1-Django - ORM基础
ORM简介
ORM(Object Relational Mapping)是对象-关系-映射的简称。
ORM是MVC框架中的重要的部分。它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的工作量,不需要面对因数据库变更而导致的无效劳动。
在ORM中,有三种对应关系:
- 类对应表。
- 类属性对应表字段。
- 类对象对应表记录。
如何在Django中使用ORM
- 创建对象映射关系,即创建模型类。所谓的创建模型类,就是在app下的models.py中,以类和字段的形式定义表的字段。
- 配置数据库连接。有了对应关系,就可以通过命令在数据库中生成具体表了,但前提是你需要在Django中配置数据连接,只有连接配置好了,才能执行命令。
- 数据库迁移。所谓数据库迁移,指的是两个命令:
makemigrations命令用来读取你在models.py中的类和属性,生成真正的映射关系文件。migrate命令读取映射文件,在数据库中真正的生成表结构。
- 在项目中写ORM。前面3步都做完了,你就可以通过ORM来代替SQL语句操作表记录了,当然,ORM语句最后的执行也会"翻译"成SQL语句来真正执行,所以,ORM也存在性能稍差的问题!不过,ORM也有接口供你生写SQL语句。
接下来,根据上面的流程来看看都是怎么玩的吧!
创建模型类
在app中的models.py中:
from django.db import models
# Create your models here.
class Book(models.Model):
# 如果表里面没有写主键,表里面会自动生成一个自增主键字段,叫做id字段,orm要求每个表里面必须要写一个主键
# 你也可以手动的指定主键字段比如 nid字段
# nid = models.AutoField(primary_key=True) # int类型,primary key auto_increment
title = models.CharField(max_length=32, verbose_name='书籍名称') # # 和varchar(32)是一样的,32个字符
price = models.FloatField(verbose_name='书籍价格') # 默认支持最大的浮点数,想要精确,使用下面的DecimalField
# price = models.DecimalField(max_digits=8, decimal_places=2) # max_digits最大位数,decimal_places小数部分占多少位
pub_date = models.DateField(verbose_name='出版日期') # # 必须存这种格式"2018-12-12"
publish = models.CharField(max_length=32, verbose_name='出版社名称')
# 当打印book对象时,通过 __str__ 的返回更友好的结果
def __str__(self):
return self.title
更多字段和参数
每个字段有一些特有的参数,例如,CharField需要max_length参数来指定VARCHAR数据库字段的大小。还有一些适用于所有字段的通用参数。 这些参数在文档中有详细定义,这里我们只简单介绍一些最常用的,先来看看字段:
CharField:字符串字段, 用于较短的字符串。CharField要求必须有一个参数maxlength, 用于从数据库层和Django校验层限制该字段所允许的最大字符数。IntegerField:用于保存一个整数。DecimalField:一个浮点数. 必须 提供两个参数:max_digits:总位数(不包括小数点和符号)。decimal_places:小数位数。
AutoField:一个IntegerField, 添加记录时它会自动增长,你通常不需要直接使用这个字段,如果你不指定主键的话,系统会自动添加一个主键字段到你的 model。BooleanField:一个True/False字段. 可以用来处理checkbox。TextField:一个容量很大的文本字段,通常用来存储textarea标签的值。EmailField:一个带有检查Email合法性的CharField,不接受maxlength参数。DateField:一个日期字段,共有下列额外的可选参数:auto_now:当对象被保存时(更新或者添加都行),自动将该字段的值设置为当前时间.通常用于表示 "last-modified" 时间戳。auto_now_add:当对象首次被创建时,自动将该字段的值设置为当前时间.通常用于表示对象创建时间。
DateTimeField:日期时间字段,类似 DateField 支持同样的附加选项。FileField:文件上传字段,要求一个必须有的参数upload_to,一个用于保存上载文件的本地文件系统路径。ImageField:类似FileField, 不过要校验上传对象是否是一个合法图片,有两个参数:height_fieldwidth_field- 如果提供这两个参数,则图片将按提供的高度和宽度规格保存。
URLField:用于保存 URL,若verify_exists参数为True(默认),给定的 URL 会预先检查是否存在( 即URL是否被有效装入且没有返回404响应)。NullBooleanField:类似BooleanField,不过允许 NULL 作为其中一个选项,推荐使用这个字段而不要用BooleanField加null=True选项,常用于选择框<select>(三个可选择的值: "Unknown", "Yes" 和 "No" ) 来表示这种字段数据。SlugField:"Slug" 是一个报纸术语。slug 是某个东西的小小标记(短签),只包含字母、数字、下划线和连字符,它们通常用于URLs。若你使用 Django 开发版本,你可以指定maxlength. 若maxlength未指定, Django 会使用默认长度: 50。在 以前的 Django 版本,没有任何办法改变50 这个长度。XMLField:一个校验值是否为合法XML的TextField,必须提供参数:schema_path, 它是一个用来校验文本的RelaxNG schema的文件系统路径。FilePathField:可选项目为某个特定目录下的文件名,支持三个特殊的参数,其中第一个是必须提供的。path:必需参数,一个目录的绝对文件系统路径,FilePathField据此得到可选项目。match:可选参数,一个正则表达式,作为一个字符串,FilePathField将使用它过滤文件名。recursive:可选参数,要么 True 要么 False,默认值是 False,是否包括 path 下面的全部子目录。- 这三个参数可以同时使用。
IPAddressField:字符串形式的 IP 地址。CommaSeparatedIntegerField:用于存放逗号分隔的整数值,类似CharField,必须要有maxlength参数。
再来看参数:
null:如果为True,Django 将用NULL 来在数据库中存储空值。 默认值是 False.blank:如果为True,该字段允许不填。默认为False。要注意,这与 null 不同。null纯粹是数据库范畴的,而 blank 是数据验证范畴的。如果一个字段的blank=True,表单的验证将允许该字段是空值。如果字段的blank=False,该字段就是必填的。default:字段的默认值。可以是一个值或者可调用对象。如果可调用 ,每有新对象被创建它都会被调用,如果你的字段没有设置可以为空,那么将来如果我们后添加一个字段,这个字段就要给一个default值。primary_key:如果为True,那么这个字段就是模型的主键。如果你没有指定任何一个字段的primary_key=True,Django 就会自动添加一个IntegerField字段做为主键,所以除非你想覆盖默认的主键行为,否则没必要设置任何一个字段的primary_key=True。unique:如果该值设置为 True, 这个数据字段的值在整张表中必须是唯一的。choices:由二元组组成的一个可迭代对象(例如,列表或元组),用来给字段提供选择项。 如果设置了choices ,默认的表单将是一个选择框而不是标准的文本框,而且这个选择框的选项就是choices 中的选项。db_index:如果db_index=True 则代表着为此字段设置一个普通索引。auto_now_add和auto_now:DatetimeField、DateField、TimeField这个三个时间字段,都可以设置这两个属性。- 置auto_now_add=True,创建数据记录的时候会把当前时间添加到数据库。
- 配置上auto_now=True,每次更新数据记录的时候会更新该字段,标识这条记录最后一次的修改时间。
- 注意,如果使用
xx.object.filter(id=1).update()去更新记录时,update不能触发自动更新时间的auto_now的"被动"!所有,你update时,需要手动给该字段传入当前时间xx.object.filter(id=1).update(pub_date=datetime.datetime.now())。或者你使用save的方式来更新记录。
to:外键关联字段,指定被关联的模型类。to_field="id":跟to搭配使用,不指定to_field参数,外键关联时会自动找主键,指定了就按照你指定的找,注意,被关联的字段,必须具有唯一约束。
数据库连接配置
db.sqlite3配置
db.sqlite3是django的集成数据库,也在settings中配置好了,在测试环境非常的好用。
# settings.py
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
}
连接MySQL配置
Django2.2配置完MySQL连接配置后,重启报错,解决办法参考:https://www.cnblogs.com/Neeo/articles/14036364.html#attributeerror-str-object-has-no-attribute-decode
首先我们先下载用于连接MySQL的模块:
pip install pymysql
然后添加配置,在与项目同名的目录中的__init__.py添加如下代码:
import pymysql
pymysql.install_as_MySQLdb()
完事你还需要手动的在MySQL中手动的创建好数据库。
另外,连接MySQL还需要在Django的settings中配置一下:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'bms', # 你的数据库名称
'USER': 'root', # 你的数据库用户名
'PASSWORD': '666666', # 你的数据库密码
'HOST': '', # 你的数据库主机,留空默认为localhost
'PORT': '3306', # 你的数据库端口
'OPTIONS': {
'charset': 'utf8mb4', # 指定字符集,这里需要你MySQL的默认字符集是utf8mb4,保持一致
'use_unicode': True,
},
}
}
想要查看ORM转换为的SQL语句,可以在settings中配置:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
由于ORM会将ORM语句"翻译"为原生SQL语句,但难免会有一些"翻译"后的SQL不符合我们的预期,导致结果也不符合预期,所以,使用这个日志配置,来查看一下ORM到底将语句"翻译"成了什么,方便我们排查。
也可以为每个app单独配置数据库,可以在settings中配置:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME':'bms', # 要连接的数据库,连接前需要创建好
'USER':'root', # 连接数据库的用户名
'PASSWORD':'', # 连接数据库的密码
'HOST':'127.0.0.1', # 连接主机,默认本级
'PORT':3306 # 端口 默认3306
},
'app01': { #可以为每个app都配置自己的数据,并且数据库还可以指定别的,也就是不一定就是mysql,也可以指定sqlite等其他的数据库
'ENGINE': 'django.db.backends.mysql',
'NAME':'bms', # 要连接的数据库,连接前需要创建好
'USER':'root', # 连接数据库的用户名
'PASSWORD':'', # 连接数据库的密码
'HOST':'127.0.0.1', # 连接主机,默认本级
'PORT':3306 # 端口 默认3306
}
}
数据库迁移操作
无论是使用哪个数据库,都需要执行数据库同步指令。
来个示例,首先在应用的models.py文件。创建相关表:
class UserInfo(models.Model):
name = models.CharField(max_length=32)
def __str__(self):
return self.name
然后执行数据库迁移,根据上面映射关系,真正的在数据库中创建相应的表结构,在项目的manage.py文件同级目录,命令行执行:
python manage.py makemigrations # 创建数据库的映射关系
python manage.py migrate # 根据上条命令生成的映射关系,在数据库中生成相应的表
上述命令会将所有的APP(settings中的INSTALLED_APPS中的app)中的models.py的映射类,真正的在数据库中创建相应的表。但是也可能有失败的时候,那么我们就要强制执行数据库迁移命令:
python manage.py migrate your_app_name --database your_app_name
如果在数据库迁移命令中,出现WARNING警告:
WARNINGS:
?: (mysql.W002) MySQL Strict Mode is not set for database connection 'default'
HINT: MySQL's Strict Mode fixes many data integrity problems in MySQL, such as data truncation upon insertion, by escalating warnings into errors. It is strongly recommended you activate it.
那就在settings的DATABASES配置项中,再增加一个OPTIONS参数:
'OPTIONS': {
'init_command': "SET sql_mode='STRICT_TRANS_TABLES'"
}
来自官方的解释。
上述操作,仅适用于连接MySQL。
最后,需要说明的是,Django为了区分某个表属于某个应用,创建的表都是以应用名加下划线加表名的形式,如上述的UserInfo表,Django会创建成app01_userinfo。
补充,模型类中,新增字段,数据库迁移成功,但是表中却没有该新增字段的问题
测试环境是django1.11+sqlite3。
首先,000开头的文件,能看到新增的字段,但是migrate也不报错,但表中就是没有这个新增字段。
解决方式就是手动注释掉这个新增的字段,然后执行makemigrations和migrate,你会发现有remove的相关提示。
然后在取消注释那个新增字段,然后再执行makemigrations和migrate,我的就可以了。注意,要为新增字段设置默认值,毕竟是后加的,要考虑人家表中有数据了。
关于时区的问题
默认的, Django使用UTC时间来操作时间数据,如果需要修改为本地时区,就需要修改settings.py配置文件:
# USE_TZ = True
USE_TZ = False
连接池
默认的,django每次进行一次数据库操作完毕,就关闭了连接,但在频繁操作数据库时就会增加数据库的压力,降低服务性能。所以我们可以通过数据库连接池来替代原有方案。
即用完不在关闭连接,而是放入连接池中,让后续请求继续复用该连接,从而降低频繁开启和关闭连接池的消耗。
但django原生不支持数据连接池,所以这里提供一个第三方的模块。
pip install django-db-connection-pool
pip install django-db-connection-pool==1.2.1
这个模块是基于SQLAlchemy的连接池(队列池),适用于MySQL和Oracle。
配置也简单,就是修改settings.py中的关于数据库的部分配置即可。
DATABASES = {
'default': {
# 1. 将原有的 django.db.backends.mysql 改为 dj_db_conn_pool.backends.mysql
# 'ENGINE': 'django.db.backends.mysql',
'ENGINE': 'dj_db_conn_pool.backends.mysql',
'NAME': 'drf', # 你的数据库名称
'USER': 'root', # 你的数据库用户名
'PASSWORD': '123', # 你的数据库密码
'HOST': '127.0.0.1', # 你的数据库主机,留空默认为localhost
'PORT': '3306', # 你的数据库端口
# 2. 关于连接池的配置
'POOL_OPTIONS': {
'POOL_SIZE': 10,
'MAX_OVERFLOW': 10
}
}
}
目前连接池限制用户传入的连接池配置为:POOL_SIZE(连接池容量)、MAX_OVERFLOW(连接池容量上下浮动最大值) 这两个参数包含在 POOL_OPTIONS 内,例如下面的配置,default 的连接池常规容量为10个连接,最大浮动10个, 即为:在 default 连接池创建后,随着程序对连接池的请求,连接池内连接将逐步增加到10个,如果在连接池内连接 全部用光后,程序又请求了第11个连接,此时的连接池容量将短暂超过 POOL_SIZE,但最大不超过 POOL_SIZE + MAX_OVERFLOW, 如果程序请求 default 数据库的连接数量超过 POOL_SIZE + MAX_OVERFLOW,那连接池将一直等待直到程序释放连接。
参考:
- https://blog.csdn.net/qq_33458131/article/details/117993520
- https://pypi.org/project/django-db-connection-pool/1.0.0/
- https://pypi.org/project/django-db-connection-pool/
反向生成模型类
现在,假若你的Django项目中的models.py是空的,而数据库中已经创建了表关系,那么可以使用下面的命令将对应关系,反向在models.py创建模型类:
python manage.py inspectdb > mysite\models.py # mysite为项目名
python manage.py makemigrations
python manage.py migrate
然后把models.py替换掉对应的app目录下的models.py即可。
单表操作
如何在脚本中使用Django环境,参考:https://www.cnblogs.com/Neeo/articles/12157378.html
为了省事儿(省略配置路由和视图这些操作),这里的操作都在脚本(我在项目(项目名是demo)根目录下创建orm.py脚本)中进行演示。
必须要的准备
必要的准备,建表和配置脚本:
# app01/models.py
from django.db import models
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name='书籍名称')
price = models.FloatField(verbose_name='书籍价格')
pub_date = models.DateField(verbose_name='出版日期')
publish = models.CharField(max_length=32, verbose_name='出版社名称')
# 当打印book对象时,通过 __str__ 的返回更友好的结果
def __str__(self):
return self.title
demo/orm.py:
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
import datetime
from app01 import models
def query():
# 写ORM语句
pass
if __name__ == '__main__':
query()
后续的操作都在query函数中执行。
添加数据
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
import time
import datetime
from app01 import models
def query():
# 添加数据 方式1
# book_obj = models.Book(
# # 对于主键 id 可以不传值,默认即可
# title='红楼梦',
# price=9.9,
# # 添加时间日期类型的数据时可以是日期时间类型的对象,也可以是字符串
# # pub_date=datetime.datetime.now(),
# pub_date='2020-1-5',
# publish='机械工业出版社'
# # 对于有默认值或者为空的字段,视具体情况而定
# )
# book_obj.save()
# 添加数据 方式2
# 注意,create方法有返回值,返回值是新添加数据的模型对象
# book_obj = models.Book.objects.create(
# # 对于主键 id 可以不传值,默认即可
# title='红楼梦',
# price=9.9,
# # 添加时间日期类型的数据时可以是日期时间类型的对象,也可以是字符串
# # pub_date=datetime.datetime.now(),
# pub_date='2020-1-5',
# publish='机械工业出版社'
# # 对于有默认值或者为空的字段,视具体情况而定
# )
# print(book_obj) # 红楼梦
# print(book_obj.title, book_obj.price, book_obj.pub_date, book_obj.publish) # 红楼梦 9.9 2020-1-5 机械工业出版社
# (伪)批量添加
# for i in range(1, 11):
# models.Book.objects.create(
# title='红楼梦{}'.format(i),
# price=9.9 + i,
# pub_date=datetime.datetime.now(),
# publish='机械工业出版社'
# )
# (真)批量添加
# 先将每条记录对象放到列表中,然后在bulk_create
# start = time.time()
# tmp_list = [
# models.Book(
# title='红楼梦{}'.format(i),
# price=9.9 + i,
# pub_date=datetime.datetime.now(),
# publish='机械工业出版社'
# )
# for i in range(1, 1000000)]
# models.Book.objects.bulk_create(tmp_list)
# print(time.time() - start) # 28.573500871658325 cpu: 20+%
# 我突发奇想,试了试生成器,发现性能没提升多少.... 好尴尬.....
start = time.time()
tmp_list = (
models.Book(
title='红楼梦{}'.format(i),
price=9.9 + i,
pub_date=datetime.datetime.now(),
publish='机械工业出版社'
)
for i in range(1, 1000000))
models.Book.objects.bulk_create(tmp_list)
print(time.time() - start) # 28.516786098480225 cpu: 20+%
if __name__ == '__main__':
query()
删除记录
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
import time
import datetime
from app01 import models
def query():
# queryset类型的数据可以调用delete删除记录,
# 如果查询出来的是多条数据,就删除多条,
# 如果没跟条件就删除所有
models.Book.objects.filter(id=3).delete()
# models.Book.objects.filter(id__gte=50).delete() # 删除id大于等于50的所有记录
# 模型对象也可以调用delete删除记录,仅能删一条
models.Book.objects.get(id=4).delete()
if __name__ == '__main__':
query()
再次强调,get命令返回唯一的符合条件的记录,紧随其后,使用delete就可以删掉它了。
修改记录
from django.shortcuts import render, HttpResponse
from web import models
def index(request):
# 从前端获取来的新的出版社名字
new_name = '中信出版社'
# 原有的出版社名字
old_name = '人民出版社'
# 以原有的名字作为查询,将这条数据查询出来
obj = models.Publisher.objects.get(name=old_name)
# 为这条记录从新赋值
obj.name = new_name
# 执行保存
obj.save()
return HttpResponse('OK')
上例,想要修改某条数据,首先要把这条数据查询出来,然后更新这条数据的指定字段。最后通过save保存即可修改。
或者可以这么修改更为简单:
from django.shortcuts import render, HttpResponse
from web import models
def index(request):
# 比如修改nid=1的出版社名称
models.Publisher.objects.filter(nid=1).update(name='玉林出版社')
return HttpResponse('OK')
上例,直接根据nid进行查询筛选出我们想要修改的记录,然后使用update语法更新指定的字段值。
upate_or_create
https://docs.djangoproject.com/zh-hans/2.2/ref/models/querysets/#update-or-create
upate_or_create方法用来根据条件判断,是否执行更新还是查询操作。
基本语法:
models.Tests.objects.update_or_create(condition, default)
- condition:如果条件为True,则执行更新操作,否则执行创建操作。
- default:字典类型的更新或创建内容。
示例:
models.Tests.objects.update_or_create(pk=2, default={"name":"zhangkai"})
如果pk为2的记录存在,就更新name字段的内容;否则创建该条记录。
也可以这么写:
select_condition = {"pk": 3, "name": '张开'}
models.Testss.objects.update_or_create(**select_condition, defaults={'name': '张开腿'})
条件是pk=3 name=张开的那条记录,有则更新,无则创建。
查询记录
https://docs.djangoproject.com/zh-hans/2.0/ref/models/querysets/
查询API是最难的!方法也很多:
| method | description |
|---|---|
all() |
查询所有的结果 |
get(**kwargs) |
返回与所给筛选条件相匹配的对象,返回结果有且只有一个。如果符合筛选条件的对象超过一个或者没有都会抛出错误。 |
filter(**kwargs) |
它包含了与所给筛选条件相匹配的对象 |
exclude(**kwargs) |
它包含了与所给筛选条件不匹配的对象 |
order_by(*field) |
对查询结果排序 |
reverse() |
对查询结果反向排序 |
count() |
返回数据库中匹配查询(QuerySet)的对象数量 |
first() |
返回第一条记录 |
last() |
返回最后一条记录 |
exists() |
如果QuerySet包含数据,就返回True,否则返回False |
values(*field) |
返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列 |
values_list(*field) |
它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 |
distinct() |
从返回结果中剔除重复纪录 |
基于双下划线的模糊查询:
| method | description |
|---|---|
Book.objects.filter(title__startswith="p") |
以什么开头,英文区分大小写 |
Book.objects.filter(title__istartswith="p") |
以什么开头,英文不分区大小写 |
Book.objects.filter(title__endswith="p") |
以什么结尾,英文区分大小写 |
Book.objects.filter(title__iendswith="p") |
以什么结尾,英文不区分大小写 |
Book.objects.filter(title__contains="py") |
包含,英文区分大小写 |
Book.objects.filter(title__icontains="py") |
包含,英文区不分大小写 |
Book.objects.filter(price__gt=10) |
大于 |
Book.objects.filter(price__gte=10) |
大于等于 |
Book.objects.filter(price__lt=10) |
小于 |
Book.objects.filter(price__lte=10) |
小于等于 |
Book.objects.filter(price=10) |
等于 |
Book.objects.filter(price__in=[100,200,300]) |
等于多个指定值,类似于MySQL中的or |
Book.objects.filter(price__range=[100,200]) |
在指定范围内100 <= price <= 200,相当于between and |
Book.objects.filter(pub_date__year='2020') |
根据年份查询,2020也可以写成整型 |
Book.objects.filter(pub_date__month=1) |
根据月份查询,所有年的指定月份都符合 |
Book.objects.filter(pub_date__year=2020,pub_date__month=3) |
根据年月查询,某年某月 |
Book.objects.filter(pub_date__day=5) |
查询某天的, |
Book.objects.filter(pub_date__year=2020, pub_date__month=12,pub_date__day=5) |
某年某月某天 |
Book.objects.filter(pub_date='2020-12-5') |
跟上一条查询等价 |
PS:我们一般亲切的称呼这些双下划线为了不起的双下划线。
接下来,我们来一一的演示下各自的用法。
准备数据
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
def query():
l = [
('人性的枷锁', 123, '北京出版社', '2018-12-12'),
('北京折叠', 124, '玉林出版社', '2018-07-12'),
('三体', 98, '人民出版社', '2017-07-12'),
('白鹿原', 67, '机械工业出版社', '2016-06-12'),
('python从入门到放弃', 67, '机械工业出版社', '2019-06-12'),
('linux从入门到精通', 23, '人民工业出版社', '2017-06-12'),
('DBA从删库到跑路', 46, '人民工业出版社', '2017-09-12'),
('渗透从入门到入狱', 46, '清华大学出版社', '2018-12-12'),
]
tmp_list = [
models.Book(
title=title,
price=price,
publish=publish,
pub_date=pub_date
)
for title, price, publish, pub_date in l]
models.Book.objects.bulk_create(tmp_list)
if __name__ == '__main__':
query()
我现在,book表中只有这些数据,之前的数据我都删除了。
查询:all
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01.models import Book
def query():
book_obj = Book.objects.all()
print(book_obj) # 以queryset返回所有的书籍对象
"""
<QuerySet [<Book: 人性的枷锁>, <Book: 北京折叠>, <Book: 三体>, <Book: 白鹿原>,
<Book: python从入门到放弃>, <Book: linux从入门到精通>, <Book: DBA从删库到跑路>,
<Book: 渗透从入门到入狱>]>
"""
# book_obj = Book.objects.all()[0] 根据索引取值
if __name__ == '__main__':
query()
all方法返回QuerySet对象,QuerySet这个数据结构可以理解为一个列表,列表中的元素是表中存储的一条条记录对象,并且默认地按照id升序排序。
相当于:
select * from book;
QuerySet与model对象区别
- QuerySet是类似于列表的数据结构,存放一条或多条记录对象。
- model对象,就是记录对象。
我们可以通过model对象点出来记录的各字段值。
查询:filter
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01.models import Book
def query():
# 单条件查询
result = Book.objects.filter(title='三体')
print(result) # <QuerySet [<Book: 三体>]>
# 多条件查询
result = Book.objects.filter(title='三体', price=110) # and关系,这里面没有or....但有其他的手法来实现or
print(result) # <QuerySet []>
if __name__ == '__main__':
query()
filter方法可以跟过滤条件,多个逗号相当于and关系,返回过滤QuerySet,如果查询不到返回空的QuerySet。
相当于:
select * from app01_book where title = "三体";
select * from app01_book where title = "三体" and price=110;
查询:get
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01.models import Book
def query():
# 查询有结果,且结果唯一才返回结果对象
book_obj = Book.objects.get(title='三体')
print(book_obj) # 返回三体那条记录的记录对象
print(book_obj.title, book_obj.price) # 既然是对象,就可以点出来具体的字段
# 查询没有匹配结果会报错
# Book.objects.get(id=1212121212112) # app01.models.DoesNotExist: Book matching query does not exist.
# 查询有多个结果也会报错
Book.objects.get(pub_date='2018-12-12') # app01.models.MultipleObjectsReturned: get() returned more than one Book -- it returned 2!
if __name__ == '__main__':
query()
get方法返回model对象。
特点:如果查询到多个结果或者无查询结果都会报错。
相当于:
select * from app01_book where title = "三体";
查询:first & last
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01.models import Book
def query():
# first
book_obj = Book.objects.all().first()
print(book_obj) # 返回所有记录中的第一条记录对象
print(book_obj.title, book_obj.publish) # 人性的枷锁 北京出版社
# last
book_obj = Book.objects.all().last()
print(book_obj) # 返回所有记录中的第一条记录对象
print(book_obj.title, book_obj.publish) # 渗透从入门到入狱 清华大学出版社
if __name__ == '__main__':
query()
first方法返回queryset中的第一个model对象。不仅能用于all中,也可以用在filter中,相当于取queryset中的0索引的model对象。
相当于:
select * from app01_Book order by id asc limit 1;
而last就没啥好说了的,用法与first一致,只是返回的是queryset中最后一条model对象,同样可以点出来字段值。
相当于:
select * from app01_Book order by id desc limit 1;
查询:exclude
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01.models import Book
def query():
# 排除一个条件
book_obj = Book.objects.exclude(price=98)
print(book_obj)
"""
<QuerySet [<Book: 人性的枷锁>, <Book: 北京折叠>, <Book: 白鹿原>,
<Book: python从入门到放弃>, <Book: linux从入门到精通>,
<Book: DBA从删库到跑路>, <Book: 渗透从入门到入狱>]>
"""
# 同时排除多个条件,且多个条件必须同时成立,即 and 关系
# 注意如果这两个条件构不成and关系,那么一个条件也不会生效
# 如,排除价格是10.9,且title是 人性的枷锁 的书籍,只有这两个条件同时生效才可以
# book_obj = models.Book.objects.exclude(price=10.9, title="人性的枷锁")
# 同时排除多个条件,多个条件是 or 的关系,只要有一个条件成立就可以了
# 如,排除价格是10.9或者书籍名称是 人性的枷锁 的
book_obj = Book.objects.exclude(price=10.9).exclude(title="人性的枷锁")
print(book_obj)
if __name__ == '__main__':
query()
exclude与所给筛选条件不匹配的对象,比如查询表中价格不等于98的所有书籍。
同样的exclude返回queryset对象。
相当于:
select * from app01_Book where not price = 98;
查询:order_by
默认情况下,QuerySet 返回的结果是按照模型 Meta 中的 ordering 选项给出的排序元组排序的。你可以通过使用 order_by 方法在每个 QuerySet 的基础上覆盖这一点。
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01.models import Book
def query():
book_obj = Book.objects.all().order_by('price') # 按照价格升序排序:默认升序排序
book_obj = Book.objects.all().order_by('-price') # 按照价格降序排序:通过 - 使倒序排序
# 除了上面的查所有然后排序,也可以按条件查询然后排序
book_obj = Book.objects.filter(publish='机械工业出版社').order_by('-price') # 按照价格降序排序:通过 - 使倒序排序
# 多条件排序
book_obj = Book.objects.filter(publish='机械工业出版社').order_by('-price', '-id') # 按照价格降序排序:通过 - 使倒序排序
# 查询价格最大的那本书, 这是一种链式操作,首先返回根据倒序排序的queryset,然后取其中第一个model对象
Book.objects.filter(publish='机械工业出版社').order_by('-price', '-id').first()
# 随机排序的话,就 order_by("?"),不过这个代价很大。
if __name__ == '__main__':
query()
order_by方法返回排序后的QuerySet。默认是升序排序,倒序的话需要在条件前加-。
也可以按多条件排序,首先根据价格(条件优先)进行倒序排序,如果遇到价格一样的,就按照id进行倒序排序。
相当于:
select * from app01_Book order by price asc ;
select * from app01_Book order by price desc ;
select * from app01_Book order by price desc , id desc ;
select * from app01_Book order by price desc , nid desc limit 1;
更多排序细节:https://docs.djangoproject.com/zh-hans/4.1/ref/models/querysets/#order-by
查询:count
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01.models import Book
def query():
# 查询记录的总条数
book_obj1 = Book.objects.count()
book_obj2 = Book.objects.all().count()
print(book_obj1, book_obj2) # 8 8
# 查询匹配结果的总条数
book_obj3 = Book.objects.filter(publish='机械工业出版社').count()
print(book_obj3) # 2
if __name__ == '__main__':
query()
count方法返回QuerySet中的model对象的总数。
相当于:
select count(*) from app01_Book ;
查询:extra
再说一个平常不怎么用的查询方法extra,正经解释参考:https://docs.djangoproject.com/zh-hans/4.1/ref/models/querysets/#extra
我就简单说下这个官网不太推荐的方法的作用,比如有一些复杂的where条件或者复杂的排序条件,orm常用的查询语句和order_by不太好处理,就可以用这extra方法来做。
例如下面这个示例:
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # MB:项目名称
django.setup()
from app03 import models
"""
# 模型类
class Test2(models.Model):
t1 = models.CharField(max_length=32)
t2 = models.CharField(max_length=32)
# 数据长这样
id t1 t2
1 contenttypes z-202208
2 sessions e-202206
3 makemigrations a-202205
4 migrate av-202204
5 corporation b-202203
6 default az-202206
7 available c-202202
"""
def foo():
"""
1. 将查询结果以t1字段长度排序
obj = models.Test2.objects.values().extra(select={"t1": "length(t1)"}).order_by('-t1')
print(obj)
<QuerySet [
{'t1': 'makemigrations', 'id': 3, 't2': 'a-202205'}, {'t1': 'contenttypes', 'id': 1, 't2': 'z-202208'},
{'t1': 'corporation', 'id': 5, 't2': 'b-202203'}, {'t1': 'available', 'id': 7, 't2': 'c-202202'},
{'t1': 'sessions', 'id': 2, 't2': 'e-202206'}, {'t1': 'migrate', 'id': 4, 't2': 'av-202204'},
{'t1': 'default', 'id': 6, 't2': 'az-202206'}
]>
2. 根据t1的第二个字符排序
obj = models.Test2.objects.values().extra(select={"t1": "substring(t1, 2)"}).order_by('-t1')
print(obj)
<QuerySet [
{'t1': 'available', 'id': 7, 't2': 'c-202202'}, {'t1': 'corporation', 'id': 5, 't2': 'b-202203'},
{'t1': 'contenttypes', 'id': 1, 't2': 'z-202208'}, {'t1': 'migrate', 'id': 4, 't2': 'av-202204'},
{'t1': 'sessions', 'id': 2, 't2': 'e-202206'}, {'t1': 'default', 'id': 6, 't2': 'az-202206'},
{'t1': 'makemigrations', 'id': 3, 't2': 'a-202205'}
]>
"""
obj = models.Test2.objects.values().extra(select={"t1": "substring(t1, 2)"}).order_by('-t1')
print(obj)
if __name__ == '__main__':
foo()
查询:reverse
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01.models import Book
def query():
book_obj = Book.objects.all().order_by('price').reverse()
print(book_obj) # 返回queryset对model对象的个数
# Book.objects.all().order_by('price').reverse().count() # 链式操作,没啥好说的
if __name__ == '__main__':
query()
reverse方法返回反转QuerySet中的model对象。类似于列表中的reverse。
相当于:
select * from app01_Book order by price desc ;
查询:exists
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01.models import Book
def query():
result = Book.objects.exists()
print(result) # True
result = Book.objects.all().exists() # 相对于取出所有,再if判断,这种写法效率高,相当于 limit 1
print(result) # True
if __name__ == '__main__':
query()
exists方法判断表中是否有记录,有则返回True,否则返回False。
相当于:
select * from app01_Book limit 1 ;
查询:values & values_list
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01.models import Book
def query():
# values
result = Book.objects.values('title')
print(result)
result = Book.objects.values('title', 'price')
print(result)
result = Book.objects.all().values('title', 'price')
print(result)
result = Book.objects.filter(price=98).values('title', 'price')
print(result) # <QuerySet [{'title': '三体', 'price': 98.0}]>
# values_list
result = Book.objects.filter(price=124).values_list('title', 'price')
print(result) # <QuerySet [('北京折叠', 124.0)]>
if __name__ == '__main__':
query()
values方法返回queryset中的指定字段,可以与all与filter连用。
相当于:
select title from app01_Book ;
select title, price from app01_Book ;
select title, price from app01_Book where price = 98 ;
values和values_list的唯一区别是:
- values返回的queryset对象是列表套字典的形式。
- values_list返回的是queryset对象是列表套元组的形式。
一般的,values用的相对较多。因为操作字典最熟悉。
查询:distinct
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01.models import Book
def query():
result = Book.objects.values('title').distinct()
print(result)
result = Book.objects.all().distinct() # 没有意义
print(result)
if __name__ == '__main__':
query()
distinct方法对queryset中指定字段值进行去重。但是,对与表中含有主键的不能直接使用,因为主键是唯一的,如上例all查出来的的id是主键。所以都不重复,所以,对于这种场景distinct没有意义。
相当于:
select distinct title from app01_Book ; -- title字段可能存在重复值,可以去重
select distinct id, title from app01_Book ; -- id是主键,这么用没有意义
模糊查询:大于小于系列
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01.models import Book
def query():
# 下面都可以写多条件比如价格大于40,出版社是某某出版社
result = Book.objects.filter(price=120) # 等于
print(result)
result = Book.objects.filter(price__gt=120) # 大于
print(result)
result = Book.objects.filter(price__gte=120) # 大于等于
print(result)
result = Book.objects.filter(price__lt=120) # 小于
print(result)
result = Book.objects.filter(price__lte=120) # 小于等于
print(result)
if __name__ == '__main__':
query()
等于没啥好说的。
在ORM中,模糊查询都是双下划线系列。
- 大于:
字段名__gt,大于等于:字段名__gte。 - 小于:
字段名__lt;小于等于:字段名__lte。
相当于:
select * from app01_Book where price = 120 ;
select * from app01_Book where price > 120 ;
select * from app01_Book where price >= 120 ;
select * from app01_Book where price < 120 ;
select * from app01_Book where price <= 120 ;
模糊查询:开头结尾和包含系列
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01.models import Book
def query():
# 下面都可以写多条件比如价格大于40,出版社是某某出版社
result = Book.objects.filter(title__startswith='p') # 开头,区分大小写
print(result)
result = Book.objects.filter(title__istartswith='p') # 开头,不区分大小写
print(result)
result = Book.objects.filter(title__endswith='跑路') # 结尾,区分大小写
print(result)
result = Book.objects.filter(title__iendswith='on') # 结尾,不区分大小写
print(result)
result = Book.objects.filter(title__contains='on') # 包含,区分大小写
print(result)
result = Book.objects.filter(title__icontains='on') # 包含,不区分大小写
print(result)
if __name__ == '__main__':
query()
以什么开头,以什么结尾,是否包含指定的值,方法较多。
__startswith方法返回以指定字符开头的queryset对象。另外,还有一个是__istartswith方法,表示指定字段值不区分大小写,但是,我发现不加i也不区分大小写!
__endswith方法返回以指定字符结尾的queryset对象。同样,__endswith也有一个__iendswith方法。同样是不区分大小写。
__contains方法返回字段值只要包含指定字符就返回。__icontains不区分大小写的包含。
相当于:
select * from app01_Book where title like "py%" ;
select * from app01_Book where title like "%py" ;
select * from app01_Book where title like "%p%" ;
模糊查询:in和range
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01.models import Book
def query():
# 查询价格等于123 or 124 等价于MySQL中的or
result = Book.objects.filter(price__in=[123, 124])
print(result)
# 查询价格在100~200之间 100 <= price <= 200
result = Book.objects.filter(price__range=[100, 200])
print(result)
if __name__ == '__main__':
query()
in和range很好理解,这里不再多表。
模糊查询:日期时间系列
https://docs.djangoproject.com/zh-hans/2.0/ref/models/querysets/#week-day
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01.models import Book
def query():
# 查询所有2018年出版的书籍
result = Book.objects.filter(pub_date__year=2018) # 写成这样也可以: pub_date__year="2018"
print(result)
# 查询所有12月份出版的书籍,该条件不受年份限制
result = Book.objects.filter(pub_date__month=12)
print(result)
# 查询所有12号这一天出版的书籍,该条件不受年份和月份的限制
result = Book.objects.filter(pub_date__day=12)
print(result)
# 查询2018年12月份出版的书籍
result = Book.objects.filter(pub_date__year=2018, pub_date__month=12)
print(result)
# 查询2018年12月12号出版的书籍
# result = Book.objects.filter(pub_date__year=2018, pub_date__month=12, pub_date__day=12)
result = Book.objects.filter(pub_date='2018-12-12') # 跟上一条语句等价
result = Book.objects.filter(pub_date__exact='2018-12-12') # 准确的日期,跟上面两条语句等价
print(result)
# 大于,大于等于指定日期
# result = Book.objects.filter(pub_date__gt='2018-12-12') # 大于指定日期
result = Book.objects.filter(pub_date__gte='2018-12-12') # 大于等于指定日期
print(result)
# 小于,小于等于指定日期
# result = Book.objects.filter(pub_date__lt='2018-12-12') # 小于指定日期
result = Book.objects.filter(pub_date__lte='2018-12-12') # 小于等于指定日期
print(result)
# in 类似于MySQL的 or
result = Book.objects.filter(pub_date__in=['2018-12-12', '2019-6-12'])
print(result)
# range 指定日期范围内 2018-12-12 <= pub_date <= 2019-6-12
result = Book.objects.filter(pub_date__range=['2018-12-12', '2019-6-12']) #
print(result)
# django1.11新功能 星期几 取一个整数值,表示从1(星期日)到7(星期六)的星期几。
result = Book.objects.filter(pub_date__week_day=3) # 星期二
print(result)
if __name__ == '__main__':
query()
小结
模糊查询系列有很多方法组合,这里无法一一列举,比如查询时间在某一范围,具体到天,过滤多少天之前,价格的范围等等。我们可以根据具体的需求来搭配实现。
最后,多看官档:https://docs.djangoproject.com/zh-hans/2.0/
多表操作
多表操作是通过ORM操作多张有关系的表。
所以,多表操作非常重要!
先来看表与表之间的关系:
- 一对多,在
多表中建立关联字段。 - 一对一,在哪张表中建立关联字段都行。
- 多对多,创立第三张表,在第三张表中建立关联字段。
设计表关系
我们通过图书管理系统来学习多表操作。
在图书管理系统中,有这样的几个对象:
- 作者模型对象,一个作者对象应该有其属性:姓名、年龄、性别。
- 作者详细信息模型对象,作者对象中只存储常用的属性,更多、更详细的属性通过作者的详情表来存储,比如生日、手机号、住址信息等等。且它和作者对象是一对一的关系。
- 出版社模型对象,出版社对象包括其属性:出版社名称、所在城市等信息。
- 书籍模型对象,一本书有书名、出版日期:
- 另外一本书也可以是有多个作者共同著作,而每个作者可以写多本书籍,所以书和作者的关系是多对多关系。
- 这里我们认为一本书应该由一家出版社出版,所以书籍和出版社的关系是一对多关系。
根据上述模型关系,在models.py中,设计表结构如下:
# app01/models.py
from django.db import models
class Author(models.Model):
""" 作者表 """
name = models.CharField(max_length=32, verbose_name='作者姓名')
age = models.IntegerField(verbose_name='作者年龄')
detail = models.OneToOneField(to='AuthorDetail', null=False, on_delete=models.CASCADE, verbose_name='作者详情')
def __str__(self):
return self.name
class AuthorDetail(models.Model):
""" 作者详情表 """
birthday = models.DateField(verbose_name='生日')
# tel = models.IntegerField(verbose_name='作者电话')
# 为了后续支持模糊查询,用varchar比较好些
tel = models.CharField(max_length=32,verbose_name='作者电话')
address = models.CharField(max_length=128, verbose_name='通信地址')
# email = models.EmailField(verbose_name='邮箱') # 为了省事儿,这个字段就不创建了
# 一对一关系创建在哪张表都可以
# author = models.OneToOneField(to='Author', on_delete=models.CASCADE, verbose_name='所属作者')
class Book(models.Model):
""" 书籍表 """
title = models.CharField(max_length=32, verbose_name='书籍名称')
price = models.DecimalField(max_digits=6, decimal_places=2, verbose_name='书籍价格') # 浮点型,9999.99
pub_date = models.DateField(verbose_name='出版日期')
# 外键关联,法1, 不推荐
# publish = models.ForeignKey(Publisher, on_delete=models.CASCADE, verbose_name='出版社')
# 外键关联,法2, 推荐
publish = models.ForeignKey(to='Publisher', on_delete=models.CASCADE,
verbose_name='出版社') # Django2.x版本,必须手动指定on_delete
# Django自动创建的多对多关系
authors = models.ManyToManyField(to='Author', verbose_name='书籍作者')
def __str__(self):
return self.title
class Publisher(models.Model):
""" 出版社表 """
name = models.CharField(max_length=32, verbose_name='出版社名称')
# email = models.EmailField(verbose_name='邮箱') # # 为了省事儿,这个字段就不创建了
address = models.CharField(max_length=32, verbose_name='出版社地址')
def __str__(self):
return self.name
# ------------ 不用自己创建的多对多关系表 ------------
'''
class AuthorToBook(models.Model):
"""
关联书籍和作者的第三张表,一般不用手动创建该类,因为Django会自动创建多对多关系
只有对这个多对多表有其他操作的时候,我们才需要手动创建,比如这个表有自己的特殊字段等情况出现
"""
book = models.ForeignKey(to='Book', on_delete=models.CASCADE)
author = models.ForeignKey(to='Author', on_delete=models.CASCADE)
'''
上例的models.py中的表关系说明,一家出版社可以出版多本书,所以,出版社和书的关系是一对多的关系。而一对多的关系是通过ForeignKey来设置,并且是设置在多的关系中,也就是书籍表中。
另外,绑定外键有两种方式,如上例所示,第一种直接引用Publisher对象,但这种方式,必须保证Publisher类在Book类上面,先定义后引用嘛!
另一种就是以字符串形式引用Publisher对象,这种方式会通过反射在当前models.py中找到Publisher对象,这种比较灵活,没有了定义类的先后顺序。
除此之外,我们还要注意在ForeignKey中的on_delete参数,这里建议指定为models.CASCADE,表示级联删除,就是说如果删除某个出版社记录的话,就把跟这个出版社对应的所有书籍记录都删除掉,但删除某本书,对应的出版社记录不会删除。
外键字段 ForeignKey 有一个 null=True 的设置(它允许外键接受空值 NULL),你可以赋给它空值 None 。
并且,id 字段是自动添加并默认为主键,如果我们不指定的话。
需要注意的是,在Django1.x版本中,该参数是有默认参数None,也就是models.CASCADE,我们不指定该字段,但是,到了Django2.x版本中,就取消了默认参数,也就需要我们手动指定了。除了默认的,还有以下几个参数,供我们选用:
CASCADE:这就是默认的选项,级联删除,Django1.x中无需显式指定它。PROTECT: 保护模式,如果采用该选项,删除的时候,会抛出ProtectedError错误。SET_NULL: 置空模式,删除的时候,外键字段被设置为空,前提就是``blank=True,null=True`,定义该字段的时候,允许为空。SET_DEFAULT:置默认值,删除的时候,外键字段设置为默认值,所以定义外键的时候注意加上一个默认值。
默认的,外键关联会自动关联主键,我们也可以通过to_field关联指定字段。
最后要补充的是:
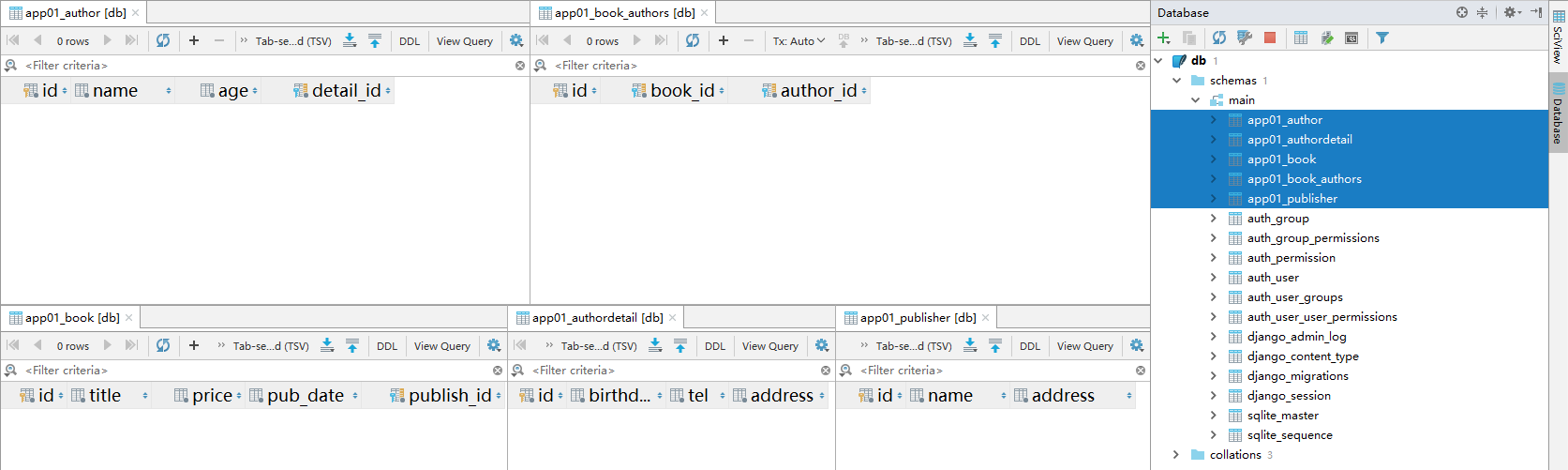
我们在执行完数据库迁移命令后,创建的效果就是如上图所示的样子。
- 我们在创建多对多关系的时候,如无特殊需求,建议让Django自动创建即可(
app01_Book_authors),这样可以使用ORM提供的许多语法,提高编码效率。 - Django会默认在表前面加上应用名,如
app01_author。其中关于外键字段,也会默认添加上_id,比如作者的详情字段是detail,Django会创建成detail_id。 - 除了我们自己定义的表结构,Django也会自动创建的其他表,比如管理权限表,用户的user表等。
关于多表的增删改查:
- 跨表查询:
- 基于对象的方式。
- 基于双下划线的方式。
- 聚合与分组查询。
- F与Q查询。
添加记录
查之前先来添加一些数据。
这里用到了faker模块,该模块用来生成各种数据。详情点击faker。
先把出版社表的记录添加了,因为这个表格没有外键字段,单表操作无压力:
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from faker import Faker
from app01 import models
fk = Faker(locale='zh_CN')
def query():
for i in range(1, 11):
models.Publisher.objects.create(
name=fk.city_name() + '出版社',
address=fk.address()
)
if __name__ == '__main__':
query()
一对一添加记录
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
import random
from faker import Faker
from app01 import models
fk = Faker(locale='zh_CN')
def query():
# 创建作者信息和作者详情表 一对一添加数据
for i in range(1, 11):
# 要先创建详情记录,因为作者表detail字段需要一个详情对象,或者详情对象的id
detail_obj = models.AuthorDetail.objects.create(
birthday=fk.date(),
tel=str(fk.phone_number()),
address=fk.address()
)
models.Author.objects.create(
name=fk.name(),
age=random.randrange(10, 101),
# 法1
detail_id=detail_obj.id, # 如果是 属性_id,那么值为关联记录的id值
# 法2
# detail=detail_obj, # 如果写属性名称来添加数据,那么值为关联记录的模型对象
)
if __name__ == '__main__':
query()
需要说明的是:
- 方法1,直接为
detail_id字段指定一个整数值,这个方便,适合批量插入。但这个值必须是详情表中的id,并且不能重复,毕竟是一对一的关系么! - 方法2,我们首先取出详情表中某个记录对象,然后在作者表的
detail字段直接等于取出的详情表对象就可以了。
一对多/多对多添加记录
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
import random
from faker import Faker
from app01 import models
fk = Faker(locale='zh_CN')
def query():
pub_id_list = [i['id'] for i in models.Publisher.objects.values('id')]
pub_queryset = models.Publisher.objects.all()
author_id_list = [i['id'] for i in models.Author.objects.values('id')]
author_queryset = models.Author.objects.all()
# print(pub_id_list, pub_queryset)
"""
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
<QuerySet [<Publisher: 太原出版社>, <Publisher: 宜都出版社>, <Publisher: 大冶出版社>, <Publisher: 沈阳出版社>,
<Publisher: 潮州出版社>, <Publisher: 济南出版社>, <Publisher: 哈尔滨出版社>, <Publisher: 银川出版社>,
<Publisher: 兴安盟出版社>, <Publisher: 成都出版社>]>
"""
# print(author_id_list, author_queryset)
"""
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
<QuerySet [<Author: 李华>, <Author: 罗辉>, <Author: 周亮>, <Author: 刘玉兰>, <Author: 张杨>,
<Author: 刘云>, <Author: 莫强>, <Author: 刘丹丹>, <Author: 马龙>, <Author: 王秀荣>]>
"""
# 多对多添加书籍记录 主要的注意点在于外键的绑定有所不同
# 方式1
for i in range(2):
book_obj = models.Book.objects.create(
title=fk.country() + '旅游指南',
price=fk.pydecimal(left_digits=2, right_digits=2, positive=True),
pub_date=fk.date(),
publish_id=random.choice(pub_id_list) # 一对多,一次添加一个出版社
)
# 方式1,添加具体的 作者对象的id
# book_obj.authors.add(random.choice(author_id_list)) # 一次添加一个作者
# 方式2
for i in range(2):
book_obj = models.Book.objects.create(
title=fk.country() + '美食探索',
price=fk.pydecimal(left_digits=2, right_digits=2, positive=True),
pub_date=fk.date(),
publish_id=random.choice(pub_id_list) # 一对多,一次添加一个出版社
)
# 方式2,添加具体的 作者对象
# book_obj.authors.add(random.choice(author_queryset)) # 一次添加一个作者
for i in range(2):
book_obj = models.Book.objects.create(
title=fk.country() + '旅游景点探秘',
price=fk.pydecimal(left_digits=2, right_digits=2, positive=True),
pub_date=fk.date(),
publish_id=random.choice(pub_id_list) # 一对多,一次添加一个出版社
)
# 方式3,利用打散添加具体的 作者对象 或者 作者对象id 适用于添加多个
# book_obj.authors.add(*author_id_list[0:2])
book_obj.authors.add(*author_queryset[0:2])
if __name__ == '__main__':
query()
多对多的方式添加起来稍微麻烦点:
- 方法1,为生成的书籍对象的authors字段添加一个作者(主键id)。
- 方法2,为生成的书籍对象的authors字段添加一个作者对象。
- 方法3,跟上面两种没啥区别,就是打散了列表,这种方式用的多,可以一次添加多个作者对象。比如用户自己选择的结果,后台以列表的方式接收,然后保存到数据库。
书籍表和作者表的多对多关系,一本书可以被多个人写,一个人可以写多本书。
第三张表(app01_book_authors)存储的关系如表所示:
| id | book_id | author_id | 描述 |
|---|---|---|---|
| 1 | 1 | 1 | authors表id为1的作者写了Book表中id为1的书籍 |
| 2 | 1 | 2 | authors表id为2的作者写了Book表中id为1的书籍 |
| 3 | 1 | 3 | authors表id为3的作者写了Book表中id为1的书籍 |
| 4 | 2 | 2 | authors表id为2的作者写了Book表中id为2的书籍 |
查询记录
基于对象的跨表查询
这里需要理解两个重点,正向查询与反向查询。
一对一跨表查询
在一对一的跨表查询中,也是依赖正向查询和反向查询的,比如作者表(关联字段所在表)和作者详情表:
- 正向查询按字段
author_obj.detail.tel。 - 反向查询按表名小写
author_detail_obj.author.name。
说白了就是根据已知条件查询关联对象的某个属性。
"""
正向查询按字段 author.detail
Author ---> AuthorDetail
反向查询按表名小写 author_detail_obj.Book
AuthorDetail ---> Author
"""
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
def query():
# 正向查询
# 通过作者查作者详情表的某个属性
# author_obj = models.Author.objects.get(id=1)
# author_obj = models.Author.objects.filter(id=1).first()
author_obj = models.Author.objects.filter(id=1)[0] # 以上这三个用哪个都可以
# author_obj.detail # 定位到了作者对象对应的详情表的对象了
# 拿到了详情表对象,想要啥属性直接点就可以了
print(author_obj.detail.tel, author_obj.detail.birthday) # 14710911994 1979-09-21
# 反向查询
# 通过详情表对象查询作者表关联记录的某个属性
# author_detail_obj = models.AuthorDetail.objects.get(id=1)
# author_detail_obj = models.AuthorDetail.objects.filter(id=1).first()
author_detail_obj = models.AuthorDetail.objects.filter(id=1)[0] # 以上这三个用哪个都可以
# author_detail_obj.author # 通过点表名小写,获取关联的作者对象
# 拿到了作者对象,想要啥属性直接点就可以了
print(author_detail_obj.author.name, author_detail_obj.author.age) # 李华 15
if __name__ == '__main__':
query()
一对多跨表查询
在一对多的关系中,比如作者表(关联字段所在表)和出版社表:
- 正向查询:也就是从多向一查询,按字段查询
book_obj.publish.name,publish为Book表的关联字段。 - 反向查询,也就是从一向多查询,按表名小写加下划线set
pub_obj.book_set,_set表示查询结果可能有多条。完事再进行过滤:pub_obj.book_set.all()取出出版社出版的所有书籍。pub_obj.book_set.filter()在所有关联的书籍中,进行过滤。
"""
正向查询按字段 book_obj.publish
Book ---> Publisher
反向查询按表名小写_set pub_obj.book_set
Publisher ---> Book
"""
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
def query():
# 正向查询 从多查一
# 通过书籍对象查询出版社
# book_obj = models.Book.objects.get(id=1)
# book_obj = models.Book.objects.filter(id=1).first()
book_obj = models.Book.objects.filter(id=1)[0] # 以上这三个用哪个都可以
# book_obj.publish # 找到了书籍对应的出版社对象
# 拿到了出版社对象,想要啥属性直接点就可以了
print(book_obj.publish.name, book_obj.publish.address) # 宜都出版社 天津市俊县东城万街F座 510431
# 你也可以手动处理 不推荐
pub_obj = models.Publisher.objects.get(id=book_obj.publish_id)
print(pub_obj.name, pub_obj.address) # 宜都出版社 天津市俊县东城万街F座 510431
# 反向查询 从一查多
# 通过出版社对象查询出版的书籍对象
# pub_obj = models.Publisher.objects.get(id=1)
# pub_obj = models.Publisher.objects.filter(id=1).first()
pub_obj = models.Publisher.objects.filter(id=1)[0] # 以上这三个用哪个都可以
print(pub_obj.book_set.all()) # <QuerySet [<Book: 拉脱维亚旅游指南>, <Book: 亚美尼亚美食探索>]>
print(pub_obj.book_set.filter(title='拉脱维亚旅游指南')) # <QuerySet [<Book: 拉脱维亚旅游指南>]>
print(pub_obj.book_set.filter().first()) # 拉脱维亚旅游指南
# 你也可以手动处理 不推荐
book_obj = models.Book.objects.filter(publish_id=pub_obj.id) # 一个出版社可能出版了多本书,所以不能用get 要用filter过滤
for book in book_obj: # 拿到多本书的对象,循环取值
print(book.title, book.price)
print(book_obj.filter(title='拉脱维亚旅游指南').first()) # 加过滤条件也都随你
if __name__ == '__main__':
query()
多对多跨表查询
在多对多的关系中,比如作者表和书籍表(关联字段所在表):
- 正向查询:也就是查询某本书都有哪些作者编写,按字段查询
book_obj.authors.all():book_obj.authors.all():取出书籍对应的所有作者。book_obj.authors.filter():在所有关联的作者中,进行过滤。
- 反向查询,也就是查询某个作者写了哪些书,按表名小写加下划线set
author_obj.book_set,_set表示查询结果可能有多条。完事再进行过滤:author_obj.book_set.all()取出出版社出版的所有书籍。author_obj.book_set.filter()在所有关联的书籍中,进行过滤。
套路跟一对多差不多。
"""
正向查询按字段 Book.authors.all()
Book ---> Author
反向查询按表名小写_set.all() auhor_obj.Book_set.all()
Author ---> Book
"""
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
def query():
# 正向查询 根据书籍查作者
# book_obj = models.Book.objects.get(id=1)
# book_obj = models.Book.objects.filter(id=1).first()
book_obj = models.Book.objects.filter(id=6)[0] # 以上这三个用哪个都可以
# book_obj.authors # 拿到作者对象,其中可能有多个作者
print(book_obj.authors.all()) # <QuerySet [<Author: 李华>, <Author: 罗辉>]>
print(book_obj.authors.filter().first()) # 可以跟过滤条件
# 反向查询 根据作者查书籍
# author_obj = models.Author.objects.get(id=1)
# author_obj = models.Author.objects.filter(id=1).first()
author_obj = models.Author.objects.filter(id=1)[0] # 以上这三个用哪个都可以
# author_obj.book_set # 通过表名小写_set 获取到(可能)多个书籍
print(author_obj.book_set.all()) # <QuerySet [<Book: 乌兹别克斯坦旅游景点探秘>, <Book: 圣皮埃尔岛及密克隆岛旅游景点探秘>]>
print(author_obj.book_set.filter().first()) # # 可以跟过滤条件
if __name__ == '__main__':
query()
由查询语法可以看到,多对多和一对多的语法基本一致。
基于双下划线的跨表查询
首先要明确一点,在基于双下划线的跨表查询中,无论是一对一、一对多、多对多的查询,都遵循:正向查询按字段,反向查询按表名小写
一对一跨表查询
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
def query():
# 一对一查询 正向查询
# 查询某作者的手机号和年龄
result = models.Author.objects.filter(name='李华').values('detail__tel', 'age')
print(result)
"""
# select * from app01_author inner join app01_authordetail on app01_author.detail_id = app01_authordetail.id;
<QuerySet [{'detail__tel': '14710911994', 'age': 15}]>
正向查询按属性,所以通过属性名加双下划线连表到另一张表,然后找属性,如: detail__tel
查询自己表中的字段,直接写就好了,如: age
"""
# 一对一查询 反向查询
# 查询某作者的手机号和年龄
result = models.AuthorDetail.objects.filter(author__name='李华').values('tel', 'author__age')
print(result)
"""
# select * from app01_authordetail inner join app01_author on app01_authordetail.id = app01_author.detail_id;
<QuerySet [{'tel': '14710911994', 'author__age': 15}]>
反向查询按表明小写
author__ 表示连接到author表,author__name 表示拿到了author表的name字段
查询自己表中的字段,直接写就好了,如: age
而想要获取被连接表的某个字段,需要表名小写来获取,如: author__age
"""
if __name__ == '__main__':
query()
一对多跨表查询
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
def query():
# 一对多查询 正向查询
# 查询某本书是哪个出版社出版的
result = models.Book.objects.filter(title='不丹美食探索').values('publish__name', 'price')
print(result)
"""
<QuerySet [{'publish__name': '宜都出版社', 'price': Decimal('35.16')}]>
正向查询按属性,所以通过属性名加双下划线连表到另一张表,然后找属性,如: publish__name
查询自己表中的字段,直接写就好了,如: price
"""
# 一对多查询 反向查询
# 查询某本书是哪个出版社出版的
result = models.Publisher.objects.filter(book__title='不丹美食探索').values('name', 'book__price')
print(result)
"""
<QuerySet [{'name': '宜都出版社', 'book__price': Decimal('35.16')}]>
反向查询按表明小写
book__ 表示连接到book表,book__title 表示拿到了book表的title字段
查询自己表中的字段,直接写就好了,如: name
而想要获取被连接表的某个字段,需要表名小写来获取,如: book__price
"""
if __name__ == '__main__':
query()
多对多跨表查询
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
def query():
# 多对多查询 正向查询
# 查询某本书的作者和作者年龄,书籍价格
result = models.Book.objects.filter(title='乌兹别克斯坦旅游景点探秘').values('authors__name', 'authors__age', 'price')
print(result)
"""
<QuerySet [{'authors__name': '李华', 'authors__age': 15, 'price': Decimal('82.70')}, {'authors__name': '罗辉', 'authors__age': 36, 'price': Decimal('82.70')}]>
正向查询按属性,所以通过属性名加双下划线连表到另一张表,然后找属性,如: authors__name, authors__age
查询自己表中的字段,直接写就好了,如: price
"""
# 多对多查询 反向查询
# 查询某本书的作者和作者年龄,书籍价格
result = models.Author.objects.filter(book__title='乌兹别克斯坦旅游景点探秘').values('name', 'age', 'book__price')
print(result)
"""
<QuerySet [{'name': '李华', 'age': 15, 'book__price': Decimal('82.70')}, {'name': '罗辉', 'age': 36, 'book__price': Decimal('82.70')}]>
反向查询按表明小写
book__ 表示连接到book表,book__title 表示拿到了book表的title字段
查询自己表中的字段,直接写就好了,如: name
而想要获取被连接表的某个字段,需要表名小写来获取,如: book__price
"""
if __name__ == '__main__':
query()
通过ORM语句可以看到,多对多查询语句和一对多基本一致,甚至和一对一也一致,所以记住要领就好了。
修改记录
修改这里,普通字段跟单表的修改是一样的,无非就是要注意关系字段的修改。
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
def query():
# 一对一修改
# 修改某个作者的年龄和手机号
models.Author.objects.filter(name='李华').update(age=25)
models.AuthorDetail.objects.filter(author__name='李华').update(tel='14710911999')
# 一对多修改
# 修改某本书的价格和出版社
pub_obj = models.Publisher.objects.get(id=1)
models.Book.objects.filter(title='不丹美食探索').update(
price=108,
# publish=pub_obj,
publish_id=pub_obj.id,
)
# 多对多修改
# 为某本书重新绑定作者
book_obj = models.Book.objects.filter(title='不丹美食探索').first()
# book_obj.authors.set(['1']) # 更新一个,注意: ['1'] id值必须是字符串且必须存在
book_obj.authors.set(['1', '2']) # 更新多个,注意: ['1', '2'] 两个id值必须是字符串且必须存在
# set就是先清除这本书的所有作者,再重新绑定指定的作者
if __name__ == '__main__':
query()
删除记录
一对一/一对多删除
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
def query():
# 一对一删除
# 删除一个作者
# models.Author.objects.filter(id=10).delete() # 不会删除对应详情表的相关关系记录
# models.AuthorDetail.objects.filter(id=10).delete()
"""
注意:由于作者表和作者详情表是一对一关系,删除作者,不会删除详情表的关系字段,需要手动删除详情表的关系记录
但是,如果你直接删除详情表的某条记录,对应的作者表的这条记录也会自动删除,这是因为级联删除关系在起作用
最后,谁受影响取决于一对一外键关系在哪个表中设置,且受是否设置级联删除影响
除此之外,相关的第三张表的相关记录会被自动删除,这也是受级联删除关系影响
"""
# models.AuthorDetail.objects.filter(id=9).delete() # 作者表的相关记录也会被自动删除
# 一对多删除
# 删除一本书
models.Book.objects.filter(id=7).delete()
models.Publisher.objects.filter(id=1).delete()
"""
注意,删除一本书,这本书对应的出版社不会受影响,但第三张表的相关记录会被自动删除,这也是受级联删除关系影响
但是,删除一个出版社,受级联删除的影响,这个出版社出版的所有书籍也会被自动删除;
也因为受级联删除的影响,这本书相关的第三张表的相关记录也会被自动删除
"""
if __name__ == '__main__':
query()
多对多中删除
本小节其实就是学习remove/clear/set,这三个方法的使用。
多对多解除绑定关系
那么,我们想为书籍解除与某个作者的绑定关系怎么办?
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
def query():
author_obj = models.Author.objects.get(id=1)
book_obj = models.Book.objects.get(id=1)
# 使用remove解除绑定,传作者对象或者作者对象的id都一样的
# book_obj.authors.remove(author_obj)
book_obj.authors.remove(author_obj.id)
if __name__ == '__main__':
query()
这样删一个没问题,但是要是删除所有作者怎么办?
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
def query():
author_obj = models.Author.objects.get(id=1)
book_obj = models.Book.objects.get(id=1)
book_obj.authors.clear()
if __name__ == '__main__':
query()
使用clear清空指定书籍的所有作者,无论它有多少作者。
多对多解除绑定再绑定
这种情况是指定书籍不管之前有多少作者,都解除关系,然后重新绑定一个作者。
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
def query():
author_obj1 = models.Author.objects.get(id=1)
author_obj2 = models.Author.objects.get(id=2)
book_obj = models.Book.objects.get(id=1)
book_obj.authors.set(str(author_obj1.id)) # # set的值不能是int类型,否则报错:TypeError: 'int' object is not iterable
book_obj.authors.set([str(author_obj1.id), str(author_obj2.id)]) # # 同时绑定多个作者
if __name__ == '__main__':
query()
set方法等于一次完成clear和add两个操作。
特殊查询
特殊查询就是在原来的查询基础上,进行聚合、分组、操作。
用之前需要先导入:
from django.db.models import Count, Avg, Max, Min, Sum # 用前先导入
聚合分组
聚合
聚合这里没什么难的,也就是avg、sum那些,如果你学过SQL语句,想必不会陌生。
Django中使用这些聚合分组函数,需要先导入再使用。
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
from django.db.models import Count, Avg, Max, Min, Sum # 用前先导入
def query():
# 查询 book 表中书籍的总数
# result = models.Book.objects.all().aggregate(Count('id'))
result = models.Book.objects.aggregate(Count('id')) # 默认取所有后再聚合,所以,可以省略 all
print(result) # {'id__count': 3} # aggregate是ROM的结束语句,因为它得到的结果,已经是Python的字典,不能再用ORM语句了
# 查询 book 表中书籍的平均价格
result = models.Book.objects.aggregate(Avg('price'))
print(result) # {'price__avg': 47.30000000000001}
# 还能自定义别名, 这个没啥说的,查询书籍价格最高的
result = models.Book.objects.aggregate(priceMax=Max('price'))
print(result) # {'priceMax': Decimal('98.16')}
# 求总价
result = models.Book.objects.aggregate(Sum('price'))
print(result) # {'price__sum': Decimal('993.30')}
# 也可以跟条件,然后对筛选后的结果进行聚合
result = models.Book.objects.filter(id__lte=3).aggregate(Avg('price'))
print(result) # {'price__avg': Decimal('34.2300000000000')}
# 也可以一次聚合多个
result = models.Book.objects.filter(id__lte=3).aggregate(Avg('price'), Sum('price'))
print(result) # {'price__avg': Decimal('34.2300000000000'), 'price__sum': Decimal('68.4600000000000')}
if __name__ == '__main__':
query()
小结:
- 使用聚合前需要导入。
- 可以为聚合起别名:
priceMax=Max('price')。 - 可以先对数据进行过滤,然后对过滤结果进行聚合。
- 可以一次聚合多个条件。
- 可以直接使用
aggregate而省略掉all。
分组
分组对应SQL中的group by,分组相对聚合稍微复杂一些。
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
from django.db.models import Count, Avg, Max, Min, Sum # 用前先导入
def query():
# 查询每个出版社出版书籍的平均价格
result = models.Publisher.objects.annotate(avg_price=Avg("book__price")).values('name', 'address', 'avg_price')
print(result)
"""
默认的分组依据是使用Publisher表的id字段,它会自动找book表中的publish_id来分组
# select name, address, avg(p.price) from app01_publisher as p left join app01_book as b on p.id = b.publish_id group by p.id;
注意:annotate中的聚合必须要起别名,想要什么值,就在values中获取
annotate中,book__price 是跨表查询
"""
# 根据book表的publish_id作为分组依据
result = models.Book.objects.values('publish_id').annotate(avg_price=Avg('price'))
# select avg(price) from app01_book group by publish_id;
print(result) # <QuerySet [{'publish_id': 2, 'avg_price': Decimal('11.2600000000000')}, {'publish_id': 3, 'avg_price': Decimal('69.9500000000000')}]>
# 查询每个作者出版书的最高价格
result = models.Book.objects.values('authors__id').annotate(max_price=Max('price'))
print(result)
"""
在左连接查询中
<QuerySet [
{'authors__id': None, 'max_price': Decimal('57.2000000000000')}, # 有本书它没有绑定作者, 所以 authors__id 为 None
{'authors__id': 1, 'max_price': Decimal('82.7000000000000')},
{'authors__id': 2, 'max_price': Decimal('82.7000000000000')}
]>
"""
result = models.Author.objects.annotate(max_price=Max('book__price')).values('max_price', 'name')
print(result)
"""
<QuerySet [
{'name': '李华', 'max_price': Decimal('82.7000000000000')},
{'name': '罗辉', 'max_price': Decimal('82.7000000000000')},
# 下面几个作者没有出版书籍,所以 max_price 为 None
{'name': '周亮', 'max_price': None},
{'name': '刘玉兰', 'max_price': None},
{'name': '张杨', 'max_price': None},
{'name': '刘云', 'max_price': None},
{'name': '莫强', 'max_price': None},
{'name': '刘丹丹', 'max_price': None}
]>
"""
if __name__ == '__main__':
query()
注意:在连表时,ORM默认使用的是left join,可能导致结果中出现一些"无用"的数据,比如以book表为主表做连表查询,那么有的作者可能没有写书;以author表作为主表,有的书没有作者......等等这些情况。你可以settings中配置ORM转原生SQL的log配置,来查看"翻译"结果。
F & Q
F查询通常应用于本表的多字段比较,而Q查询则多用于多条件查询中。
用之前需要先导入:
from django.db.models import F, Q
来看怎么用的。
必要的准备
现在,有文章表Article,表结构如下:
from django.db import models
class Article(models.Model):
""" 文章表 """
title = models.CharField(max_length=64, verbose_name='标题')
# content = models.TextField(verbose_name='文章内容')
like = models.IntegerField(verbose_name='点赞数', default=0)
collect = models.IntegerField(verbose_name='收藏数', default=0)
comment = models.IntegerField(verbose_name='评论数', default=0)
def __str__(self):
return self.title
别忘了数据库迁移:
python manage.py makemigrations
python manage.py migrate
插入一些数据:
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
import random
from faker import Faker
from app01 import models
from django.db.models import Count, Avg, Max, Min, Sum # 用前先导入
from django.db.models import F, Q
fk = Faker(locale='zh_CN')
def query():
tmp_list = [
models.Article(
title=fk.sentence(),
like=random.randint(1, 200),
comment=random.randint(1, 200),
collect=random.randint(1, 200),
)
for i in range(20)]
models.Article.objects.bulk_create(tmp_list)
if __name__ == '__main__':
query()
F
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
from django.db.models import F, Q
def query():
# 查询点赞数大于评论数的文章
# 在没有使用 F 查询之前,我们可以手动来处理
at_obj = models.Article.objects.all()
article_list = [article for article in at_obj if article.like > article.comment]
print(article_list)
# 现在有了 F 查询
at_obj = models.Article.objects.filter(like__gt=F('comment'))
print(at_obj)
"""
like__gt 点赞数小于,使用F('要比较的字段名称')
"""
# F 查询可以比较字段之外,也可以进行4则运算和取模运算
# 将所有收藏数加10
# 手动处理
# at_obj = models.Article.objects.all()
# for at in at_obj:
# at.collect += 10
# at.save()
# 使用 F 处理
models.Article.objects.update(collect=F('collect') + 10)
if __name__ == '__main__':
query()
Q
Q查询中可以使用的连接符:
| 连接符 | 描述 |
|---|---|
| |
相当于SQL中的or |
& |
相当于SQL中的and |
~ |
相当于SQL中的not |
上示例:
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
from django.db.models import F, Q
def query():
# 查询 like > 100 or comment >100 的文章
at_obj = models.Article.objects.filter(Q(like__gt=100) | Q(comment__gt=100))
print(at_obj)
# 查询 (like > 100 or comment >100) and collect < 20 的文章
# at_obj = models.Article.objects.filter((Q(like__gt=100) | Q(comment__gt=100)) & Q(collect__lt=20))
at_obj = models.Article.objects.filter(Q(like__gt=100) | Q(comment__gt=100), Q(collect__lt=20)) # 逗号相当于 and
"""
上面两个语句是等价的,在Q查询中,多个连接符组成多条件查询,算是一组查询条件,如:Q(like__gt=100) | Q(comment__gt=100)
"""
print(at_obj)
# Q 查询中也支持取反
# 查询 (like > 100 or comment >100) and collect != 30
at_obj = models.Article.objects.filter(Q(like__gt=100) | Q(comment__gt=100), ~Q(collect=30))
print(at_obj)
if __name__ == '__main__':
query()
ORM执行原生SQL
在模型查询不够或者有些情况下必须使用原生SQL查询的情况下,Django提供了两种方式支持使用原生SQL:
raw方法用于查询本表的原生SQL语句,并返回模型实例。- 执行自定义原生SQL查询,彻底绕开ORM直接和数据库打交道。
先来看第一种:
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
def query():
# raw只能查询本表的数据
result = models.Book.objects.raw('select * from app01_book;')
# print(result) # <RawQuerySet: select * from app01_book;>
# for item in result:
# print(item, item.title)
"""
格林纳达旅游指南 格林纳达旅游指南
马里旅游指南 马里旅游指南
乌兹别克斯坦旅游景点探秘 乌兹别克斯坦旅游景点探秘
"""
# 使用 params 参数来代替字符串格式化,防止SQL注入
result = models.Book.objects.raw('select * from app01_book where id = %s;', params=[3, ]) # 一个或多个参数都以列表形式设置
for item in result:
print(item, item.title)
if __name__ == '__main__':
query()
再来看第二种,这种方式提供是直接从Django提供的接口中获取数据库连接,然后像使用pymysql一样操作数据库。
这里以MySQL数据库为例,所以,你要先配置好MySQL的相关配置。
然后再操作:
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "demo.settings") # demo:项目名称
django.setup()
from app01 import models
from django.db import connection # 用前先导入
def query():
# 通过connection.cursor() 获取游标
cursor = connection.cursor()
# 通过游标执行SQL语句
cursor.execute('select * from user;')
result = cursor.fetchall()
print(result) # (('222', 'lisi'), ('333', 'wangwu'), ('111', 'zhangkai'), ('444', 'zhaoliu'))
# 也要注意防止SQL注入
cursor.execute('select * from user where user = %s;', ('zhangkai',))
result = cursor.fetchall()
print(result) # (('111', 'zhangkai'),)
cursor.close()
if __name__ == '__main__':
query()
关于pymysql,参考:https://www.cnblogs.com/Neeo/articles/11330801.html
ORM事务和锁
Django2.2 + MySQL5.7
事务
在Django中,一般有三种方式添加事务:
- 全局事务,它处理事务的方式是,将每个请求都包裹在事务中,在整个请求流程中,在调用视图函数之前,就开启一个事务,如果请求正常的处理并且返回正确的结果,提交事务,否则回滚事务。
- 局部事务,全局事务有点无脑和呆板,所以,这里推荐使用局部事务,局部事务又可以通过下面这两种方式设置:
- 基于视图,只为某个视图开启事务。
- 基于
with语句,作用于with语句中。
全局事务
全局事务的开启非常简单,只需要你在settings中配置:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'userinfo', # 你的数据库名称
'USER': 'root', # 你的数据库用户名
'PASSWORD': 'root1234', # 你的数据库密码
'HOST': '127.0.0.1', # 你的数据库主机,留空默认为localhost
'PORT': '3306', # 你的数据库端口
"ATOMIC_REQUESTS": True, # 全局开启事务,绑定的是http请求响应整个过程
# "AUTOCOMMIT": False, # 全局取消自动提交,慎用
}
}
当配置生效后,每来一个HTTP请求,Django会将该HTTP请求中的所有SQL操作,都放在一个事务中执行。
但问题来了,我想对某个视图"放水"怎么办?稳住,non_atomic_requests装饰器来解决被装饰的视图不受事务的影响:
from django.shortcuts import render, HttpResponse, redirect
from django.db import transaction # 用前导入
@transaction.non_atomic_requests # 加装饰器
def index(request):
return HttpResponse('OK')
注意,不推荐使用全局事务。
局部事务
相对于全局事务来说,不够灵活,所以,Django又提供了 transaction.atomic来更加明确的控制事务。
基于视图函数的事务
先来看用法之一,就是以装饰器的形式加装在视图函数上:
from django.shortcuts import render, HttpResponse, redirect
from django.db import transaction # 用前导入
@transaction.atomic # 加装饰器
def index(request):
# 正常写业务逻辑,其中的SQL都会打包成一个事务
return HttpResponse('OK')
非常的简单,事务控制比较灵活。
再来看另一种实现方式。
基于with上下文管理器实现事务
这种方式粒度更新,至于处于上下文管理器中的SQL才会打包成事务。
from django.shortcuts import render, HttpResponse, redirect
from django.db import transaction
def index(request):
# 在with语句之外SQL不会打包成事务
with transaction.atomic():
# 在with中的SQL都会打包成一个事务
pass
# 在with语句之外SQL不会打包成事务
return HttpResponse('OK')
锁
在事务中,通常也会搭配锁的使用。所以,这里再说下Django中锁的应用。
Django中,可以加行锁和表锁,来看怎么加。
行锁
在ORM语句中,直接使用for_update进行加锁。
models.Book.objects.select_for_update().filter(id=1)
表锁(了解)
from django.db import models
from django.db import connection
class Job(models.Model):
title = models.CharField(max_length=64, verbose_name='标题')
def lock(self):
""" Lock table. """
cursor = connection.cursor()
table = self.model._meta.db_table
cursor.execute("LOCK TABLES %s WRITE" % table)
row = cursor.fetchone()
return row
def unlock(self):
""" Unlock the table. """
cursor = connection.cursor()
table = self.model._meta.db_table
cursor.execute("UNLOCK TABLES")
row = cursor.fetchone()
return row
查询操作练习
查询"机械工业出版社"出版过的价格大于20的书籍
查询2020年9月出版的所有以"py"开头的书籍名称
查询价格为50,100,或者150的所有书籍名称及其出版社名称
查询价格在100~200之间的所有书籍名称及其价格
查询"机械工业出版社"出版过的所有书籍的价格,并以价格降序排序和去重
查询每个作者的姓名以及出版的书的最高价格
查询作者id大于2作者的姓名以及出版的书的最高价格
查询作者id大于2或者作者年龄大于等于20岁的女作者的姓名以及出版的书的最高价格
查询每个作者出版的书的最高价格的平均值
每个作者出版的所有书的最高价格以及最高价格的那本书的名称
统计每一个出版社的最便宜的书
统计每一本书的作者个数
统计每一本以py开头的书籍的作者个数
统计不止一个作者的图书
统计每一本以py开头的书籍的作者个数
统计不止一个作者的图书
根据一本图书作者数量的多少对查询集 QuerySet进行排序
查询各个作者出的书的总价格
坑
max_length不生效
有同学问我,我明明模型类中指定了max_length值,为啥不生效?
答案就是:
- sqlite数据库不生效。
- mysql数据库生效。
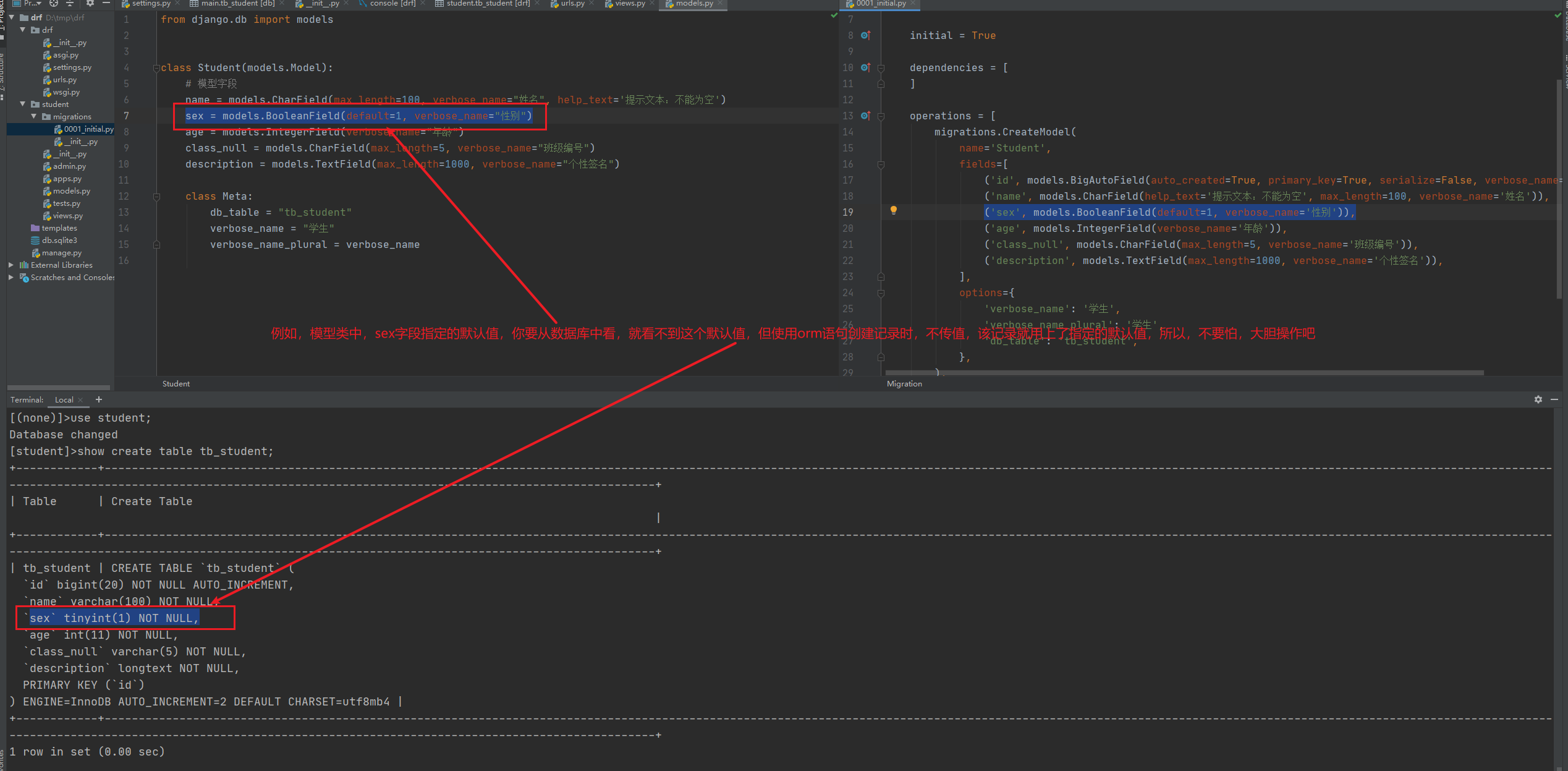
有些约束为啥从数据库中看不到
有同学问我,为啥模型类中的有些约束能在数据库中看到,有些看不到。那些看不到的,是不是没有起作用呀?
答案是:看不到的不代表不起作用,这要以测试结果为准,但一般不会出现这种问题,所以,请相信你在模型类中定义的字段信息。
that's all,see also:
Django基础五之django模型层(一)单表操作 | https://www.cnblogs.com/maple-shaw/articles/9323320.html)> | https://www.cnblogs.com/yuanchenqi/articles/8933283.html | django 中的USE_TZ设置为true有何影响? | django中的时区设置TIME_ZONE,USE_TZ | Django学习目录 | django数据模型中关于on_delete的使用 | https://www.cnblogs.com/yuanchenqi/articles/8963244.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号