【ECCV 2020】论文阅读:Motion Guided 3D Pose Estimation from Videos
ECCV2020的一篇关于3D姿态视频评估的文章
论文地址:https://arxiv.org/abs/2004.13985
Github地址:好像没找到官方的,但已经有非官方的供参考:https://github.com/tamasino52/UGCN
单位:亚马逊、港中文
摘要
作者提出了一个新的损失函数,称之为motion loss,用于解决单目下从2D pose到3D HPE的问题。在计算motion loss时,一种简单却有效的关键点动作表示方法——paorwise motion被引入进来。作者设计了一个新的图卷积神经网络架构UGCN,这个架构同时捕获长短时动作信息以充分利用motion loss中额外的监督信息。作者在两个大型数据集Human3.6M 和 MPI-INF-3DHP.上进行了实验。该模型大大超过了其他最先进的模型,同时展示了产生平滑的3D序列和恢复关键动作的强大能力。
1&2. Introduction and related work
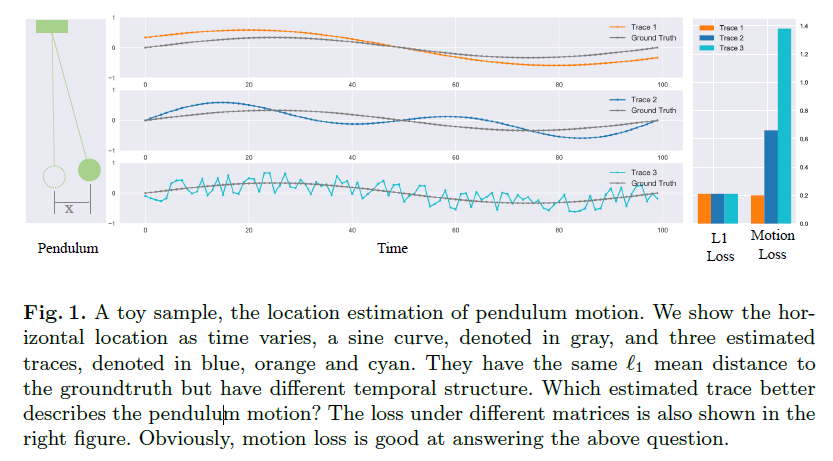
解释一下文中关于Minkowski Distance部分的描述,下图是定义,P=1时为曼哈顿距离,P=2时为欧几里得距离。通过Fig.1解释一下Minkowski Distance的局限性。通过图中可知,trace1基本和ground truth曲线形状相似,trace2趋势不同但还是比较丝滑的,trace3就随机摇摆并且不平滑了,三条曲线的L1 loss平均值相等,但是时序结构完全不同,因为Minkowski Distance只是独立计算每个瞬间的距离,而无法体现轨迹的内部依赖。因为人体关节点与单摆类似,这也是为什么作者要提出这个motion loss。
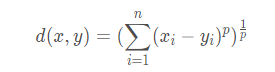
motion loss需要在重建三维关键点位置的基础上,额外重建关键的的轨迹。它通过计算特定表中空间(称为motion encoding)中预测关节点位置和真实值之间的差值来衡量动作重建质量。motion encoding以可微分算子的形式建立。首先将一个轨迹粗略的分解为一组成对的坐标向量,它们具有不同的时间间隔对应不同的时间尺度。一个可微分的二元向量算子,如减法,内积和向量积,应用在每一对上。然后将得到的结果串联起来构造完全的motion coding。这种表示方法如图1所示,运用的是减法,可以有效的评估时序结构的质量。
为了估计出合理的人体运动姿态轨迹,由于人体动作往往具有不同的速度,3D姿态评估模型必须能够在短时间和长时间范围内都能够对动作进行建模。为了解决这一问题,作者提出了一个新的图卷积网络。首先,作者对ST-GCN模型进行了改进,受到U-shaped CNN在语义分割和目标识别中成功应用的启发,作者在ST-GCN的时间轴上构建了类似的U形结构,作者将这个新的架构称之为U-shaped GCN(UGCN)。
3. Approach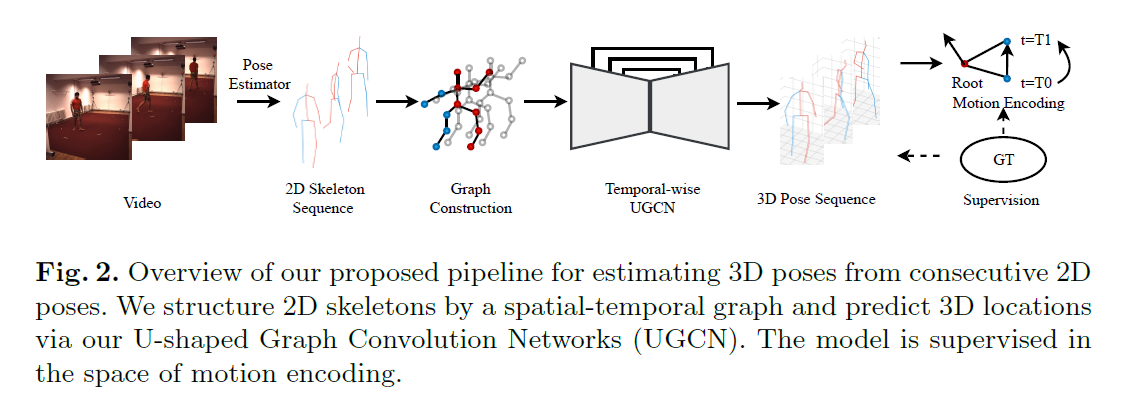
Fig.2 是方法总体架构图。输入T帧的视频,提取2D骨架序列,feeding到spatial-temporal graph中构造2D 关节点,再通过UGCN预测3D 关节位置。
3.1 Motion Loss
本文中,motion loss定义为与运动空间中预测值与真实值的距离。因此需要一个motion encoder来讲骨架序列投影到这个空间中。一般来说,motion encoder需要满足一些基本规则:可微、非独立和多尺度。可微是端到端训练的前提,计算是跨时间的,依赖于时序关系,因此具有非独立性,由于动作速度的不一致,多尺度建模就显得很重要了。
这部分作者设计了一个简单但是卓有成效的encoding,称之为pairwise motion encoding。
pairwise motion encoding:先考虑最简单的例子,姿态的帧长序列长度为2,关节j上的motion encoding可以表示为:

* 表示可微分的二元算子,如减法、数量积或向量积。在一般情况下,帧长序列会更长,则可在motion encoding上进行维度扩增,此处计算相邻帧的motion encoding:

需要注意的是,这种表达方式仅能对两个相邻瞬间(adjacent moments)的关系进行建模。由于人体动作速度变化范围较大,这启发我们在人体动作上进行多时序尺度编码,也就是间隔时间不一定是一帧:
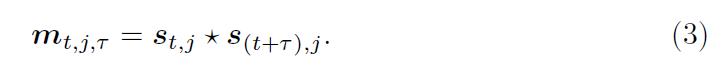
t(\Tau,暂时没去整公式,看得懂就行)表示时间间隔。如Fig.3所示,为了计算整个姿势序列的motion loss,要计算在编码空间中所有关节点、时刻和时间间隔的ell1 Distance,数学表达关系式为:
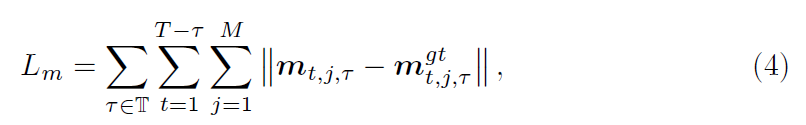
T(\Tau的大写,是\Tau的集合。不是真的T,真的T表示视频帧长)表示时间间隔集,包含多个时间尺度t(\Tau)。motion encoding将轨迹分解为坐标对,并通过微分运算 * 提取每对的特征。因为第一次探究3D姿态评估中的运动监督,作者采用的算子操作都是最简单的:减法、数量积和向量积。
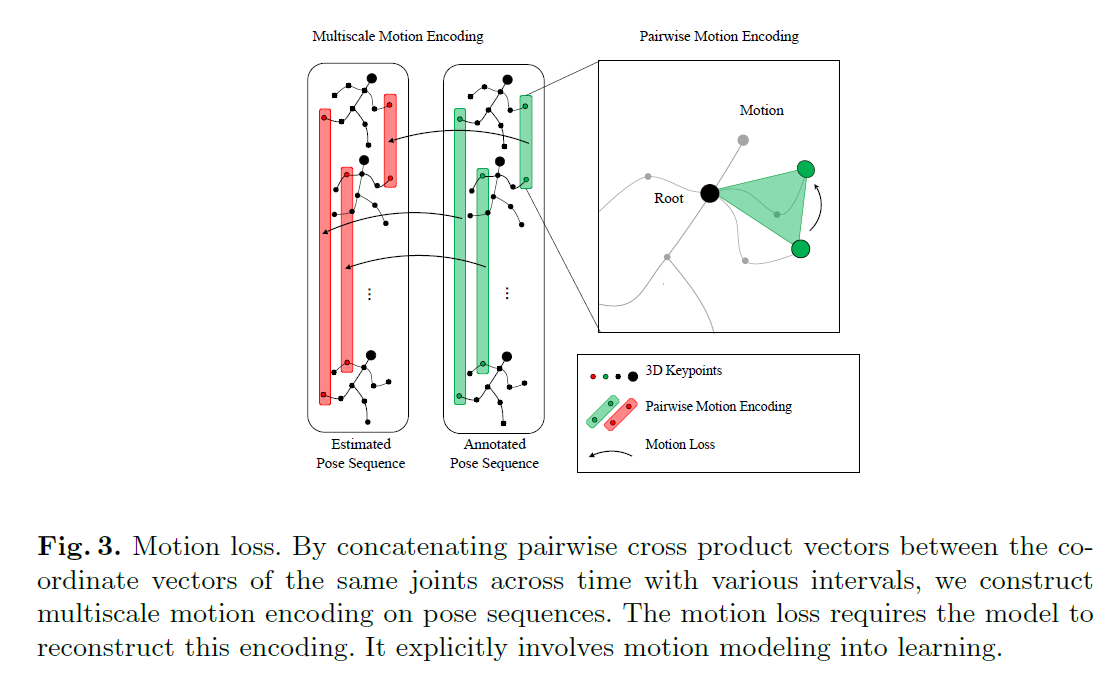
Fig.3 图释:图中显示了如何计算motion loss,计算同一关节向量在不同时间间隔内的向量积,构造了姿态序列的多尺度motion encoding。这个要结合前面的几个公式看更好理解,计算按某一个时间间隔为t的motion encoding时,要计算对应每一帧的motion encoding,细化一点是计算每个节点的motion encoding(这部分参考公式3),并和ground truth的motion encoding取差值,时间间隔t的取值可能有几个,隔帧长短不一,将这几个时间间隔的motion encoding进行累加,就得到了具有长短时间的信息的loss。
Loss Function:motion loss仅考虑了成对motion encoding信息中的二阶相关,而缺少了绝对的位置信息。因此,作者在整体训练中增加了一个传统的损失项:
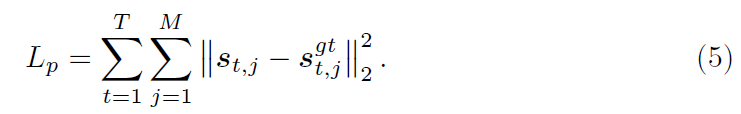
模型的总损失为:
![]()
/lamda为平衡两者的超参数
3.2 U-shaped Graph Convolutional Networks
3D pose estimator除了要注重时序信息,也要关注空间上的信息,因此作者将skeleton sequence表示一个spatial temporal graph以保持其拓扑性,并且通过U-shaped graph convolution network(UGCN)进行信息聚合。
Graph Modeling 2D关键点到3D的投影是一个不适定问题,总的来说,来自其他关节点的信息,尤其是邻居节点,在3D 姿势重建中起到了重要作用。为了对相关节点进行关系建模,使用st-graph处理skeleton sequence是非常自然的一件事。特别的,st-graph G由一个顶点集和一个边集组成,顶点集V={v_t,j | t=1,..., T, j= 1,...,M}包含所有sequence的关节点。边集E由两部分组成:一部分连接每个节点的相邻帧,另一部分连接每根骨头的两端(其实就是同帧的顶点相连了),这些边构成了时序和空间上的连接。然后在这个图上进行一系列的图卷积运算。
Graph Convolution 作者在本文使用st-gcn作为聚合结点特征的基本单元,可被视为两步基本操作:一个空域图卷积(graph spatial convolution)和一个时域卷积( temporal convolution)。时序卷积Conv_t是直接对每个关节的时间维度进行标准的卷积运算,而每个时间点(每帧)对骨架进行空间图卷积。具体公式如下,f_in为输入的特征向量:
f_s为空间图卷积的输出,更详细的为:
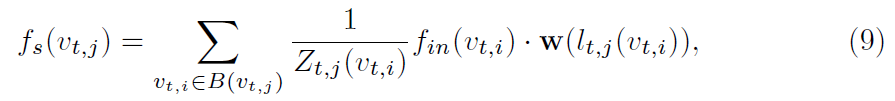
其中B(v_t,j)表示结点v_t,j 的邻居结点集合,l_t,j 将邻居结点映射到它的子集标签,w根据子集标签采样权值,Z(v)是对应子集的正则项。因为人体的躯干和四肢的活动方式非常不同,这启发作者给予模型空间感知感来区分中心关节和边缘关节。为了使空间结构在三维姿态中凸显出来,作者将邻域划分为三个子集:
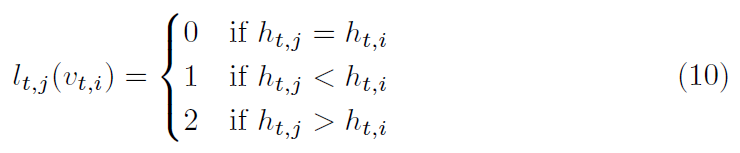
h_t,i 表示结点v_t,i到根节点的跳数,本文髋关节为根节点。
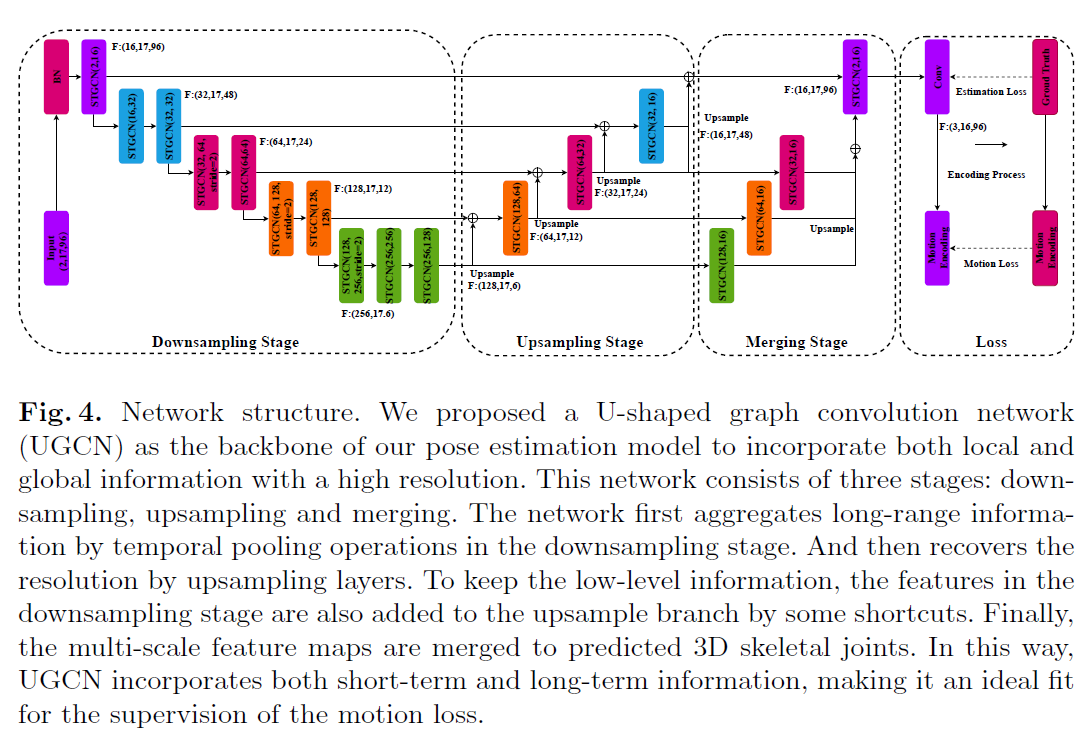
Network structure 如Fig.4所示,为网络架构图。网络基本单元是st-gcn block,包含五个基本操作:空域图卷积、时序卷积、batch normalization、dropout和激活函数ReLu。网络包含三个阶段:下采样、上采用和融合。
在下采样阶段,作者利用9个 st-gcn block用于提取时序信息,另外为了增加感受野,在序数为偶数的blocks中设置stride = 2,这一阶段嵌入了所有skeleton sequence的全局信息。
在上采样阶段,包含4个st-gcn block,每个block后跟随一个上采用层,由于st-graph是规则时序结构,上采样能够通过下式轻易执行:

接连的上采样操作,使得时序分辨率逐渐恢复且扩散至全图(full graph)。由于二维输入投影得到3D输出,底层信息(low-level information)为三维姿态估计提供了很强的几何约束,这驱使作者在网络中保留这些底层信息,因此作者将第一阶段的特征添加到了具有相同时间分辨率的上采样阶段。
在融合阶段,在第二阶段包含不同时间尺度的特征映射图(feature maps)被转化为同样的shape并融合得到最终的embedding。显然,这个embedding在多个时间尺度上包含了丰富的信息。
最后,利用st-gcn regressor估计各关键带你的三维坐标。
Traning & inference 训练时,作者设置st-gcn的temporal kernel为5,dropout为0.5。网络以96帧的2D pose sequence为输入,motion loss的\lamda设置为1,优化器使用Adam,110 epochs, 256大小的batch size,初始学习率为0.01,在80,90,100epochs衰减0.1,为避免过拟合,卷积层参数的权值衰减因子设置为10^-5。
reference阶段,采用步长为5的滑动窗口算法来估计一个固定输入长度的变长姿态序列,并在不同的时间位置上对所有结果取平均。
4.Experiment
4.1 Dataset
Human3.6M
MPI-INF-3DHP
4.2 Evaluation Metric
mean per joint position error(MPJPE)
the area under the curve (AUC)
the percentage of correct key-points(PCK)
4.3 Ablation Study
Effect of motion loss.
在H3.6M上进行消融实验,主要是为了证明UGCN和motion loss的有效性,此部分实验以2D ground-truth作为输入。
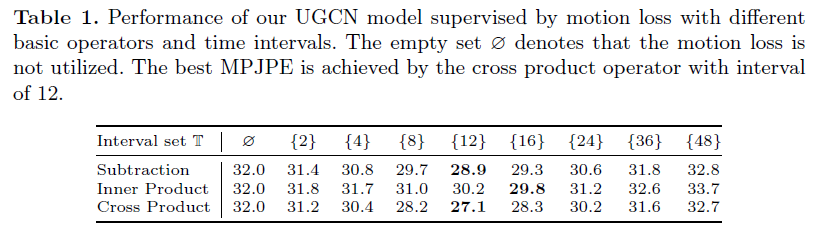
研究motion loss的影响时,对时间间隔t(\Tau)控制不同尺度,对多种算子进行了不同的实验,得到了Table1所示结果,向量积的MPJPE error最小,t的取值上,MPJPE error先减小后增大,说明不能太大也不能太小。
Design choices in UGCN
研究U型架构的影响,从一开始没有到逐对增加,观得如Table3所示结果,实验表明U型结构对实验影响重大,在使用motion loss进行监督的情况下获得了更大的增益。
4.4 Comparison with state-of-the-art
Results on Human3.6M
主要是一些结果对比,2D pose是由CPN得到的,平均效果和子动作的效果都是最好的
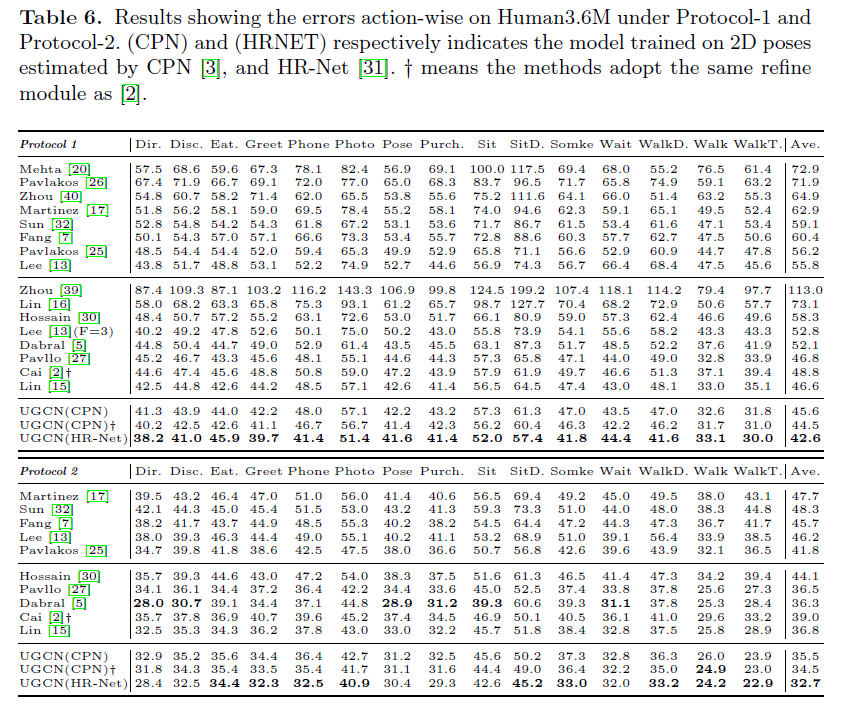
2D sequence以ground truh为输入的结果:
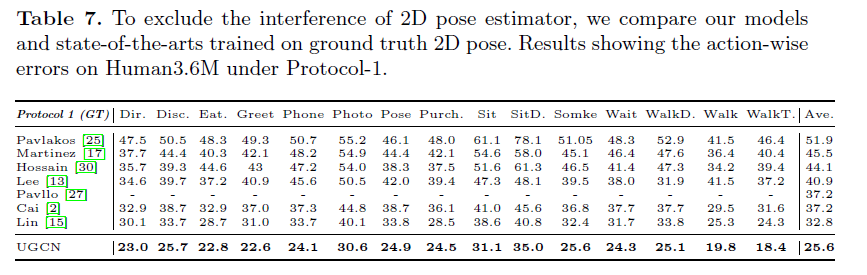
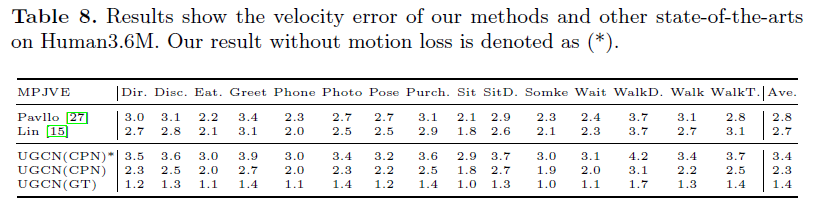
MPJVE评估预测的三维姿态序列的动态质量,表示预测姿态序列的平滑性,结果如下:
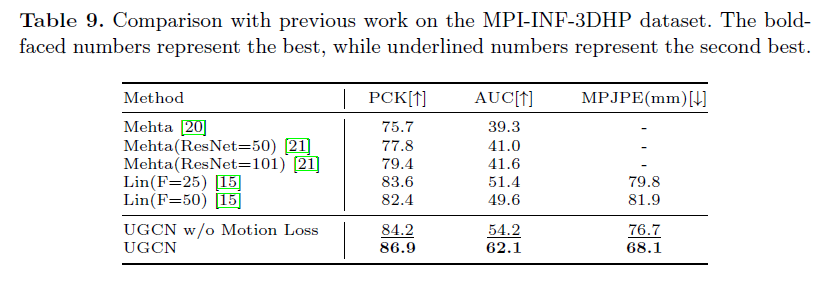
Results on MPI-INF-3DHP
在另一个数据集上的表现:
4.5 Visualization results
作者截取了一些高难度动作,进行可视化展示,以此表明方法的有效性,如Fig 5所示:

5. Conclusion
本文,作者提出了一个新的目标函数——motion loss,它明确的将运动建模引入到了学习过程,为了在该目标函数下更好的优化模型,3D姿态评估需要更长期的骨架序列感知,于是作者设计了U-shaped模型用于捕捉骨架序列的长短时信息。在两个大新数据集上,作者的模型都实现了SOTA效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号