【第3次作业】卷积神经网络
【第一部分】视频学习心得及问题总结
【第二部分】代码练习
1.MNIST 数据集分类
1.1.加载数据
将本次CNN的训练和测试的数据加载进来。
加载成功后,显示数据集中的部分图像。

1.2.创建网络
定义网络,继承nn.Module并实现其中的forward方法,把网络中具有可学习参数的层放在构造函数init中。


定义训练和测试函数
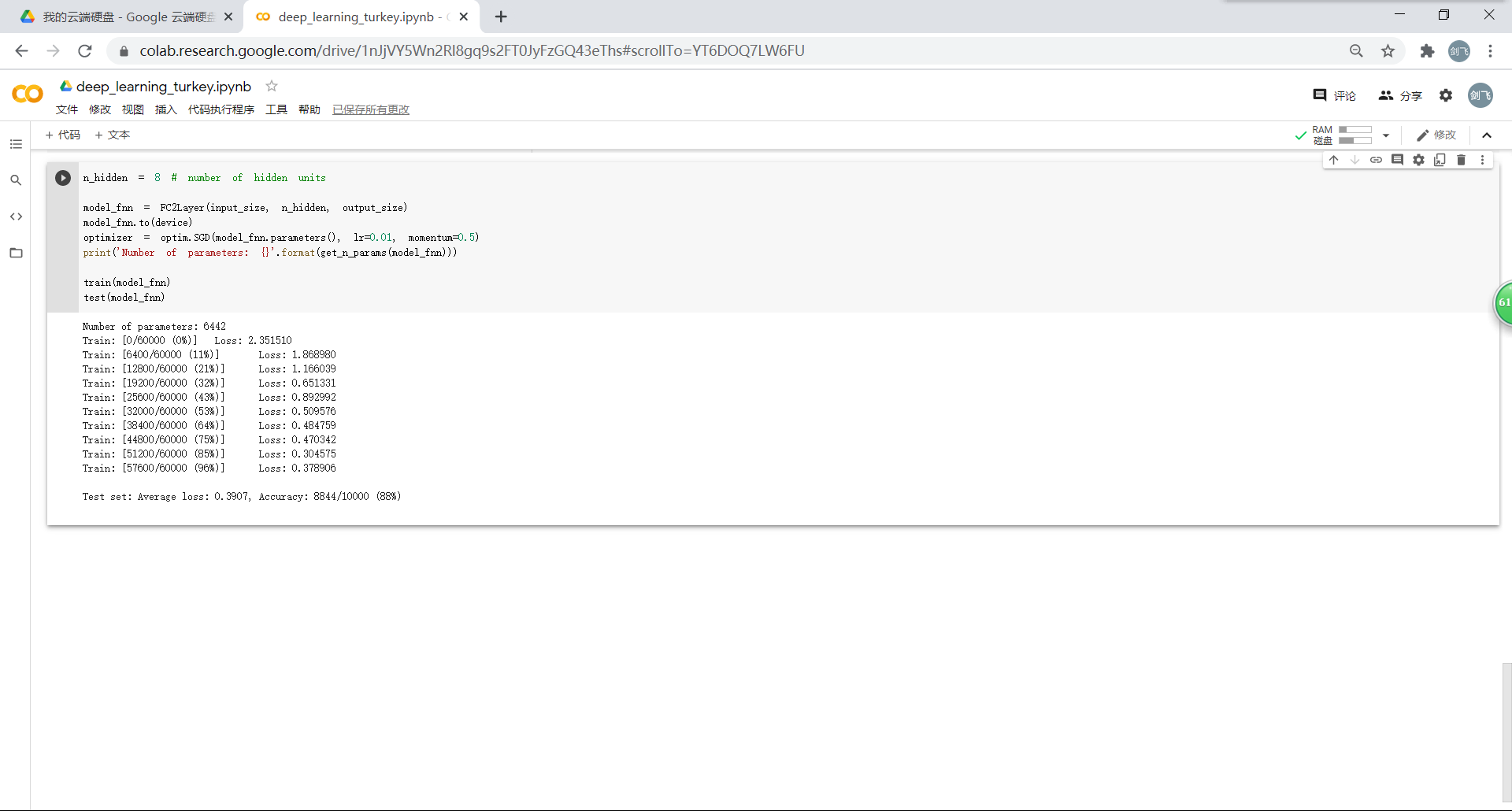
1.3.在小型全连接网络上训练
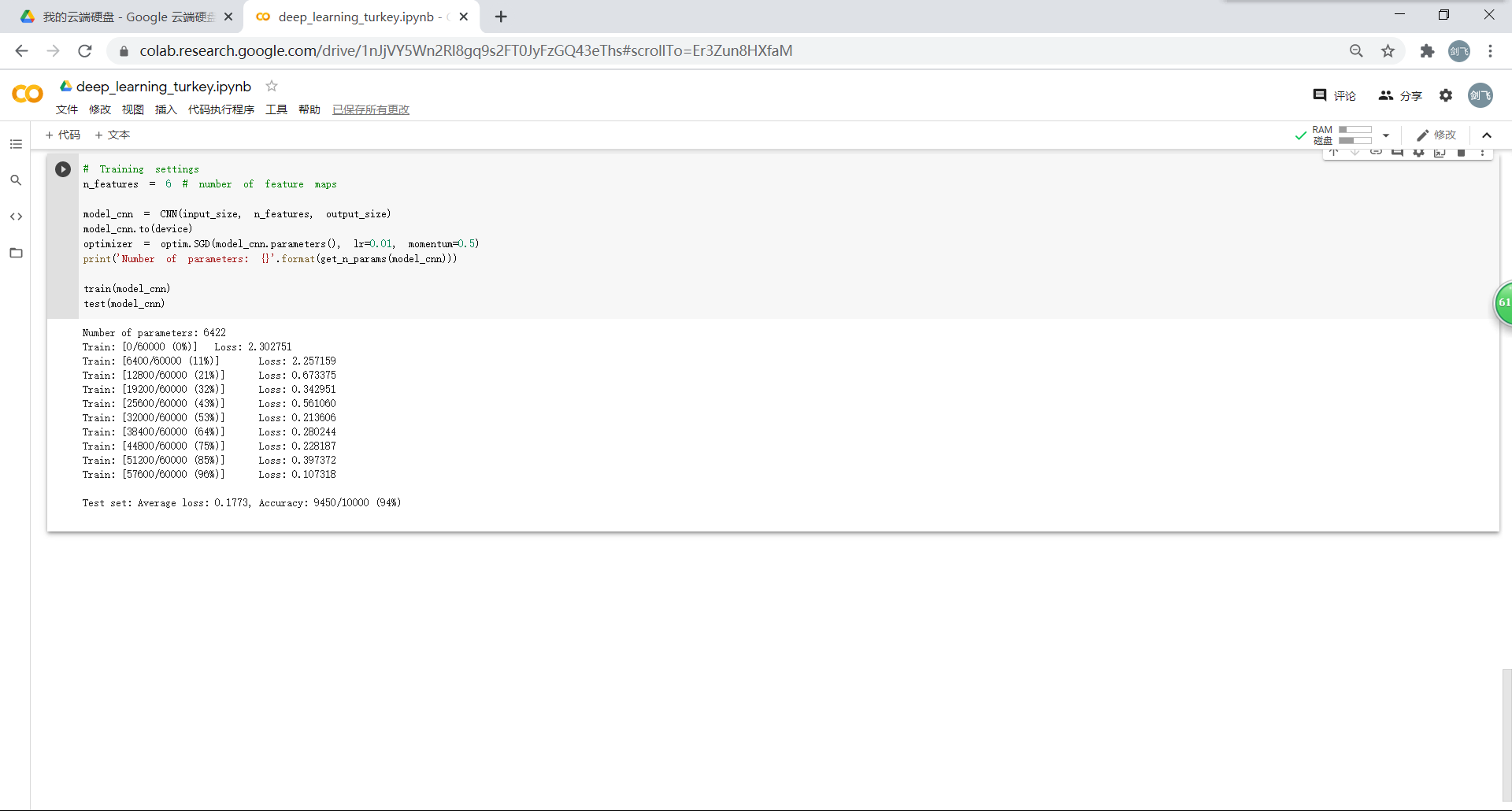
1.4.在卷积神经网络上训练
通过上面的测试结果,可以发现:含有相同参数的 CNN 效果要明显优于简单的全连接网络。(卷积和池化)
1.5.打乱像素顺序再次在两个网络上训练与测试
如果我们把图像中的像素打乱顺序,卷积和池化是否就难以发挥作用了?为了验证这个想法,我们把图像中的像素打乱顺序再试试。随机打乱像素顺序后图像的形态:

重新定义训练与测试函数:train_perm 和 test_perm,分别对应着加入像素打乱顺序的训练函数与测试函数。与之前相比只是吧data 加入了打乱顺序操作。

在全连接网络上训练与测试:
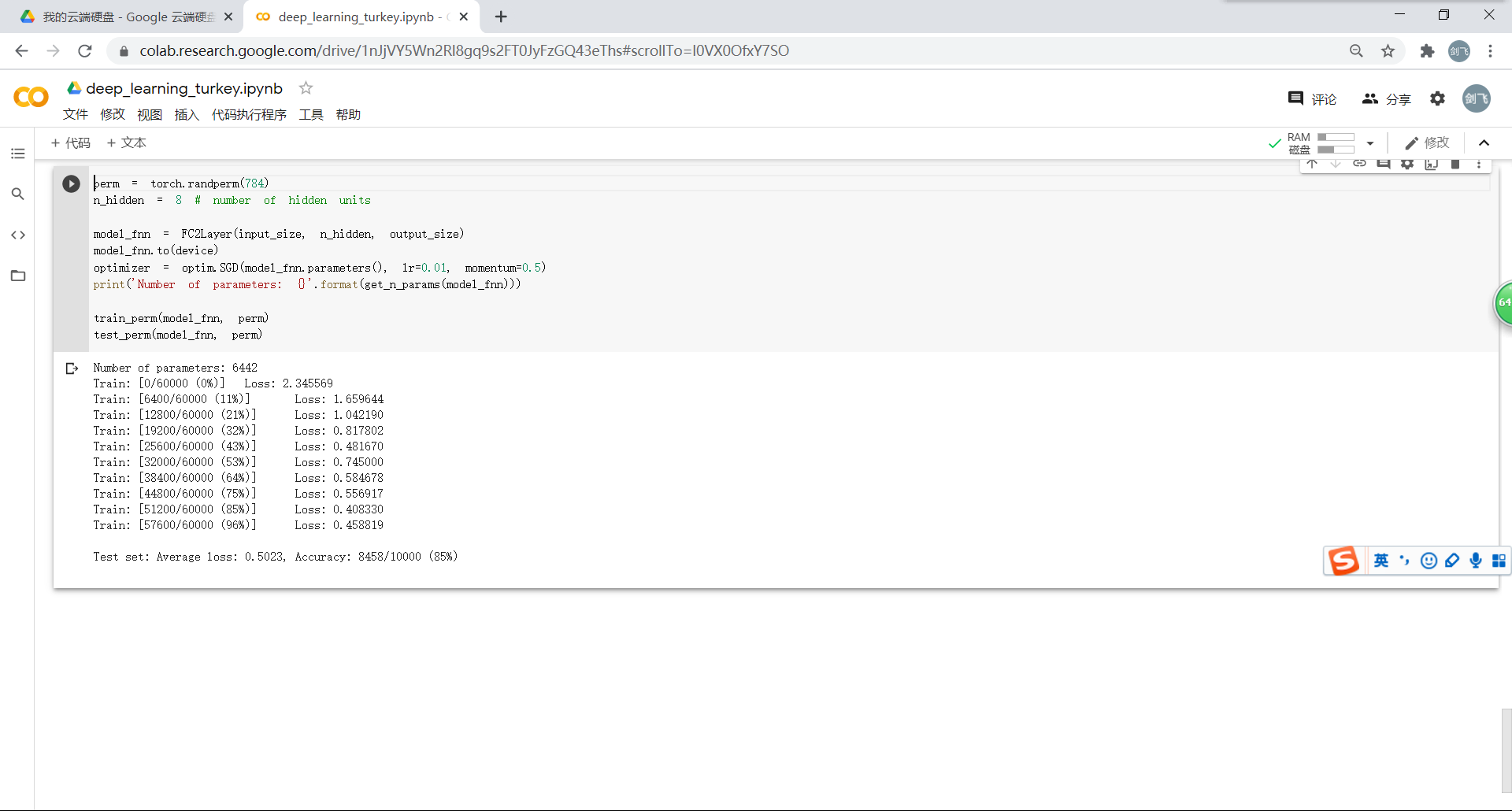
在卷积神经网络上训练与测试:与上面相比较可以看出,在打乱顺序之后的训练和测试中全连接网络的效果更好。

2.CIFAR10 数据集分类
2.1.下载数据
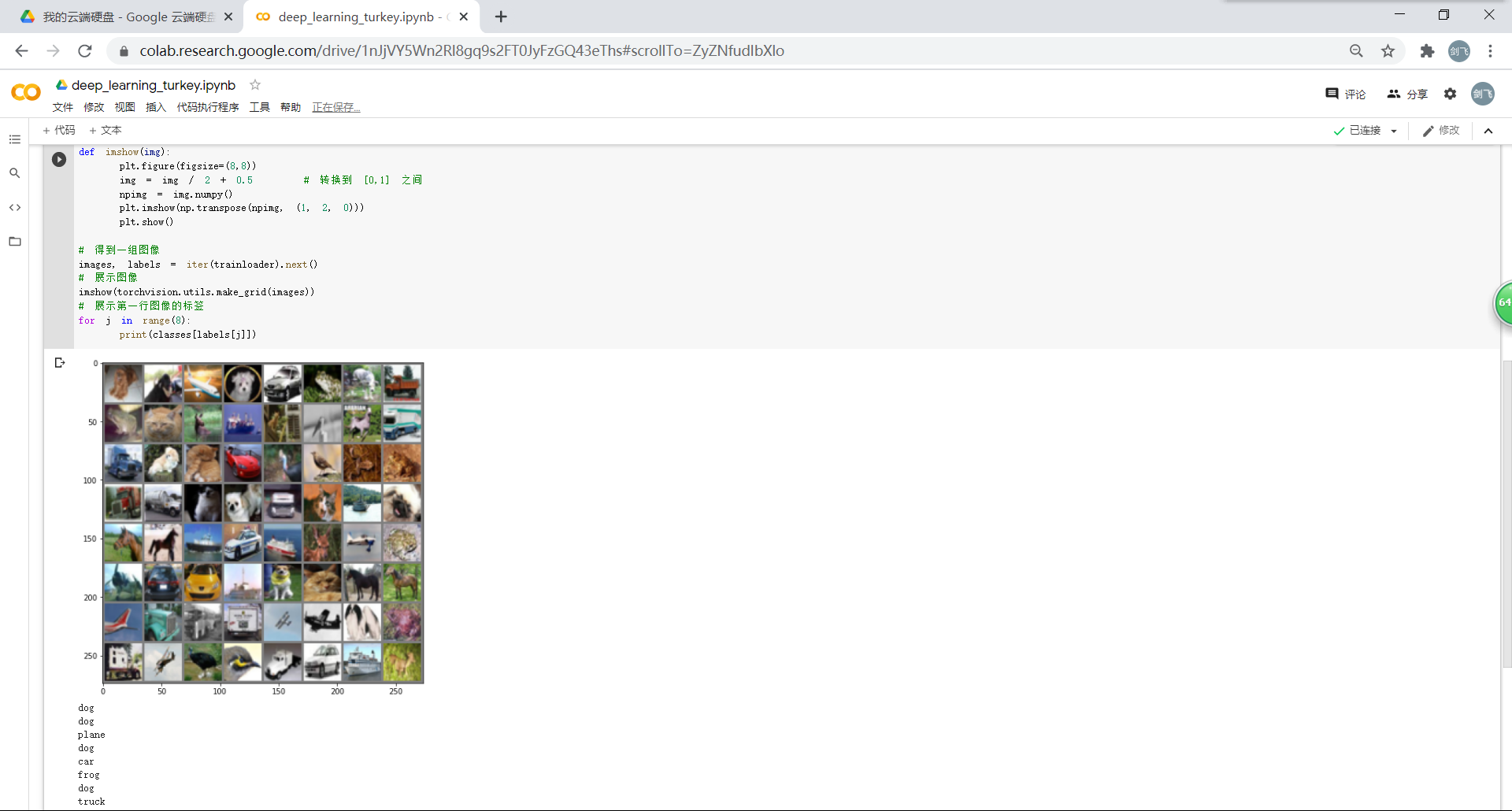
展示加载的数据(CIFAR10) 里面的一些图片:
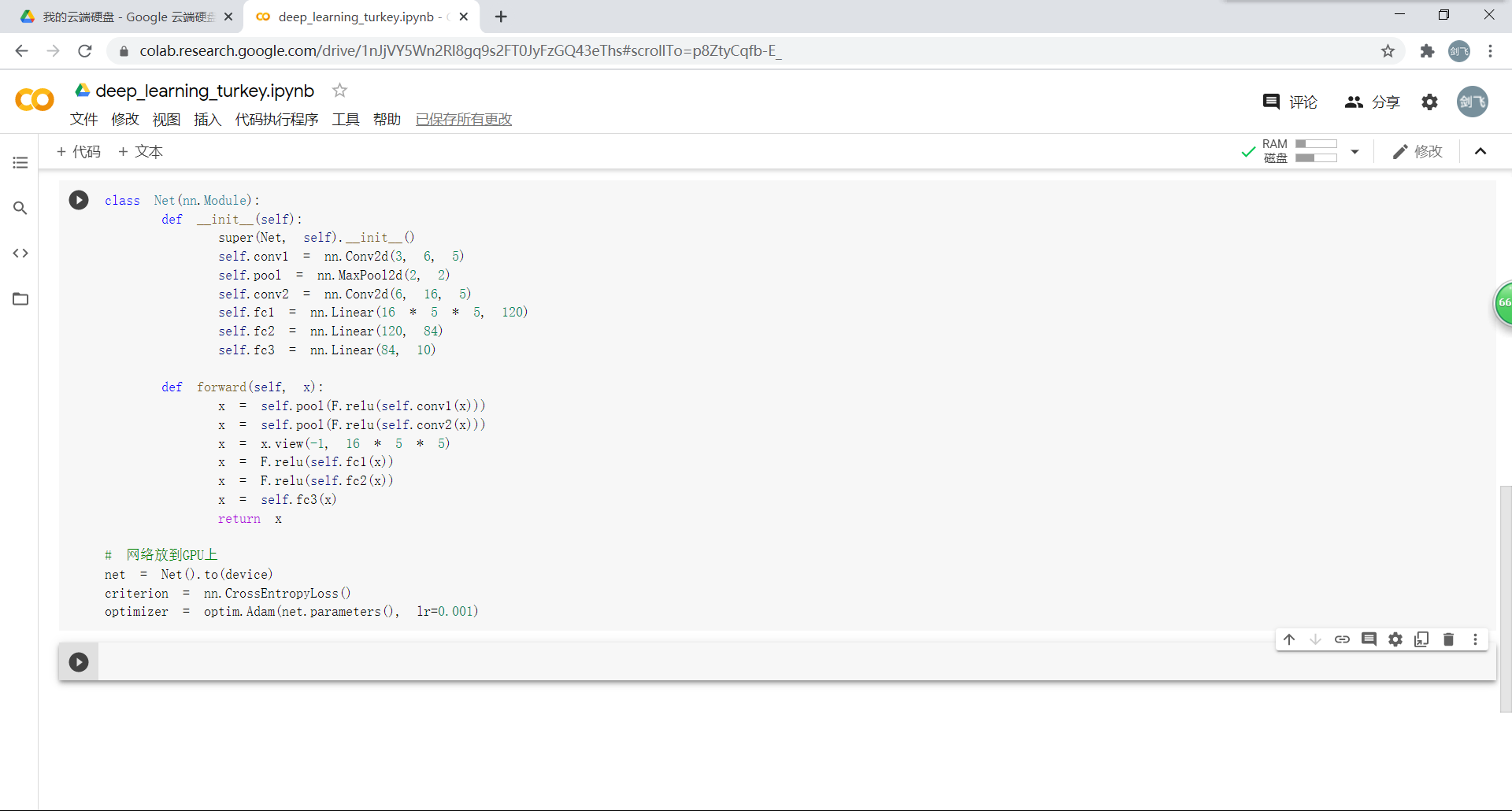
2.2.创建网络
定义网络,损失函数和优化器:
训练网络:
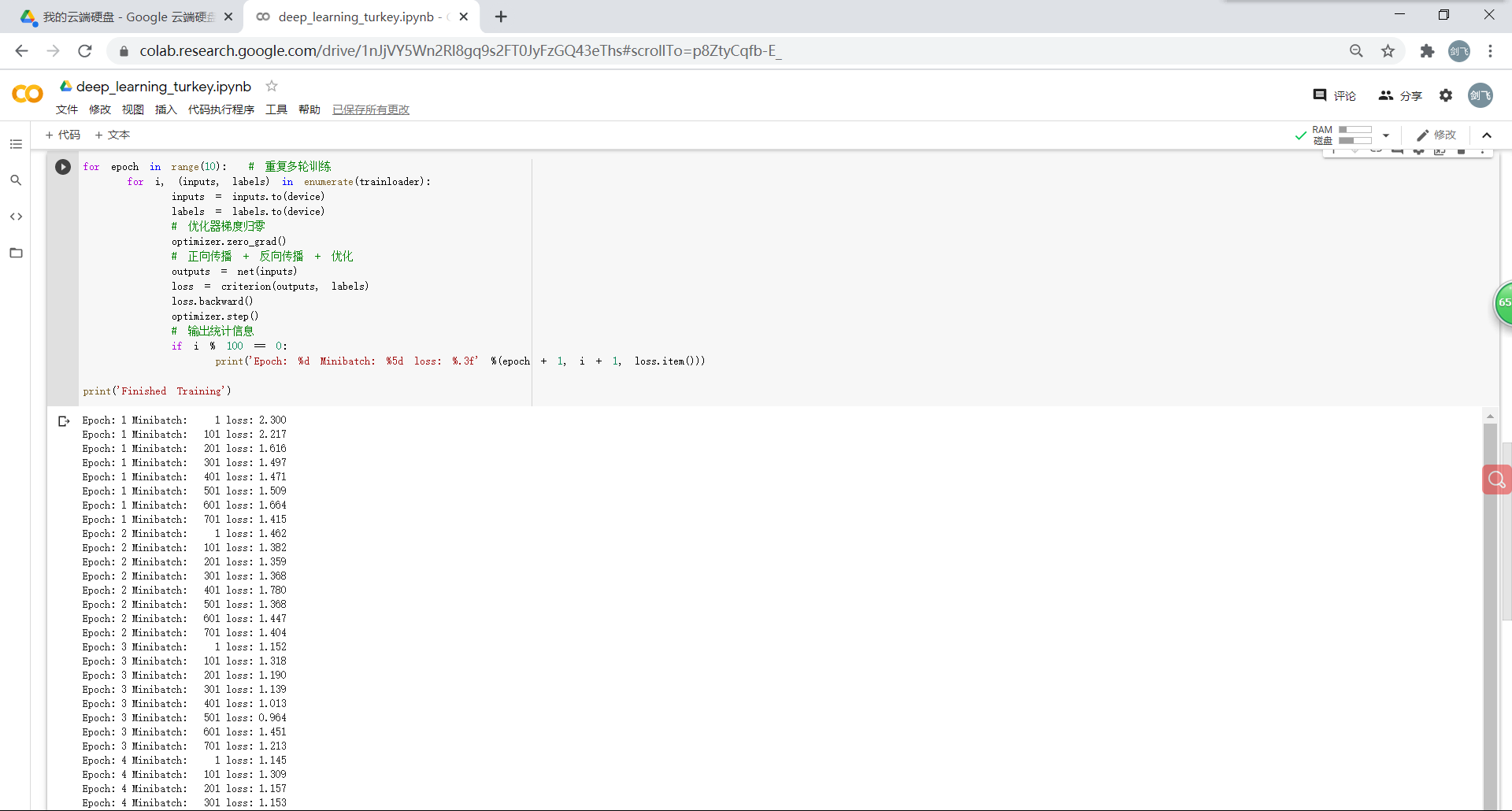

2.3.测试
从测试集中取出8张图片:
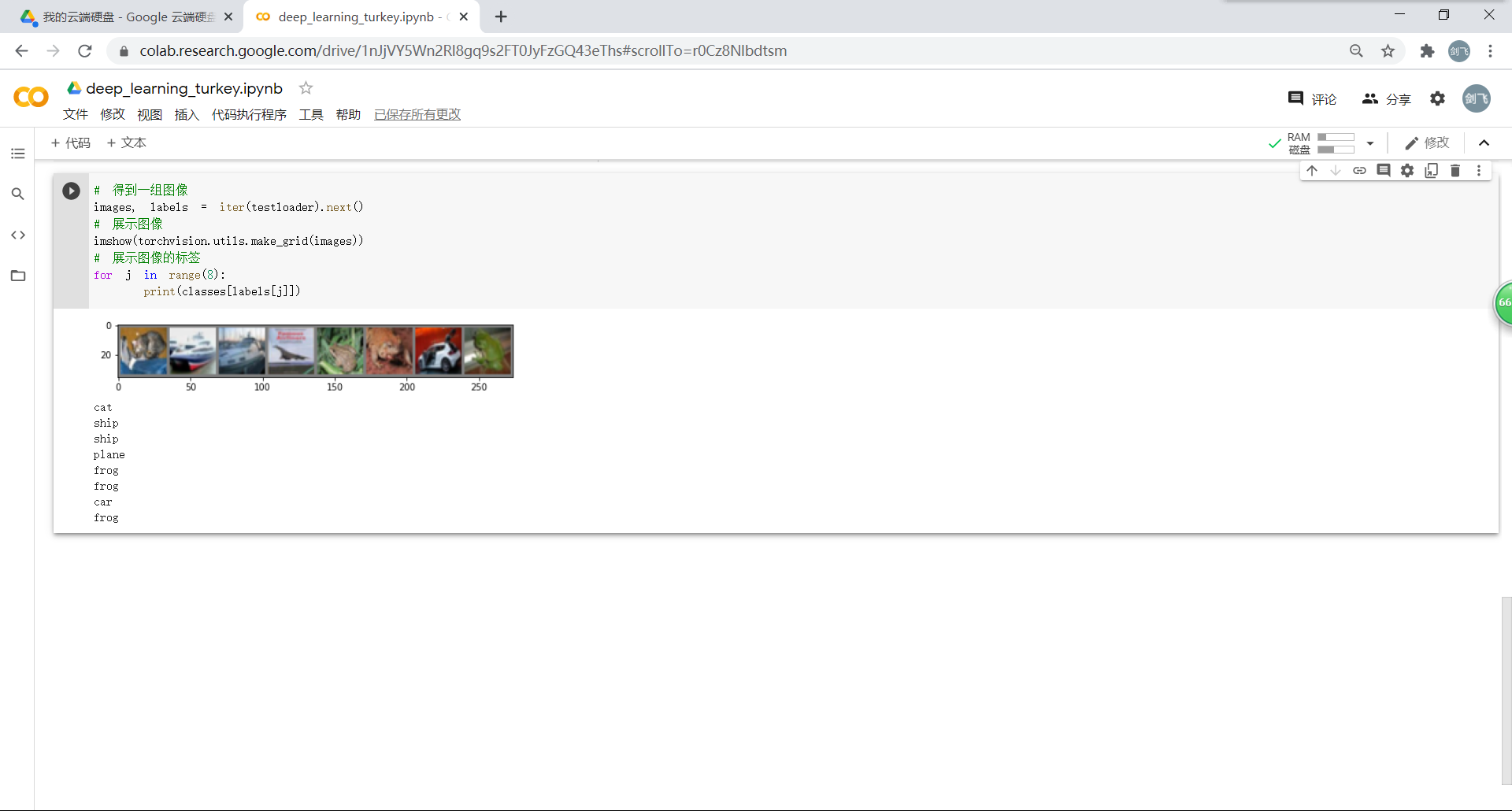
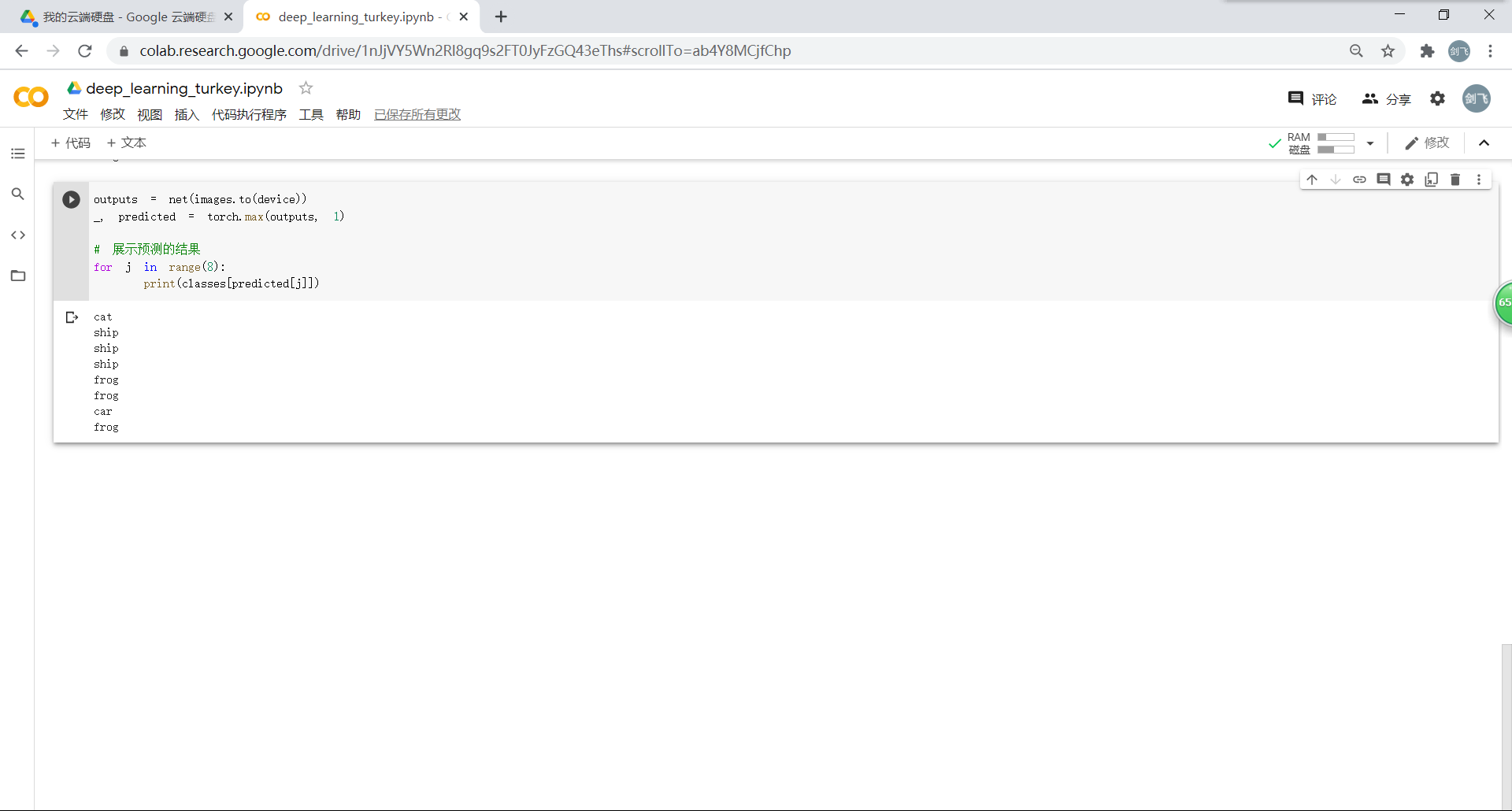
把图片输入模型,看看CNN对图片的识别结果:
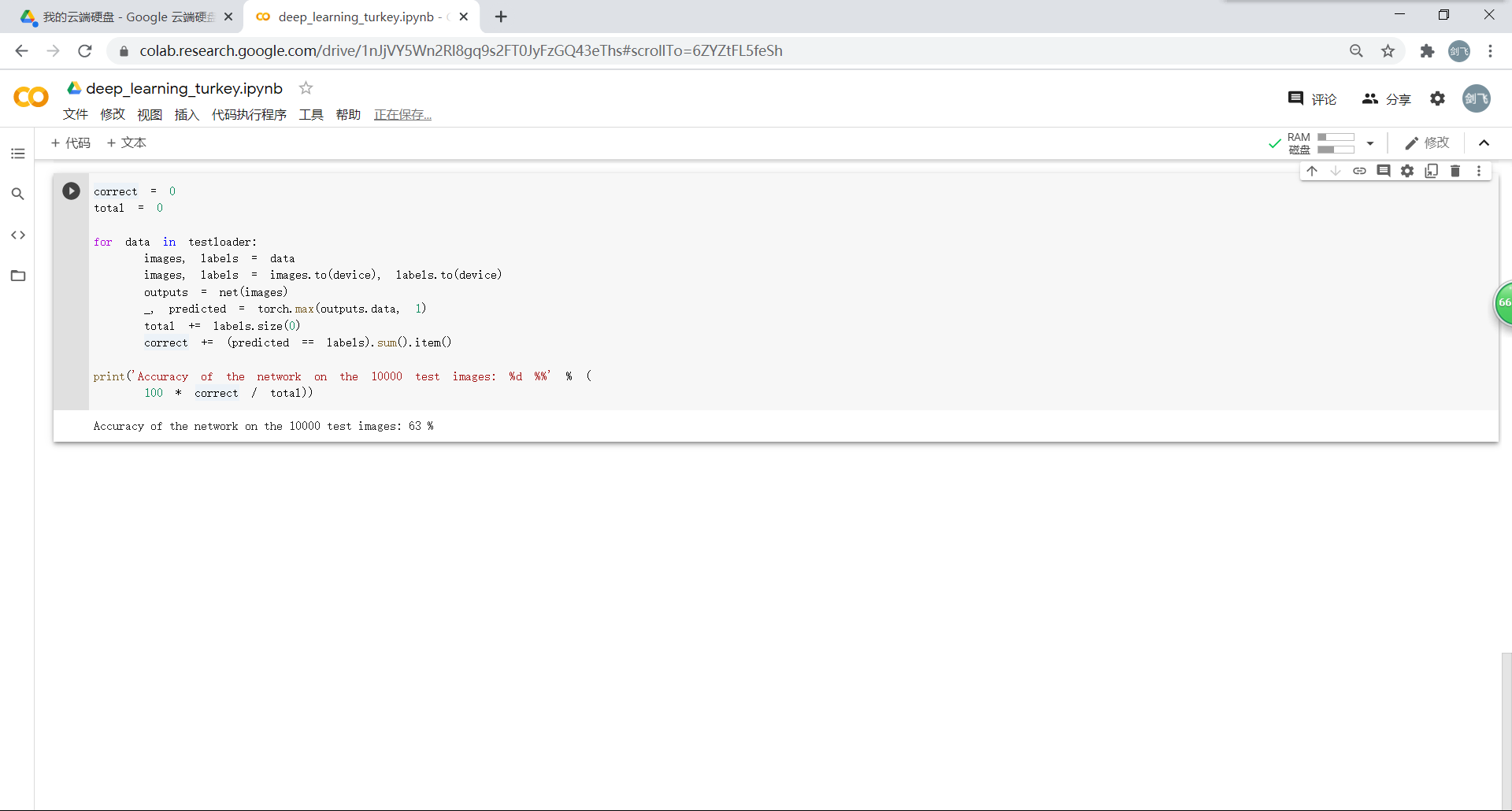
看看网络在整个数据集上的表现:(准确率还可以,通过改进网络结构,性能还可以进一步提升)
3.使用 VGG16 对 CIFAR10 分类
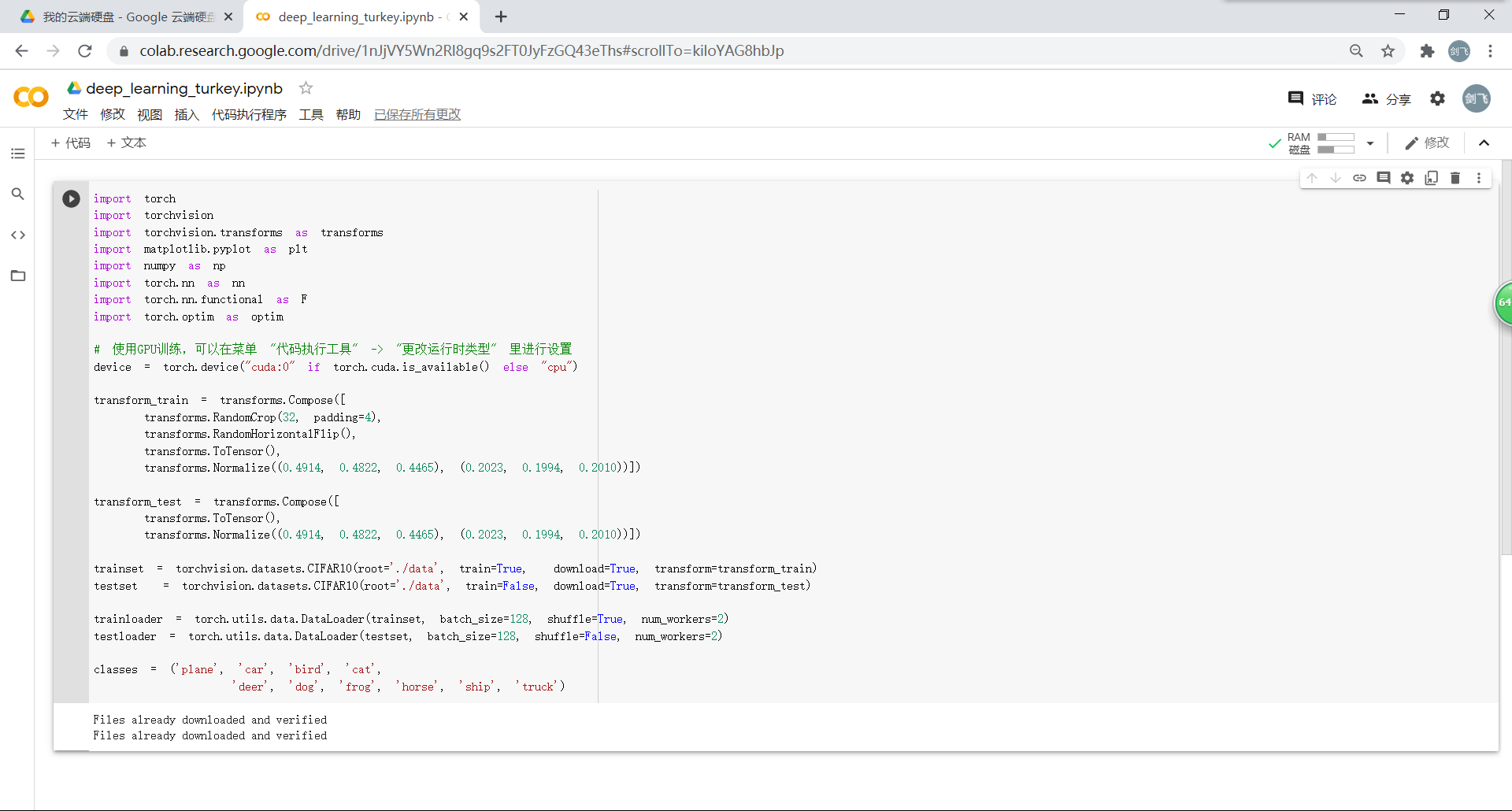
3.1.定义 dataloader
这里的 transform和dataloader 与之前实验中的定义的有所不同:
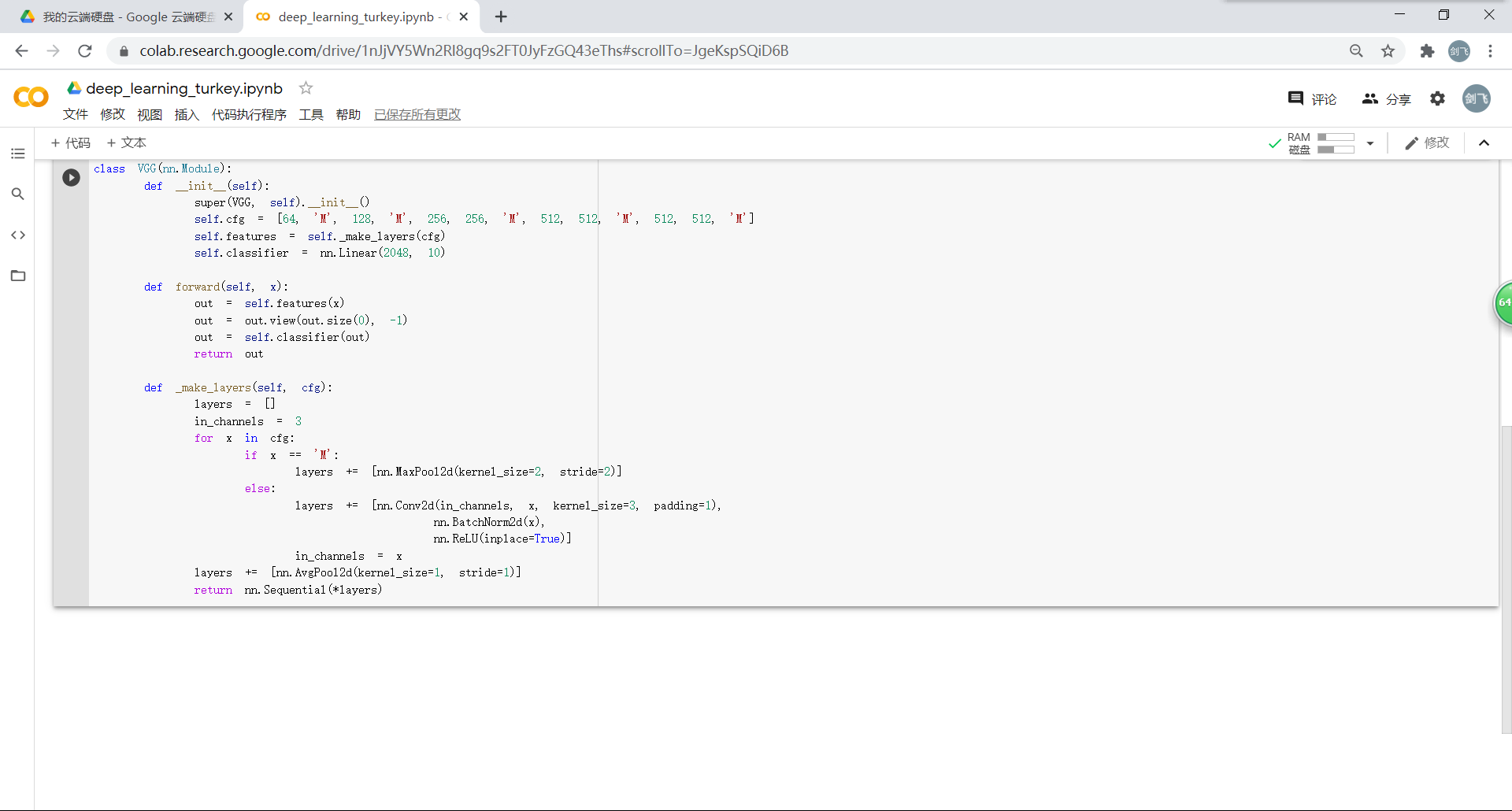
3.2. VGG 网络定义
现在的结构基本上是:(64 conv, maxpooling, 128 conv, maxpooling, 256 conv, 256 conv, maxpooling, 512 conv, 512 conv, maxpooling, 512 conv, 512 conv, maxpooling, softmax)
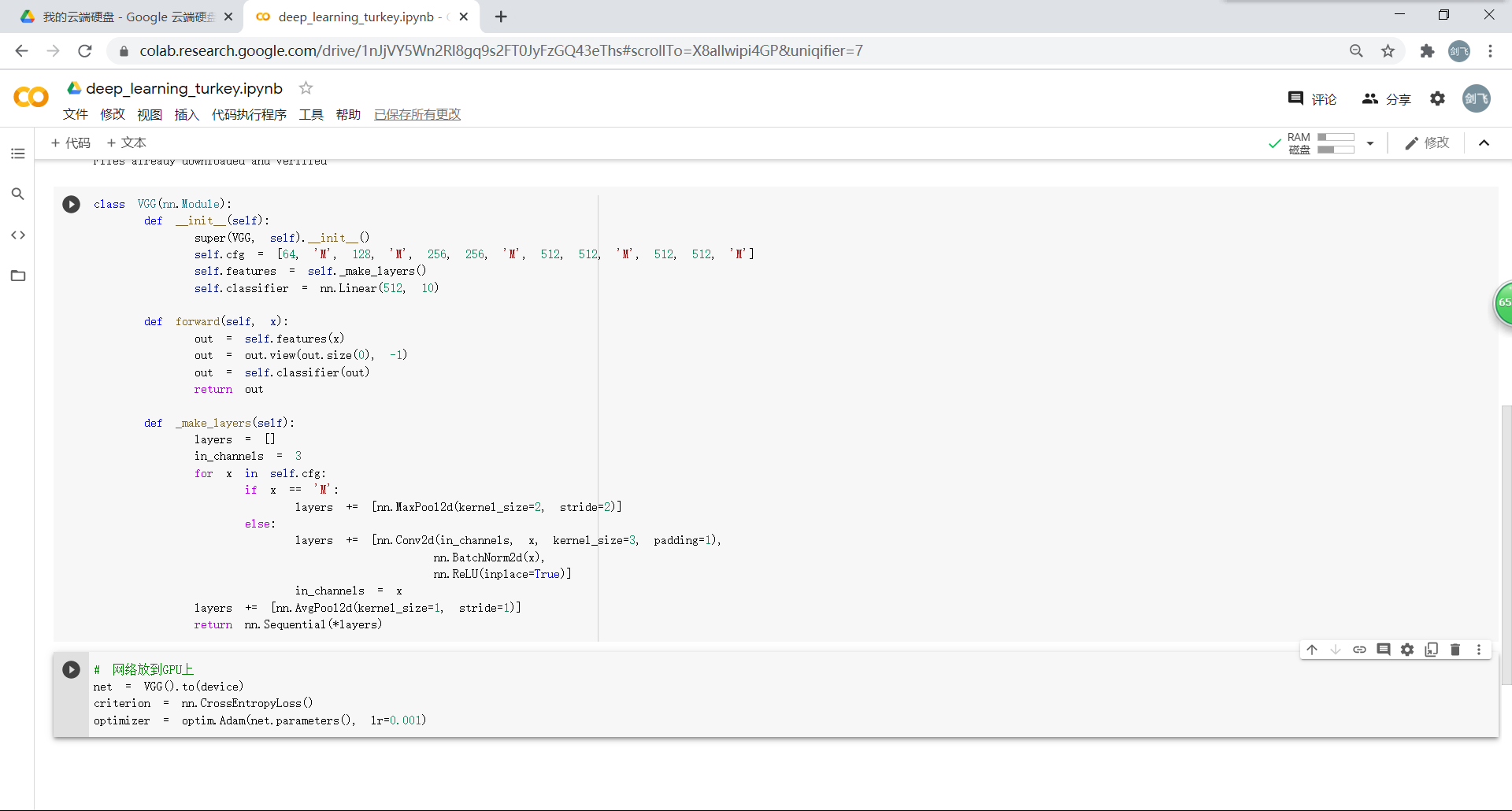
因为 tiny-imagenet 是对200类图像分类,这里把输出修改为200:
3.3.网络训练
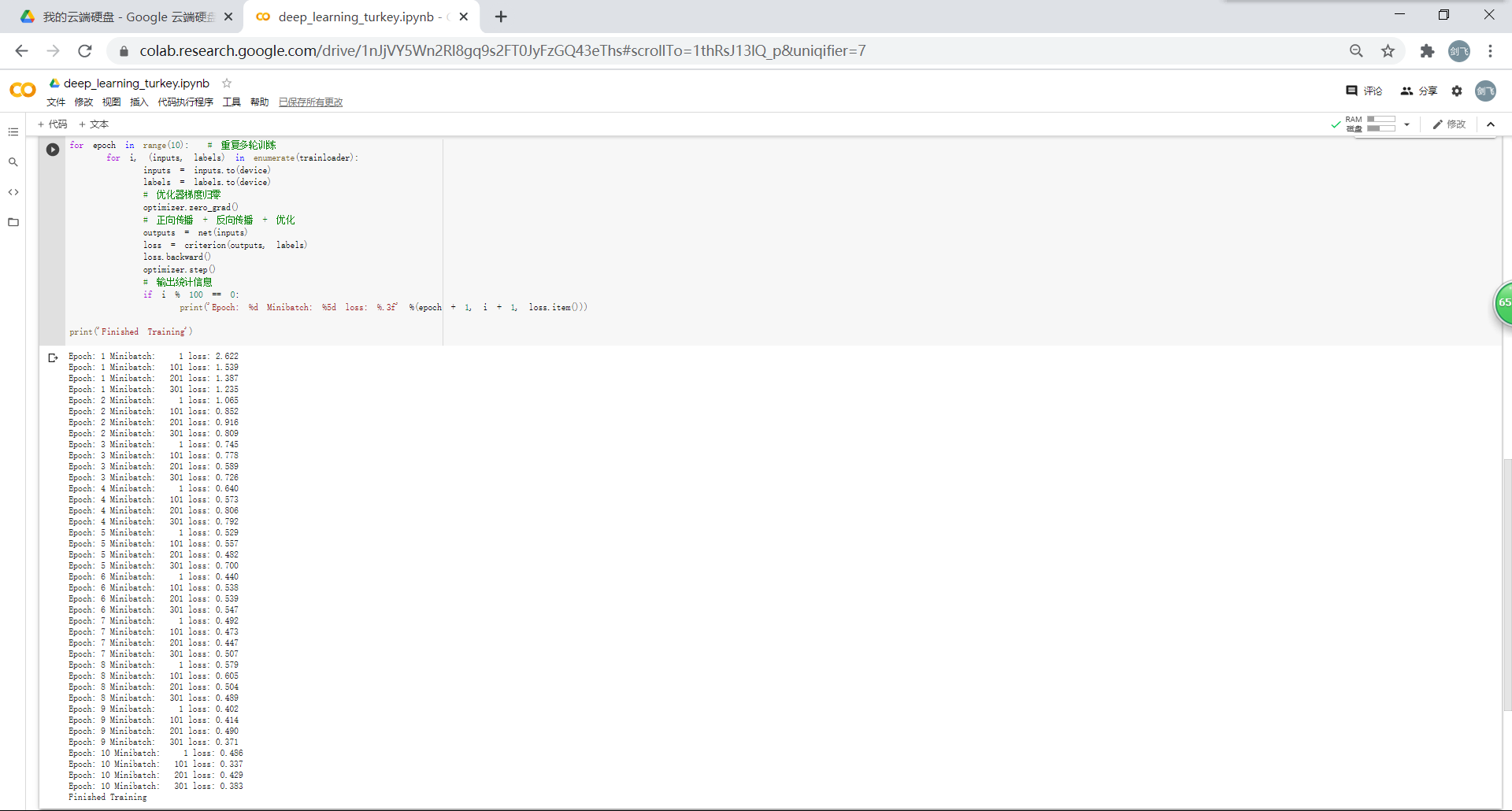
使用一个简化版的 VGG 网络,就能够显著地将准确率由 63%,提升到 83.94%:
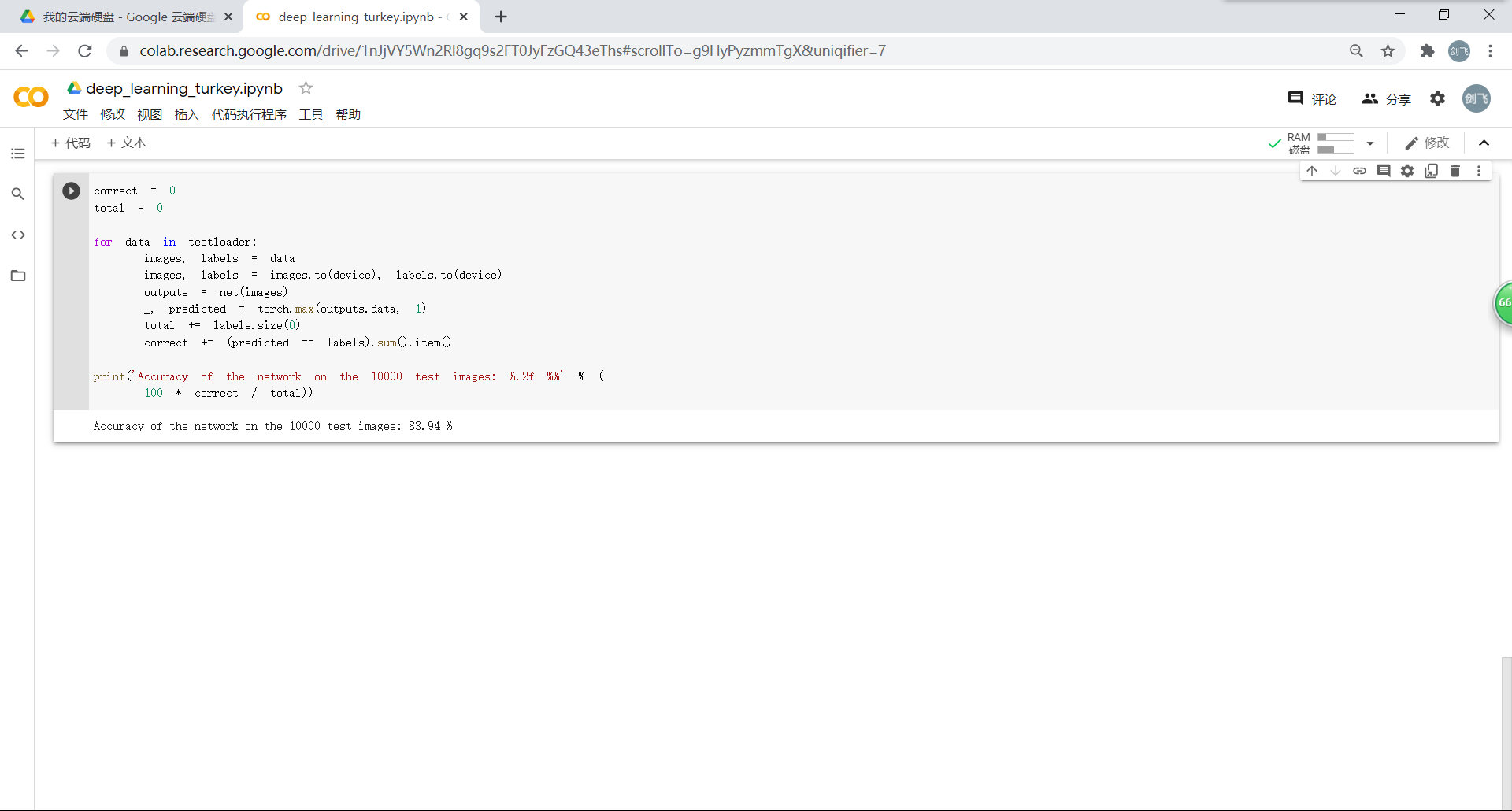
4.感受和总结:
通过三个实验,让我们体验到了从最简单的全连接网络到卷积神经网络到VGG16的实施以及效率逐步提升。让我对于之前的视频学习有了一个更具体形象的理解,能大概理解代码的意思和内容,但是靠自己依然无法写出(很多库和函数的调用并不是很会)。希望能够慢慢进步!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号