一、MongoDB集群的三种核心模式-介绍
1. 主从复制模式(Master-Slave,已过时)
定义:
早期的主从架构,由一个**主节点(Master)和一个/多个从节点(Slave)**组成。主节点负责所有写入操作,从节点通过复制主节点的操作日志(oplog)同步数据,仅提供只读服务。
特点:
主节点故障时需手动切换从节点为主节点,无自动故障转移能力。
从节点之间不感知,数据同步依赖主节点,存在单点故障风险。
适用场景:
仅用于早期简单备份或读写分离场景,MongoDB官方已明确不推荐生产环境使用,建议用副本集替代。
2. 副本集模式(Replica Set,推荐生产环境)
定义:
MongoDB的核心高可用解决方案,由一组(至少3个)节点组成,包括主节点(Primary)、从节点(Secondary)和可选的仲裁节点(Arbiter)。主节点处理所有写入操作,从节点异步复制主节点数据,仲裁节点仅参与选举投票(不存储数据)。
核心能力:
自动故障转移:主节点故障时,从节点通过选举自动选出新主节点(需多数节点存活)。
数据冗余:多节点存储相同数据,避免单点故障导致数据丢失。
读写分离:从节点可分担读请求,提升集群读性能。
适用场景:
对高可用性要求高的生产环境(如电商、金融系统)。
需要数据备份和灾备的场景。
读多写少的业务模型(可通过从节点扩展读能力)。
典型架构:3节点副本集(1主+2从)或5节点副本集(1主+3从+1仲裁),推荐奇数节点以确保选举有效性。
3. 分片集群模式(Sharding,大规模数据场景)
定义:
MongoDB的水平扩展解决方案,通过**分片(Shard)**将数据分布式存储在多个节点上,每个分片通常是一个副本集(确保高可用)。
分片集群由以下组件构成:
分片(Shard):存储部分数据的副本集,所有分片数据总和为完整数据集。
配置服务器(Config Server):存储集群元数据(如分片键、数据分布信息),需部署为副本集。
查询路由器(mongos):客户端入口,负责将请求路由到对应的分片,并合并结果返回。
核心能力:
水平扩展:支持数据量和并发量的线性增长,突破单机存储和性能瓶颈。
自动数据均衡:当分片间数据分布不均时,自动迁移数据块(chunk)实现负载均衡。
灵活分片策略:支持基于范围(Range)或哈希(Hash)的分片键,适配不同业务场景。
适用场景:
数据量超过单机存储能力(如TB级以上)。
高并发读写场景(如社交、日志系统)。
需要跨地域部署数据的全球化应用。
典型架构:至少2个分片(每个分片为3节点副本集)+ 3节点配置服务器副本集 + 2个以上mongos节点。
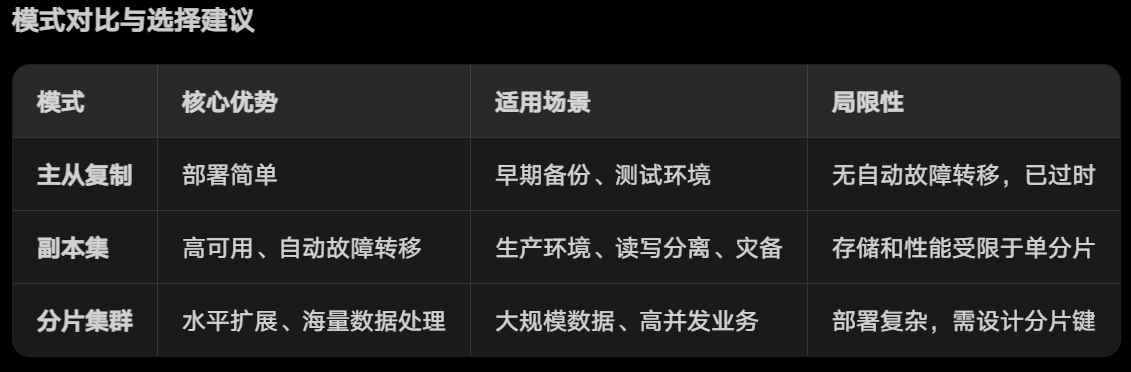
总结
优先选择副本集:绝大多数生产环境的基础高可用方案,简单可靠。
分片集群:当数据量或并发量达到单机瓶颈时,结合副本集使用(分片+副本集是MongoDB企业级部署的标准架构)。
主从复制:仅用于历史系统维护,新项目避免使用。
根据你的业务需求(如数据量、可用性要求、并发量),可选择单一模式或组合模式(如分片+副本集)。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号