1-Python - dict
About
在之前的学习中,我们知道,无论字符串、列表、元组都是将数据组织到一个有序的结构中,然后通过下标索引处理数据,这几种数据结构虽然已经满足大多数场景了,但是依然不够丰满,现在了解一种通过名字(key)来处理数据的数据类型,这种名字对应数值的关系我们称之为映射关系,而这种数据类型就是前文或多或少的了解过的——字典(dict)。字典是目前为止,Python唯一的内建的映射类型的数据类型。需要说明的是,从Python 3.6开始,字典元素的存储顺序由各键值对根据存储时的顺序而定(但依然不支持索引取值),并优化了空间上的开销,更节省内存占用。
通过存储同样的数据,利用列表和字典的不同之处来学习字典。比如存储商品的名称和编号,可以用列表来存。
goods = ['apple', 'orange', 'banana']
price = ['20', '24', '32']
有三个商品,对应三个价钱,那想要知道banana的价钱怎么办?
goods = ['apple', 'orange', 'banana']
price = ['20', '24', '32']
banana = price[goods.index('banana')]
print(banana) # 32
如上例这样取值很麻烦,而且,你可能要问为什么价钱要存成字符串类型?
goods = ['apple', 'orange', 'banana']
price = [20, 24, 32]
banana = price[goods.index('banana')]
print(banana) # 32
上例虽然可以存储为int类型。但要是存个电话号码呢?比如存010998998这样的数字怎么存?
number = [010, 998, 998] # SyntaxError: invalid token
这个问题告诉我们,碰到类似的数据,或者是0开头的数据,尽量存储为字符串类型,而不是整型。另外,虽然列表能存储多种数据类型,但是通过上面的商品和价钱的例子,在用列表的时候,应该尽量存储数据为单一的类型。
好,言归正传,再来看看更好的选择。
goods = {'apple': '20', 'orange': '24', 'banana': '32'}
print(goods['banana']) # 20
上例采用了字典来存储数据,是不是简单多了?接下来就学习一下字典的用法。
字典的基本操作
字典是无序(Python 3.6版本之前)的可变类型数据类型。我们通过一对{}来创建字典(dict),字典内的值是通过:来存储的,也就是key:value的格式。
d1 = {}
d2 = dict()
print(d1, d2) # {} {}
d3 = {'apple': 20}
print(d3) # {'apple': 20}
print(d3['apple']) # 20
使用内建函数dict()来创建字典
d = dict(apple='20', orange='24')
print(d) # {'apple': '20', 'orange': '24'}
字典的增删改查
d = dict(apple=20, orange=24)
print(d['apple']) # 字典取值
d['apple'] = 40 # 为字典的apple键重新赋值
print(d)
d['banana'] = 32 # 为字典新添加一对键值对
print(d)
del d['apple']
del d['orange'], d['banana']
del d
我们可以通过字典加中括号的形式,来对字典进行增删改查的操作。但需要注意的是,通过中括号取值的时候和del声明删除字典的key时,该key必须存在,否则报错(KeyError)。
成员资格测试:in, not in
这都没啥好说的了,字典中的成员资格测试就是判断某个key在不在字典中。
d = {'a': 1, 'b': 2, 'c': 3}
print('a' in d) # True
print('a' not in d) # False
需要注意的是,成员资格测试只能判断key而不能判断某个value是否存在于字典。
另外,字典相较于序列类型,它有更优查询性能:
In [1]: l = [1, 2, 3, 4, 5]
In [2]: d = {'a':1, 'b':2,'c':3}
In [3]: % timeit 1 in l
46.3 ns ± 0.316 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
In [4]: % timeit 'a' in d
53.2 ns ± 0.395 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
In [5]: % timeit 5 in l
121 ns ± 0.866 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
In [6]: % timeit 'c' in d
53.4 ns ± 0.164 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
由上例可以看出,列表的成员资格测试是不稳定的,而字典稳定。这是因为列表的成员资格判断取决于判断元素处于列表的什么位置,如果是列表的靠前位置,速度肯定快,如果是末尾,就要从头到尾挨着判断,速度就慢下来了。
而字典的存储结构是由key、哈希表、value三部分组成的,字典在创建一个键值对的时候,首先将key通过哈希得到结果,结果的位置上就是value,然后这个对应关系被保存在哈希表上。查询的时候,无论该key在何方,只要哈希后根据结果去哈希表上就能找到对应的value。所以查询速度快而且稳定,但由于要维护哈希表,在存储和修改时可能会相对麻烦些。
目前为止,字典不支持索!引!取!值!!!
字典能索引取值吗?当习惯用索引取值后,可能不小心也对字典使用索引取值。
d = {'a': 1, 'b': 2}
print(d['a']) # 1
print(d[0]) # KeyError: 0
在字典中,字典加中括号的形式是在取key对应的值,而不是之前学过的按照索引取值,字典是不可以按照索引取值的,通过第5行的报错也可以看到,报的错误是“KeyError”,意思是字典中没有“0”这个key。
需要注意的是,字典的key可以是任何不可变类型,比如整形、浮点型、字符串、元组(元组内的每个元素也必须是不可变的类型)类型可以成为字典的key,并且所有的key都是唯一的。而value则不限制类型。
d = {12.3: 'a', (1, 2): 'b', 'c': 2, 1: 1}
print(d) # {12.3: 'a', (1, 2): 'b', 'c': 2, 1: 1}
不是什么元组都能成为字典的key
需要注意的是,如果字典的key是元组,那么这个元组就不能是普通的元组了。我们知道元组是可哈希的数据类型,这种说法是基于元组内的元素都是不可变类型才成立的。
print(hash((1, 'a', 2.3, (4, 5)))) # -1680772126
t1 = (1, 'a', 2.3, (4, 5), [6, 7])
print(t1) # (1, 'a', 2.3, (4, 5), [6, 7])
print(hash(t1)) # TypeError: unhashable type: 'list'
上例中,虽然列表(字典和集合也行)可以成为元组的元素,但是,此时这个元组已经变成了不可哈希了。这种元组也就无法成为字典的key。
t1 = (1, 'a', 2.3, (4, 5))
t2 = (1, 'a', 2.3, (4, 5), [6, 7])
d = {t1: 1, t2: 2} # TypeError: unhashable type: 'list'
上例告诉我们,只有当元组内的所有元素类型都是可哈希类型才可以成为字典的key。
字典的常用操作
再来看字典的其他常用操作。
遍历字典
d = {'a': 1, 'b': 2, 'c': 3}
for k in d:
print(k)
'''
a
b
c
'''
由上例可以看到,遍历的时候,字典默认返回key,那么怎么分别取key和value呢?
d = {'a': 1, 'b': 2, 'c': 3}
print(d.keys()) # dict_keys(['a', 'b', 'c'])
for k in d.keys():
print(k)
'''
a
b
c
'''
print(d.values()) # dict_values([1, 2, 3])
for k in d.values():
print(k)
'''
1
2
3
'''
上例中,d.keys()取出来的是字典所有的key,而d.values()取出的是所有的value。
那怎么同时取key和value呢:
d = {'a': 1, 'b': 2, 'c': 3}
for k in d.items():
print(k)
'''
('a', 1)
('b', 2)
('c', 3)
'''
for k, v in d.items():
print(k, v)
'''
a 1
b 2
c 3
'''
第一个for循环,我们通过d.items()以元组的形式拿到key和value。第二个循环,相当于平行赋值,每次从d.items()中取出一个元组,然后平行赋值给k v两个变量。
dict.get(key, None)
之前说,我们通过字典加中括号取值的时候,当key不存在的时候,会报错:
d = {'a': 1, 'b': 2, 'c': 3}
print(d['a']) # 1
print(d['w']) # KeyError: 'w'
报错~嗯2333333,很明显是不行滴,怎么办呢,我们可以通过dict.get()方法来避免这个问题:
d = {'a': 1, 'b': 2, 'c': 3}
print(d['a']) # 1
print(d.get('a')) # 1
print(d.get('w')) # None
print(d.get('w', 'hi man, 你想要的键不存在呀')) # hi man, 你想要的键不存在呀
dict.get()可以获取指定的key,当key不存在的时候,默认会返回一个None,意思是没取到key,而且我们可以修改这个返回值,更加灵活。
dict.setdefault(key, None)
d = {'a': 1, 'b': 2, 'c': 3}
print(d.setdefault('a')) # 1
print(d.setdefault('x', 'y')) # y
print(d) # {'a': 1, 'b': 2, 'c': 3, 'x': 'y'}
dict.setdefault()方法跟dict.get()方法类似,获取字典指定的key,存在则返回对应的value,如果key不存在的话,它会将我们指定的key添加到字典中,默认的value是None,该value也可以自己指定。
dict.update(obj)
字典可以拼接(+)吗?
d1 = {'a': 1, 'b': 2}
d2 = {'c': 3, 'd': 4}
d3 = d1 + d2 # TypeError: unsupported operand type(s) for +: 'dict' and 'dict'
显然是不行的!
但我们可以通过dict.upate()方法来完成类似的操作:
d1 = {'a': 1, 'b': 2}
d2 = {'c': 3, 'd': 4}
d2.update(d1)
print(d2) # {'c': 3, 'd': 4, 'a': 1, 'b': 2}
此方法将一个字典(d1)的键值对一次性的更新到当前字典(d2),如果两个字典中存在同样的键,更新的时候,对应的值以另一个字典(d1)的值为准。
注意,字典的键是唯一的,但是值可以是相同的。
dict.pop() & dict.popitem()
我们在上面也了解过了del来删除字典以及删除字典的键,这里我们再介绍两个方法删除字典的键。
d = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
print(d.pop('a'), d) # 1 {'b': 2, 'c': 3, 'd': 4}
# print(d.pop('w')) # KeyError: 'w'
print(d.popitem()) # ('d', 4)
d.pop()方法删除字典指定的key,返回对应的value,如果key不存在,则抛出KeyError错误。
而d.popitem()在Python2.7(Python 2.x的最后一个版本)和Python3.6(及以上版本)删除的是最后一个key。而其他版本(如Python2.4和Python3.5版本)则是随机删除一对键值对。另外,如果字典为空,上述两个方法都将抛出KeyError的错误。
dict.clear()
要清空一个字典,使用dict.clear()方法,这没啥好解释的:
d = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
d.clear()
print(d) # {}
dict.fromkeys()
d = dict.fromkeys(['a', 'b'], None)
print(d) # {'a': None, 'b': None}
d1 = dict.fromkeys(['a', 'b'], '自定义value')
print(d1) # {'a': '自定义value', 'b': '自定义value'}
dict.fromkeys(seq, None)用来生成字典 ,第一个参数seq为序列类型(如上例中的字符串,列表)作为字典的key,第二个参数为每一个key对应的value,如若不设置则默认为None。
dict.contains(key)
dict.__contains__(key)用来判断某一个key是否在字典中。
d = dict.fromkeys(['a', 'b'], None)
print(d.__contains__('a')) # True
需要注意的是,dict.__contains__(key)适用于Python2和3中,而Python2中,多了一个d.has_key(key)的方法,同样用来判断key是否在字典中。但这方法在Python3中取消了。
d = dict.fromkeys(['a', 'b'], None)
print(d.__contains__('a')) # True
print(d.has_key('b')) # True
来个小结,下表列举了字典中的常用方法或者可以应用于字典的函数或者声明语句:
| 方法 | 描述 | 重要程度 |
|---|---|---|
| x in dict | 成员运算符 | *** |
| help(dict) | 获取字典的帮助信息 | ***** |
| len(dict) | 返回字典项目的个数 | ***** |
| str(dict) | 转字典类型为字符串类型 | **** |
| type(dict) | 查看类型 | **** |
| sorted(dict) | 字典排序 | ***** |
| dict.fromkeys(seq) | 创建新字典 | ***** |
| dict1.update(dict2) | 另一个字典更新当前字典 | ***** |
| dict.keys () | 以列表的形式返回字典的所有的键 | ***** |
| dict.values() | 以列表的形式返回字典的所有的值 | ***** |
| dict.setdefault(key,default=None) | 返回字典的指定key对应的value,如不存在则添加为字典的key,value则默认None | *** |
| dict.popitem() | 随机删除字典中的键值对 | *** |
| dict.pop() | 删除字典中的指定key,并返回对应的value | ***** |
| del dict | 删除字典或其内的指定键 | *** |
| dict.clear() | 将字典清空 | *** |
字典的嵌套
字典的嵌套类型非常的丰富而且手法多变。
d = {'a': 'b', 1: 'c', (2, 3): [4, 5], 's': {6, 7}}
for item in d:
print(item)
'''
a
1
s
(2, 3)
'''
还是那句话:字典的key必须是可哈希类型,并且是唯一的,而value则是什么都行。
字典视图
python3.9
我已经和无数的学生强调过,字典不是序列类型(序列类型有个特点就是每一个元素都有下标索引,能根据索引取值),字典是映射(键值对)类型的数据。
所以,我们先上代码证明它是无序的:
from collections.abc import Sequence
print(isinstance({1, 2, 3}, Sequence)) # False
print(isinstance({'a': 1, "b": 2}, Sequence)) # False
print(isinstance([1, 2, 3], Sequence)) # True
print(isinstance((1, 2, 3), Sequence)) # True
print(isinstance("abcd", Sequence)) # True
一目了然,列表、元组、字符串是序列类型;字典和set是无序类型。
而你可能会说Python3.6之后,字典就是有序的了!的确,实际操作起来,的确是这样的现象,但本质上它还是无需的。
这就要说一个叫做"字典视图对象"的东西了。
看官网https://docs.python.org/zh-cn/3.9/library/stdtypes.html#dictionary-view-objects:
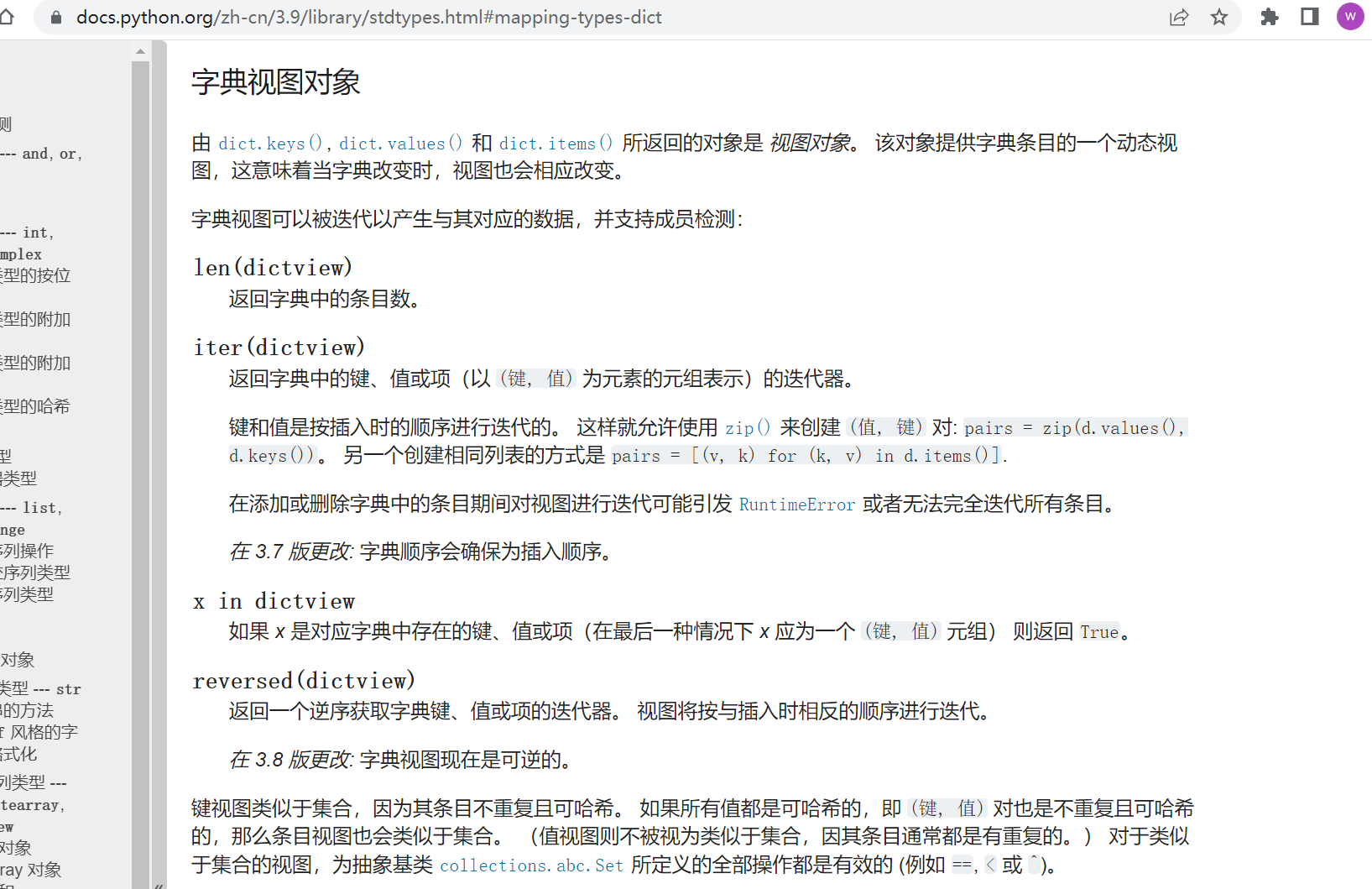
你可以对字典视图做如上操作,但是就是不能对它进行索引取值。
欢迎斧正,that's all

 浙公网安备 33010602011771号
浙公网安备 33010602011771号