

垃圾回收机制
1.概念
- 垃圾回收机制(GC):是Python解释器自带一种机制,专门用来回收不可用的变量值所占用的内存空间
2.原理
- Python的垃圾回收机制(GC)主要使用引用计数(reference counting)来跟踪和回收垃圾。在引用计数的基础上,通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用问题,通过“分代回收”(generation collection)以空间换时间的方法提高垃圾回收效率。
- python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略。
3.引用计数
- 引用计数:变量值被变量名关联的次数
- 引用计数存在一个致命缺陷:循环引用导致内存泄漏
- 解决办法:标记清楚、分代回收、手动GC
name = 'NianBai' # 'NianBai'被关联了一个变量名name,称之为引用计数为1
name1 = name # 把name的内存地址给了name1,而name、name1都关联了'NianBai',所以'NianBai'的引用计数为2
del name1 # 解除'NianBai'和name1的关联,'NianBai'身上的引用计数变为1
4.标记清除
- 专门用于解决循环引用的问题,将内存中程序产生的所有数据值全部检查一遍,查看是否存在循环引用,存在则打上标记 ,之后一次性清除
- 标记:遍历所有的GC Roots对象(栈区中的所有内容或者线程都可以作为GC Roots对象),然后将所有GC Roots的对象可以直接或间接访问到的对象标记为存活的对象,其余的均为非存活对象,应该被清除。
- 清除:清除过程中遍历堆中所有的对象,将没有标记的对象全部清除
- 标记清除算法时,发现栈区内不再有l1与l2(只剩下堆区内二者的相互引用),于是列表1与列表2都没有被标记为存活,二者会被清理掉,这样就解决了循环引用带来的内存泄漏问题。
l1 = ['jason', ]
l2 = ['kevin', ]
l1.append(l2) # 引用计数为2
l2.append(l1) # 引用计数为2
del l1 # 解除变量名l1与列表的绑定关系,列表引用计数减一
del l2 # 解除变量名l1与列表的绑定关系,列表引用计数减一
5.分代回收
- 因为标记清除每隔一段时间就需要将所有的数据排查一遍,资源消耗过大,所以为了减轻资源损耗,开发了分代管理。
- 分代回收:是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代。
- Python将内存分为了3“代”,分别对应三个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。
- 年轻代(第0代):新创建的对象分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把不会回收的对象移到中年代
- 中年代(第1代):不会回收的对象移到中年代
- 老年代(第2代):老年代中的对象是存活时间最久的对象,存活于整个系统的生命周期内。
字符编码
1.发展史
-
阶段一:一家独大
- 美国人发明了计算机,为了让计算机识别英文字符,有了他们的字符编码——ASCII码(只能识别英文,不能识别除英文以外的文字)
- ASCII码:记录英文字符和数字的对应关系,用1bytes来存储字符(A-Z:65-99,a-z:97-122)
-
阶段二:群雄割据
- 计算机传到其他国家后,其他国家使用计算机时发现ASCII对于有些语言来说不好使,于是各个国家发明了各自的字符编码。
- 中国:需要计算机识别中文,开发了一套中文的编码表——GBK码
- GBK码:记录了中文字符、英文字符与数字的对应关系,2bytes起步存储中文(生僻字使用更多),1bytes存储英文
- 韩国:需要计算机识别韩文,开发了一套韩文编码表——Euc_kr码
- Euc_kr码:记录了韩文字符、英文字符与数字的对应关系
- 日本:需要计算机识别日文,开发了一套日文编码表——shift_JIS码
- shift_JIS码:记录了日文字符、英文字符与数字的对应关系
- 各国计算机文本文件无法直接交互,否则会出现乱码的情况
-
阶段三:天下统一
- 由于各个国家各自的字符编码不同,不同国家之间在传输信息的时候就会出现乱码的情况,于是就发明了万国码国码——Unicode
- unicode:所有字符全部使用2bytes起步存储
- utf针对Unicode的优化版本——UTF-8
- UTF-8:英文采用1bytes,其他统一采用3bytes
- 内存使用Unicode,硬盘使用UTF-8
- 由于各个国家各自的字符编码不同,不同国家之间在传输信息的时候就会出现乱码的情况,于是就发明了万国码国码——Unicode
2.实际应用
2.1.编码与解码
- 编码(encode):将人类能够读懂的字符翻译成计算机能够读懂的字符
s1 = '你是猪'
res = s1.encode('utf-8')
print(res, type(res))
- 解码(decode):将计算机能够读懂的字符翻译成人类能够读懂的字符
s1 = '你是猪'
res1 = res.decode('utf-8')
print(res1)
2.2.乱码问题
- 当一组数据用不同的字符编码进行编码解码时,就会出现乱码的情况。
- 解决乱码措施:什么编码存就用什么编码解
2.3.Python默认编码
- python2.x默认的字符编码是ASCII(不支持中文),默认的文件编码是ASCII
-
python解释器可以识别中文和其他语言的方法
- 方法一:告知python解释器,这个.py文件里的文本是用UTF-8编码的。这样,python就会依照utf-8的编码形式解读其中的字符,然后转换成unicode编码内部处理使用
# coding:utf8 或 -*- coding:utf8 -*- # -*- coding:XXX -*-声明的编码方式要与.py文件的编码方式一致- 方法二:在定义字符串时习惯在前面加u
name = u'张三' -
python2不区分str和unicode,但在拼接str和unicode时,str将自动转换成unicode
-
- python3.x默认的字符编码是Unicode(支持中文),默认的文件编码是UTF-8
- python3严格区分了bytes和str,二者不能进行拼接。文本总是unicode,有str表示;二进制数据则由bytes表示。
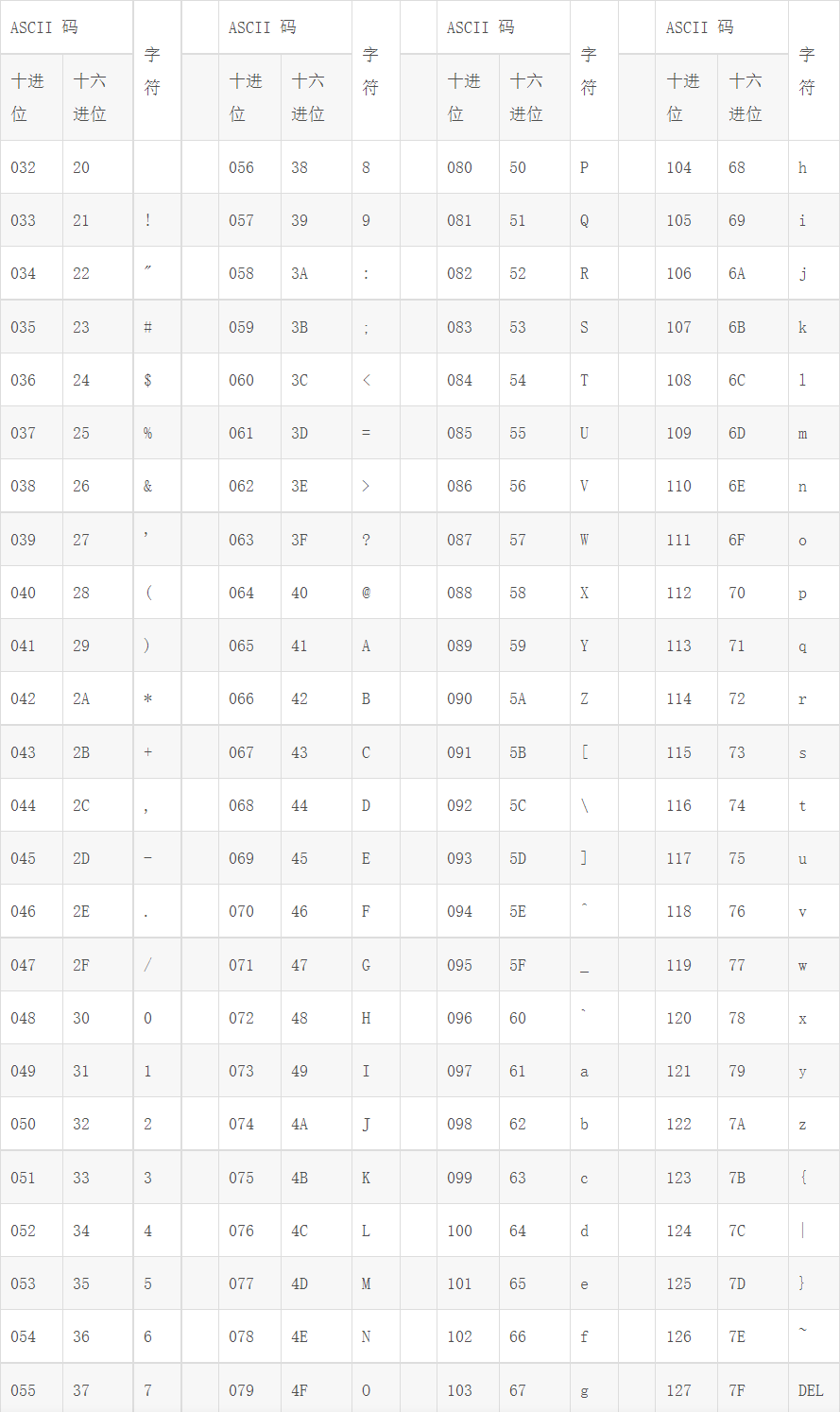
ASCII码表
文件操作简介
1.文件
- 文件其实是操作系统暴露给用户操作计算机硬盘的快捷方式
2.文件操作
- 文件操作流程:
- 打开文件:由应用程序向操作系统发起系统调用open(文件路径,读写模式,字符编码),操作系统打开该文件,对应一块硬盘空间,并返回一个文件对象赋值给一个变量f
- 操作文件:调用文件对象下的读/写方法,会被操作系统转换为读/写硬盘的操作
- 关闭文件:向操作系统发起关闭文件的请求,回收系统资源
f = open('a.txt', 'r', encoding = 'utf-8') # 打开文件
data=f.read() # 操作文件
# 关闭文件
方式1(手动写关闭文件代码):
f.close()
方式2(推荐):
with open() as f:
# 子代码运行结束之后自动调用close()方法
作业
1.统计列表中每个数据值出现的次数并组织成字典战士
eg: l1 = ['jason','jason','kevin','oscar']
结果:{'jason':2,'kevin':1,'oscar':1}
真实数据
l1 = ['jason','jason','kevin','oscar','kevin','tony','kevin']
l1 = ['jason', 'jason', 'kevin', 'oscar', 'kevin', 'tony', 'kevin']
dict_l = {}
for i in l1:
dict_l[i] = l1.count(i)
print(dict_l)
2.编写员工管理系统
1.添加员工信息
2.修改员工薪资
3.查看指定员工
4.查看所有员工
5.删除员工数据
提示:用户数据有编号、姓名、年龄、岗位、薪资
数据格式采用字典:思考如何精准定位具体数据>>>:用户编号的作用
data_dict = {}
while True:
print("""
1.添加员工信息
2.修改员工薪资
3.查看指定员工
4.查看所有员工
5.删除员工数据
""")
func_id = input('请输入功能的编号:').strip()
if func_id == '1':
emp_id = input('请输入员工编号:').strip()
if emp_id in data_dict:
print('该员工编号已经存在')
continue
emp_name = input('请输入员工姓名:').strip()
emp_age = input('请输入员工年龄:').strip()
emp_job = input('请输入员工岗位:').strip()
emp_salary = input('请输入员工薪资:').strip()
temp_dict = {}
temp_dict['emp_id'] = emp_id
temp_dict['emp_name'] = emp_name
temp_dict['emp_age'] = emp_age
temp_dict['emp_job'] = emp_job
temp_dict['emp_salary'] = emp_salary
data_dict[emp_id] = temp_dict # {'1':{}}
elif func_id == '2':
target_emp_id = input('请输入想要修改的员工编号:').strip()
if target_emp_id not in data_dict:
print('当前员工编号不存在 无法修改!!!')
continue
emp_data = data_dict.get(target_emp_id) # {}
new_salary = input('请输入该员工新的薪资:').strip()
emp_data['emp_salary'] = new_salary
data_dict[target_emp_id] = emp_data
print(f'员工编号:{target_emp_id} 员工姓名:{emp_data.get("emp_name")}薪资修改成功')
elif func_id == '3':
target_emp_id = input('请输入想要查询的员工编号:').strip()
if target_emp_id not in data_dict:
continue
emp_data = data_dict.get(target_emp_id)
print(f"""
--------------------emp of info------------------
编号:{emp_data.get('emp_id')}
姓名:{emp_data.get('emp_name')}
年龄:{emp_data.get('emp_age')}
岗位:{emp_data.get('emp_job')}
薪资:{emp_data.get('emp_salary')}
-------------------------------------------------
""")
elif func_id == '4':
all_emp_data = data_dict.values()
for emp_data in all_emp_data:
print(f"""
--------------------emp of info------------------
编号:{emp_data.get('emp_id')}
姓名:{emp_data.get('emp_name')}
年龄:{emp_data.get('emp_age')}
岗位:{emp_data.get('emp_job')}
薪资:{emp_data.get('emp_salary')}
-------------------------------------------------
""")
elif func_id == '5':
target_delete_id = input("请输入想要删除的员工编号:").strip()
if target_delete_id not in data_dict:
print('员工编号不存在')
continue
data_dict.pop(target_delete_id)
print(f'员工编号{target_delete_id}数据删除成功')
else:
print('输入指令错误,请重新输入')
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号