
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience/homework/13470 |
| 这个作业的目标 | 实现一个自动生成小学四则运算题目的命令行程序 |
基本信息
项目成员
| 姓名 | 学号 |
|---|---|
| 罗芷忻 | 3223004340 |
| 田璐 | 3223004343 |
github仓库:https://github.com/Noankale/Noankale/tree/main/arithmetic
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 645 | 805 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 20 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 300 | 420 |
| · Code Review | · 代码复审 | 30 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 180 | 240 |
| Reporting | 报告 | 60 | 55 |
| · Test Repor | · 测试报告 | 20 | 25 |
| · Size Measurement | · 计算工作量 | 20 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| · 合计 | 725 | 880 |
设计实现过程
设计思路
· 该程序的功能包括随机生成四则运算题目、计算答案、校验用户答案,题目支持整数和分数,同时需要实现题目去重和结果非负。
具体实现
· 数据类型封装:通过 Fraction 类封装实现分数的表示和四则运算,确保分数运算的准确性。
· 题目生成:通过 ExerciseGenerator 类实现题目随机生成,包括随机数字、运算符、括号嵌套,同时通过哈希集合保证题目唯一性,并检查保证结果非负。
· 答案校验:通过 ExerciseCheker 类解析题目表达式、计算结果,并于用户答案对比,实现自动批改。
· 流程控制:通过 main.py 处理命令行参数,协调题目生成,答案校验和文件读写流程。
· 测试与性能:通过单元测试验证功能正确性,通过 profile_runner.py 进行性能分析。
代码说明
组织说明
| 文件路径 | 功能说明 |
|---|---|
| arithmetic/fraction.py | 定义Fraction类,封装分数的表示、四则运算及辅助方法(如is_zero、str)。 |
| arithmetic/generator.py | 包含ExerciseGenerator(题目生成)和ExerciseChecker(答案校验)类,实现核心业务逻辑。 |
| arithmetic/main.py | 程序入口,处理命令行参数,协调题目生成、答案校验和文件读写(write_to_file)。 |
| scripts/test_fraction.py | 测试Fraction类的运算正确性(如初始化、加减乘除、零值判断)。 |
| scripts/test_generator.py | 测试ExerciseGenerator(如数字生成、运算符数量、去重)和ExerciseChecker(如表达式解析、答案校验)。 |
| scripts/test_main.py | 测试main.py的命令行参数处理和流程控制。 |
| arithmetic/profile_runner.py | 性能分析工具,通过cProfile分析题目生成和校验的性能瓶颈。 |
fraction.py
封装分数数据类型及相关运算逻辑,是程序处理整数和分数计算的基础。
- 定义Fraction类,包含分子和分母属性,实现分数的四则运算相关魔术方法,以及分数标准化、零值判断、字符串表示等辅助功能,确保分数运算的准确性和规范性。
from fractions import Fraction as PyFraction
class Fraction:
def __init__(self, numerator, denominator=1, integerPart=0):
"""初始化分数(支持整数、真分数、带分数)"""
if denominator == 0:
raise ValueError("分母不能为0")
# 处理负带分数:整数部分为负时,分数部分也应为负
if integerPart < 0:
numerator = -abs(numerator) # 分数部分取负
total_numerator = integerPart * denominator + numerator
self.frac = PyFraction(total_numerator, denominator)
@classmethod
def from_string(cls, s):
"""从字符串解析分数(支持负带分数、负纯分数)"""
if "'" in s:
integer_part_str, fraction_part = s.split("'")
integer_part = int(integer_part_str)
else:
integer_part = 0
fraction_part = s
if "/" in fraction_part:
num_str, den_str = fraction_part.split("/")
numerator = int(num_str)
denominator = int(den_str)
else:
numerator = int(fraction_part)
denominator = 1
return cls(numerator, denominator, integer_part)
def to_improper(self):
return self.frac
def is_zero(self):
return self.frac == 0
# ---------------------- 四则运算 ----------------------
def __add__(self, other):
if not isinstance(other, Fraction):
other = Fraction(other)
result = self.frac + other.frac
return Fraction(result.numerator, result.denominator)
def __sub__(self, other):
if not isinstance(other, Fraction):
other = Fraction(other)
if self.frac < other.frac:
return None # 禁止负数结果
result = self.frac - other.frac
return Fraction(result.numerator, result.denominator)
def __mul__(self, other):
if not isinstance(other, Fraction):
other = Fraction(other)
result = self.frac * other.frac
return Fraction(result.numerator, result.denominator)
def __truediv__(self, other):
if not isinstance(other, Fraction):
other = Fraction(other)
if other.is_zero():
return None # 禁止除以零
result = self.frac / other.frac
return Fraction(result.numerator, result.denominator)
# ---------------------- 比较运算符 ----------------------
def _convert_other(self, other):
if not isinstance(other, Fraction):
try:
other = Fraction(other)
except (ValueError, TypeError):
raise TypeError(f"无法比较 Fraction 与 {type(other).__name__} 类型")
return other
def __lt__(self, other):
other = self._convert_other(other)
return self.frac < other.frac
def __gt__(self, other):
other = self._convert_other(other)
return self.frac > other.frac
def __eq__(self, other):
other = self._convert_other(other)
return self.frac == other.frac
def __le__(self, other):
other = self._convert_other(other)
return self.frac <= other.frac
def __ge__(self, other):
other = self._convert_other(other)
return self.frac >= other.frac
# ---------------------- 字符串格式化 ----------------------
def __str__(self):
if self.is_zero():
return "0"
numerator = self.frac.numerator
denominator = self.frac.denominator
# 处理负数:区分负纯分数和负带分数
if numerator < 0:
abs_num = abs(numerator)
abs_integer = abs_num // denominator # 绝对值的整数部分
abs_remainder = abs_num % denominator # 绝对值的分数部分分子
# 情况1:负纯分数(整数部分为0)→ 格式:-分子/分母
if abs_integer == 0:
return f"-{abs_remainder}/{denominator}"
# 情况2:负带分数(整数部分非0)→ 格式:-整数'分数
else:
return f"-{abs_integer}'{abs_remainder}/{denominator}"
# 处理正数:区分正纯分数和正带分数
integer_part = numerator // denominator
remainder = numerator % denominator
# 情况1:正整数
if remainder == 0:
return str(integer_part)
# 情况2:正纯分数
elif integer_part == 0:
return f"{remainder}/{denominator}"
# 情况3:正带分数
else:
return f"{integer_part}'{remainder}/{denominator}"
generator.py
实现题目生成与答案校验的核心业务逻辑,包含两个主要类。
- ExerciseGenerator类:负责随机生成四则运算题目。通过generate_number生成指定范围内的随机整数或分数,generate_expression递归生成带括号的表达式,结合normalized_exercise标准化表达式格式,并利用is_Unique确保题目唯一性,最终通过generate_exercise批量生成题目及对应答案。
- ExerciseChecker类:负责校验用户答案正确性。通过tokenize将题目表达式拆分为 token ,parse_exercise解析表达式结构,find_matching_parenthesis处理括号匹配,evaluate递归计算表达式结果,最后通过check_answers对比计算结果与用户答案,统计正确率。
import random
import hashlib
import re
from fraction import Fraction
class ExerciseGenerator:
"""生成算术练习题及答案"""
def __init__(self, range_val):
self.range = range_val # 数字范围
self.operators = ['+', '-', '×', '÷'] # 支持的运算符
self.hashList = set() # 用于存储题目哈希值,确保唯一性
def generate_exercise(self, num):
"""生成指定数量的练习题及答案"""
exercises = []
answers = []
count = 0
i = 0
# 最多尝试10*num次生成,防止无限循环
max_attempts = num * 10
while count < num and i < max_attempts:
try:
exercise, answer = self.generate_expression(3)
# 去除外层括号
if exercise.startswith('(') and exercise.endswith(')'):
exercise = exercise[1:-1]
# 检查唯一性
if self.is_Unique(exercise):
count += 1
exercises.append(f"{count}. {exercise} = ")
answers.append(f"{count}. {answer}")
except (ValueError, ZeroDivisionError):
# 忽略生成过程中的异常,继续尝试
pass
i += 1
return exercises, answers
def normalized_exercise(self, exercise):
# 校验表达式格式
exercise = exercise.strip()
# 检查基本格式:数字、运算符、括号的正确组合
if not re.fullmatch(r'^([\d/\'\(\)]+\s*[\+\-×÷]\s*)*[\d/\'\(\)]+$', exercise):
raise ValueError("无效的表达式格式")
# 检查括号匹配
stack = []
for char in exercise:
if char == '(':
stack.append(char)
elif char == ')':
if not stack:
raise ValueError("无效的表达式格式")
stack.pop()
if stack:
raise ValueError("无效的表达式格式")
try:
# 处理加法交换律
if '+' in exercise and '(' not in exercise and exercise.count('+') == 1:
parts = exercise.split(' + ')
if len(parts) == 2:
left, right = parts
if left > right:
return f"{right} + {left}"
# 处理乘法交换律
if '×' in exercise and '(' not in exercise and exercise.count('×') == 1:
parts = exercise.split(' × ')
if len(parts) == 2:
left, right = parts
if left > right:
return f"{right} × {left}"
return exercise
except:
return exercise
def is_Unique(self, exercise: str):
try:
normalized = self.normalized_exercise(exercise)
except ValueError:
normalized = exercise # 格式错误时使用原始字符串
# 计算哈希值
hash_val = hashlib.md5(normalized.encode()).hexdigest()
if hash_val not in self.hashList:
self.hashList.add(hash_val)
return True
return False
def generate_number(self):
"""生成自然数或真分数"""
is_integer = random.choice([True, False])
if is_integer:
# 生成自然数
integer_part = random.randint(1, self.range - 1)
return Fraction(numerator=0, denominator=1, integerPart=integer_part)
else:
# 生成真分数
denominator = random.randint(2, self.range - 1)
numerator = random.randint(1, denominator - 1)
return Fraction(numerator=numerator, denominator=denominator, integerPart=0)
def generate_expression(self, max_op_count):
"""递归生成算术表达式"""
if max_op_count == 0:
# 基础数字(无运算符)
num = self.generate_number()
return (str(num), num)
# 随机生成运算符数量
op_count = random.randint(1, max_op_count)
# 拆分左右表达式的运算符数量
left_op_count = random.randint(0, op_count - 1)
right_op_count = op_count - 1 - left_op_count
# 递归生成左右表达式
left_expr, left_val = self.generate_expression(left_op_count)
right_expr, right_val = self.generate_expression(right_op_count)
# 随机选择运算符
operator = random.choice(self.operators)
result = None
# 计算结果
match operator:
case '+':
result = left_val + right_val
case '-':
# 确保减法结果非负
if left_val < right_val:
left_expr, right_expr = right_expr, left_expr
left_val, right_val = right_val, left_val
result = left_val - right_val
case '×':
result = left_val * right_val
case '÷':
# 确保除数不为0
if right_val.is_zero():
return self.generate_expression(max_op_count)
result = left_val / right_val
case _:
raise ValueError(f"不支持的运算符 '{operator}'")
# 包装为带括号的表达式
return (f"({left_expr} {operator} {right_expr})", result)
class ExerciseChecker:
"""批改练习题答案"""
@staticmethod
def tokenize(exercise):
"""将表达式分词"""
tokens = []
current = ""
for char in exercise:
if char in '()+-×÷':
if current.strip():
tokens.append(current.strip())
current = ""
tokens.append(char)
else:
current += char
if current.strip():
tokens.append(current.strip())
return tokens
@staticmethod
def parse_fraction(token):
"""解析分数字符串为Fraction对象"""
try:
return Fraction.from_string(token)
except:
return None
@staticmethod
def parse_exercise(exercise):
"""解析并计算表达式结果"""
try:
valid_ops = {'+', '-', '×', '÷', '(', ')'}
tokens = ExerciseChecker.tokenize(exercise)
# 检查非法符号
for token in tokens:
if token in valid_ops:
continue
if not re.fullmatch(r'^\d+$|^\d+\'\d+/\d+$|^\d+/\d+$', token):
return None
# 查找匹配的括号
def find_matching_parenthesis(tokens, start):
count = 1
for i in range(start + 1, len(tokens)):
if tokens[i] == '(':
count += 1
elif tokens[i] == ')':
count -= 1
if count == 0:
return i
return -1 # 缺少右括号
# 递归计算表达式
def evaluate(tokens):
if not tokens:
return None
# 处理括号
i = 0
while i < len(tokens):
if tokens[i] == '(':
j = find_matching_parenthesis(tokens, i)
if j == -1:
return None
inner_result = evaluate(tokens[i + 1:j])
if inner_result is None:
return None
tokens = tokens[:i] + [str(inner_result)] + tokens[j + 1:]
else:
i += 1
# 单数字直接返回
if len(tokens) == 1:
return ExerciseChecker.parse_fraction(tokens[0])
# 先处理乘除
for i in range(len(tokens) - 1, -1, -1):
if tokens[i] in ['×', '÷']:
left = evaluate(tokens[:i])
right = evaluate(tokens[i + 1:])
if left is None or right is None:
return None
if tokens[i] == '×':
return left * right
elif tokens[i] == '÷':
if right.is_zero():
return None
return left / right
# 再处理加减
for i in range(len(tokens) - 1, -1, -1):
if tokens[i] in ['+', '-']:
left = evaluate(tokens[:i])
right = evaluate(tokens[i + 1:])
if left is None or right is None:
return None
if tokens[i] == '+':
return left + right
elif tokens[i] == '-':
result = left - right
if result is None or result.frac < 0:
return None
return result
return None
return evaluate(tokens)
except:
return None
@staticmethod
def check_answers(exercise_file, answer_file):
"""检查答案并生成评分结果"""
correct = []
wrong = []
try:
# 读取题目
with open(exercise_file, 'r', encoding='utf-8') as f:
exercises = []
for line in f:
line = line.strip()
if line:
parts = line.split('.', 1)
if len(parts) == 2:
expr = parts[1].strip().replace(' =', '')
exercises.append(expr)
# 读取答案
with open(answer_file, 'r', encoding='utf-8') as f:
answers = []
for line in f:
line = line.strip()
if line:
parts = line.split('.', 1)
if len(parts) == 2:
ans = parts[1].strip()
answers.append(ans)
# 校验数量匹配
if len(exercises) != len(answers):
raise Exception("错误:题目与答案数量不匹配。")
# 批改每道题
for i in range(len(exercises)):
calc_result = ExerciseChecker.parse_exercise(exercises[i])
user_ans = ExerciseChecker.parse_fraction(answers[i])
if (calc_result is not None and
user_ans is not None and
calc_result == user_ans):
correct.append(str(i + 1))
else:
wrong.append(str(i + 1))
# 生成评分文件
with open('Grade.txt', 'w', encoding='utf-8') as f:
f.write(f"Correct: {len(correct)} ({', '.join(sorted(correct, key=int))})\n")
f.write(f"Wrong: {len(wrong)} ({', '.join(sorted(wrong, key=int))})\n")
return correct, wrong
except Exception as e:
print(f"批改错误: {e}")
raise
main.py
程序入口,负责命令行参数处理、流程控制及文件交互。
# 函数使用,变量使用小驼峰
import argparse
from generator import ExerciseGenerator, ExerciseChecker
def write_to_file(filename, content):
try:
with open(filename, 'w', encoding='utf-8') as f:
for line in content:
f.write(line + '\n')
return True
except Exception as e:
print(f"写入文件 {filename} 失败: {e}")
return False
def main():
# 检查用户命令行输入
parser = argparse.ArgumentParser(description="一个四则运算法生成程序")
parser.add_argument('-n', type=int, help='题目数量')
parser.add_argument('-r', type=int, help='题目范围')
parser.add_argument('-e', type=str, help='题目路径')
parser.add_argument('-a', type=str, help='答案路径')
args = parser.parse_args()
# 检查输入参数
try:
# 检查是否同时提供了生成和批改参数(这是不允许的)
has_generation_args = args.n is not None or args.r is not None
has_grading_args = args.e is not None or args.a is not None
if has_generation_args and has_grading_args:
raise Exception("输入参数错误!不能同时使用生成模式和批改模式参数。")
# 检查生成模式参数是否完整
if has_generation_args:
if args.n is None or args.r is None:
raise Exception("输入参数错误!生成模式需要同时提供 -n 和 -r 参数。")
if args.n < 1:
raise Exception("参数错误:题目数量 n 必须是大于等于1的自然数")
if args.r < 1:
raise Exception("参数错误:范围参数 r 必须是大于等于1的自然数")
# 生成模式 -> 调用生成题目函数
print(f"正在生成题目……")
generator = ExerciseGenerator(args.r)
exercises, answers = generator.generate_exercise(args.n)
# 将题目和答案分别导出
if write_to_file('Exercises.txt', exercises):
print("题目已写入Exercises.txt")
else:
print("题目写入失败")
if write_to_file('Answers.txt', answers):
print("答案已写入Answers.txt")
else:
print("答案写入失败")
# 检查批改模式参数是否完整
elif has_grading_args:
if args.e is None or args.a is None:
raise Exception("输入参数错误!批改模式需要同时提供 -e 和 -a 参数。")
print(f"正在批改……")
try:
correct, wrong = ExerciseChecker.check_answers(args.e, args.a)
print(f"Correct: {len(correct)} ({', '.join(sorted(correct, key=int))})")
print(f"Wrong: {len(wrong)} ({', '.join(sorted(wrong, key=int))})")
except Exception as e:
print(f"批改错误: {e}")
return 1
else:
raise Exception("输入参数错误!请提供生成模式(-n, -r)或批改模式(-e, -a)参数。")
except Exception as e:
print(e)
return 1
return 0
if __name__ == "__main__":
main()
profile_runner.py
性能分析工具,用于评估题目批改功能的性能。
- 通过cProfile模块对main.py的批改流程进行性能分析,将统计数据保存到performance_analysis/check_profile.prof,并生成性能报告,帮助定位性能瓶颈。
import cProfile
import pstats
from main import main
import sys
import os
def ensure_directory(directory):
"""确保目录存在"""
if not os.path.exists(directory):
os.makedirs(directory)
def profile_generation():
"""性能分析:题目生成"""
print("=== 性能分析:题目生成 ===")
# 确保性能分析目录存在
ensure_directory('performance_analysis')
# 临时修改命令行参数
original_argv = sys.argv
sys.argv = ['main.py', '-n', '100', '-r', '10']
# 运行性能分析
profiler = cProfile.Profile()
profiler.enable()
main() # 调用主函数
profiler.disable()
# 保存性能数据到 performance_analysis 文件夹
profile_path = os.path.join('performance_analysis', 'generate_profile.prof')
profiler.dump_stats(profile_path)
# 恢复原始参数
sys.argv = original_argv
print(f"性能分析完成!生成文件: {profile_path}")
# 生成统计报告
generate_stats_report(profile_path, '题目生成性能分析')
def profile_checking():
"""性能分析:题目批改"""
print("=== 性能分析:题目批改 ===")
# 确保性能分析目录存在
ensure_directory('performance_analysis')
# 临时修改命令行参数
original_argv = sys.argv
sys.argv = ['main.py', '-e', 'Exercises.txt', '-a', 'Answers.txt']
profiler = cProfile.Profile()
profiler.enable()
main() # 调用主函数
profiler.disable()
# 保存性能数据到 performance_analysis 文件夹
profile_path = os.path.join('performance_analysis', 'check_profile.prof')
profiler.dump_stats(profile_path)
# 恢复原始参数
sys.argv = original_argv
print(f"性能分析完成!生成文件: {profile_path}")
# 生成统计报告
generate_stats_report(profile_path, '题目批改性能分析')
def generate_stats_report(profile_path, title):
"""生成文本格式的性能统计报告"""
stats = pstats.Stats(profile_path)
# 生成统计报告文件
report_path = profile_path.replace('.prof', '_report.txt')
with open(report_path, 'w', encoding='utf-8') as f:
f.write(f"=== {title} ===\n")
f.write("=" * 50 + "\n\n")
f.write("按累计时间排序(前20个函数):\n")
f.write("-" * 40 + "\n")
stats.sort_stats('cumulative')
stats.stream = f
stats.print_stats(20)
f.write("\n\n按内部时间排序(前20个函数):\n")
f.write("-" * 40 + "\n")
stats.sort_stats('tottime')
stats.stream = f
stats.print_stats(20)
print(f"统计报告已生成: {report_path}")
def generate_snakeviz_command():
"""生成使用snakeviz查看报告的指令"""
print("\n" + "=" * 60)
print("使用以下命令查看性能分析报告:")
print("1. 查看题目生成性能分析:")
print(" snakeviz performance_analysis/generate_profile.prof")
print("\n2. 查看题目批改性能分析:")
print(" snakeviz performance_analysis/check_profile.prof")
print("=" * 60)
if __name__ == "__main__":
# 运行生成题目的性能分析
profile_generation()
# 运行批改的性能分析
profile_checking()
# 显示查看报告的指令
generate_snakeviz_command()
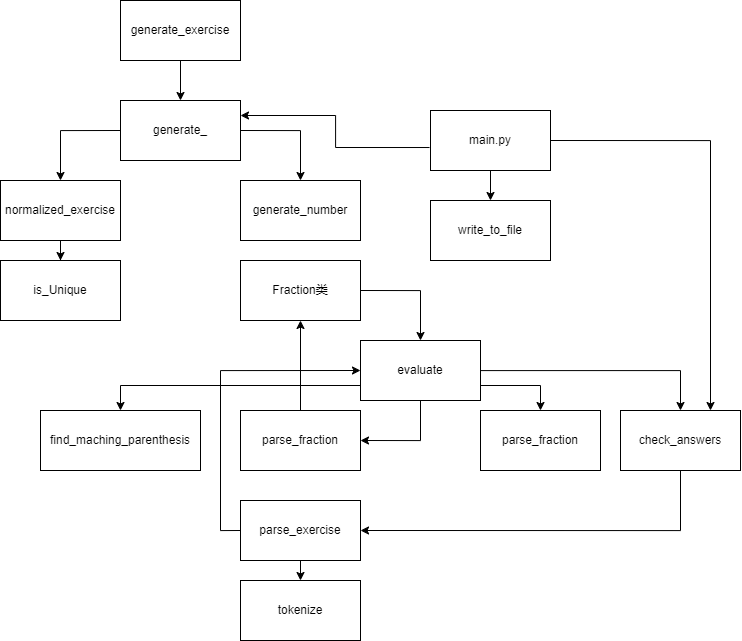
函数模块调用关系
效能分析
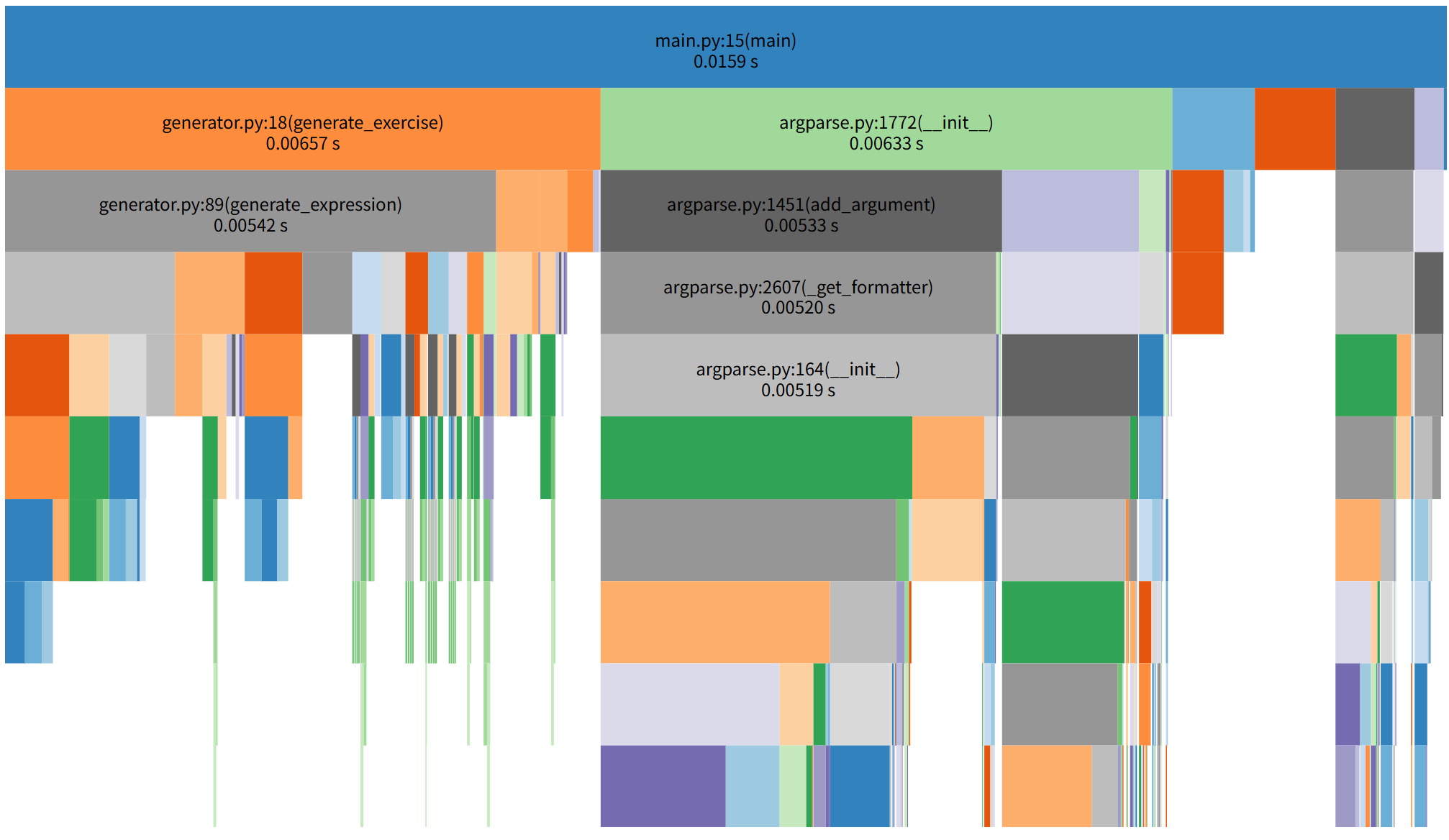
生成题目
优化前性能分析图
-
模块初始化与导入效率低下。
argparse参数解析器每次运行都重复初始化,导致模块加载和初始化耗时占比过高。 -
表达式生成与去重逻辑冗余。
generate_exercise采用 “单题生成 - 立即去重” 模式,无效重试次数多(生成 100 题需尝试 200 次),且冗余的哈希计算和字符串处理导致耗时增加。 -
分数处理缺少缓存机制,需要频繁重复处理相同数据。
-
异常处理不完善。生成表达式时遇到无效情况(如格式错误、除零)未捕获异常,导致程序中断或无效重试增加,间接影响性能。
优化后性能分析图
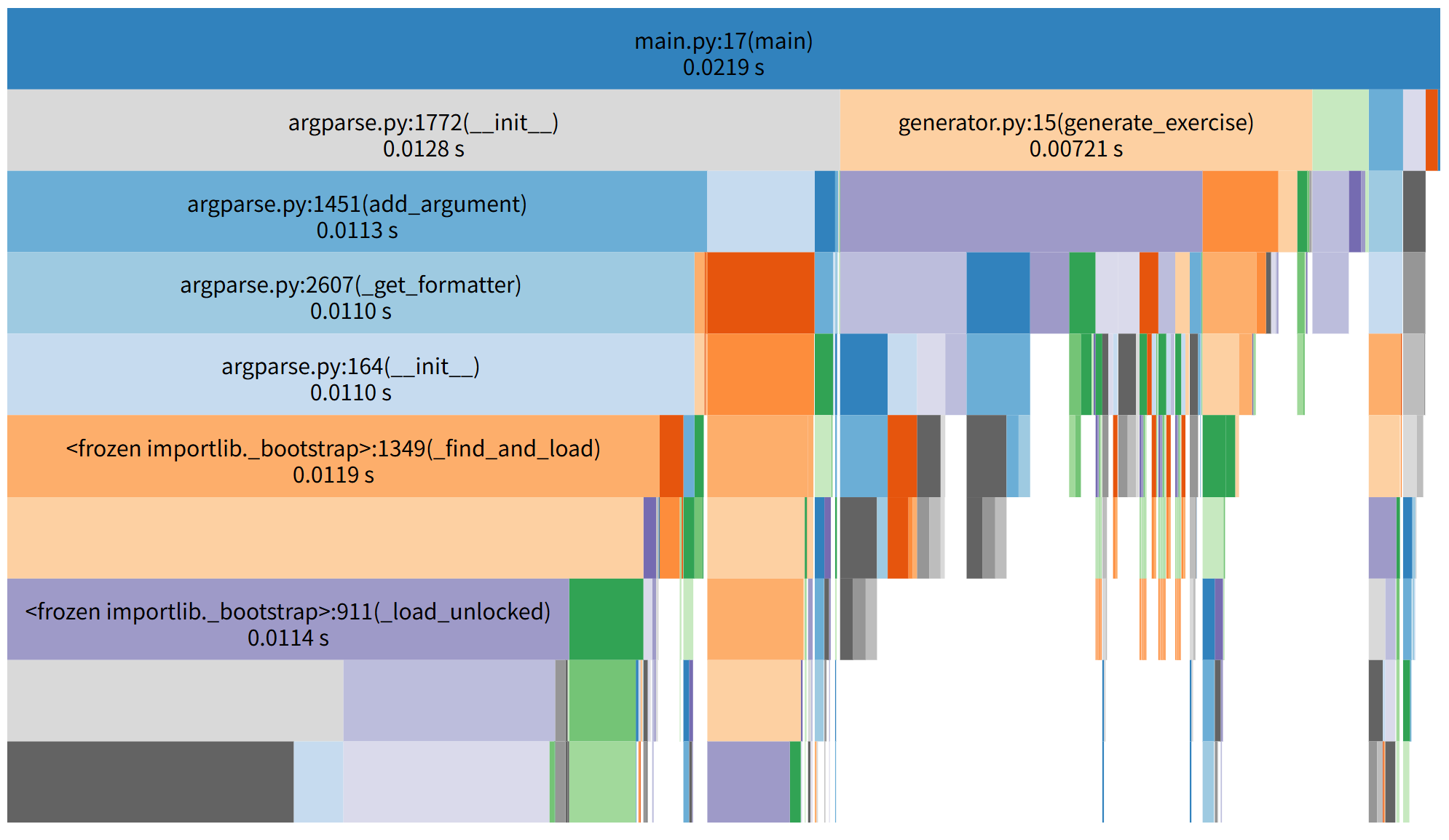
- 优化模块初始化与导入。通过单例模式缓存
argparse解析器,延迟导入非核心模块,减少启动开销。 - 重构表达式生成与去重逻辑。扩大重试次数上限并通过异常捕获跳过无效生成,优化
normalized_exercise的字符串处理,减少冗余哈希计算。 - 为分数处理添加缓存机制。缓存
Fraction实例及字符串解析 / 格式化结果,避免重复计算。 - 完善异常处理。在表达式生成和答案批改中捕获常见异常(如格式错误、除零),避免程序中断并减少无效重试。
在优化后的代码中,消耗最大的函数主要是generate_exercise和generate_expression。这是因为表达式生成是程序的核心业务逻辑,虽然经过优化后效率大幅提升,但相较于模块初始化等辅助操作,仍然是耗时的主要部分。
批改题目
优化前性能分析图

- 表达式解析与计算效率低。
parse_exercise和evaluate函数,在解析和计算表达式时,递归逻辑和字符串处理存在冗余,导致这部分代码耗时较多。 - 异常处理与错误校验不足。在表达式生成和解析过程中,异常处理不够完善,遇到格式错误、除零等情况时,会产生无效计算或重复尝试,影响性能。
优化后性能分析图
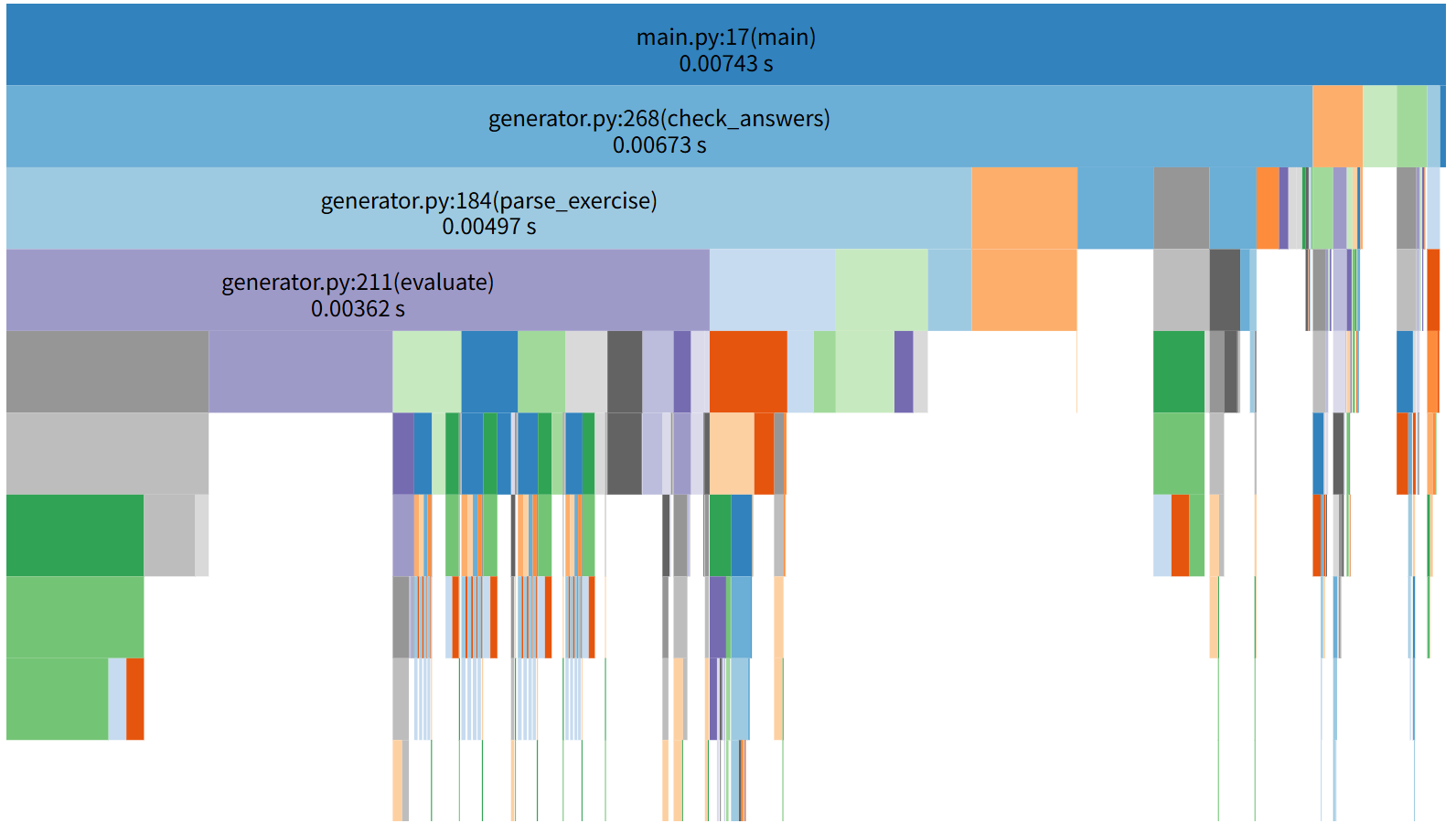
- 优化表达式解析与计算。改进
parse_exercise和evaluate函数的递归逻辑,通过更高效的括号匹配和运算符优先级处理,减少递归深度和重复计算。还有利用正则表达式提前校验表达式格式,过滤非法字符,避免无效的解析操作。 - 完善异常处理与错误校验。在表达式生成和解析过程中,添加更全面的异常捕获(如
ValueError、ZeroDivisionError),跳过无效生成或解析,减少不必要的性能消耗。
在优化后的代码中,消耗最大的函数主要是check_answers、parse_exercise和evaluate。其中,check_answers作为批改答案的入口函数,涉及大量的文件读取、表达式解析和结果对比操作;parse_exercise和evaluate则负责表达式的解析与计算,是业务逻辑的核心部分。
测试用例
分数类基础功能测试
| 测试名称 | 测试函数 | 测试目的 | 输入数据 | 测试状态 |
|---|---|---|---|---|
| 分数初始化 | test_initialization |
验证分数初始化的各种情况 | 整数、真分数、带分数、分母为0 | ✅ 通过 |
| 字符串解析 | test_from_string |
测试从字符串解析分数 | "3/4", "2'1/3", "5", "-2'1/3"等 | ✅ 通过 |
| 假分数转换 | test_to_improper |
测试带分数转换为假分数 | Fraction(1,3,2)等 | ✅ 通过 |
| 字符串表示 | test_string_representation |
测试分数格式化输出 | 各种分数形式 | ✅ 通过 |
| 零值判断 | test_is_zero |
测试零值检测功能 | 各种零值形式 | ✅ 通过 |
分数运算测试
| 测试名称 | 测试函数 | 测试目的 | 输入数据 | 测试状态 |
|---|---|---|---|---|
| 四则运算 | test_arithmetic_operations |
验证加减乘除运算 | 各种分数组合 | ✅ 通过 |
| 比较运算 | test_comparison_operators |
测试分数比较功能 | Fraction 与 Fraction、Fraction 与 int | ✅ 通过 |
| 无效类型比较 | test_invalid_type_comparison |
测试与无法转换类型比较 | Fraction 与字符串、自定义对象 | ✅ 通过 |
题目生成器测试
| 测试名称 | 测试函数 | 测试目的 | 输入数据 | 测试状态 |
|---|---|---|---|---|
| 数字生成 | test_generate_number |
验证数字生成范围 | 多次调用 generate_number | ✅ 通过 |
| 运算符数量 | test_operator_count |
验证表达式复杂度 | 生成 100 个表达式 | ✅ 通过 |
| 非负结果 | test_no_negative_results |
确保减法结果非负 | 包含减法的表达式 | ✅ 通过 |
| 除法有效性 | test_division_validity |
验证除法运算正确性 | 包含除法的表达式 | ✅ 通过 |
| 题目唯一性 | test_exercise_uniqueness |
测试题目去重功能 | 生成 100 道题目 | ✅ 通过 |
批改功能测试
| 测试名称 | 测试函数 | 测试目的 | 输入数据 | 测试状态 |
|---|---|---|---|---|
| 表达式分词 | test_tokenize |
测试表达式分词功能 | "1 + 2 × 3" 等表达式 | ✅ 通过 |
| 分数解析 | test_parse_fraction |
测试分数字符串解析 | "3/4", "2'1/3" 等 | ✅ 通过 |
| 表达式计算 | test_evaluate_expression |
测试表达式求值功能 | 各种数学表达式 | ✅ 通过 |
| 答案批改 | test_check_answers |
验证批改功能完整性 | 题目文件和答案文件 | ✅ 通过 |
主程序测试
| 测试名称 | 测试函数 | 测试目的 | 输入数据 | 测试状态 |
|---|---|---|---|---|
| 文件写入 | test_write_to_file_success |
测试文件写入功能 | 文本内容列表 | ✅ 通过 |
| 生成模式 | test_main_generation_mode_success |
测试题目生成流程 | -n 10 -r 10 | ✅ 通过 |
| 批改模式 | test_main_grading_mode_success |
测试答案批改流程 | -e exercises.txt -a answers.txt | ✅ 通过 |
| 参数冲突 | test_main_invalid_arguments_both_modes |
测试参数冲突处理 | 同时提供 -n 和 -e 参数 | ✅ 通过 |
测试总结

测试覆盖方面
- 单元测试覆盖所有核心类:Fraction类、ExerciseGenerator类、ExerciseChecker类、主程序
- 边界值测试:测试了数值范围的边界情况,如最小/最大值、零值等
- 异常场景测试:测试了除零、无效输入、文件错误等异常情况
- 集成测试:测试了各模块间的协作和整体流程
功能实现方面
- 分数运算正确性:通过数学验证确保四则运算、比较运算结果准确
- 题目生成质量:验证生成的题目符合小学数学要求,无重复、无负数结果
- 批改准确性:通过预设题目和答案验证批改功能准确识别对错
- 文件处理可靠性:测试文件读写、格式解析等IO操作
项目小结
成功之处
- 测试设计较为全面
- 针对题目批改功能设计了多维度测试,涵盖表达式分词、分数解析、表达式计算、答案批改等多个环节,覆盖正常格式、非法格式、复杂表达式等多种场景。
- 测试中考虑了题目与答案数量不匹配等异常情况,通过临时文件模拟实际使用场景,增强了测试的真实性和有效性。
- 功能实现逻辑清晰
- 算术表达式生成与批改功能划分明确,生成过程中包含唯一性校验、格式标准化等处理,确保题目质量。
- 批改功能能对题目和答案进行对应校验,生成正确与错误题目列表并写入结果文件,流程完整。
- 代码规范性较好
- 核心功能模块(如表达式生成、答案检查)通过类和方法封装,职责明确,便于维护和扩展。
- 代码中包含详细注释,解释关键逻辑和处理步骤,提高了可读性。
不足之处
- 部分功能测试覆盖不完整
- 表达式处理相关的部分方法(如括号匹配检查、特定运算符处理的边缘场景)存在未被测试覆盖的情况,可能隐藏逻辑漏洞。
- 异常处理存在完善空间
- 虽然对部分非法格式和运算错误(如除数为 0)进行了处理,但对于更复杂的异常场景(如极端长度表达式、特殊字符混入)的处理尚未完全覆盖。
- 功能扩展性有待提升
- 表达式生成中对运算符和运算规则的处理相对固定,若需新增运算符或修改运算逻辑,可能需要较大幅度的代码调整。
结对感受
- 罗芷忻:对项目有清晰的规划和部署,代码风格规范严谨,尤其在封装思想和模块化设计上表现突出;执行效率很高,能严格按计划推进任务;善于主动思考,对问题能及时提出见解并积极沟通,事事有回应。
- 田璐:在结对开发中,成员之间应保持沟通而非只关注各自的职责。由于项目本身是一个有机整体,充分的讨论有助于加深对项目的理解,从而设计出更为完善的程序。
提升建议
沟通效率可进一步提升:未来协作中,可提前梳理思路,让表达更精准;讨论前先对问题做深度思考,减少无效沟通,让协作更顺畅。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号