

处理DataFrame的技巧
DataFrame:
| user_id | name | age | country | score | continent |
|---|---|---|---|---|---|
| 1001 | Mark | 55 | Italy | 4.5 | Europe |
| 1000 | John | 33 | USA | 6.7 | America |
| 1002 | Tim | 41 | USA | 3.9 | America |
| 1003 | Jenny | 12 | Germany | 9 | Europe |
如果在构造DataFrame时没有提供列名,那么pandas会用从0开始的数字为列编号。
user_id name age country score continent
0 1001 Mark 55 Italy 4.5 Europe
1 1000 John 33 USA 6.7 America
2 1002 Tim 41 USA 3.9 America
3 1003 Jenny 12 Germany 9.0 Europe
将某列设为索引
df.reset_index().set_index("user_id")
为列命名
df.columns.name = "properties"
| properties | user_id | name | age | country | score | continent |
|---|---|---|---|---|---|---|
| 0 | 1001 | Mark | 55 | Italy | 4.5 | Europe |
| 1 | 1000 | John | 33 | USA | 6.7 | America |
| 2 | 1002 | Tim | 41 | USA | 3.9 | America |
| 3 | 1003 | Jenny | 12 | Germany | 9.0 | Europe |
修改列名
df.rename(columns={"name":"First Name","age":"Age"})
删除列
df.drop(columns=["name","country"],index = [1000,1003])
| index | age | score | continent |
|---|---|---|---|
| user_id | |||
| 1001 | 0 | 55 | 4.5 |
| 1002 | 2 | 41 | 3.9 |
数据操作
选取数据
使用标签选取数据
df.loc[row_selection, column_selection]
df.loc[column_selection]会返回一个Series
df.iloc[1,2]
用in运算符判断是否包含某些对象
isin方法
df.loc[df["country"].isin(["Italy","Germany"]),:]
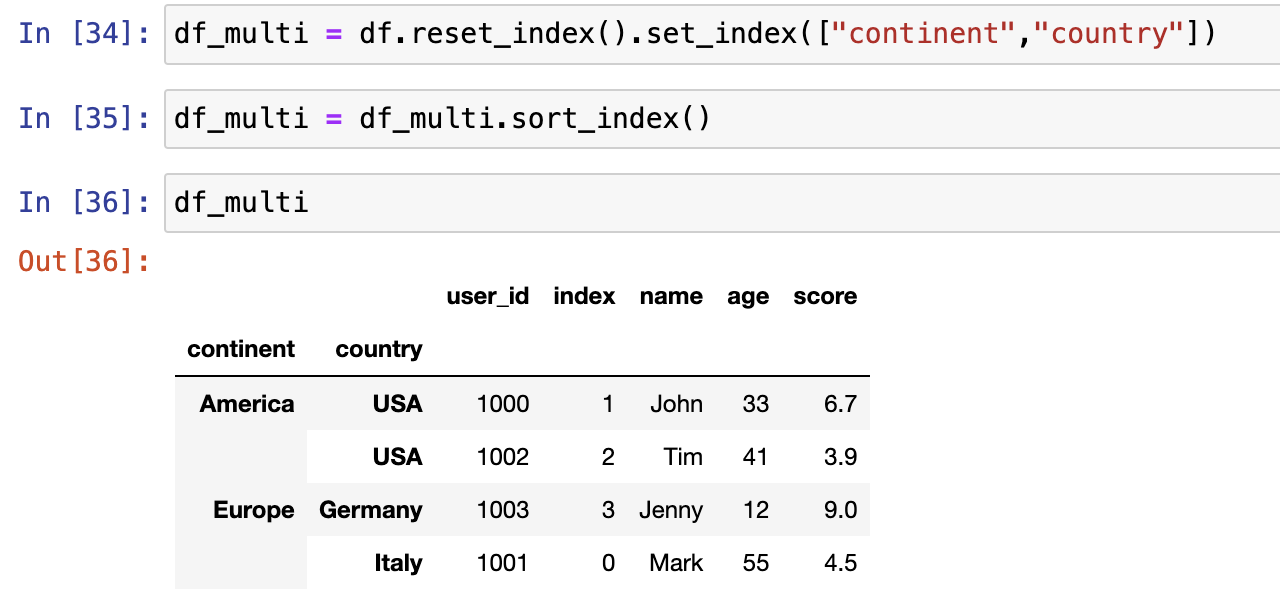
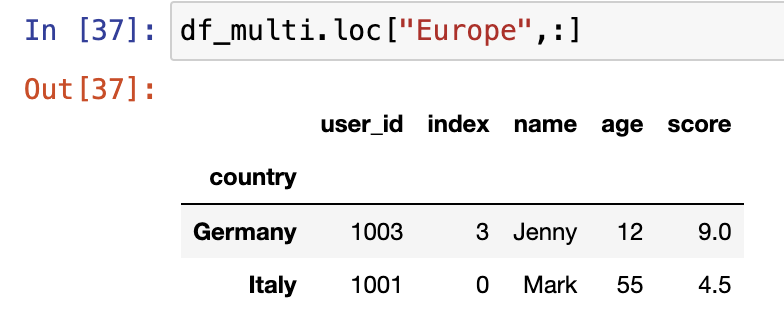
使用MultiIndex选取数据
df.reset_index().set_index(["continent","country"])
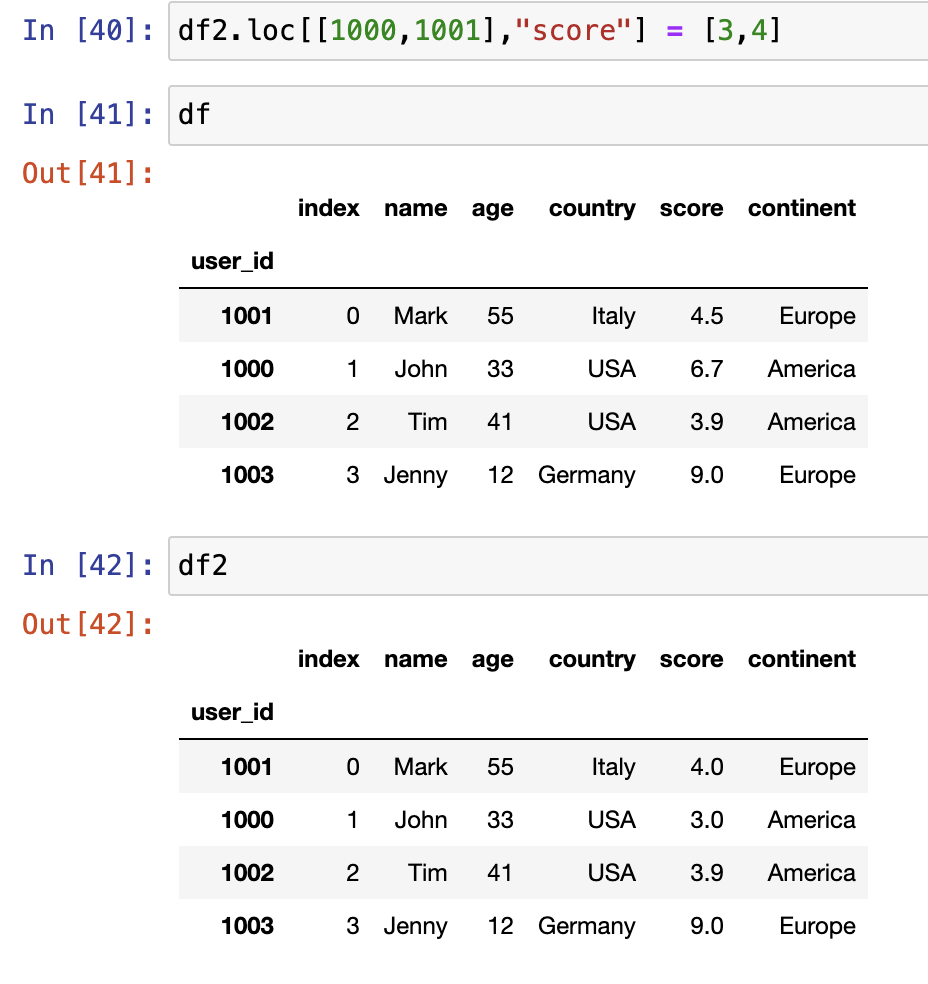
如何批量赋值
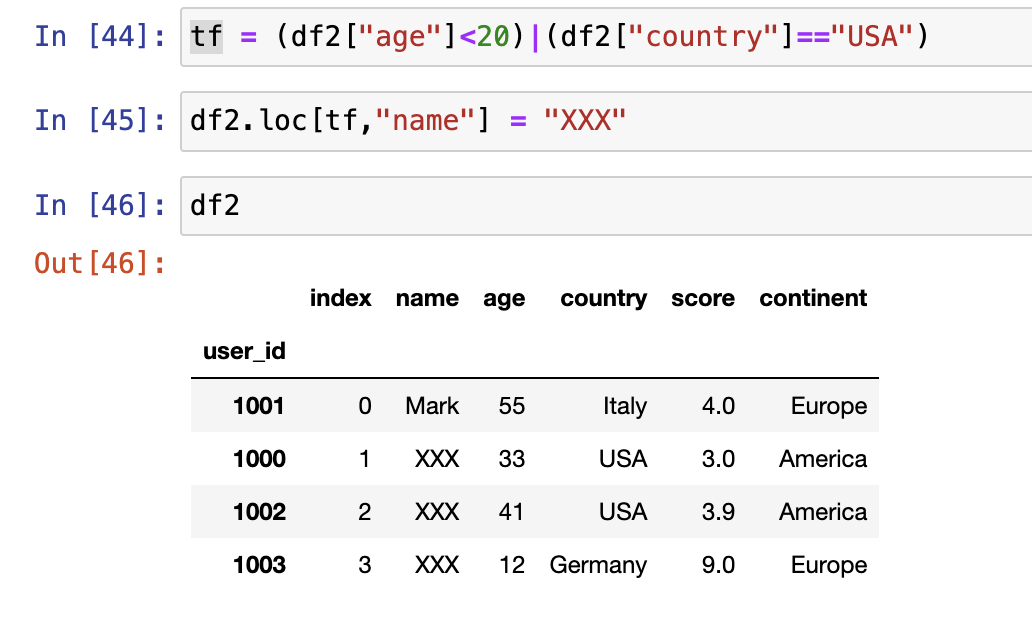
通过布尔索引设置数据
通过添加新列设置数据
添加新列还能增加筛选条件
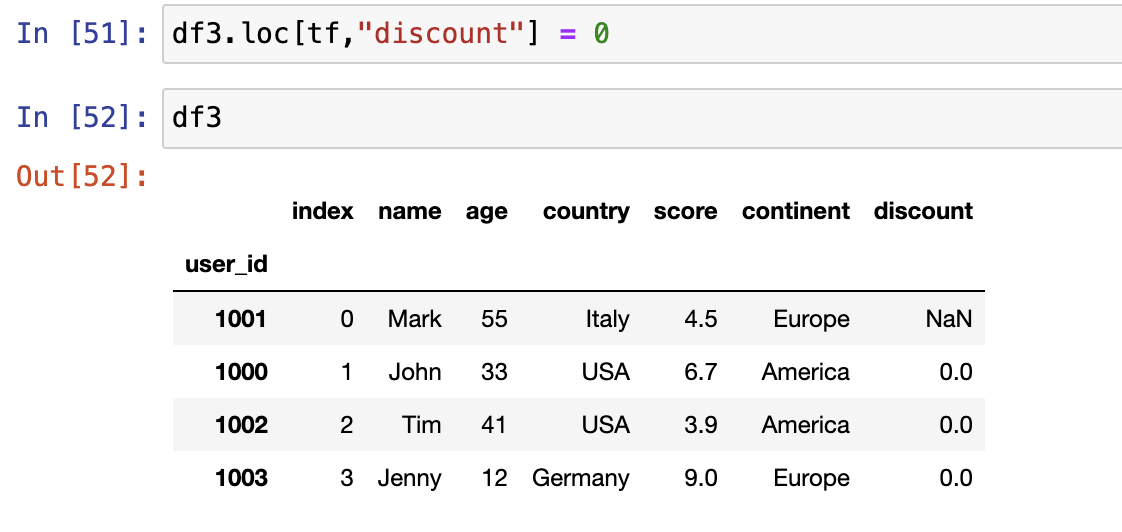
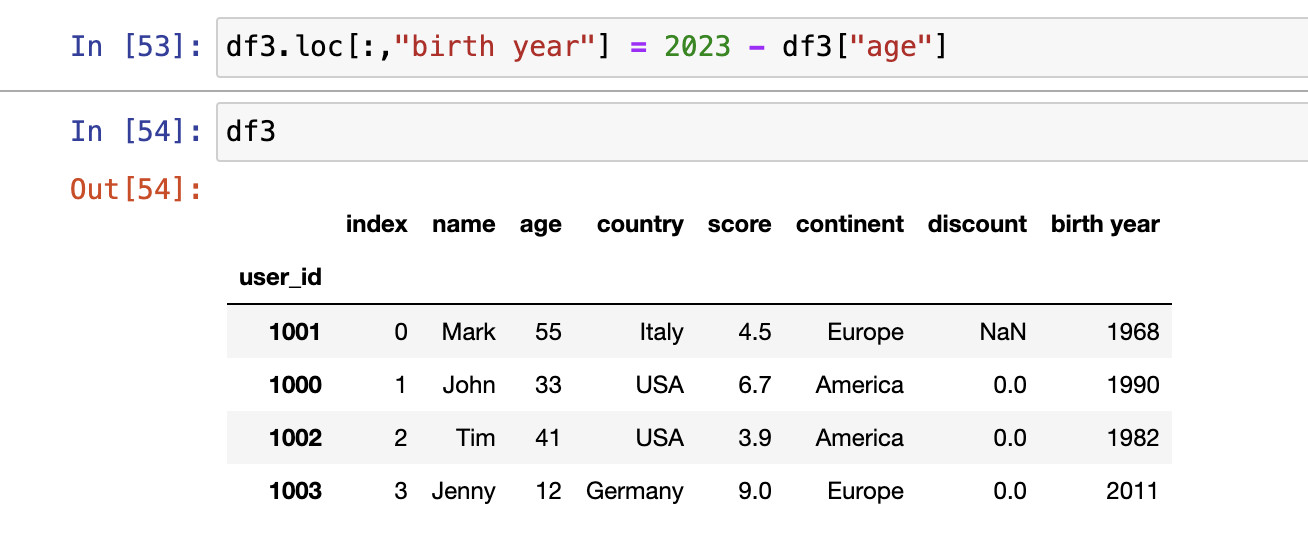
添加新列时还涉及向量化运算
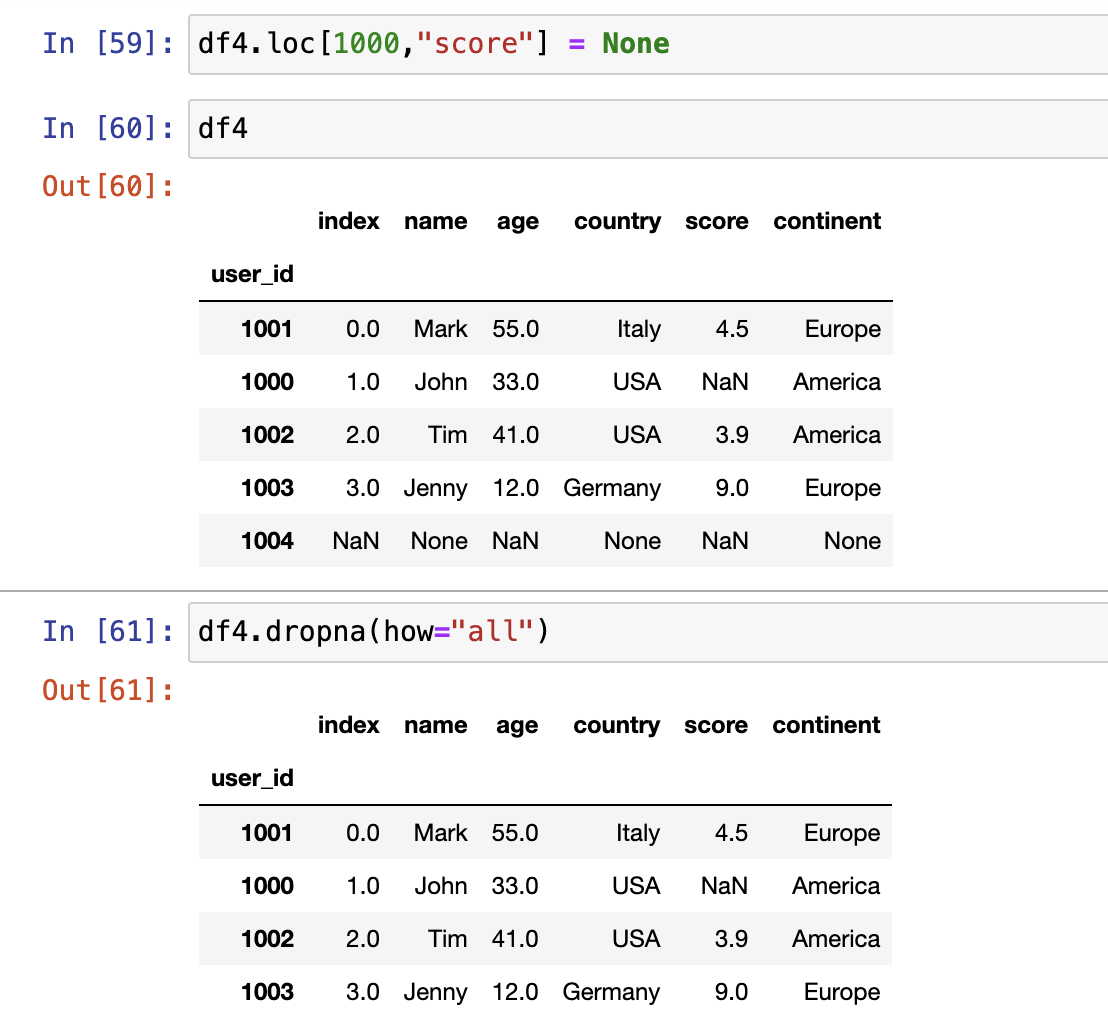
删除None
取唯一值


 浙公网安备 33010602011771号
浙公网安备 33010602011771号