【算法笔记】生成式人工智能导论
- 15 生成式人工智能
- 16 Trick - Speculative Decoding
- 17 有关影像的生成式AI
15 生成式人工智能
课程链接:第15讲 为什么语言模型用文字接龙,图片生成不用像素接龙呢?
1 什么是生成式人工智能(Generative AI)?
机器产生复杂而有结构的物件,例如:文字、图像、音频等。
复杂:指可能性没有办法穷举。 例如可以生成无数种文章、无数种图片、无数种音频等。
有结构:指由有限的基本单位构成。例如文字由token组成、图片由像素组成、音频由采样点组成。



生成式人工智能的本质:输入条件,利用AI生成由基本单位用正确的排序组合起来的物件。


2 有哪些生成策略?
2.1 Autoregressive Generation (AR,自回归)



2.1.1 自回归生成的缺点
限制:循序渐进按照某种顺序依次生成。


2.2 Non-autoregressive Generation (NAR,非自回归)

2.2.1 非自回归生成文字
方法一:由模型预测一个max_len最大长度,再通过模型一次生成max_len个文字。
方法二:由模型直接输出固定长度的文字,再删除后面的无效字符。


2.2.2 非自回归生成的缺点
一次性生成所有位置的元素时,每个位置生成的元素所表达的含义可能不同,不能形成一个正常的整体。


2.2.3 如何保证所有位置上的内容一致性?
事先将整体内容定好,输入给生成式AI。

方法一:事先定义一个随机向量。

方法二:自回归生成初略 + 非自回归精细化
初略版本不需要人看懂,只要模型能看懂就可以。

如何产生初略版本?
方法一:Encoder压缩:压缩尺寸、压缩元素维度



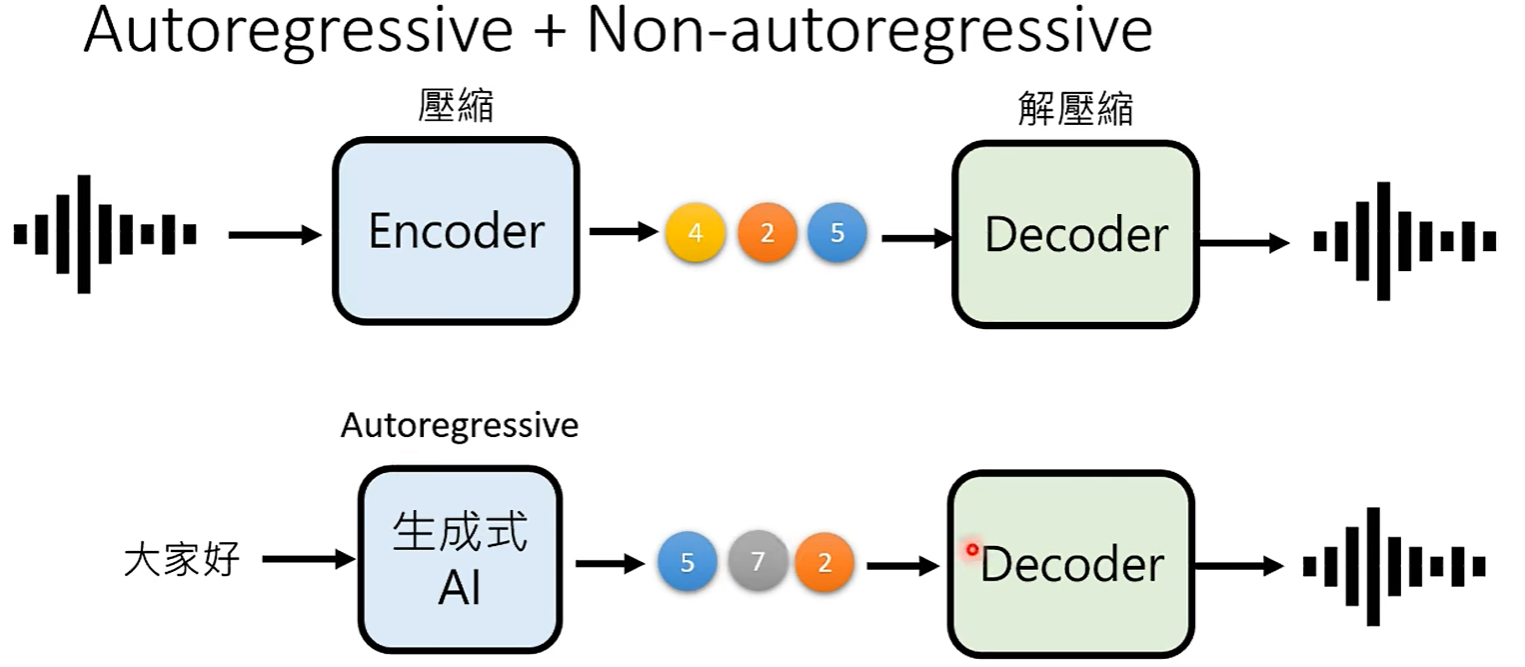
方法二:多次Non-Autoregressive Generation
每个迭代版本,可以是从小尺寸到大尺寸,也可以是从模糊到清晰,或者,每次将生成不好的部分抹除掉。
中间结果可以不是图片,可以是压缩后的结果。



Autoregressive的迭代次数可能远大于Non-Autoregressive的迭代次数,例如使用autoregressive将1024x1024的图像压缩为256x256的迭代次数>>使用non-autoregressive的方式的迭代次数。


16 Trick - Speculative Decoding
课程链接:可以加速所有语言模型生成速度的神奇外挂-Speculative Decoding


问题:如果预言家可以预测接下来生成的内容为什么不让预言家直接生成?
预言家没有办法精准的预测语言模型的输出,有可能出错。
如何知道预言家从哪里出错? - 生成结果与预言家的结果比对。


问题:谁可以担任预言家?
预言家模型要求:超快速、犯错没关系。
方法一:Non-autoregressive Model
方法二:压缩后的模型

方法三:不一定非要是模型 - 搜索引擎

方法四:多个预言家

17 有关影像的生成式AI
课程链接:有关影像的生成式AI(上)
1 有哪些影像生成方式?
1.1 文字生成影像


1.1.1 文字生成影像的数据集


1.1.2 如何训练文字生成图像?
方式一:自回归文字生成图像patch。很少使用这种方式,因为一张图片中的patch数量太多了。

方式二:非自回归。一次生成所有patch。概念上如下左图,实际上如下右图(即使在attention中增加文字说明,也不能保证让多个patch内容保持一致性)。


1.2 文字生成影片
方法一:non-autoregressive

问题所在:patch跟空间和时序上的所有patch计算注意力。
解决方案:patch空间做一次2D attention,时间上做一次attention。两个attention交替使用。



方法二:多次non-autoregressive




1.3 影像生成影像

1.4 其他输入生成影像
例1:输入 语音+人像图片,生成人像说出语音的视频
例2:输入 草图,生成精细的图。输入 人体姿态,生成照片。


2 AI如何理解影像?
patch的压缩可以是尺寸的压缩,也可以是时序上的压缩。



3 如何评估影像生成的好坏?
文字生成任务中,人工评估是最准确的,但是成本很高,所以用chatgpt代替人进行评估。在图像生成中,也有类似的方法CLIP。CLIP高分就是好,低分就是坏。


但是,有写图像很难描述。


4 个人化的图像生成
定制化的图像生成:使用一个没有用过的符号代表图片,因为任何不相关的文字都可能污染生成过程。


5 影像生成经典算法



5.1 文字生成影像的挑战 - non-autoregressive 所有patch内容不一致

5.2 如何让所有patch内容保持一致?- 脑补信息保持一致

如何训练资讯抽取模型? - 资讯抽取模型与图片生成模型端到端训练(auto-encoder)
资讯不一定是文字,可以是数值向量,不一定要人看懂,只要Decoder能看懂就行。


推理时资讯如何生成? - 随机产生

5.3 VAE
训练时,Encoder和Decoder一起训练(autoencoder)。推理时,随机产生资讯。

5.4 Flow-based
观察到VAE中Encoder和Decoder是一样的功能,只是流程正好相反。所以,只训练一个Decoder就好,用Decoder的反函数生成资讯。

5.5 关于noise的实验 - 证明资讯的有效性


5.6 diffusion model

diffusion Model的问题:denoise需要进行很多次。
denoise Model的任务:去除杂讯。
5.6.1 如何训练denoise Model去除杂讯?
如何生成denoise Model 训练资料?- 图像+噪声

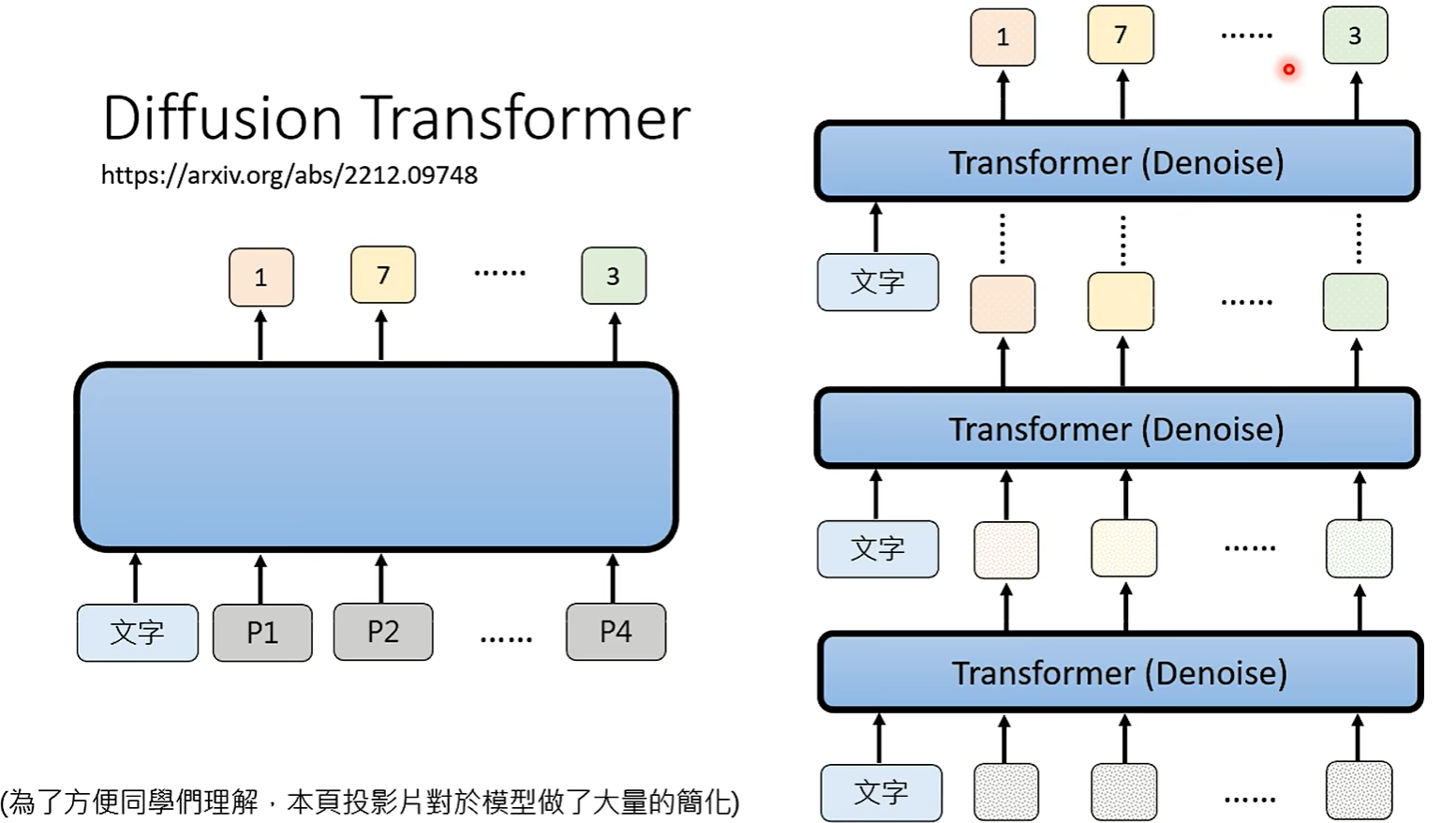
5.6.2 defusion transformer

5.7 GAN (Generative Adversarial Network)
VAE, Flow based, Defusion 都是训练Encoder生成noise资讯,再基于noise生成图像。(从图像中学习生成图像)
而GAN是先训练一个判别器,再用判别器训练图像生成模型生成图像。(从判别器学习生成图像)
判别器跟CLIP很像,只是CLIP中给出的负样本是随机打乱文字和图片的组合,而GAN中比较差的图像生成模型根据句子生成一个品质差的图像。


Generator的任务就是产生一张较好的图像,让判别器打出高分。

多数文献中都给出了脑补杂讯,但是根据经验,文字生图任务中,不给出杂讯,仍然可以得到很好的结果。

跟RLHF对比,GAN中的判别器作为reward Model,区别在于GAN中 reward model 产生的都是评分不好的,而RLHF中评分好坏由专家标注。

GAN可以看做外挂插件

6 生成影像与人类互动

Genie






 浙公网安备 33010602011771号
浙公网安备 33010602011771号