1 #include<cstdio>
2 #include<iostream>
3 #include<algorithm>
4 #include<queue>
5
6 using namespace std;
7
8 const int maxn = 100005;
9
10 struct node{
11 int w, id, ans;
12 node() { }
13 bool operator < (const node & p) const{
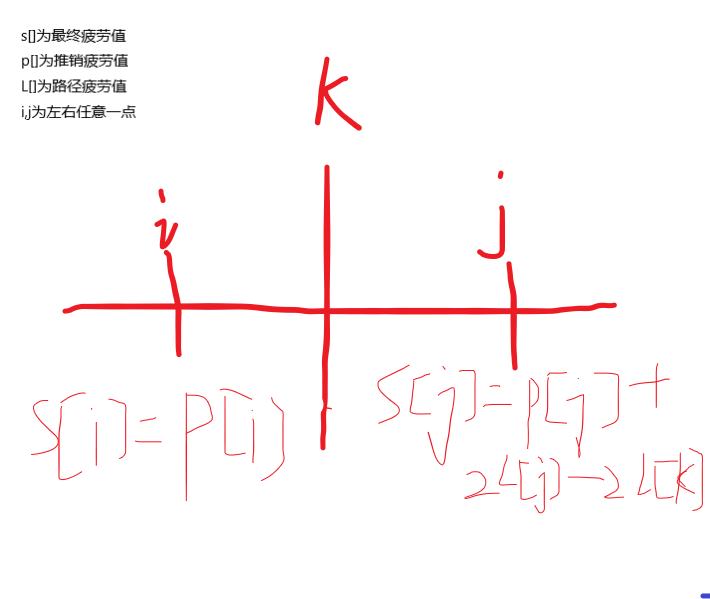
14 return w + 2 * id < p.w + 2 * p.id;
15 }//重载运算符
16 } e[maxn];
17
18
19 priority_queue <int> a;//左边点
20 priority_queue <node> b;//右边点
21
22 int m, cnt, n, k, j;
23
24 inline void fir(){
25 m = b.top().ans;//第一个值为最大值
26 printf("%d\n", m);
27 cnt = n - 1;//cnt用来记录当前i
28 k = b.top().id;//k转移到最大值的id
29 b.pop();
30 for(j = 1; j <= n; j++){
31 if(e[j].id >= k) break;//右边点
32 else a.push(e[j].w);//左边点
33 }//更新
34 }//第一次
35
36 inline void solve(){
37 while(cnt--){
38 if(b.top().ans - 2 * k >= a.top()){
39 if(b.top().id <= k){//更新,若原右边点现在在左边
40 b.pop();
41 cnt++;
42 continue;
43 }//右边堆顶比左边堆顶大
44 m += b.top().ans - k * 2;//加最大值
45 k = b.top().id;//k转移
46 b.pop();
47 while(j++ <= n){
48 if(e[j].id >= k) break;
49 else{
50 a.push(e[j].w);
51 b.pop();
52 }//右边转移到左边
53 }
54 }
55 else{
56 m += a.top();
57 a.pop();
58 }//左边堆顶大
59 printf("%d\n", m);
60 }
61 }
62
63
64 int main(){
65 scanf("%d", &n);
66 for(int i = 1; i <= n; i++) scanf("%d", &e[i].id);
67 for(int i = 1; i <= n; i++){
68 scanf("%d", &e[i].w);
69 e[i].ans = e[i].w + 2 * e[i].id;
70 b.push(e[i]);
71 }
72 fir();
73 solve();
74 return 0;
75 }



 浙公网安备 33010602011771号
浙公网安备 33010602011771号