Stream接口与流式编程
一、认识Stream接口
1.概述
Java 的 Stream 接口是 Java 8 引入的核心 API,用于以声明式编程风格处理数据集合(如集合、数组等)。它简化了集合操作,支持链式调用和并行处理。Stream 是来自数据源的元素序列,支持聚合操作,这里的数据源可以是集合(如List、Set)、数组、I/O资源等,同时Stream不是数据结构,它不存储数据,而是对数据源进行连续计算(例如过滤、映射、排序等)并生成结果。
2.核心特点
1)非存储数据结构:Stream 本身不存储数据,而是从数据源(集合、数组、I/O 等)获取数据。
2)链式操作:支持多个操作串联成流水线(类似 Linux 管道 |)。
3)惰性求值:中间操作不会立即执行,只有遇到终结操作时才触发计算。
4)不可复用:一个 Stream 只能被消费一次(操作后自动关闭)。
5)支持并行:通过 .parallel() 可自动并行处理数据。
二、使用
1.使用步骤
使用Stream的基本步骤:
创建一个Stream(从集合、数组等)。
调用一系列中间操作(可能没有,也可能有多个)。
调用一个终结操作,得到结果。
2.如何获得Stream流
1)Collection家族的可以通过stream()方法,该方法会返回一个Stream流携带泛型。
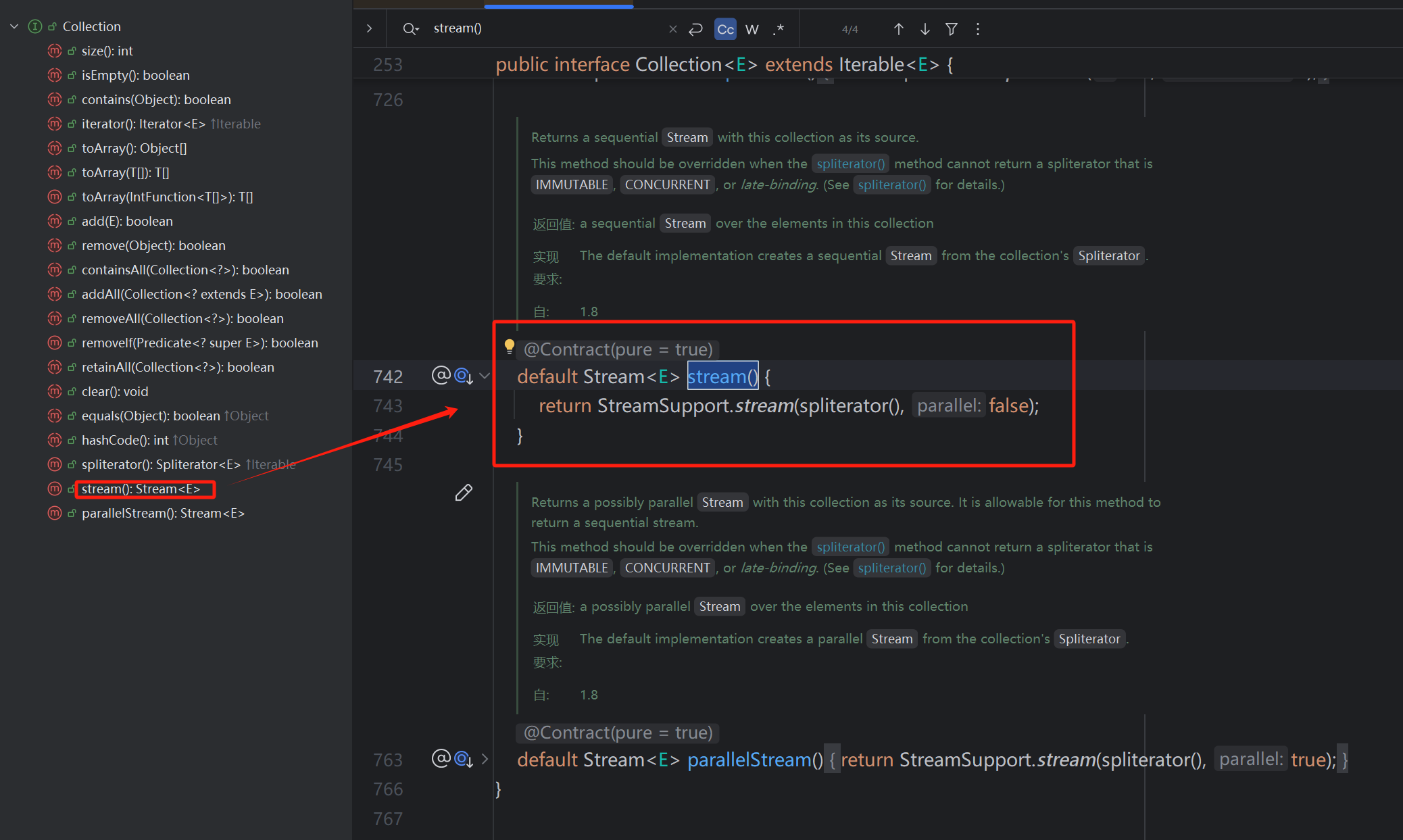
2)数组可以通过其工具类Arrays的stream()方法传入一个数组,返回一个流对象。该方法是一个静态方法。
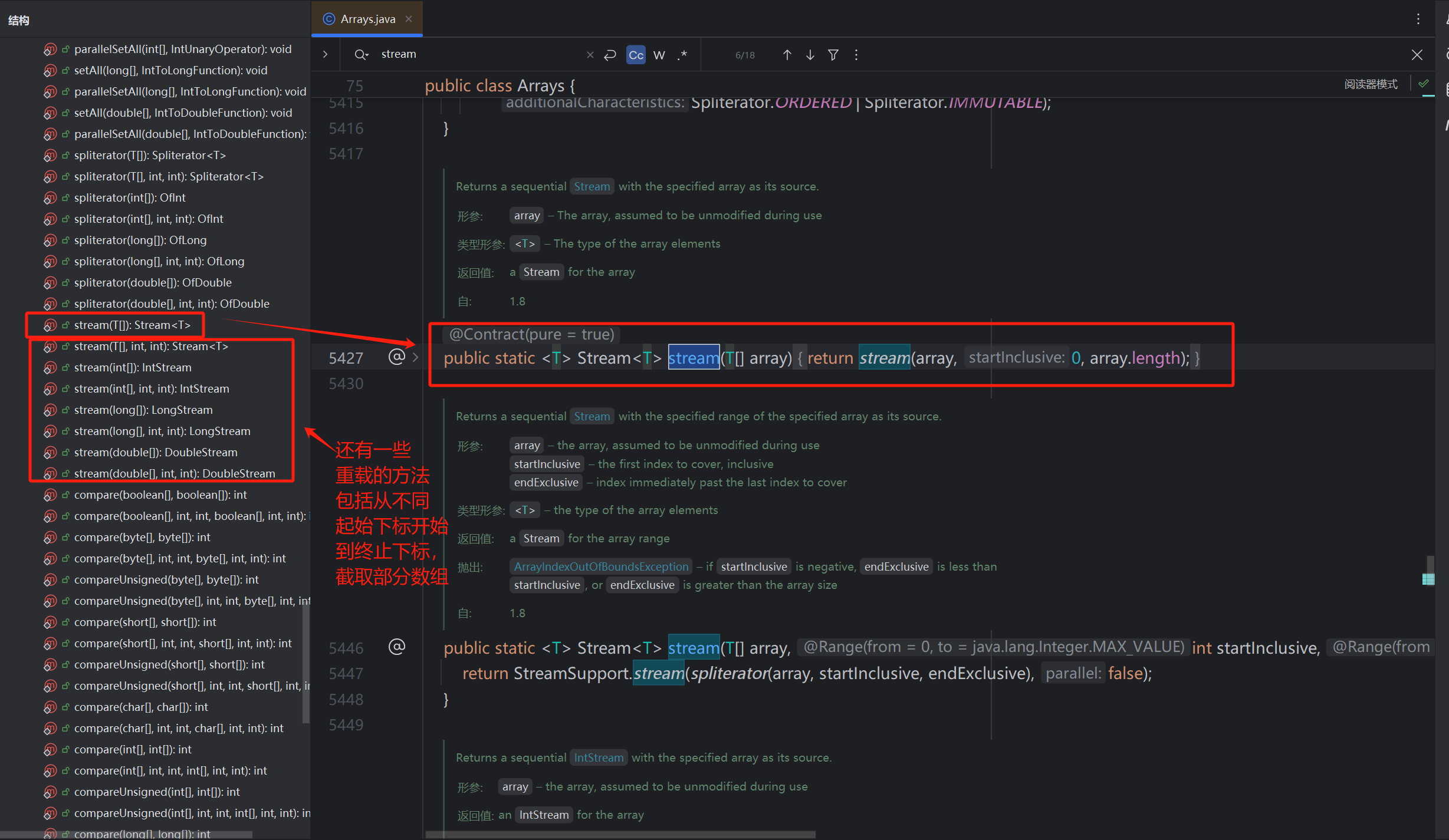
3)Stream接口也提供了静态方法of()方法,传入一个或多个参数,返回一个流对象。该方法也是一个静态方法。
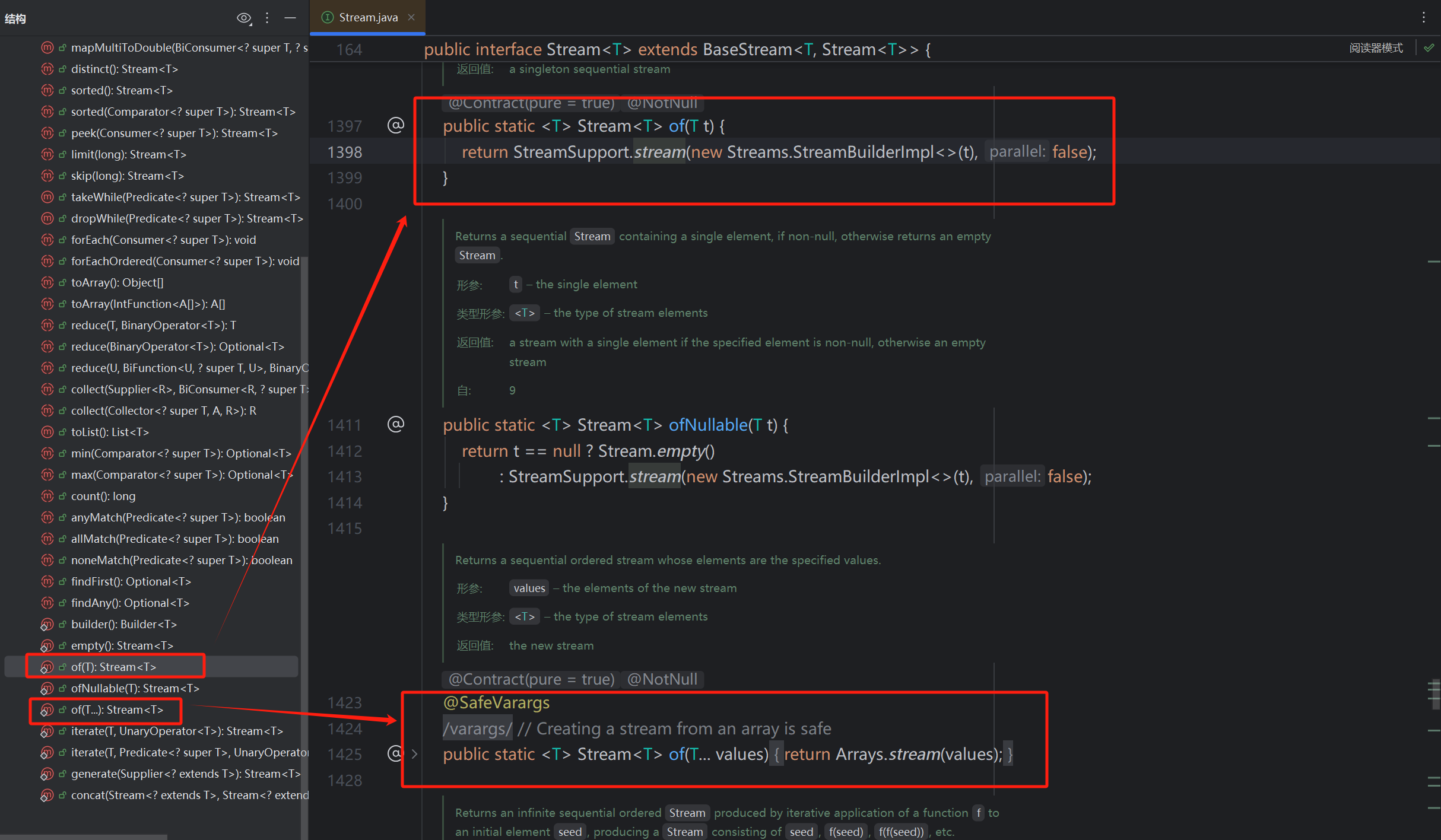
4)还有一些其他的接口,例如:IntStream、LongStream、DoubleStream,他们都有各自的of()方法(优先用基本类型流IntStream, LongStream,避免装箱开销)
注:Stream接口和IntStream、LongStream、DoubleStream接口都继承于BaseStream接口。
3.StreamAPI的中间操作
中间操作(Intermediate Operations):可以连续调用,会生成一个新的Stream并返回。中间操作不会立即执行,只有遇到终结操作时才触发计算。
注:StreamAPI中会使用java8新增的四个函数式接口:Consumer,Supplier,Function,Predicate,不清楚的可以看下之前Lambda表达式的文章,里面有具体讲述。
1)Stream filter(Predicate<? super T> predicate);
filter()方法会对原先的流中元素进行过滤,流中每个元素会按过滤规则返回布尔值,当返回值为true时会保留该元素在新的流中,当返回值为false时不会保留在新的流中。例如:
Stream.of(1,2,3,4,5,6,7).filter(i -> i % 2 == 0 );
该代码表示对1,2,3,4,5,6,7进行保留偶数处理。
2) Stream map(Function<? super T, ? extends R> mapper);
map()方法是将流中每个元素按一定映射规则映射到一个新的流中。例如:
Stream.of("abc","def","ghi").map(s -> s.toUpperCase());
该代码表示将字符串"abc","def","ghi",变成大写。当然上面代码也可以使用方法引用:
Stream.of("abc","def","ghi").map(String::toUpperCase);
3) Stream flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
flatMap()方法也被称为扁平化,该方法会将多个集合类型流合并变成一个数据流中。例如:
点击查看代码
List<String> str1 = new ArrayList<>();
str1.add("1");
str1.add("2");
str1.add("3");
List<String> str2 = new ArrayList<>();
str2.add("abc");
str2.add("def");
str2.add("ghi");
Stream.of(str1, str2).flatMap(Collection::stream).forEach(System.out::println);
4)Stream distinct();
distinct()方法是去重,对于重复元素的判定是通过hashCode()方法和equals()方法来区分。例如:
Stream.of("abc", "abc", "acc", "abb").distinct();
该代码表示对"abc", "abc", "acc", "abb"四个元素进行去重操作。
5)Stream sorted(); 或者 Stream sorted(Comparator<? super T> comparator);
sorted()方法是对流中元素进行排序,所以要么流中元素实现了Comparable接口,要么传入一个Comparator比较器。例如:
Stream.of("aaa","aac","acb","aba","ab").sorted();
该代码执行结果为:aaa aac ab aba acb
6)public static Stream concat(Stream<? extends T> a, Stream<? extends T> b)
concat()方法是将两个流合并成一个流。例如:
点击查看代码
Stream<Integer> stream1 = Stream.of(1, 2, 3, 4);
Stream<String> stream2 = Stream.of("abc", "def", "ghi", "jkl");
Stream.concat(stream1, stream2).forEach(System.out::println);
注意区别与flatmap()方法,concat()是将两个数据流合并成一个数据流,flatmap()是将多个集合类合并成一个数据流。
7)Stream limit(long maxSize);
limit()方法是截取maxSize个元素的操作。例如:
Stream.of(11,22,33,44,55).limit(3).forEach(System.out::println);
执行结果为:11 22 33
8)Stream skip(long n);
skip()方法是跳过前n个元素,经常与limit()方法搭配使用。例如:
Stream.of(11,22,33,44,55).skip(2).limit(3).forEach(System.out::println);
执行结果为:33 44 55
4.终止操作
终结操作(Terminal Operations):终止流,并产生一个结果(如一个集合,一个值,或者什么都不返回)。触发终止操作时才会真正执行中间操作,终止操作执行完毕后Stream对象就失效了,即无法在执行中间操作或终止操作。
1)void forEach(Consumer<? super T> action);
forEach()方法是遍历操作,将流中每个元素。例如:
Stream.of(11,22,33,44,55).forEach(System.out::println);
执行结果为:11 22 33 44 55
2)boolean allMatch(Predicate<? super T> predicate);
allMatch()方法是检查流中所有元素是否所有都匹配(全部匹配才返回true)。例如:
System.out.println(Stream.of(11, 22, 33, 44, 55).allMatch(e -> e % 2 == 0));
执行结果为:false
3)boolean anyMatch(Predicate<? super T> predicate);
anyMatch()方法是检查流中所有元素是否匹配(有一个匹配返回true)。例如:
System.out.println(Stream.of(11, 22, 33, 44, 55).anyMatch(e -> e % 2 == 0));
执行结果为:true
4)boolean noneMatch(Predicate<? super T> predicate);
noneMatch()方法是检查流中所有元素是否所有都不匹配(全部不匹配返回true)。例如:
System.out.println(Stream.of(11, 33, 55).noneMatch(e -> e % 2 == 0));
执行结果为:true
5)Optional findFirst();
findFirst()方法是获得第一个元素,返回值类型是Optional容器,可以通过get()方法获取该容器存储的值。例如:
System.out.println(Stream.of(11, 33, 55).findFirst().get());
执行结果为:11
6)Optional reduce(BinaryOperator accumulator);
reduce()方法是将流中所有元素按照指定规则合并成一个结果,可以是相加、相乘等。例如:
System.out.println(Stream.of(2, 3, 5).reduce(( a, b ) -> a*b ).get());
执行结果为:30
7)T reduce(T identity, BinaryOperator accumulator);
reduce()方法是将流中所有元素按照指定规则合并成一个结果,identity是一个初始值。例如:
System.out.println(Stream.of(2, 3, 5).reduce(2, ( a, b ) -> a*b ));
执行结果为:60
8)long count();
count()方法是统计流中元素个数。例如:
System.out.println(Stream.of(2, 3, 5).count());
执行结果为:3
9)Optional min(Comparator<? super T> comparator); 和 Optional max(Comparator<? super T> comparator);
min()方法是取流中元素最小的元素,max()方法是取流中元素最大的元素。例如:
System.out.println(Stream.of(2, 6, 5).max((a, b) -> a- b ).get());
执行结果为:6
10)<R, A> R collect(Collector<? super T, A, R> collector);
collect()方法是将流转换成一个值或者一个集合,参数Collector,使用的实现类为Collectors,该类包括:
public static <T> Collector<T, ?, List<T>> toList()
public static <T> Collector<T, ?, Set<T>> toSet()
public static <T, K, U, M extends Map<K, U>> Collector<T, ?, M> toMap
public static <T, C extends Collection<T>> Collector<T, ?, C> toCollection(Supplier<C> collectionFactory)
public static <T> Collector<T, ?, Long> counting()
public static <T> Collector<T, ?, Double> averagingInt(ToIntFunction<? super T> mapper)
public static <T> Collector<T, ?, Optional<T>> maxBy(Comparator<? super T> comparator)
public static <T> Collector<T, ?, Integer> summingInt(ToIntFunction<? super T> mapper)
等等一些转换或者统计的方法与collect()搭配使用。
2)Collectors类中的方法涵盖了转为集合,统计,分组,接合等类型的方法
5.Collectors
Collectors 是 Java Stream API 中一个非常实用的工具类,位于 java.util.stream.Collectors,主要用于在流操作的终结操作 collect() 中执行各种可变归约操作(如将元素累积到集合中、汇总元素等)。
核心作用包括
数据聚合:将流元素转换为集合(List/Set/Map)、字符串或数值
分组与分区:类似 SQL 的 GROUP BY 和 PARTITION
统计计算:求和、平均值、极值等统计操作
1)基础收集
| 方法 | 说明 | 示例 |
|---|---|---|
| toList() | 收集到 List | stream.collect(Collectors.toList()) |
| toSet() | 收集到 Set | stream.collect(Collectors.toSet()) |
| toMap() | 收集到 Map | stream.collect(Collectors.toMap()) |
| toCollection() | 指定集合类型 | stream.collect(Collectors.toCollection(LinkedList::new)) |
注:toList(),toSet(),toMap()是将流转换成集合,但具体的实现类并不清楚,若想指定具体转换的实现类,应使用toCollection()方法
2)数值统计
| 方法 | 说明 | 示例 |
|---|---|---|
| counting() | 元素计数 | stream.collect(Collectors.counting()) |
| summingInt() | 整数求和 | stream.collect(Collectors.summingInt(Product::getPrice)) |
| averagingDouble() | 平均值 | stream.collect(Collectors.averagingDouble(Student::getScore)) |
| summarizingInt() | 获取统计摘要 | IntSummaryStatistics stats = stream.collect(Collectors.summarizingInt(...)) |
注:IntSummaryStatistics是一个统计对象,里面包含着计数,总和,最大值,最小值;同理LongSummaryStatistics和DoubleSummaryStatistics也是统计对象。
3)高级操作
| 方法 | 说明 | 示例 |
|---|---|---|
| joining() | 字符串拼接 | stream.map(Object::toString).collect(Collectors.joining(", ")) |
| groupingBy() | 分组(类似SQL GROUP BY) | Map<Department, List |
| partitioningBy() | 按布尔条件分区 | Map<Boolean, List |
注:groupingBy()方法中还可以传Collectors的方法作为参数,例如:
1-1)按部门分组,再按薪资级别分组
Map<Department, Map<String, List<Employee>>> multiGroup = employees.stream().collect(Collectors.groupingBy( Employee::getDepartment, Collectors.groupingBy( e -> e.getSalary() > 10000 ? "高薪" : "普通" ) ));
1-2)分组后统计数量(而不是保存整个对象)
Map<Department, Long> deptCount = employees.stream().collect(Collectors.groupingBy( Employee::getDepartment, Collectors.counting()));
1-3)每个部门只保留员工姓名(而不是整个Employee对象)
Map<Department, List<String>> deptNames = employees.stream().collect(Collectors.groupingBy( Employee::getDepartment, Collectors.mapping(Employee::getName, Collectors.toList())));
三、总结
StreamAPI是java8带来的一种全新数据处理方式,使用流式编程让数据处理的代码变得简洁明了,我们需要习惯并运用到日常开发中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号