

kafka
【
概念?
分布式消息队列。底层是scala。对消息保存时根据topic进行归类。
角色:producer consumer broker
集群:多个kafka实例,每个实例称为broker。
注意:无论是kafka还是consumer,都依赖zookeeper保存一些信息,来保证系统可用性。
同时支持单播和多播。
常用消息系统对比?
rabbitMQ:支持多种协议和通信模式,支持数据持久化,但是比较重量级。
redis:短消息性能好。
ActiveMQ:点对点模式,支持持久化
kafka:分布式,数据持久化,同时支持在线和离线处理。
设计目标?
高吞吐率、消息持久化、完全分布式(支持水平扩展)、同时适应流处理和离线批处理
消息系统?
发布者将消息推给消息系统,订阅者可以拉或者推的方式从系统中拿数据。
】
【
怎么用?
1.启动zk
2.启动kafka server
3.创建主题
4.启动生产者
5.启动消费者
每个生产者生产什么主题的内容,由生产者自己决定。
】
【
内部原理?
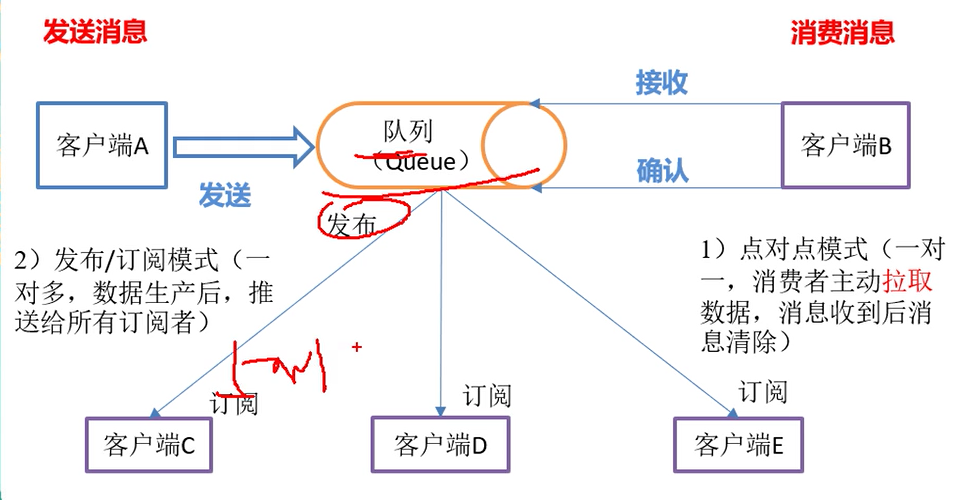
1.接收消息的两种模式
点对点:拉取数据速度可以由客户端控制,但是需要主动拉取数据,需要实时监控队列。
发布订阅模式:多个客户端速度不一致,但是可以主动接收消息。
kafka架构?客户端请求只能由leader处理
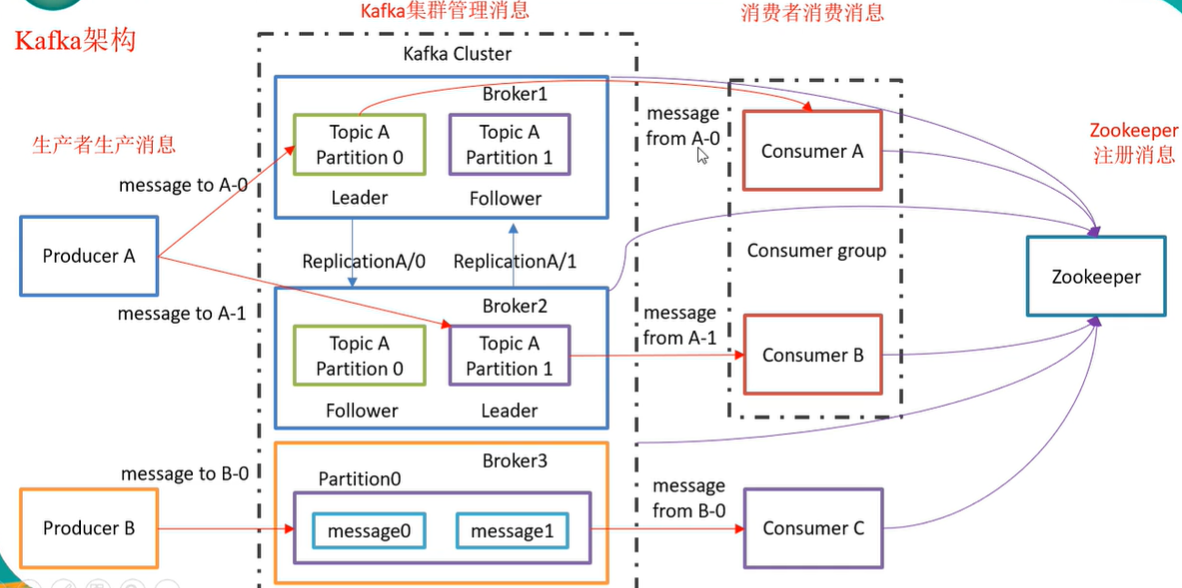
zookeeper:管理broker集群,管理元数据
消费组:在同一个消费组中的消费者,对同一条消息,只能消费1次。
offset:某个消费组,对于某个主题下的某个分区的消费偏移量。
主题
消息以主题进行数据归纳。
生产者,消费者一般以主题为单位进行操作,但是也可以以比主题更细的分区为单位进行操作。
分区和副本
分区:针对某个主题下数据的拆分。目的:让消费者拿数据更快。
-分区中数据是有序的,且不可修改,但是不同分区中数据是无序的。
-如何保证1个主题下的数据一定是有序的???让1个主题下只有1个分区。
-分区数量决定了每个消费者组中并发消费者的最大数量。
-分区偏移量:让消费者知道自己消费到什么地方,可以让消费者自定义消费某1条消息。
副本
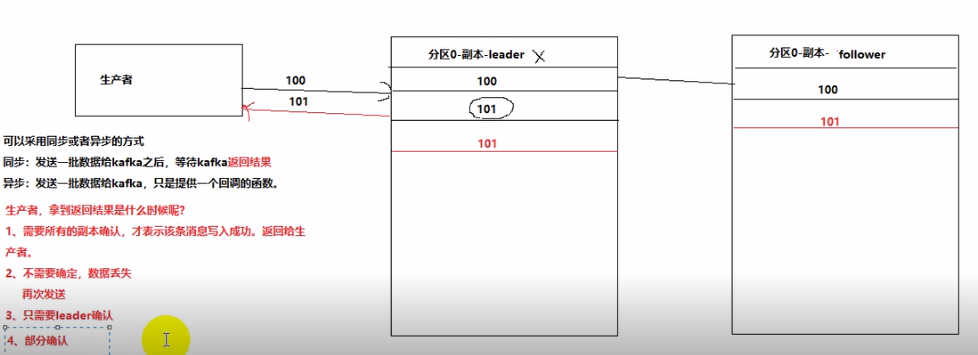
-副本作用:让kafka读取和写入数据时高可靠。
-分区副本因子
当有多个副本时,kafka不是让所有副本都提供读取功能。
-对外提供读写服务的只有leader。由leader同步到follower。
如何解决副本丢失?如何解决消息丢失?如何解决重复消费?
注意:如果某个分区中的1个副本挂掉,只会在剩余副本中选出1个leader,但是不会在其他的broker中再启动1个副本,因为重新启动会存在数据传递,占用网络IO,kafka是一个高吞吐量的消息系统,这个情况不允许发生。
如果所有副本都挂了,生产者将写入不成功。
-副本中是怎么选出leader的?
-ack机制(部分确认)
-controller broker:管理所有的broker
kafka如何解决数据堆积?
kafkax消息的写入过程?
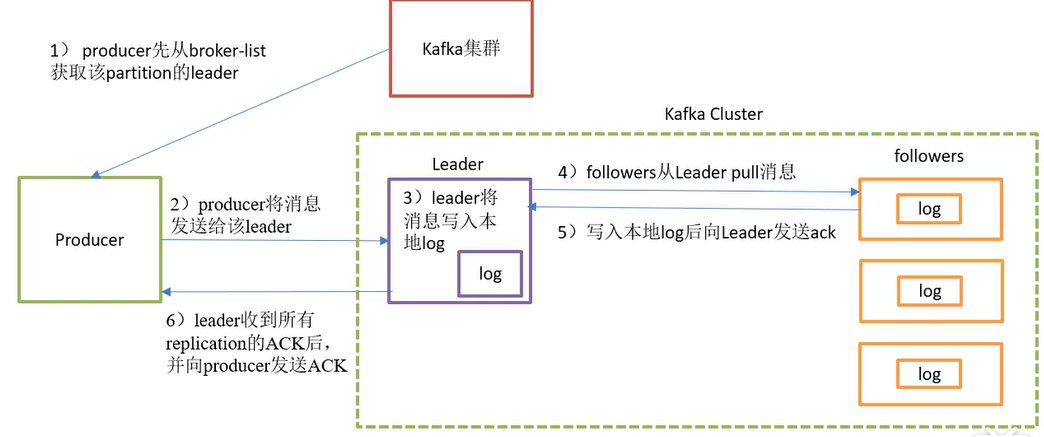
写入方式:生产者采用push的方式将消息发布到broker,每条消息追加到分区中,通过顺序写入磁盘增加吞吐量。
分区:区内有序,每一个消息被赋予一个唯一的offset值。
分区的原因:1.方便在集群中扩展,每个Partition可以通过调整来适应它所在的机器 2.提高并发
分区的原则:1.指定了partition,就直接使用;2.未指定partition但指定了key,hash ; 3.轮询
写入流程:
保证消息不丢失?ack选择all
kafka消息的存储机制?
存储方式:
1.本地:log
2.zk: 元数据 broker的id, 分区,副本等;consumer的offset等
kafka消费过程?
高级API:不用自行管理offset,系统通过zk自行管理
低级API:自行指定
通过换组可以重复消费
消费方式:消费者以pull的方式消费,可以自己控制消息消费的速率。
如何保证kafka消息的有序性?
kafka如何保证并发情况下消息只被消费1次?
kafka吞吐量高的原因
1.顺序读写并且批量发送
消息不断被追加到文件中,充分利用磁盘的顺序读写性能。
顺序读写不需要磁盘磁头的寻道时间,只需很少的扇区旋转时间,所以速度快于随机读写。
2.零拷贝
3.分区
每个topic被分为多个partition,每个partition又被分为多个segment,每次操作只针对一小部分。
kafka如何解决查找效率的问题?
1.数据文件的分段
例如offset是0-99,将消息分成几段,放在单独的数据文件中,以最小的offset命名,利用二分查找定位;
2. 为数据文件创建索引
为每个分段后的文件创建索引,
kafka如何保证消息消费的顺序性?
每个分区只发给一个消费者组。因为有多个分区,可以在多个消费者组中进行负载均衡。
只能保证分区上的强顺序性,如果需要保证topic中所有消息的有序性,只能让这个topic有一个分区。
kafka消息的过期机制
1.删除
为了防止删除时阻塞读操作,采用copy on write,所以读操作是在一个静态的快照副本上进行的。
2.压缩
只保留key最后一个版本的数据 这个时候读取时,offset是不连续的,向后读取。
场景:key是用户id,value是用户资料信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号