
| 参数 | 默认值 | 范围 | 作用 |
|---|---|---|---|
| distance | 必填 | l2 / cosine / inner_product | 多数 embedding 用 cosine |
| type | 必填 | hnsw / hnsw_sq / hnsw_bq | — |
| m | 16 | [5, 64] | 每节点最大邻居数,越大召回越高但内存和构建时间也越大 |
| ef_construction | 200 | [5, 1000] | 构建时候选集大小,必须 > m。越大索引质量越好,构建越慢 |
| ef_search | 64 | [1, 16000] | 查询时候选集大小,运行时也可调 |
| refine_k | 4.0 | [1.0, 1000.0] | 仅 BQ。重排比例,越大召回越高延迟也越大 |
| refine_type | sq8 | sq8 / fp32 | 仅 BQ。sq8 省内存,fp32 召回略高 |
5.4. IVF 系列参数
| 参数 | 默认值 | 范围 | 作用 |
|---|---|---|---|
| nlist | 128 | [1, 65536] | 聚类中心数,取 sqrt(单分区数据量) |
| nprobes | 8 | 运行时设置 | 查询时探测的聚类数,越大召回越高 |
| m(IVF_PQ) | 必填 | [1, 65536] | 量化后维度,取 dim/2 |
| nbits | 8 | [1, 24] | 量化位数,8-10 为宜 |
| sample_per_nlist | 256 | [1, max] | 每个聚类中心的采样数,默认一般够用 |
5.5. 按规模的参数推荐
百万级:
| 索引类型 | 构建参数 | 查询参数(Top100,目标召回 ≥0.95) |
|---|---|---|
| HNSW_SQ | m=16, ef_construction=200 | ef_search=240 |
| HNSW_BQ | m=16, ef_construction=200 | ef_search=240, refine_k=4 |
| IVF_PQ | nlist=1000, m=dim/2, nbits=8 | nprobes=20 |
千万级:
| 索引类型 | 构建参数 | 查询参数(Top100,目标召回 ≥0.95) |
|---|---|---|
| HNSW_SQ | m=32, ef_construction=400 | ef_search=350 |
| HNSW_BQ | m=32, ef_construction=400 | ef_search=1000, refine_k=10 |
| IVF_PQ | nlist=3000, m=dim/2, nbits=8 | nprobes=20 |
亿级(分区表):参数按单分区最大数据量来定——单分区 ≤1000 万参照百万级,1000-2000 万参照千万级。
5.6. 增量与重建
索引创建后增量写入的向量立即可查,但增量部分不做量化压缩,会额外占内存。HNSW 系列增量达 20% 时自动触发后台重建,IVF 新增超 30% 后需手动 CALL dbms_vector.rebuild_index()。重建耗时与初次构建接近。
中篇:向量查询调优实践
【查询与验证】 怎么写查询、混合检索怎么调、性能怎么测、出问题怎么排查。这一部分对 PoC 实测和上线后的运维都有用。
6. 查询与调优
查询语句怎么写、Hint 怎么用、召回和延迟的旋钮怎么拧——这一章决定了你的 QPS 报告好不好看。
6.1. 基础查询
不带标量过滤的向量近似查询(approximate nearest neighbor search)写法:
SELECT id, cosine_distance(embedding, @query_vector) AS distance
FROM htl_image_recall
ORDER BY distance APPROXIMATE
LIMIT 100;
APPROXIMATE 必须写(简写 APPROX 也行)。不写就走全表精确计算,不会用向量索引。
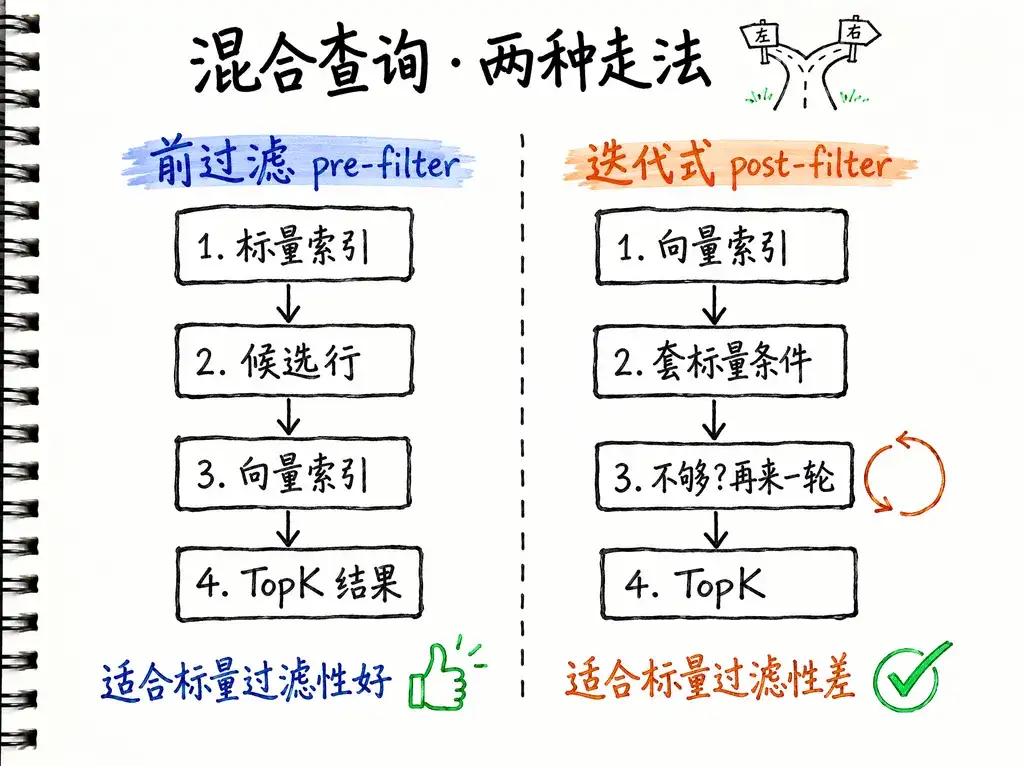
6.2. 混合查询
带标量过滤条件的向量近似查询称为混合查询(hybrid search),以下是 geohash 过滤 + 向量检索的写法:
SELECT id, picturename, cosine_distance(picturevector, @query_vector) AS distance
FROM htl_image_recall
WHERE geohash IN ('gcq2j', 'u10kk', 'wvkut')
ORDER BY distance APPROXIMATE
LIMIT 100;
OceanBase 4.3.5 起混合检索会自动选算法:标量过滤性好就走前过滤(pre-filter,先用标量索引筛,再向量搜),过滤性差就走迭代式过滤(post-filter,向量搜的过程中逐步套标量条件)。在过滤字段上最好都建好索引。
6.3. Hint 控制策略
知道过滤特征的话,用 hint 指定比依赖自适应更稳。4.6.0 起推荐使用 VECTOR_INDEX hint,可同时指定向量索引和过滤路径:
-- 4.6.0+ 推荐写法:指定向量索引 + 前过滤(pre-filter),并指定标量索引
SELECT /*+ VECTOR_INDEX(t idx_vec PRE_FILTER) index(t idx_geohash) */ id,
cosine_distance(picturevector, @query_vector) AS distance
FROM htl_image_recall t
WHERE geohash IN ('gcq2j', 'u10kk')
ORDERBY distance APPROXIMATE LIMIT 100;
-- 4.6.0+ 推荐写法:指定向量索引 + 迭代式过滤(post-filter)
SELECT /*+ VECTOR_INDEX(t idx_vec POST_FILTER) */ id,
cosine_distance(picturevector, @query_vector) AS distance
FROM htl_image_recall t
WHERE geohash IN ('gcq2j', 'u10kk')
ORDERBY distance APPROXIMATE LIMIT 100;
旧版本(4.6.0 以前)用 index() hint 也能控制:指定标量索引名走前过滤,指定向量索引名走迭代式过滤。
6.4. 召回与延迟的权衡
ef_search(HNSW 系列)和 nprobes(IVF)是核心旋钮。
HNSW 系列(768 维,千万级,目标 Recall ≈ 0.95):
| Top-K | ef_search |
|---|---|
| Top10 | 100 |
| Top100(HNSW_SQ) | 350 |
| Top100(HNSW_BQ) | 1000, refine_k=10 |
IVF 单分区(千万级,目标 Recall ≈ 0.90):
| Top-K | nprobes |
|---|---|
| Top10 | 1 |
| Top100 | 20 |
| Top1000 | 90 |
IVF 分区表(亿级)——各分区独立查询后汇总 rerank,实际召回高于单分区,可以用更低的 nprobes:
| Top-K | nprobes |
|---|---|
| Top10 | 1 |
| Top100 | 10 |
| Top1000 | 45 |
总的来说,ef_search 和 nprobes,可以用性能换取召回,或者反过来。但如果将这两个参数调到很大都无法满足召回,或者性能太差,可以再调整索引构建参数重建索引,用构建性能换取查询性能。
6.5. 用 EXPLAIN 检查向量索引、分区裁剪与过滤策略
EXPLAIN 可以看出:走了向量索引没有(不是全表扫)、分区裁剪生效没有(partitions 字段应只含少量分区)、混合查询用了什么算法(前过滤还是迭代式过滤)。
EXPLAIN EXTENDED SELECT id,
cosine_distance(picturevector, @query_vector) AS distance
FROM htl_image_recall
WHERE geohash = 'gcq2j'
ORDER BY distance APPROXIMATE LIMIT 100;
7. 性能验证
怎么测才不踩坑——压测姿势不对,得出的结论会误导决策。
7.1. 测试方法
四个核心指标:QPS、平均 RT、P95/P99 RT、召回率。

召回率测试:准备 100 个以上查询向量,分别跑精确搜索和近似搜索,对比结果:
-- 精确搜索(ground truth)
SELECT /*+ PARALLEL(32) */ id,
cosine_distance(picturevector, @query_vector) AS distance
FROM htl_image_recall
WHERE geohash IN ('gcq2j', 'u10kk')
ORDERBY distance LIMIT 100;
-- 近似搜索
SELECT id,
cosine_distance(picturevector, @query_vector) AS distance
FROM htl_image_recall
WHERE geohash IN ('gcq2j', 'u10kk')
ORDERBY distance APPROXIMATE LIMIT 100;
注意:压测时最好进行合并(major freeze)和预热,减小回表和读盘对查询性能的影响。
7.2. 实测性能参考
百万级 768 维(m=16, ef_construction=200, Top100, ef_search=240):
| 索引类型 | QPS | 召回率 | 内存 |
|---|---|---|---|
| HNSW | 3475 | 0.9499 | 7.3 GB |
| HNSW_SQ | 5599 | 0.9468 | 2.1 GB |
| HNSW_BQ (refine_k=4) | 3113 | 0.9278 | 0.4 GB |
千万级 768 维(m=32, ef_construction=400, Top100):
| 索引类型 | QPS | 召回率 | ef_search |
|---|---|---|---|
| HNSW | 2637 | 0.9574 | 350 |
| HNSW_BQ (refine_k=10) | 857 | 0.9531 | 1000 |
4.5 亿 384 维混合查询(HNSW_SQ, m=32, 45 分区,20 并发):
| geohash 过滤个数 | QPS | 平均 RT |
|---|---|---|
| 10 | 810 | 24ms |
| 20 | 717 | 28ms |
| 40 | 488 | 40ms |
8. 向量查询性能问题排查手册
出问题时不要乱调参数,按这张表的“现象 → 原因 → 动作”走,90% 的问题能在 10 分钟内定位。
以下是大规模向量场景最常见的性能问题及排查方法

| 现象 | 最可能的原因 | 动作 |
|---|---|---|
| 延迟秒级 | 没做分区裁剪 | EXPLAIN 看 partitions 字段 |
| 延迟秒级 | 没加 APPROXIMATE | EXPLAIN 确认是否走了向量索引 |
| P99 >> P50 | 部分分区索引没加载到内存 | 查 GV$OB_VECTOR_MEMORY |
| RT 偏高 | 向量列大量 NULL,大表扫描开销 | 拆非空行到小表,实测 RT 从 21ms 降至 3ms(见 4.3) |
| 召回低 | ef_search / nprobes 太小 | 逐步调大 ef_search 或 nprobes(见 6.4) |
| 召回低 | BQ 的 ef_construction 或 refine_k 不够 | ef_construction ≥ 300, refine_k ≥ 10 |
| 召回低 | 低维向量用了量化索引 | BQ 需 ≥ 512 维,PQ 需 ≥ 128 维 |
| 混合查询慢 | 标量字段没索引 | 建标量索引 |
| 混合查询慢 | 自动策略没选对 | hint 手动指定 |
| 建索引报 key too long | 分区键 varchar 太长 | 缩到实际长度 |
| 索引构建极慢 | 并行度或采样精度不够 | 调 PARALLEL 和 _px_object_sampling |
| 内存不够 | 向量索引配比低,租户内存不足 | 调 ob_vector_memory_limit_percentage,或增加租户内存 |
| QPS 低 / RT 高 | 分区太碎,单分区不到 100 万 | 合并分区,控制在 500-2000 万(见 4.1) |
下篇:向量运维实践
【运维 SQL 速查】 内存视图怎么查、索引创建到哪一步、并行度是不是生效。这一部分是日常巡检和故障排查的工具书。
9. 内存相关
这一章是巡检 SQL 速查:复制即用,区分老版本 / 新版本 / 用户租户 / sys 租户。
9.1. 查看向量内存使用情况
OceanBase 4.3.5 BP3 之前的版本,还没有 GV$OB_VECTOR_MEMORY 视图,需要查虚拟表 __all_virtual_vector_index_info。
SELECT DISTINCT
u.tenant_id,
u.svr_ip,
u.svr_port,
ROUND(u.memory_size / 1024 / 1024, 2) AS tenant_mem_mb,
ROUND(COALESCE(v.vector_mem_bytes, 0) / 1024 / 1024, 2) AS vector_mem_mb,
ROUND(u.memory_size * CAST(p.value AS UNSIGNED) / 100 / 1024 / 1024, 2) AS vector_mem_limit_mb,
ROUND(COALESCE(v.vector_mem_bytes, 0) * 100.0 / u.memory_size, 4) AS vector_mem_pct,
CAST(p.value AS UNSIGNED) AS vector_mem_limit_pct_cfg
FROM oceanbase.GV$OB_UNITS u
LEFT JOIN (
SELECT
tenant_id,
svr_ip,
svr_port,
MAX(CAST(IFNULL(SUBSTRING_INDEX(SUBSTRING_INDEX(statistics, 'all_index_mem_used=', -1), ';', 1), 0) AS UNSIGNED))
+ MAX(CAST(IFNULL(SUBSTRING_INDEX(SUBSTRING_INDEX(statistics, 'all_index_bitmap_used=', -1), ';', 1), 0) AS UNSIGNED))
AS vector_mem_bytes
FROM oceanbase.__all_virtual_vector_index_info
GROUP BY tenant_id, svr_ip, svr_port
) v
ON v.tenant_id = u.tenant_id
AND v.svr_ip = u.svr_ip
AND v.svr_port = u.svr_port
LEFT JOIN oceanbase.GV$OB_PARAMETERS p
ON p.tenant_id = u.tenant_id
AND p.name = 'ob_vector_memory_limit_percentage'
ORDER BY vector_mem_pct DESC;
OceanBase 4.3.5 BP3 之后的版本有 GV$OB_VECTOR_MEMORY 视图,可以直接查看。
--- 用户租户下查
SELECT b.zone,
a.svr_ip,
a.svr_port,
a.tenant_id,
ROUND(a.vector_mem_hold / 1024 / 1024 / 1024, 2) AS hold_gb,
ROUND(a.vector_mem_used / 1024 / 1024 / 1024, 2) AS used_gb,
ROUND(a.vector_mem_limit / 1024 / 1024 / 1024, 2) AS limit_gb
FROM GV$OB_VECTOR_MEMORY a
JOIN gv$ob_units b
ON a.tenant_id = b.tenant_id
AND a.svr_ip = b.svr_ip
AND a.svr_port = b.svr_port
ORDER BY b.zone, used_gb DESC;
-- sys 租户下查
SELECT b.zone,
a.svr_ip,
a.svr_port,
a.tenant_id,
ROUND(a.vector_mem_hold/1024/1024/1024, 2) AS hold_gb,
ROUND(a.vector_mem_used/1024/1024/1024, 2) AS used_gb,
ROUND(a.vector_mem_limit/1024/1024/1024, 2) AS limit_gb
FROM GV$OB_VECTOR_MEMORY a
JOIN dba_ob_units b
ON a.tenant_id = b.tenant_id
AND a.svr_ip = b.svr_ip
AND a.svr_port = b.svr_port
WHERE a.tenant_id = 1002
ORDER BY b.zone, used_gb DESC;
10. 向量索引创建
创建中、创建完、确认并行度——三类排查 SQL 一次备齐。
10.1. 向量索引已经完成创建时的确认方法
select table_id from oceanbase.__all_table where table_name='c_search_semantic_yb_sft_2560';
+----------+
| table_id |
+----------+
| 500008 |
+----------+
1 row in set (0.02 sec)
select table_name, table_id from oceanbase.__all_table where table_name like'%idx_500008%';
+------------------------------------------------+----------+
| table_name | table_id |
+------------------------------------------------+----------+
| __idx_500008_idx_vec | 501892 |
| __idx_500008_idx_vec_index_id_table | 502269 |
| __idx_500008_idx_vec_index_snapshot_data_table | 503023 |
| __idx_500008_rowkey_vid_table | 501515 |
| __idx_500008_vid_rowkey_table | 502646 |
+------------------------------------------------+----------+
5 rows in set (0.00 sec)
select * from __all_virtual_ddl_diagnose_info order by create_time desc limit 10\G
*************************** 1.row ***************************
tenant_id: 1004
ddl_task_id: 1187533
object_table_id: 503023
opname: DDL_CREATE_PARTITIONED_LOCAL_INDEX
create_time: 2026-03-2011:14:16.876958
finish_time: 2026-03-2013:55:21.307453
diagnose_info: buildlocalindex batch num: 3,
THREAD_INFO: { parallel_num : 60, row_max: 1509758, row_max_thread_id: 232598, row_min: 111628, row_min_thread_id: 233047 }
*************************** 2.row ***************************
tenant_id: 1004
ddl_task_id: 1187528
object_table_id: 502646
opname: DDL_CREATE_PARTITIONED_LOCAL_INDEX
create_time: 2026-03-2011:14:16.559993
finish_time: 2026-03-2011:14:48.023609
diagnose_info: buildlocalindex batch num: 3,
THREAD_INFO: { parallel_num : 60, row_max: 1509758, row_max_thread_id: 233069, row_min: 111628, row_min_thread_id: 232597 }
*************************** 3.row ***************************
tenant_id: 1004
ddl_task_id: 1173102
object_table_id: 502269
opname: DDL_CREATE_PARTITIONED_LOCAL_INDEX
create_time: 2026-03-2011:12:20.096392
finish_time: 2026-03-2011:14:16.538926
diagnose_info: buildlocalindex batch num: 3,
THREAD_INFO: { parallel_num : 0, row_max: 0, row_max_thread_id: 0, row_min: 0, row_min_thread_id: 0 }
*************************** 4.row ***************************
tenant_id: 1004
ddl_task_id: 1173096
object_table_id: 501892
opname: DDL_CREATE_PARTITIONED_LOCAL_INDEX
create_time: 2026-03-2011:12:19.761647
finish_time: 2026-03-2011:14:16.409340
diagnose_info: buildlocalindex batch num: 3,
THREAD_INFO: { parallel_num : 0, row_max: 0, row_max_thread_id: 0, row_min: 0, row_min_thread_id: 0 }
*************************** 5.row ***************************
tenant_id: 1004
ddl_task_id: 1169322
object_table_id: 501515
opname: DDL_CREATE_PARTITIONED_LOCAL_INDEX
create_time: 2026-03-2011:11:53.983074
finish_time: 2026-03-2011:12:19.723261
diagnose_info: buildlocalindex batch num: 3,
THREAD_INFO: { parallel_num : 60, row_max: 1509758, row_max_thread_id: 232591, row_min: 111628, row_min_thread_id: 232608 }
5rowsinset (0.01 sec)
# 根据 task_id 确认创建向量索引时,对应的 trace_id
select * from __all_ddl_error_message where task_id = 1187533\G
*************************** 1.row ***************************
gmt_create: 2026-03-2013:55:21.307453
gmt_modified: 2026-03-2013:55:21.307453
tenant_id: 0
task_id: 1187533
target_object_id: -1
object_id: 503023
schema_version: 1773976456876848
svr_ip: 1.2.3.4
svr_port: 2882
ret_code: 0
ddl_type: 10
affected_rows: 0
user_message: Successful ddl
dba_message: Successful ddl
parent_task_id: 1169317
trace_id: YB420A80D393-00064D4622BFF791-0-0
consensus_schema_version: -1
1rowinset (0.01 sec)
10.2. 向量索引正在创建中确认方法
select * from gv$session_longops \G
*************************** 1.row ***************************
SID: -1
TRACE_ID: YB420A80D394-00064D34502CB6A9-0-0
OPNAME: create partitioned localindex
TARGET: 506793
SVR_IP: 1.2.3.4
SVR_PORT: 2882
START_TIME: 2026-03-2416:50:35
ELAPSED_SECONDS: 1414
TIME_REMAINING: 0
LAST_UPDATE_TIME: 2026-03-2417:14:09
MESSAGE: ...
*************************** 2.row ***************************
SID: -1
TRACE_ID: YB420A80D394-00064D34502CB6A9-0-0
OPNAME: create vec index
TARGET: 505285
SVR_IP: 1.2.3.4
SVR_PORT: 2882
START_TIME: 2026-03-2416:47:07
ELAPSED_SECONDS: 1622
TIME_REMAINING: 0
LAST_UPDATE_TIME: 2026-03-2417:14:09
MESSAGE: TENANT_ID: 1004, TASK_ID: 5459185, STATUS: WAIT_VID_ROWKEY_TABLE_COMPLEMENT
2rowsinset (0.49 sec)
10.3. 收集 traceid
- 根据上面查询的 __all_virtual_ddl_diagnose_info 确认向量索引创建的时间。
- 根据 __all_ddl_error_message 或者 gv$session_longops 确认向量索引创建对应的 traceid。
obdiag gather log --from='2026-03-16 21:00:00' --to='2026-03-17 17:00:00' --scope=all --grep='YB420A80D369-000649E8EDEED23D-0-0'
注意:收集的日志时间跨度大,可能会超过 obdiag 默认配置的阈值,可以按需调整一下。 /opt/oceanbase-diagnostic-tool/conf/inner_config.yml 修改一下 file_number_limit。
10.4. 确认创建向量索引的并行度
通过 real_parallelism 关键字在 rs 机器上搜索 trace id。
grep "real_parallelism" rootservice.log.20260320* | vim -
rootservice.log.20260320130120505:[2026-03-20 11:11:54.486345]
INFO [RS] create_ddl_task (ob_ddl_scheduler.cpp:1259)
[28844][DDLQueueTh0][T1][YB420A80D393-00064D4622BFF791-0-0]
[lt=10] create ddl task(real_parallelism=400, param=...
拿到 trace id YB420A80D393-00064D4622BFF791-0-0 之后,继续在 rs 机器上确认更多信息即可。
grep "YB420A80D393-00064D4622BFF791-0-0" rootservice.log* | grep "execute sql" | grep "index_snapshot_data_table"
rootservice.log.20260320130120505:[2026-03-20 11:14:22.005772]
INFO [RS] process (ob_index_build_task.cpp:169) [29241][T1_DdlBuild10][T1][YB420A80D393-00064D4622BFF791-0-0]
[lt=12] execute sql(sql_string=INSERT /*+ monitor enable_parallel_dml parallel(134)...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号