Stream
简介
流是Java API的新成员,它允许你以声明性方式处理数据集合(通过查询语句来表达,而不是临时编写一个实现)。就现在来说,你可以把它们看成遍历数据集的高级迭代器。此外,流还可以透明地并行处理。
流是从支持数据处理操作的源生成的元素序列。
特点
- 元素序列——就像集合一样,流也提供了一个接口,可以访问特定元素类型的一组有序值。因为集合是数据结构,所以它的主要目的是以特定的时间/空间复杂度存储和访问元素(如ArrayList 与 LinkedList)。但流的目的在于表达计算。
- 源——流会使用一个提供数据的源,如集合、数组或输入/输出资源。 请注意,从有序集合生成流时会保留原有的顺序。由列表生成的流,其元素顺序与列表一致。
- 数据处理操作——流的数据处理功能支持类似于数据库的操作,以及函数式编程语言中的常用操作,如filter、map、reduce、find、match、sort等。流操作可以顺序执行,也可并行执行。
此外,流操作有两个重要的特点。
- 流水线——很多流操作本身会返回一个流,这样多个操作就可以链接起来,形成一个大的流水线。
- 内部迭代——与使用迭代器显式迭代的集合不同,流的迭代操作是在背后进行的。
优势
- 声明性——更简洁,更易读
- 可复合——更灵活
- 可并行——性能更好
只能遍历一次
请注意,和迭代器类似,流只能遍历一次。遍历完之后,我们就说这个流已经被消费掉了。你可以从原始数据源那里再获得一个新的流来重新遍历一遍,就像迭代器一样。
List<String> title = Arrays.asList("Java8", "In", "Action");
Stream<String> s = title.stream();
s.forEach(System.out::println);
//java.lang.IllegalStateException
s.forEach(System.out::println);
流操作
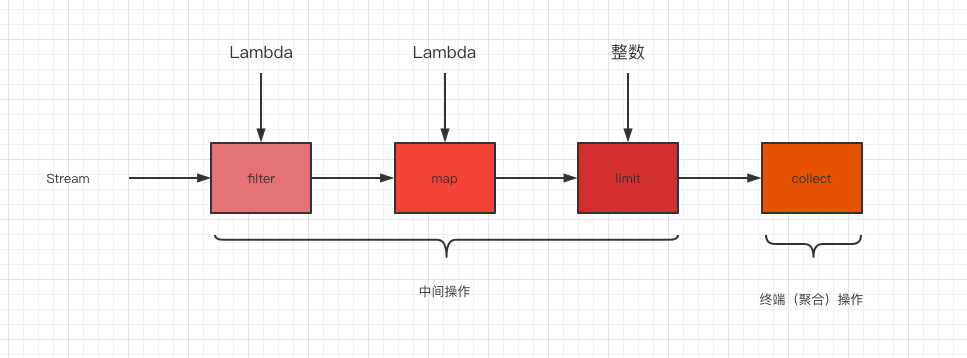
流的使用一般包括三件事:
- 一个数据源(如集合)来执行一个查询;
- 一个中间操作链,形成一条流的流水线;
- 一个终端操作,执行流水线,并能生成结果。
中间操作API
中间操作返回的都是流(Stream
| 操作 | 作用 | 操作参数 |
|---|---|---|
| filter | 过滤 | Predicate |
| map | 映射 | Funcation<T,R> |
| limit | 截断, 方法会返回一个不超过给定长度的流。所需的长度作为参数传递 给limit。如果流是有序的,则最多会返回前n个元素。 | |
| sorted | 排序 | Comparator |
| distinct | 去重 | |
| flatMap | 先映射后扁平化 | Function<T, Stream |
| skip | 跳过 | long |
终端(聚合)操作API
终端操作返回的都是最终结果。
| 操作 | 目的 | |
|---|---|---|
| forEach | 消费流中的每个元素并对其应用 Lambda。这一操作返回 void | |
| count | 返回流中元素的个数。这一操作返回 long | |
| collect | 把流归约成一个集合,比如 List、Map 甚至是 Integer。 | |
| reduce | 聚合求值/数据比较 | |
| allMatch | 所有匹配 | |
| findAny | 查找所有 | |
| findFirst | 查找第一个 |
构建流
由值创建流
Stream<String> stream = Stream.of("Java 8 ", "Lambdas ", "In ", "Action");
stream.map(String::toUpperCase).forEach(System.out::println);
由数组、集合创建流
int[] numbers = {2, 3, 5, 7, 11, 13};
int sum = Arrays.stream(numbers).sum();
List<String> title = Arrays.asList("Java8", "In", "Action");
title.stream().forEach(System.out::println);
由文件创建流
long uniqueWords = 0;
try(Stream<String> lines =
Files.lines(Paths.get("data.txt"), Charset.defaultCharset())){
uniqueWords = lines.flatMap(line -> Arrays.stream(line.split(" ")))
.distinct()
.count();
}
catch(IOException e){
}
由函数创建流
Stream.iterate(0, n -> n + 2)
.limit(10)
.forEach(System.out::println);
流处理数据
收集器
java.util.stream.Collectors
@Data
@ToString
public class Dish {
private String name;
//素食
private boolean vegetarian;
//卡路里
private int calories;
private Type type;
public Dish(String name, boolean vegetarian, int calories, Type type) {
this.name = name;
this.vegetarian = vegetarian;
this.calories = calories;
this.type = type;
}
public enum Type { MEAT, FISH, OTHER }
public enum CaloricLevel{DIET,NORMAL,FAT}
}
筛选、截断、跳过
//筛选
List<Dish> vegetarianMenu = menu.stream()
.filter(Dish::isVegetarian).collect(Collectors.toList());
//返回前3个元素
List<Dish> dishes1 = menu.stream()
.filter(d -> d.getCalories() > 300).limit(3).collect(Collectors.toList());
//跳过前两个元素
List<Dish> dishes2 = menu.stream()
.filter(d -> d.getCalories() > 300)
.skip(2)
.collect(Collectors.toList());
映射、查找、归纳
//映射出Name
List<String> dishNames = menu.stream()
.map(Dish::getName)
.collect(toList());
//短路匹配
boolean isHealthy = menu.stream()
.allMatch(d -> d.getCalories() < 1000);
//短路查找,查找到匹配项就返回
Optional<Dish> dish =
menu.stream()
.filter(Dish::isVegetarian)
.findAny();
//归纳 求和
int total = menu.stream()
.map(Dish::getCalories).reduce(0, Integer::sum);
//归纳,求最大值
Optional<Integer> max = menu.stream()
.map(Dish::getCalories).reduce(Integer::max);
流的扁平化
List<String> title = Arrays.asList("Hello", "World");
List<String> l = title.stream()
.map(word -> word.split(""))
.flatMap(Arrays::stream)
.distinct()
.collect(toList());
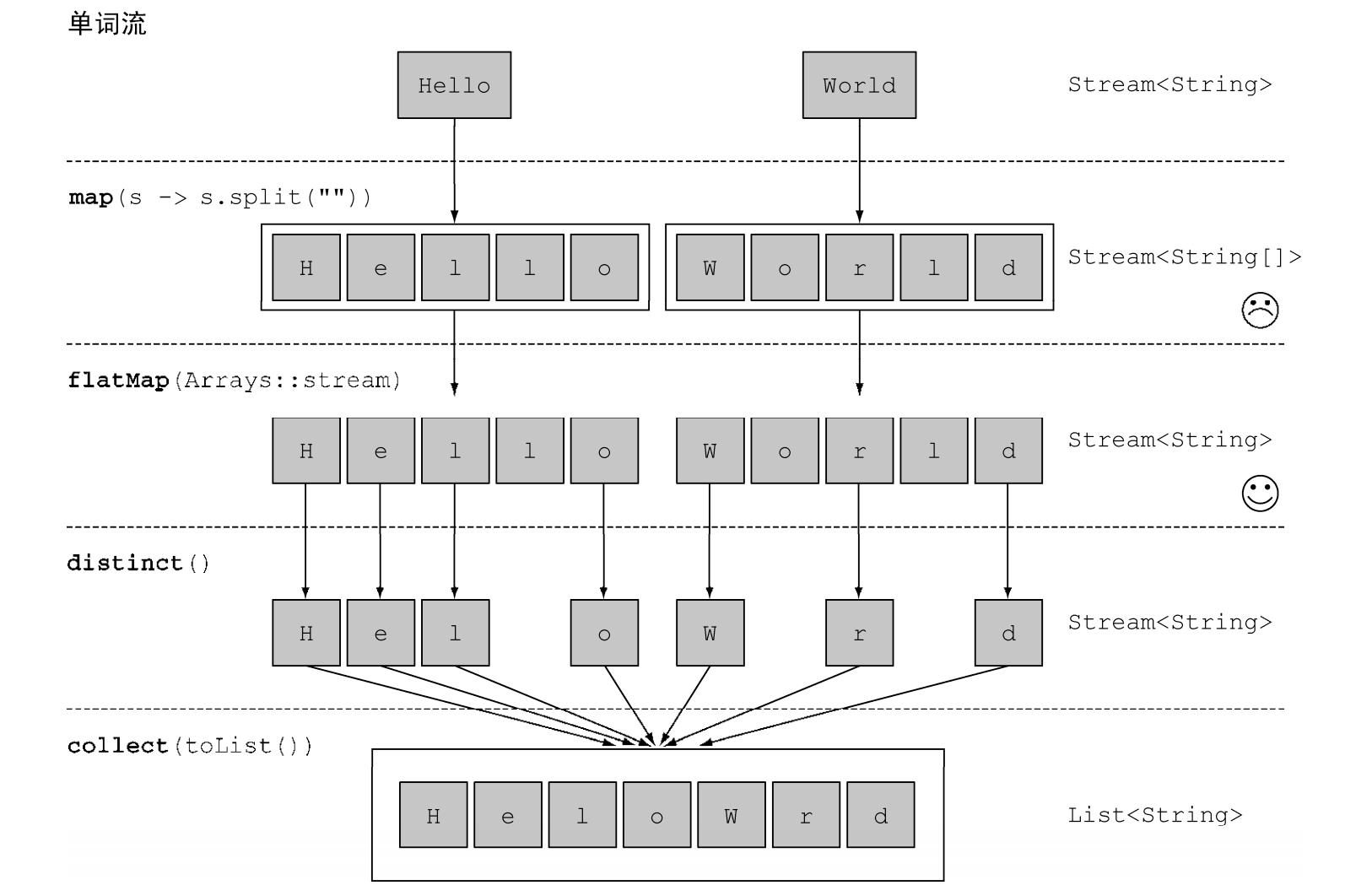
连接、分组、分区
//连接
String shortMenu = menu.stream()
.map(Dish::getName).collect(joining(","));
//一级分组
Map<Dish.Type,List<Dish>> map = menu.stream()
.collect(groupingBy(Dish::getType));
//多级分组
Map<Dish.Type, Map<Dish.CaloricLevel, List<Dish>>> dishesByTypeCaloricLevel =
menu.stream().collect(groupingBy(Dish::getType,groupingBy(d -> {
if (d.getCalories() <= 400) return Dish.CaloricLevel.DIET;
else if (d.getCalories() <=700) return Dish.CaloricLevel.NORMAL;
else return Dish.CaloricLevel.FAT;
})));
//分区
Map<Boolean, List<Dish>> partitionedMenu =
menu.stream().collect(partitioningBy(Dish::isVegetarian));
并行流
可以通过对收集源调用parallelStream方法来把集合转换为并行流。并行流就是一个把内容分成多个数据块,并用不同的线程分别处理每个数据块的流。这样一来,你就可以自动把给定操作的工作负荷分配给多核处理器的所有内核。默认线程数是cpu核数
//并行流求前n个数字合
public static long parallelSum(long n) {
//数据源
return Stream.iterate(1L, i -> i + 1)
//截取前n个数字
.limit(n)
//转换成并行流
.parallel()
.reduce(0L, Long::sum);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号