

一致性 hash 原理与 golang 实现
前置要求:
- 熟悉 hash 算法
1 简介
hash 算法可以将数据随机的分配到分布式集群的所有节点,并且相同输入的输出总是相同的,所以广泛应用于缓存或分布式存储中.但当集群中任意节点失效或集群加入了新节点时,原有的 hash 结果就会失效,需要重新对所有数据进行 hash 计算.这样是不可接受的.如下图所示,当 S-2 节点从集群中删除后,整个集群的 hash 算法就需要因此发生变化,从而使得原有数据全部失效.
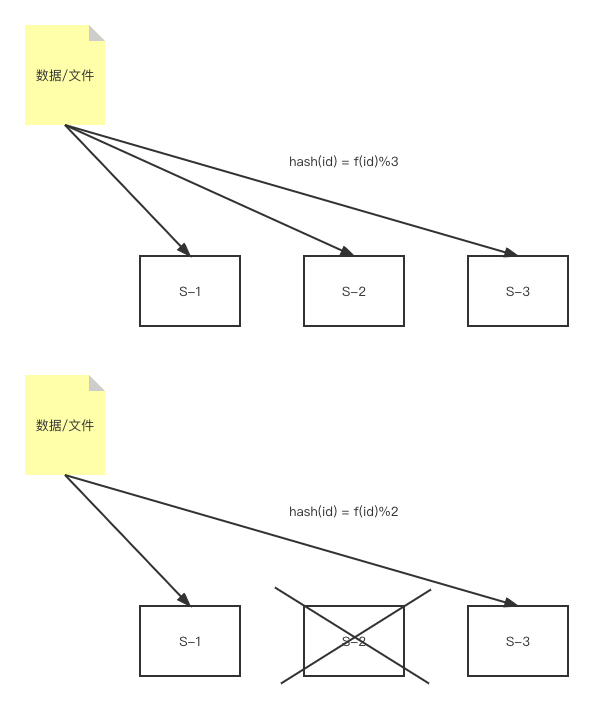
f(id) 也是 hash 算法,后面的求余数是为了防止结果溢出
人们为了降低插入/删除节点对整个集群的影响,需要一种新的算法来应对上述的问题.仔细观察上图,我们可以发现,hash 算法整体只有被除数发生了变化,而前面的 f(id)计算结果仍是相同的,那么能不能直接使用 f(id)的结果而不再取余呢?
一致性 hash 算法,在 1997 年由麻省理工学院的Karger等人在解决分布式Cache中提出的,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT(磁力链接,IPFS 中的核心技术)可以在P2P环境中真正得到应用。
但是现在一致性 hash 算法在分布式系统中也得到了了广泛应用,比如在分布式 K/V缓存集群中.简单描述流程:
- 构建一个从 0 到 232-1 顺时针组织的环
- 使用每个节点的唯一 id 计算得到一个 232的 hash 值,将其映射到环上
- 每个插入的数据计算其 hash 值,从 hash 值开始,在环上顺时针找到第一个节点,存入其中.
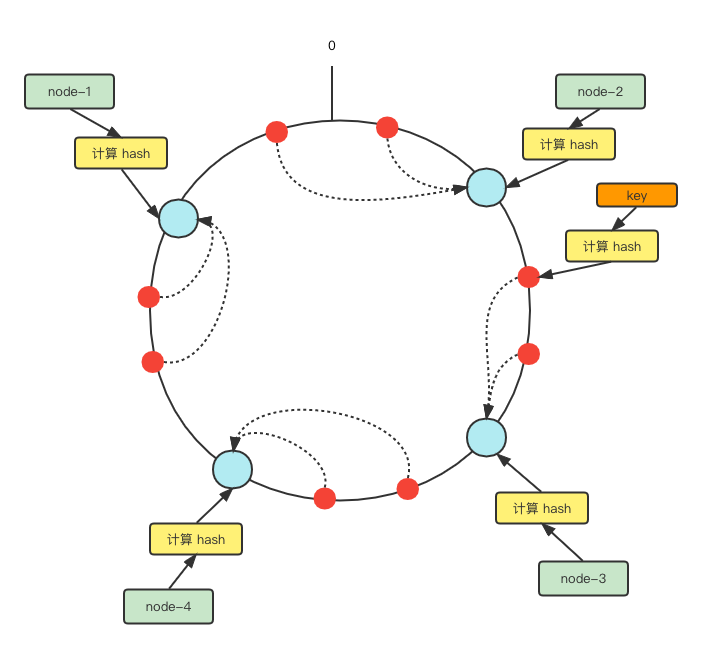
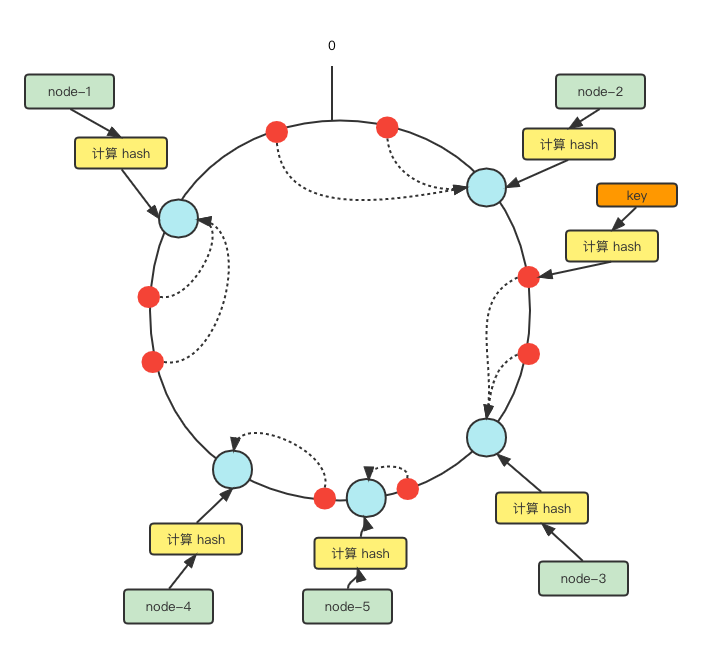
添加一台节点到集群中,将他 hash 到环上,此时只会有部分数据受到影响.大部分数据可以正常使用.
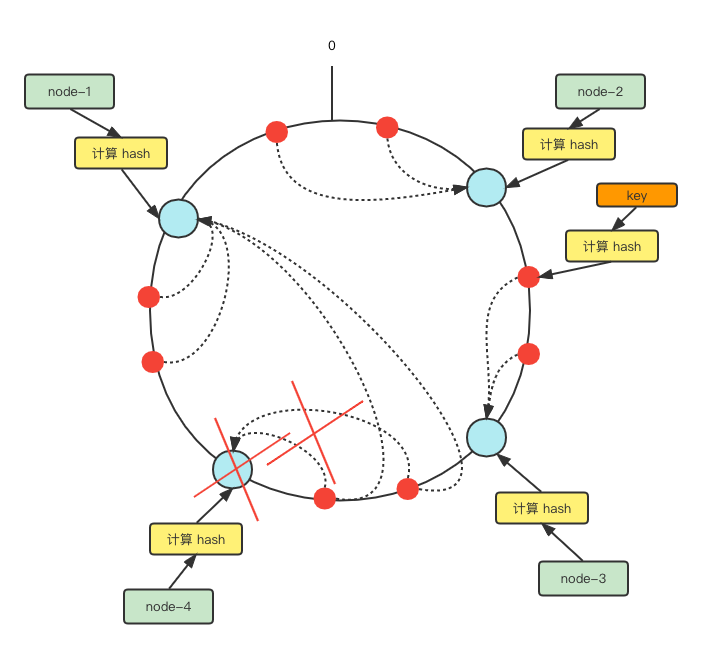
删除一个节点,也只会有部分数据受到影响.
2 Golang 实现
一句话描述一致性hash 就是让每个节点从具体映射的一个值升级成映射一片范围.
2.1 一致性 hash 实现
import (
"hash/crc32"
"sort"
"strconv"
)
type Hash func(date []byte) uint32
type Map struct {
hash Hash //使用的 Hash 函数
replicas int //副本数,用于解决少两节点在环上分布不均匀的问题
keys []int //节点 hash 值排序
hashMap map[int]string //节点 hash 值与节点信息的映射
}
/**
* Map 初始化接口
* @param replicas 副本数量, fn 指定的 hash 函数
* @return 返回创建成功后的节点对象指针
*/
func New(replicas int, fn Hash) *Map {
m := &Map{
replicas: replicas,
hash: fn,
hashMap: make(map[int]string),
}
// 没有指定 hash 函数时指定默认的函数
if m.hash == nil {
m.hash = crc32.ChecksumIEEE
}
return m
}
/**
* Map 添加节点接口
* @param keys 要添加的节点信息
*/
func (m *Map) Add(keys ...string) {
for _, key := range keys {
for i := 0; i < m.replicas; i++ {
hash := int(m.hash([]byte(strconv.Itoa(i) + key)))
m.keys = append(m.keys, hash)
m.hashMap[hash] = key
}
}
// 对节点 hash 值进行排序,相当于顺时针的环
sort.Ints(m.keys)
}
/**
* 在 Map 中删除指定节点
* @param keys 要删除的节点
*/
func (m *Map) Del(key string) {
for i := 0; i < m.replicas; i++ {
hash := int(m.hash([]byte(strconv.Itoa(i) + key)))
for j := 0; j < len(m.keys); j++ {
if m.keys[j] == hash {
m.keys = append(m.keys[:j], m.keys[j+1:]...)
break
}
}
delete(m.hashMap, hash)
}
}
/**
* 获取指定key 对应的节点
* @param key 对应数据的 key
* @return 返回指定数据对应的节点
*/
func (m *Map) Get(key string) string {
if len(m.keys) == 0 {
return ""
}
hash := int(m.hash([]byte(key)))
idx := sort.Search(len(m.keys), func(i int) bool {
return m.keys[i] >= hash
})
// 求余数的原因是当hash 值大于 keys 中的所有时
// 这个 hash 应该存在环上的第一个节点上
return m.hashMap[m.keys[idx%len(m.keys)]]
}
2.2 服务注册与发现
一致性 hash 节点会部署在多台机器上,且不定期会有节点加入或节点暂时/永久下线.所以我们需要使用服务注册与发现对集群外提供服务,同时一致性 hash 也需要动态的添加删除节点.在这里我们使用 etcd 进行服务注册与发现.
- 每个节点向 etcd 中注册自身,并定使用lease + keepalive保持最新,key 为相同前缀+自身地址
- 获取所有相同前缀的节点信息并初始化 一致性hash
- 使用 watch 机制 监听该前缀
- 根据 watch 结果增加或删除节点
总结
一致性 hash 概念简单,使用广泛,从事后端开发非常有必要学习这项知识.
限于本文的作者水平,文中的错误在所难免,恳请大家批评指正.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号