软工实践结对作业二
结对第二次作业——顶会热词统计的实现
| 这个作业属于哪个课程 | 2021春软件工程实践 | W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 结对第二次作业——顶会热词统计的实现 |
| 结对学号 | 221801304&221801331 |
| 这个作业的目标 | 实现顶会热词统计的相关功能 |
| 其他参考文献 | 无 |
git仓库链接和代码规范链接
JS、CSS、HTML文件命名
js、css、html的命名均采用小写命名方式(templates下的html除外)
正例:detail.css、echarts.js、table.html
反例:Echarts.js、Detail.cssHTML类型声明
使用HTML5的文档类型申明,不使用XHTML或HTML4
正例:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="X-UA-Compatible" content="IE=Edge" />
<meta charset="UTF-8" />
<title>Page title</title>
</head>
<body>
<img src="images/company-logo.png" alt="Company" />
</body>
</html>
- 缩进
嵌套的节点应该缩进,并且同层节点缩进需一致。
正例:<div> <p>111</p> <span>33</span> </div>反例:
<div> <p>fa</p> <span>33</span> </div>
- CSS内部命名应该有意义
正例:.conceal{ border:none; }
- 每个选择器及属性独占一行
正例:.btn{ width: 100px; height: 30px; }
- 多使用相对宽度,少用绝对宽度
这样的目的主要是更容易适配不同浏览器及屏幕。
项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 7day | 8day |
| Development | 开发 | ||
| • Analysis | • 需求分析 | 30 | 30 |
| • Dicussing & Design Spec | • 讨论交流 & 设计文档 | 30 | 40 |
| • Design Review | • 设计复审 | 20 | 10 |
| • Learning | • 学习新知识 | 60 | 80 |
| • Coding Standard | • 代码规范 | 30 | 30 |
| • Coding | • 具体编码 | 2500 | 3000 |
| • Code Review | • 代码复审 | 30 | 30 |
| • Test | • 测试 | 30 | 20 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 30 | 30 |
| • Size Measurement | • 计算工作量 | 30 | 20 |
| • Postmortem & Improvement Of The Prototype | • 事后总结, 并提出过程改进计划 | 30 | 20 |
| 合计 | 2820 | 3310 |
成品展示
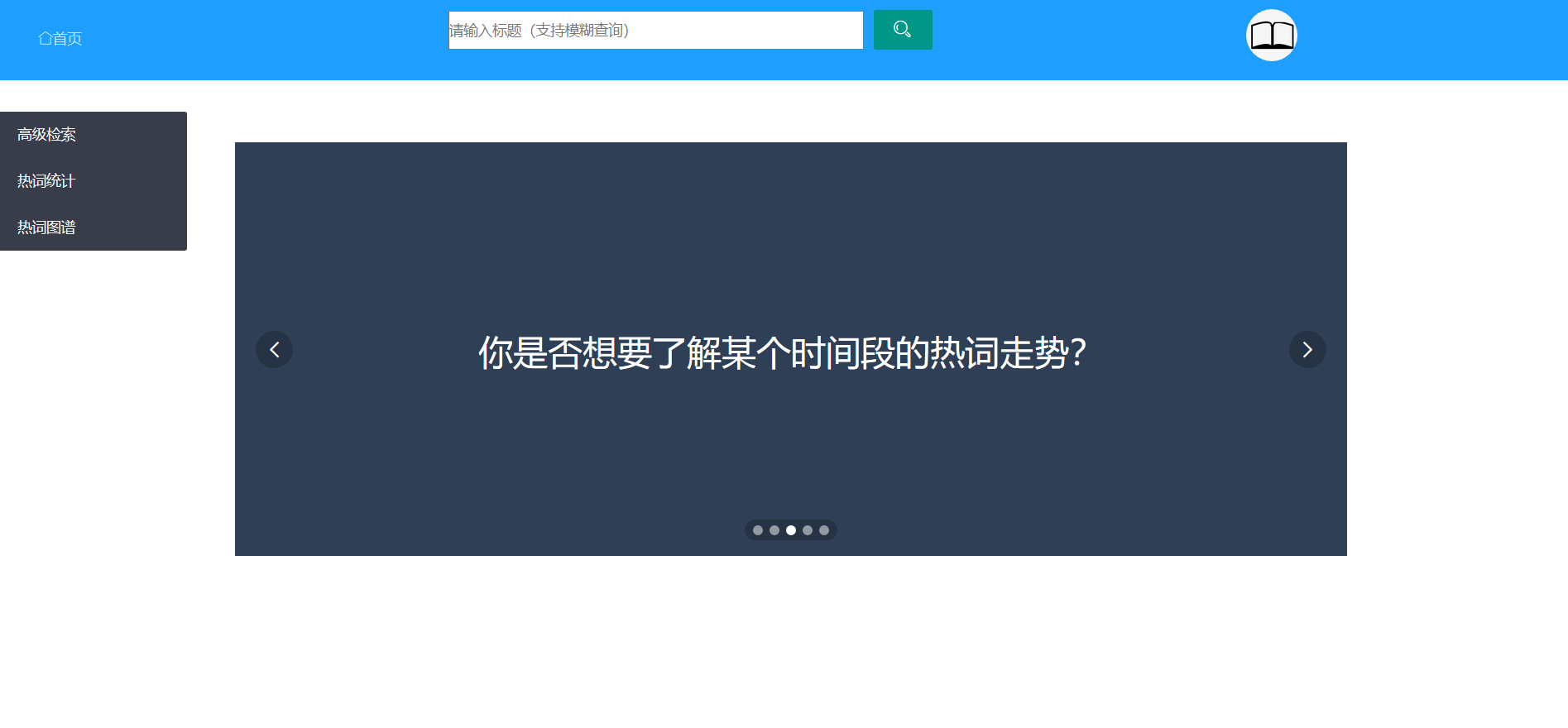
- 主页
由头部和侧边导航栏和主体三部分,主题采用轮播图进行网站的推销介绍(笑)。
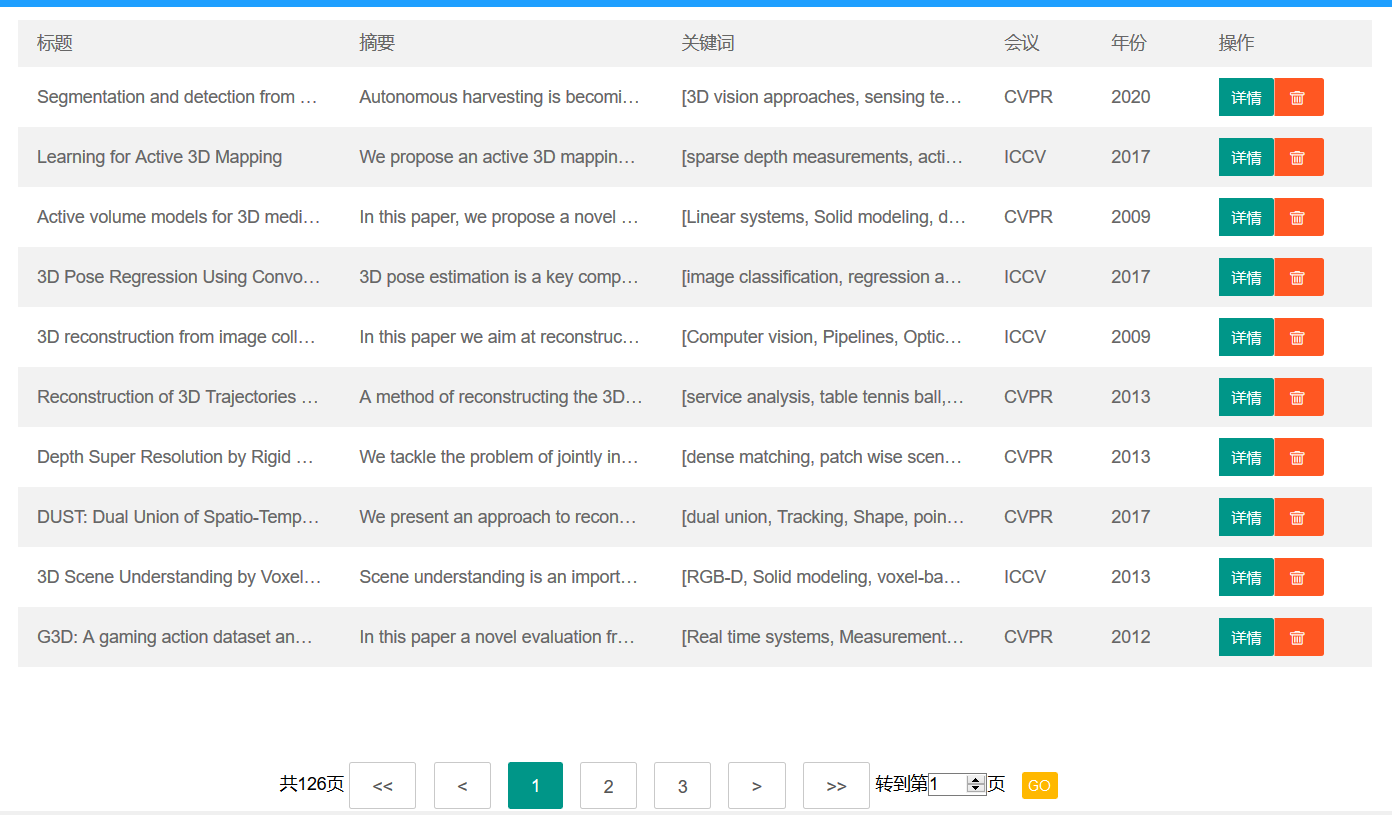
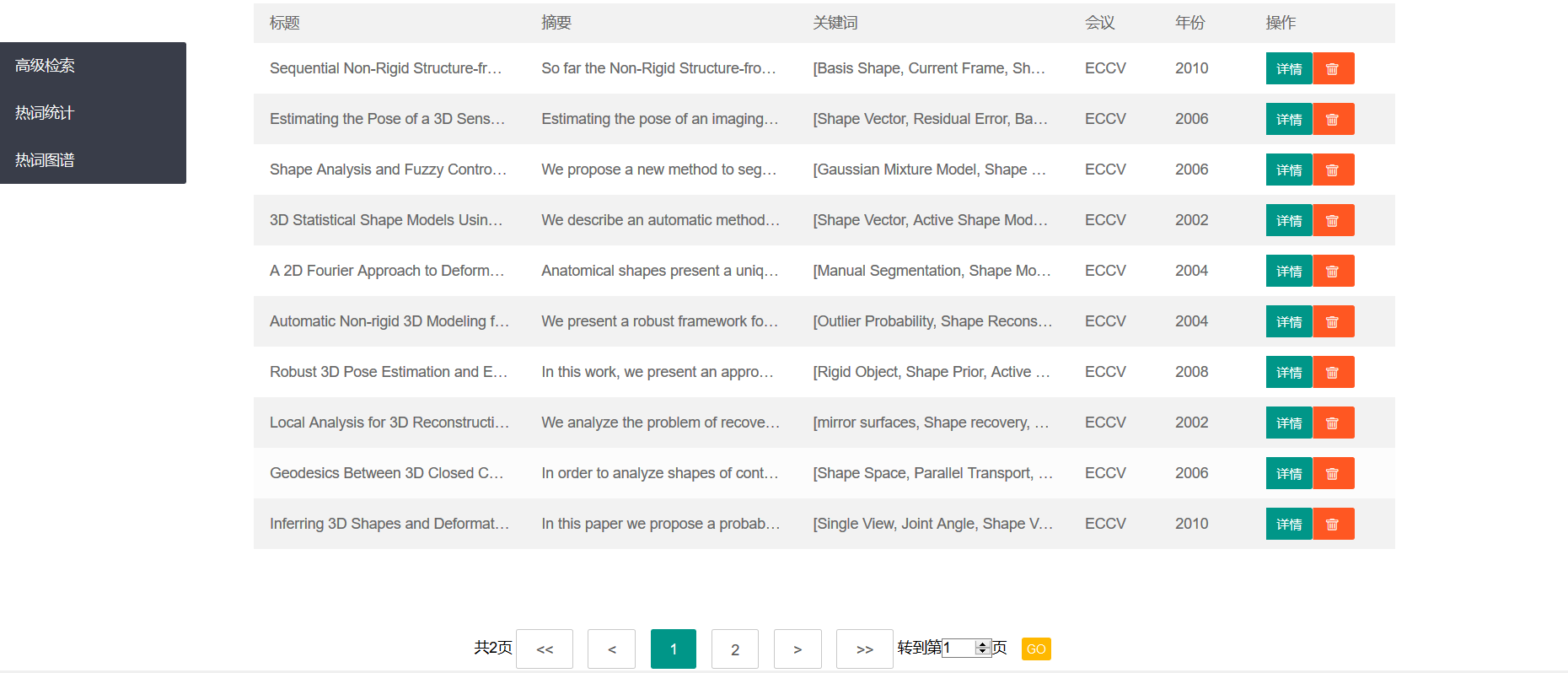
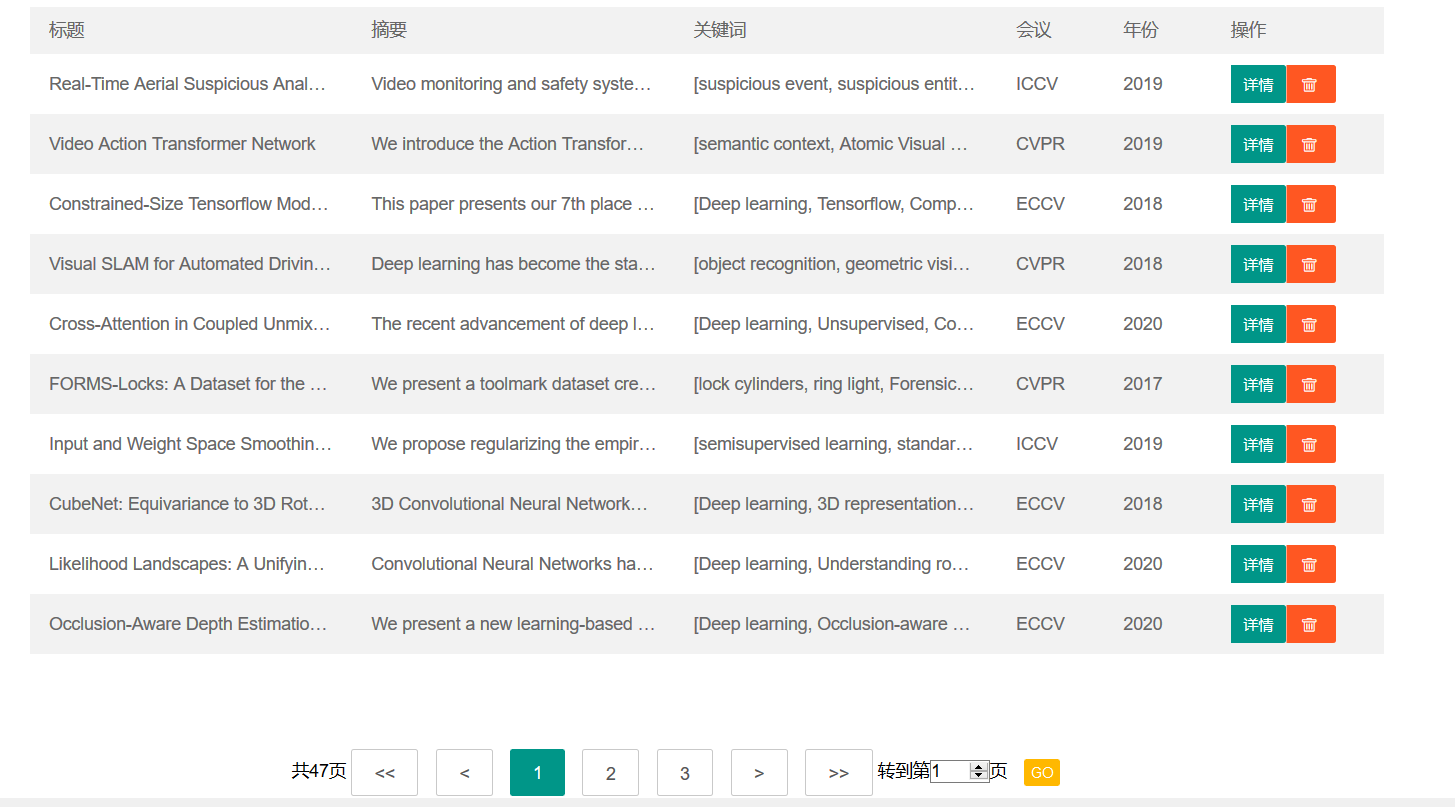
可以在头部搜索框快速搜索,根据标题模糊查询,得到查询结果的列表。
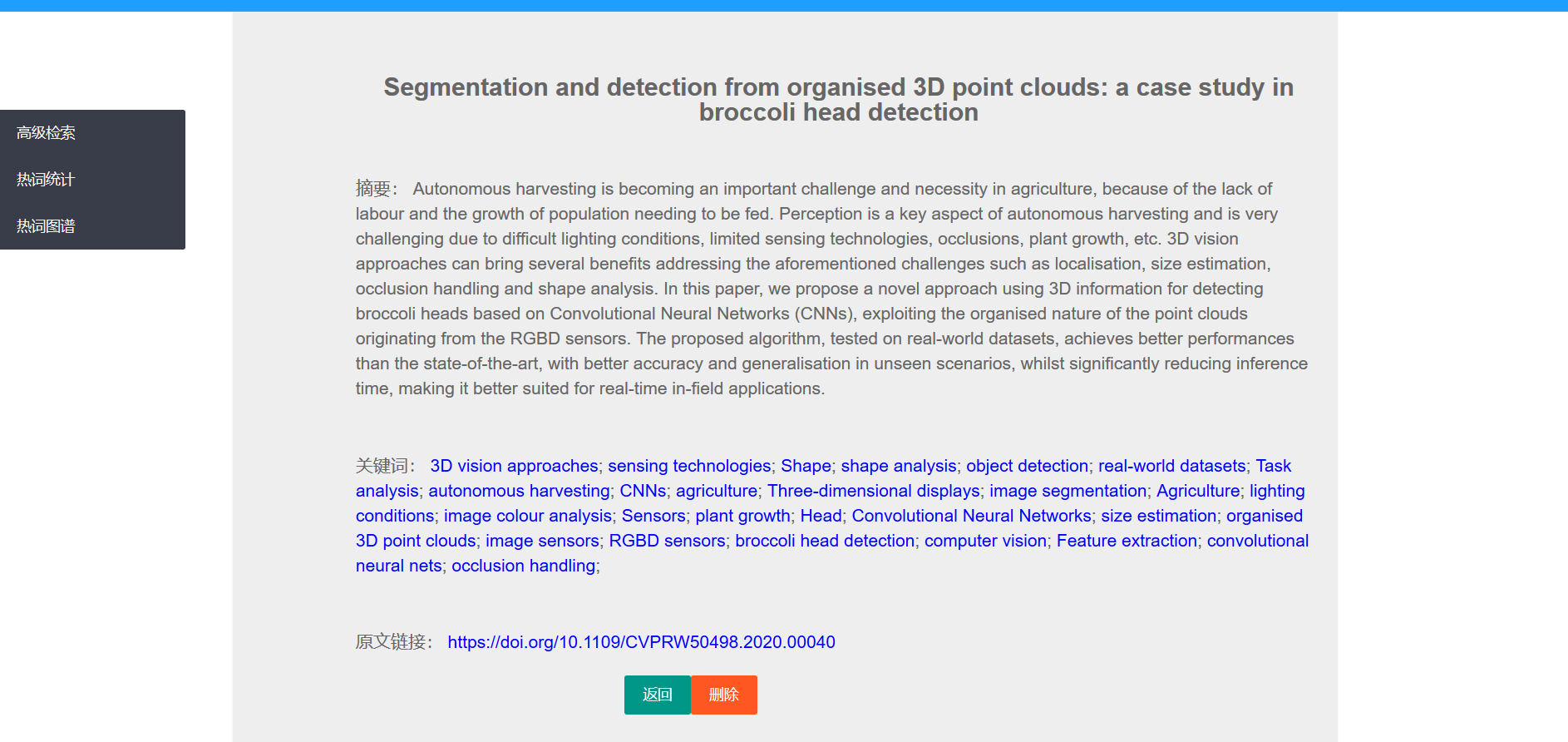
每个条目显示标题、摘要、关键词、会议、时间的信息,点击详情后可以观看更详细的内容。
详情页内的关键词里每个关键词都可以点击,点击后可以跳转到包含该关键词的论文列表。
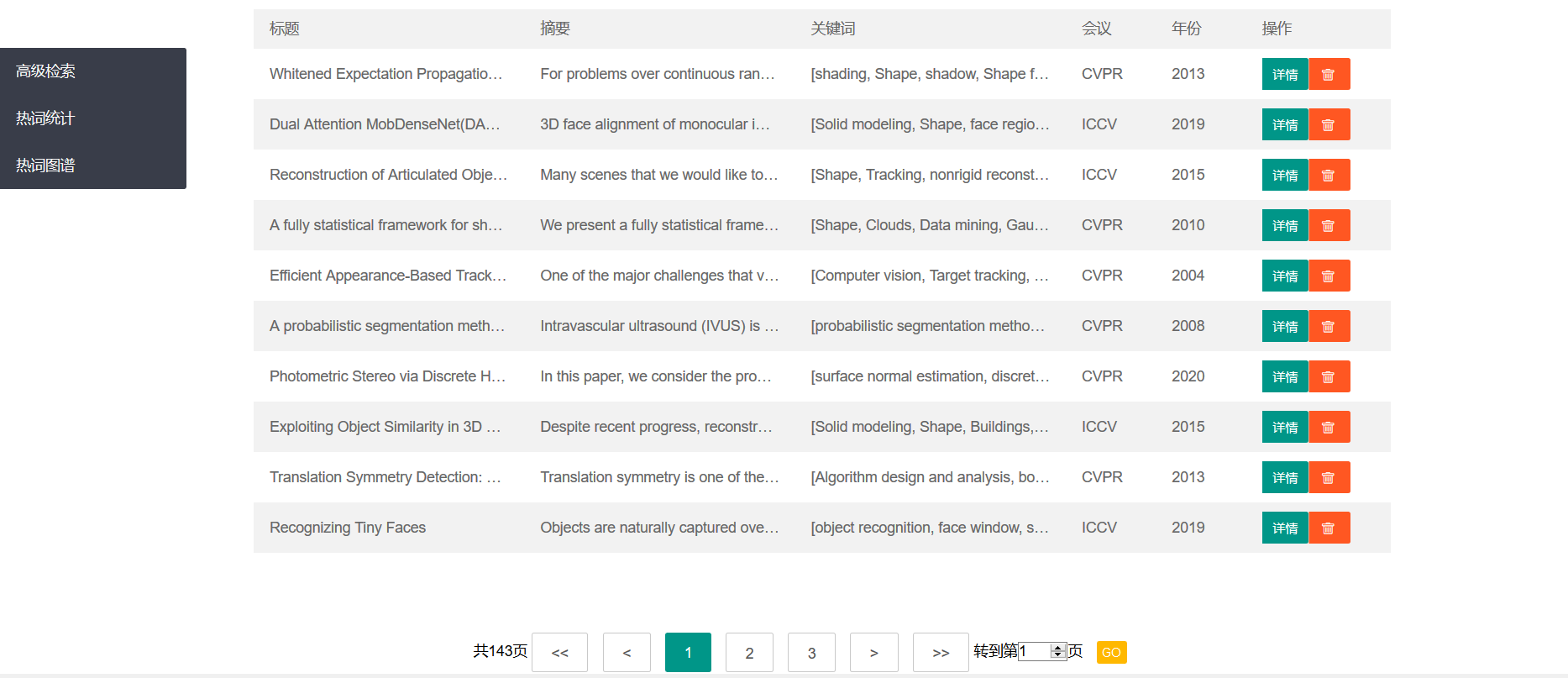
另外,在论文列表和详情页都可以删除该论文。- 高级搜索页
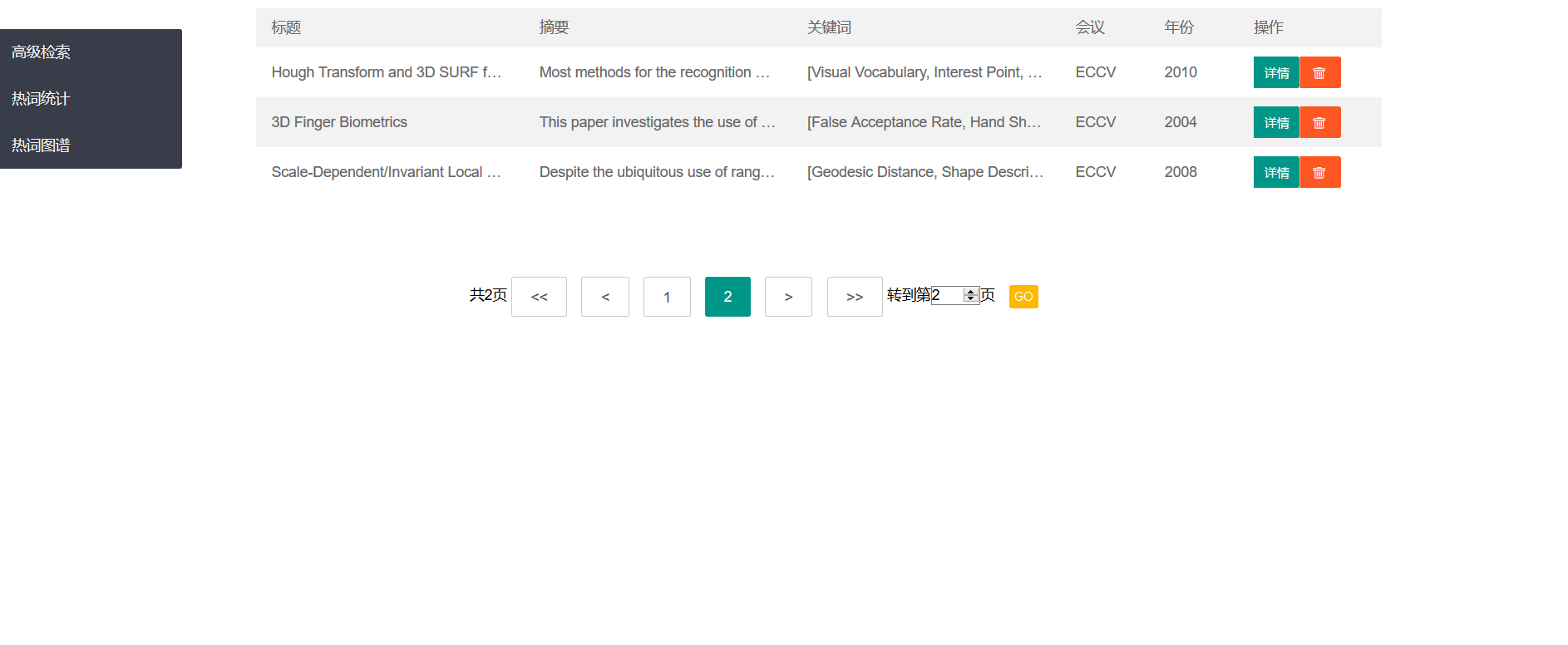
点击侧边栏的高级搜索可以到高级搜索页面,可以进行标题、摘要、关键词的模糊或精确查询,还可以选定时间区间和会议,默认是2000-2020和三大会议都查询(如果把三个会议都取消掉再查询,会弹出提示信息不让你查询)
顺带一提,这个分页是可以用的,是真的分页。
- 热词统计页
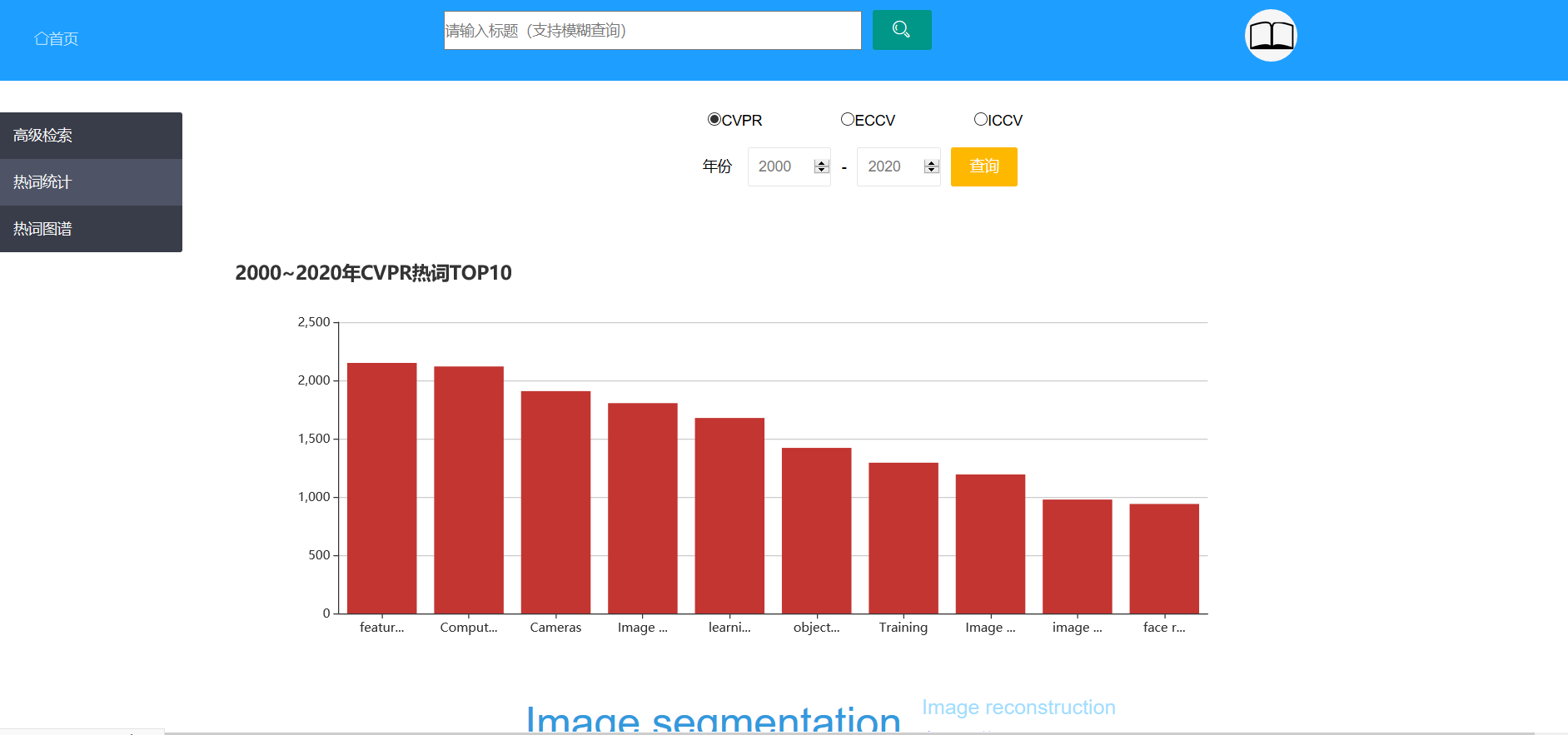
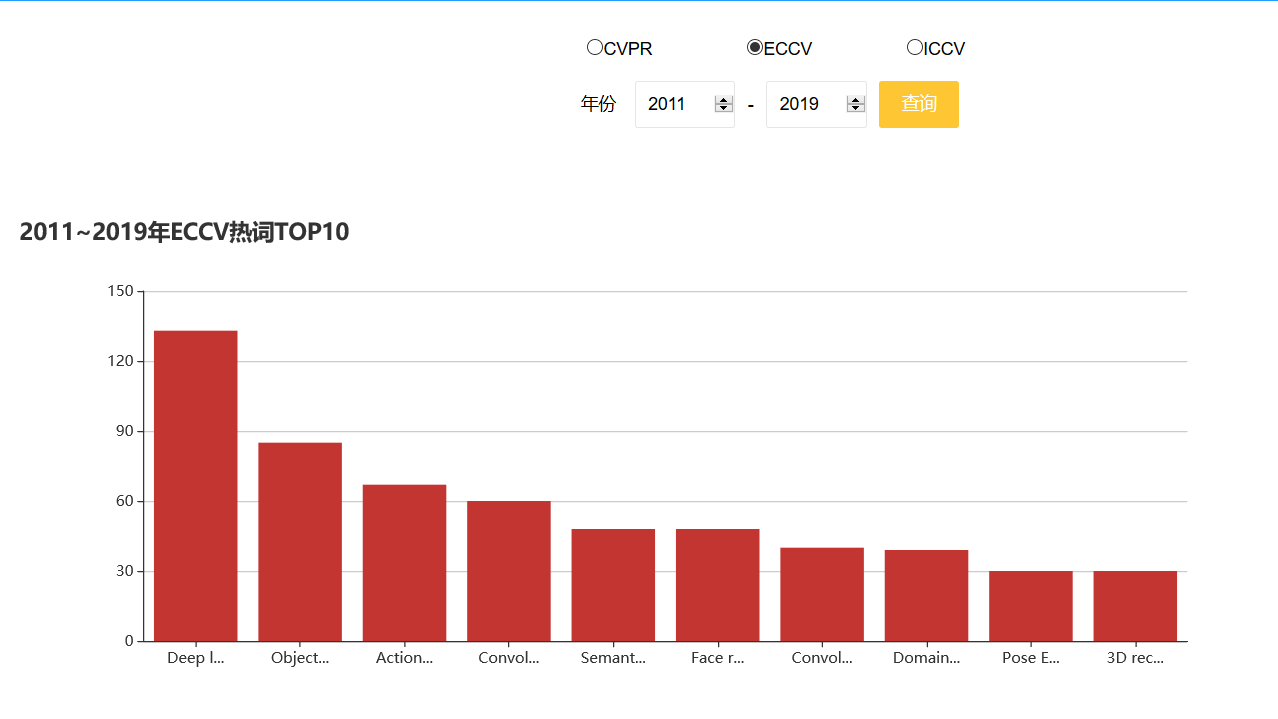
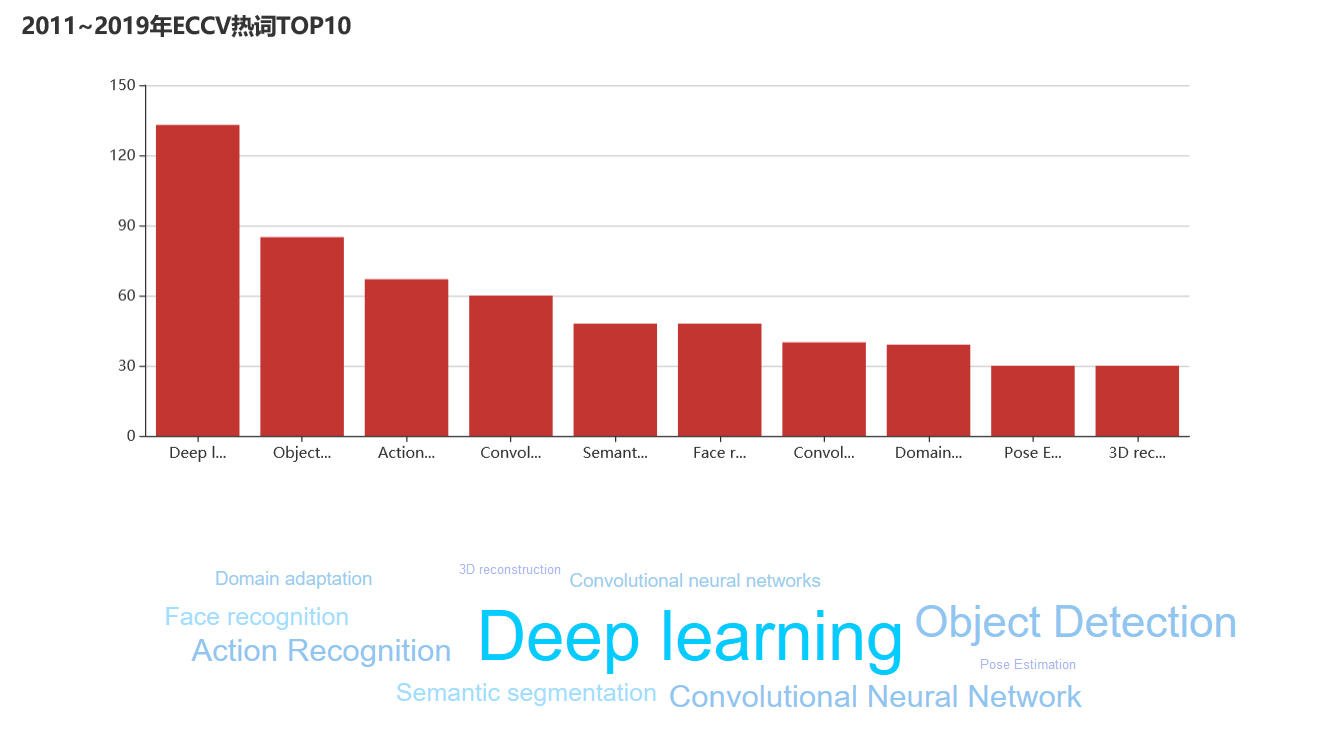
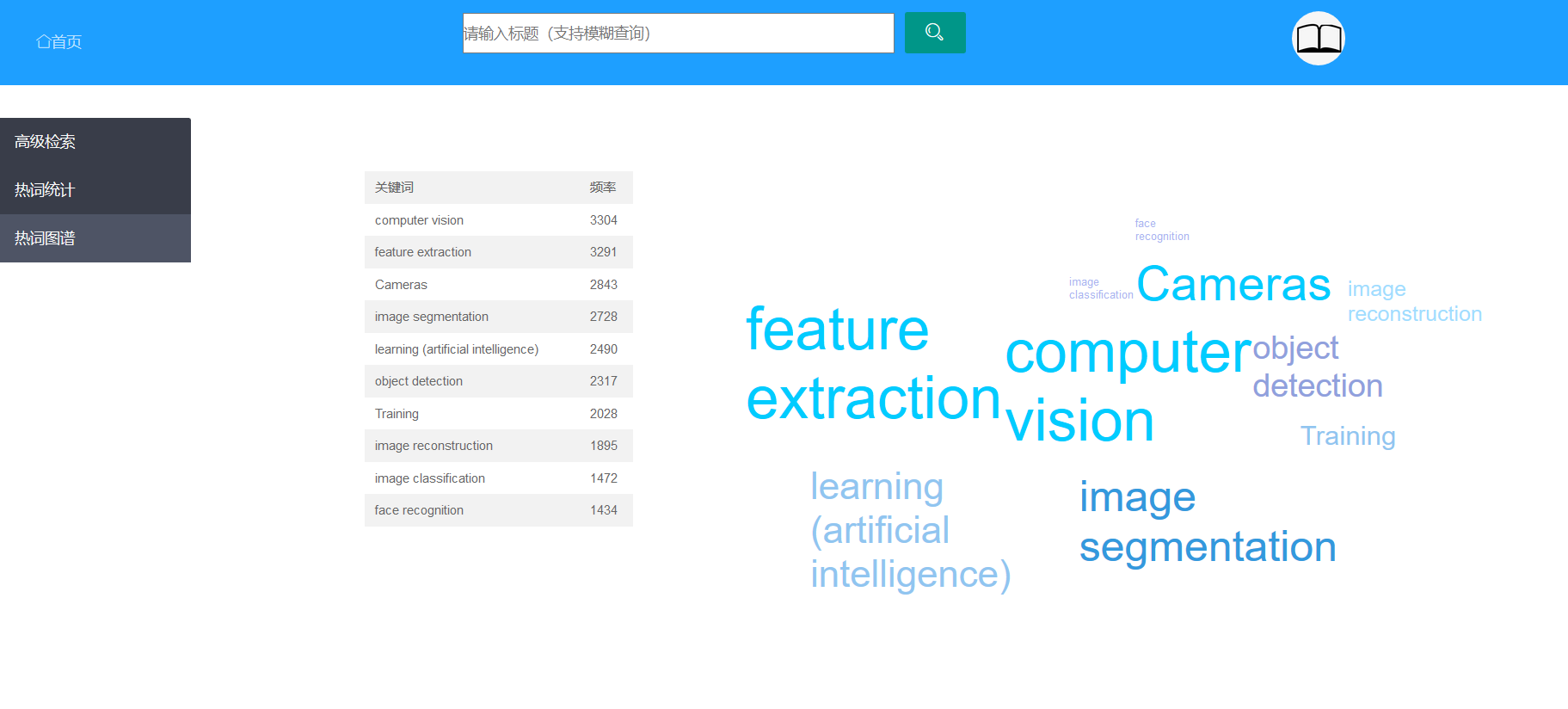
点击侧边栏的热词统计后,可以显示热词top10,并且可以选择查看某个会议、某个年份区间的热词top10。
热词top10下面还有对应上面top10的词云,点击某个关键词词云还可以跳转到对应的论文列表。
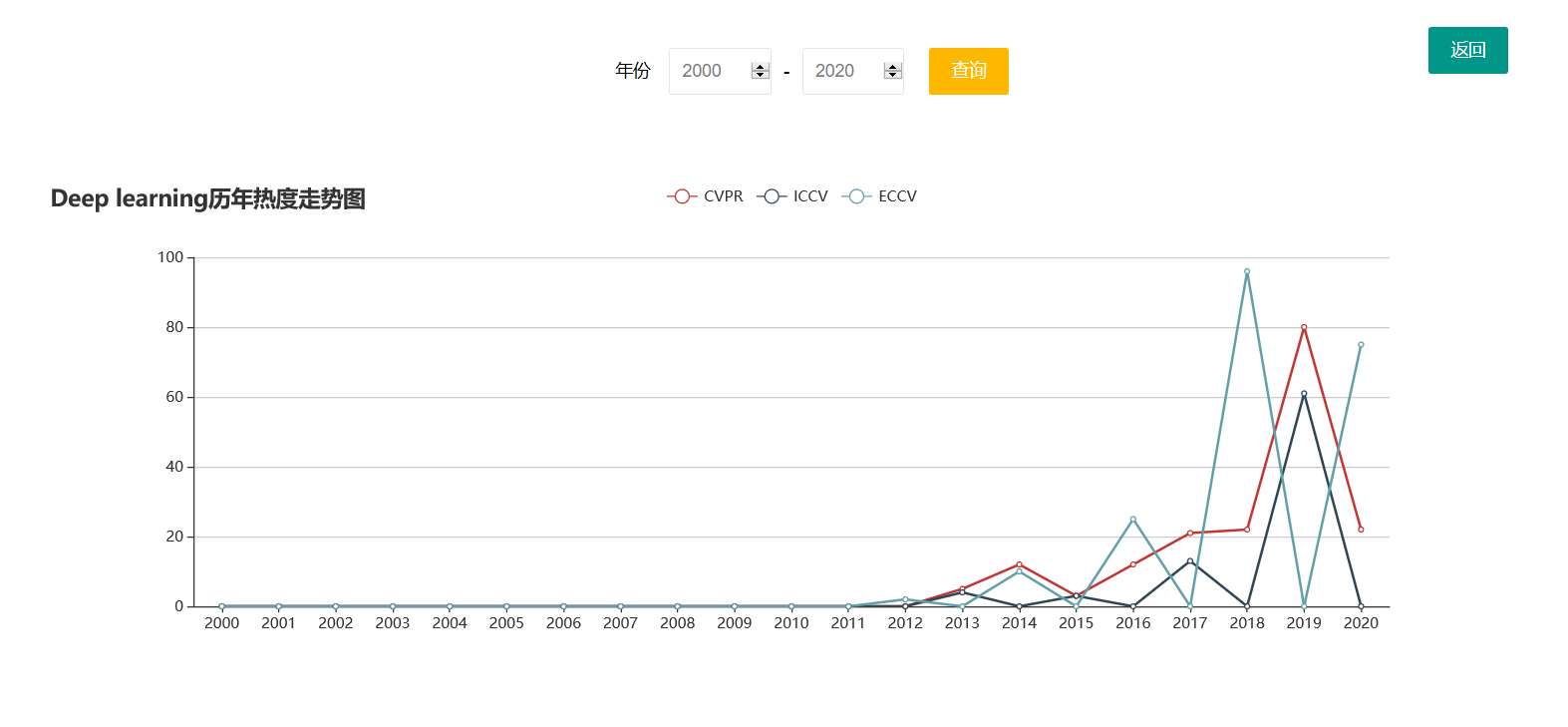
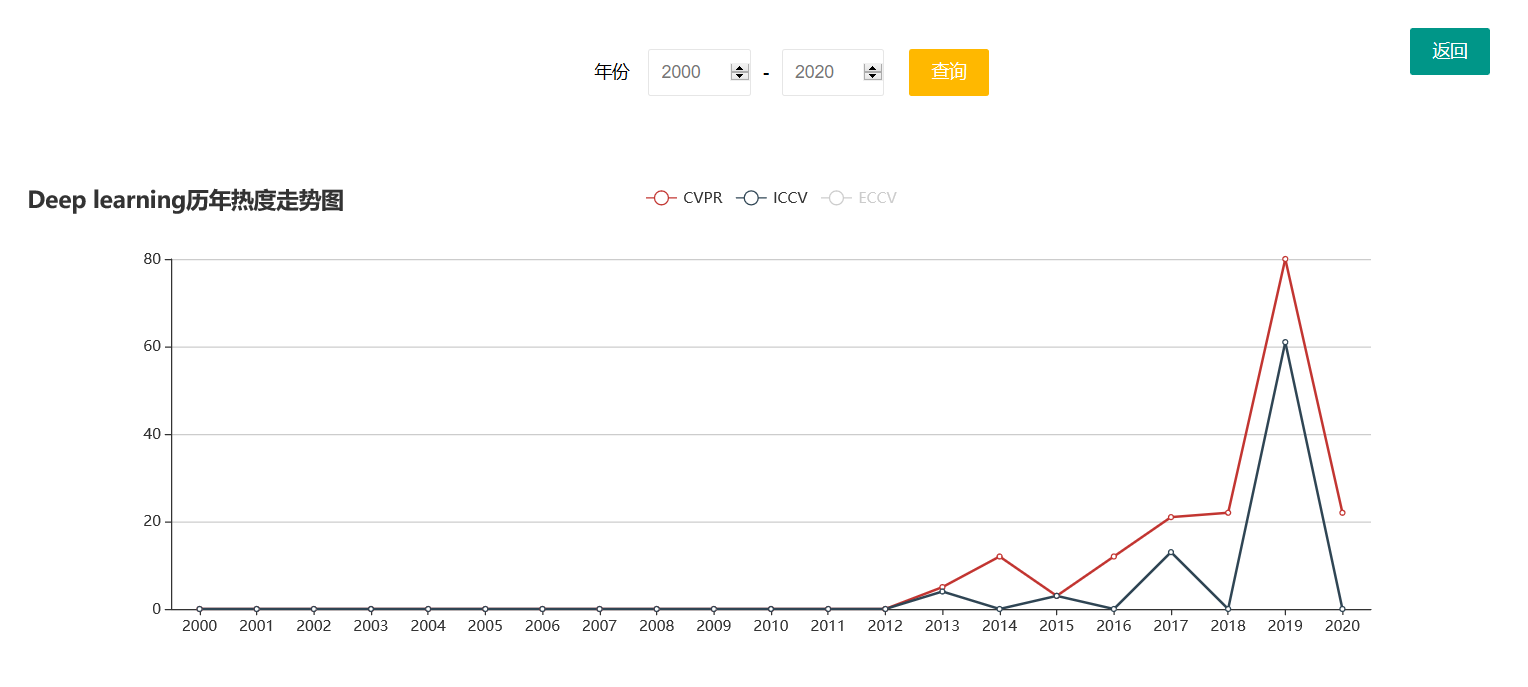
点击柱状图中某个柱形,还可以查看对应的这个热词的热度走向图,并且可以选择查看不同会议的走向。
- 热词图谱页
点击侧边栏的热词图谱可以到这个页面,展示的是所有会议的2000到2020期间的所有热词热度还有词云,点击这里的词云依然可以跳转到对应搜索的论文列表。






结对讨论过程描述
有了第一次结对作业的经验,加上第二次结对作业开始时我们已经返校,面对面交流方便了许多,所以第二次结对作业的准备工作还是比较迅速的。
开始讨论:由于在同一个宿舍,所以讨论比较方便。第二次结对作业发布后,我们首先根据作业要求,把每一条需求映射到前端、后端,分别需要实现什么进行了分析,并且生成了下面的文档。

虽然一个人写前端一个人写后端,但是经常写着写着就跑去对方的电脑面前,看看对方正在写什么,并且提出自己的意见,通过不断的交换意见,修改代码,达成意见上的一致。
遇到问题:在编码的过程中,遇到的最大的问题是数据库CRUD的效率问题,把爬取下来的数据映射完转换后,插入过程不尽如人意,跑了一晚上居然还没插入完成(???),并且到后面越来越慢,从一开始的一秒n条到最后一分钟一条。
解决问题:后来,通过不断地测试和搜索引擎的资料查找与讨论后,发现问题在于:插入关键词信息之前使用了select(*)语句判断关键词是否存在,导致每插入一条论文数据,就需要执行十多次该语句,在论文数量逐渐增大之后,该语句效率也越来越低,导入论文导入时间迅速增加。于是我们重构了数据库,将论文和关键词的对应关系由多对多改为一对多,将三张表改为了两张表,虽然会有一些数据冗余,但是大幅提升了性能,论文导入时间也缩短到了2分钟。
遇到问题:在模糊查询的过程中,由于需要连表,在本地进行一次查询时间需要30s(当然也有电脑卡的原因),用户体验很差。
解决问题:将需要连表和模糊查询的字段增加了索引,让本地运行所需时间减少到了1s内
遇到问题:写前端的时候,样式问题困扰了许久,常常犹豫不决,有时写完后发现不好看或者不合理,重写样式。加上第一次使用layui美化界面,不熟悉效果与用法,花了比较长的时间。
解决问题:不断与队友进行讨论,探讨页面布局与样式是否合理、美观,设计好一个部分就commit一次,邀请队友一起看效果,作出修改。研究layui官方文档,通过不断地测试样式,调整样式,把页面做的更加美观,同时也更加熟练的使用layui。
从需求分析开始到最后撰写博客,我们两个人都没有停止过讨论,我觉得这才是结对作业真正的意义所在,有交流才有改善,有交流才能解决问题。
下面附带两张讨论时的照片,讨论都是面对面交流。


设计实现过程
项目技术
本次项目前后端不分离,使用springboot开发。前端使用了thymeleaf模板引擎进行前后端的数据库交互,并使用了Layui美化了样式
设计思路
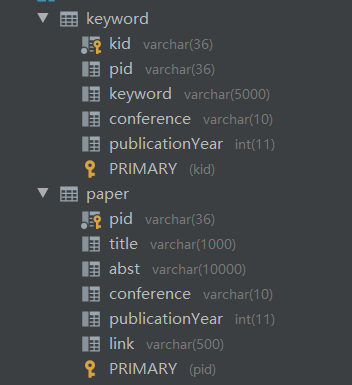
- 数据库
本次作业的数据主要有三部分,论文信息、关键词信息、关键词与论文之间的对应关系
我们将论文与关键词之间设计成1对多的关系进行建表
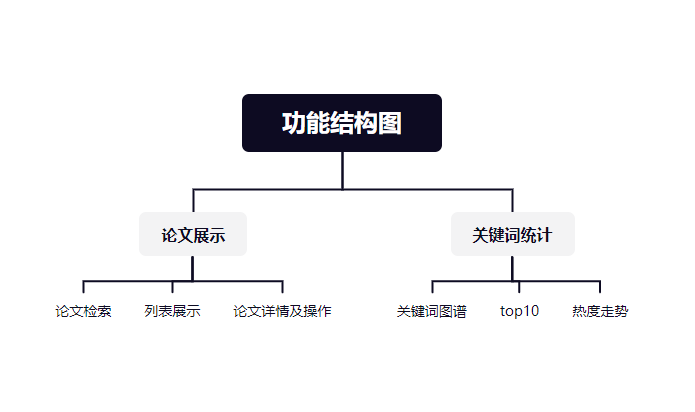
- 模块设计
主要将功能模块分为两个部分:论文管理和关键词统计
论文的搜索支持多条件模糊查询;
关键词统计模块中包括了关键词图谱和top10排行;
实现过程
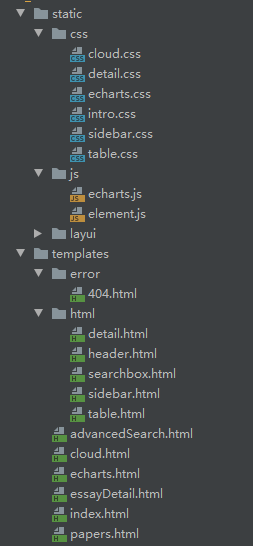
- 前端:使用thymeleaf做前后端数据传递,通过Layui美化样式
前端项目结构图
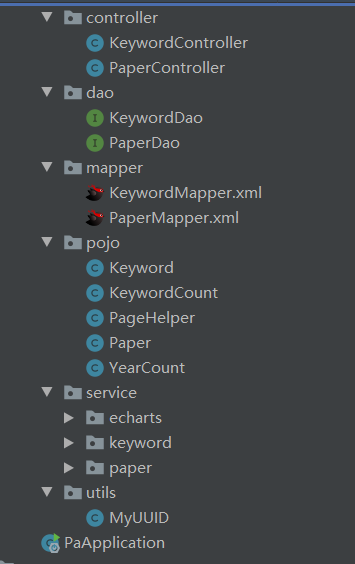
- 后端:使用java语言,通过SSM框架进行开发
后端项目结构图
功能结构图
代码说明
论文高级检索
<select id="selectPapersByMap" parameterType="map" resultMap="Paper">
SELECT p.pid,title,abst,p.conference,p.publicationYear,link,
keyword
FROM paper AS p
LEFT JOIN keyword AS k ON p.pid=k.pid
<where>
<!--精确查询-->
<if test="etitle !=null and etitle !='' ">AND title=#{etitle}</if>
<if test="eabst !=NULL and eabst !='' ">AND abst=#{eabst}</if>
<if test="econference !=NULL and econference !=''">AND p.conference=#{econference}</if>
<if test="ekeyword !=NULL and ekeyword !=''">AND k.keyword=#{ekeyword}</if>
<!--模糊查询-->
<if test="vtitle !=NULL and vtitle!=''">AND title LIKE '%${vtitle}%'</if>
<if test="vabst !=NULL and vabst !=''">AND abst LIKE '%${vabst}%'</if>
<if test="vkeyword !=NULL and vkeyword !=''">AND keyword LIKE '%${vkeyword}%'</if>
<!--年份查询-->
<if test="publicationYear !=NULL and publicationYear !=''">AND p.publicationYear=#{publicationYear}</if>
<if test="beginYear !=NULL and beginYear !=''">AND p.publicationYear BETWEEN #{beginYear} AND #{endYear}</if>
<if test="link !=NULL and link !=''">AND link=#{link}</if>
<if test="conference !=NULL and conference !=''">
AND p.conference IN (1,
<if test="CVPR !=NULL and CVPR !=''">"CVPR",</if>
<if test="ECCV !=NULL and ECCV !=''">"ECCV",</if>
<if test="CVPR !=NULL and CVPR !=''">"CVPR",</if>
2)
</if>
</where>
</select>
使用mybatis实现dao层接口,通过将查询参数传入map进行查询,可支持任意数量条件、模糊或精确查询(不过使用map好像不太规范,下次封装一个DO类来代替map)
论文展示(分页)
@Data
@NoArgsConstructor
@AllArgsConstructor
public class PageHelper
{
private List<String> pidList; //论文id列表
private int totalNum; //总条数
private int paperNum; //单页面页数
private int currentPage; //当前页面
private int totalPage; //总页数
/**
* 构造方法
* @param pidList
* @param paperNum
*/
public PageHelper(List<String> pidList, int paperNum)
{
this.pidList = pidList;
this.paperNum = paperNum;
this.totalNum=pidList.size();
this.currentPage=0;
this.totalPage=(totalNum%paperNum)==0?(totalNum/paperNum):(totalNum/paperNum+1);
}
/**
* 根据索引获得列表
* @param start
* @param end
* @return
*/
public List<String> getListByIndex(int start,int end)
{
if(start>=totalNum || end<=0)
{
return new LinkedList<>();
}
if(end>=totalNum)
{
end=totalNum;
}
return pidList.subList(start,end);
}
/**
* 获取指定页号的内容
* @return
*/
public List<String> getPageByNum(int pageNum)
{
currentPage=pageNum;
return getListByIndex((pageNum-1)*paperNum,pageNum*paperNum);
}
/**
* 获得上一页的内容
* @return
*/
public List<String> getPrePage()
{
return getListByIndex((currentPage-1)*paperNum,currentPage--*paperNum);
}
/**
* 获得下一页的内容
* @return
*/
public List<String> getNextPage()
{
return getListByIndex((currentPage-1)*paperNum,currentPage++*paperNum);
}
封装了一个PageHelper来帮助实现分页,论文检索时,将查询结果的id列表存入List,进行分批读取;
类里封装了一些方法进行读取和遍历
关键词图谱
$(document).ready(function()
{
//根据条件请求数据
$.post('/getTop10Keywords/',{beginYear:2000,
endYear:2020,conference:''},function(data) {
data = JSON.parse(data);
//加载词云
CloudLoad(data);
});
})
function CloudLoad(data)
{
array.splice(0,array.length);
for(var i=0;i<data.x.length;i++)
{
var obj=new Object();
obj.text = data.x[i];
obj.weight = data.y[i]/100;
obj.link = "/getPapersByKeyword/"+data.x[i]; //为每个关键词设置链接
array.push(obj);
}
//加载词云
$("#main").empty();
$("#main").jQCloud(array, { //设置参数
removeOverflowing: false,
shape: "elliptic",
width: 500,
height: 300
});
}
通过ajax异步请求后端数据,利用jQCloud组件进行关键词图谱的渲染
热词统计
function BarLoad(beginYear,endYear,conference)
{
bar.showLoading();
//根据筛选条件获取后端数据
$.post('/getTop10Keywords/',{beginYear:beginYear,
endYear:endYear,conference:conference},function(data)
{
bar.hideLoading();
data=JSON.parse(data);
//加载词云
CloudLoad(data);
bar.setOption
({
title: {
text: beginYear==endYear?beginYear:(beginYear+'~'+endYear)+'年'+conference+'热词TOP10'
},
xAxis: {
data: data.x
},
series: [
{
type: 'bar',
data: data.y
}]
});
});
}
通过ajax异步请求后端数据,利用Echarts组件进行热词统计图表的渲染
心路历程和收获
ZCX:这次作业是一次全新的体验,我还是第一次对上十万的数据进行处理。在导入论文以及进行查询的过程中,经历了一次次看着页面转圈圈的痛苦,第一次深切地体会到“性能”两个字意味着什么。在不断debug、不断修改的过程中,慢慢试着去关注性能,试着去深入代码底层,进行调优。当论文导入时间从40分钟改进到2分钟的时候,真的有一种某名的快感。希望自己在未来的开发和编码过程中,能够不仅仅满足于解决问题,而是追求更快、更优的解决方案。
WKJ:这是第一次写一个项目的前端,以往都只是手敲html、css、js,这次是比较规范的写前端,各个方面都感觉挺新的,也是第一次接触到layui和thymeleaf。虽然是第一次,但是通过不断查看示例,查看官方文档,再实践应用,还是收获颇丰的。一边写一边看一边修改,把一个空的界面变成有东西的界面,再变成美观的界面,还是挺有成就感的。同时也体会到结对编程的快乐,通过跟队友的讨论与交流,自身实力也得到了提高。
评价结对队友
ZCX:这是和KJ的第二次结对合作,这一次的合作从线上转为了线下,双方的交流更多,也更方便了。因为在同一个宿舍,有时在睡觉前突然想到一个好点子,便会直接转过头来和对方分享讨论,大家都在这样的交流讨论过程中开阔了思维,试着从多种角度思考问题。
KJ是一个非常有耐心、非常负责的队友,能够把每一项任务都完成到最好,和他合作效率很高。
WKJ:第二次结对合作,跟第一次相比,还是有不同的收获的,首先从线上变成了线下,两个人的交流变得更多了,而且因为第二次结对合作量比较大,合作交流显得更为重要。在宿舍里,常常代码打着打着,就转头开始讨论,交换想法,在这种模式下,可以及时发现分歧并且解决。
CX是一个效率高、乐于助人的队友,时常能提出很好的点子,跟他合作结对编程又充实又得到了成长,吸取了经验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号