文档整理:dolphinscheduler

龙蜥8.6系统:apprun用户
一.JDK1.8 安装采用 jdk-8-321.an8.x86_64.rpm 部署[略]
二.HADOOP安装:【做免密认证,基于运行用户apprun】
Hadoop安装主要就是配置文件的修改,一般在主节点进行修改,完毕后scp下发给其他各个从节点机器。

cd /apprun/soft/
tar -zxf hadoop-3.2.2.tar.gz -C /apprun/server/
cd /apprun/server
ln -s hadoop-3.2.2/ hadoop
配置文件修改:
hadoop-env.sh


1 添加: 在54行 2 export JAVA_HOME=/apprun/jdk 3 4 5 #文件最后添加: 6 export HDFS_NAMENODE_USER=apprun 7 export HDFS_DATANODE_USER=apprun 8 export HDFS_SECONDARYNAMENODE_USER=apprun 9 export YARN_RESOURCEMANAGER_USER=apprun 10 export YARN_NODEMANAGER_USER=apprun
core-site.xml [建议主机添加内部映射,用内部域名寻址] <configuration>修改如下
1 <configuration> 2 <property> 3 <name>fs.defaultFS</name> 4 <value>hdfs://192.168.109.139:8020</value> 5 </property> 6 7 <property> 8 <name>hadoop.tmp.dir</name> 9 <value>/apprun/hadoop_tmp/data/hadoop</value> 10 </property> 11 12 <!-- 设置HDFS web UI用户身份 --> 13 <property> 14 <name>hadoop.http.staticuser.user</name> 15 <value>apprun</value> 16 </property> 17 18 <!-- 整合hive --> 19 <property> 20 <name>hadoop.proxyuser.apprun.hosts</name> 21 <value>*</value> 22 </property> 23 24 <property> 25 <name>hadoop.proxyuser.apprun.groups</name> 26 <value>*</value> 27 </property> 28 </configuration>
hdfs-site.xml <configuration>修改如下
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.109.140:50090</value>
</property>
</configuration>
mapred-site.xml <configuration>修改如下
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
yarn-site.xml <configuration>修改如下
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.109.139</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://192.168.109.139:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
workers
Hadoop 3.x之后,slaves文件改名为workers,用于指定集群中的DataNode和NodeManager所在的主机名。
workers文件的配置,列出所有从节点的主机名或IP。
192.168.109.140 192.168.109.141
同步安装包
cd /apprun/server/
rsync -avz --progress -e ssh ./hadoop-3.2.2 192.168.109.140:$PWD
rsync -avz --progress -e ssh ./hadoop-3.2.2 192.168.109.141:$PWD
然后同步的2台主机[192.168.109.140\192.168.109.141]做软连接
cd /apprun/server/ && ln -s hadoop-3.2.2/ hadoop
Hadoop环境变量
3台机器都需要配置环境变量文件
vim /etc/profile 添加
#HADOOP_HOME
export HADOOP_HOME=/apprun/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
Hadoop集群启动
在主节点上使用以下命令启动HDFS NameNode:
$HADOOP_HOME/bin/hdfs --daemon start namenode
在每个从节点上使用以下命令启动HDFS DataNode:
$HADOOP_HOME/bin/hdfs --daemon start datanode
在hadoop02上使用以下命令启动HDFS SecondaryNameNode:
$HADOOP_HOME/bin/hdfs --daemon start secondarynamenode
namenode集群页面管理:http://192.168.109.139:9870/explorer.html
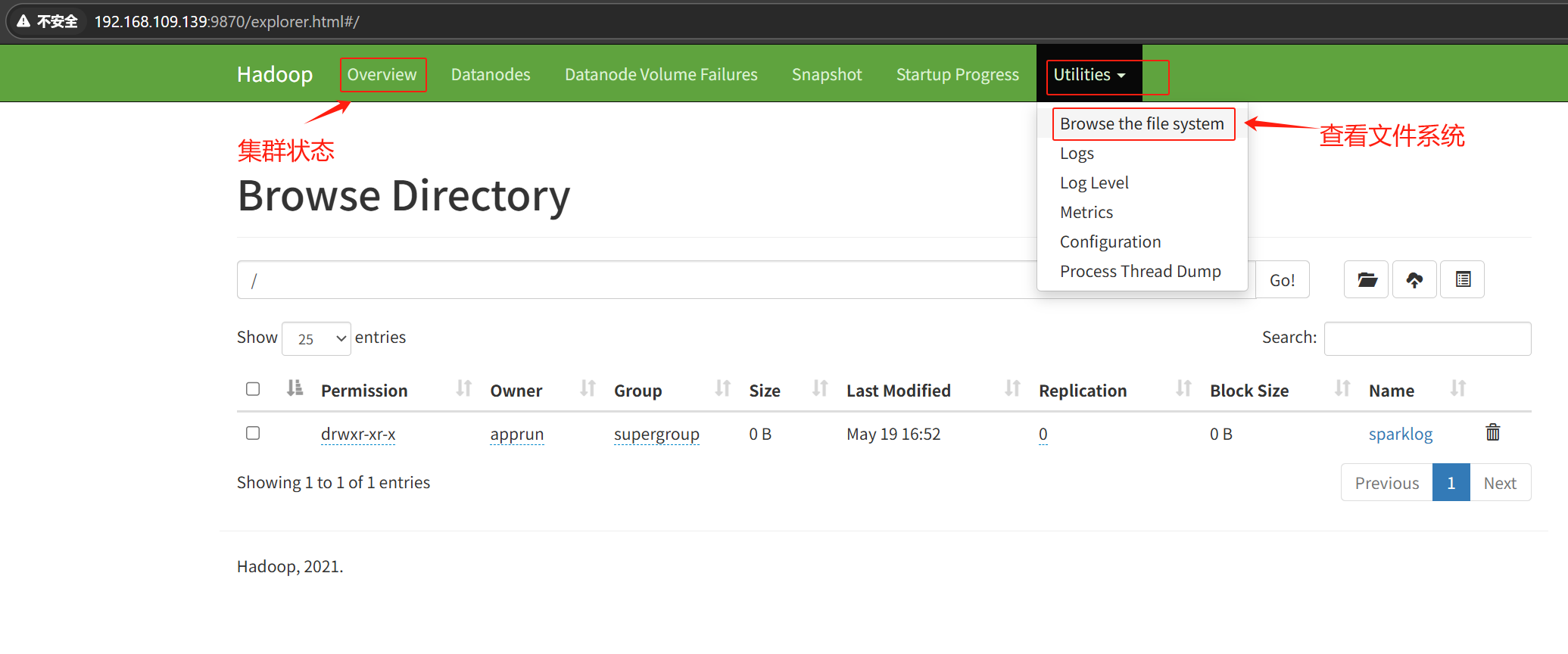
三.ZOOKEEPER集群部署
采用 zookeeper-3.9.3-1.an8.x86_64.rpm 安装部署;
修改配置文件:
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/apprun/data/zookeeper clientPort=2181 autopurge.snapRetainCount=3 autopurge.purgeInterval=1 server.1=192.168.109.139:2888:3888 server.2=192.168.109.140:2888:3888 server.3=192.168.109.141:2888:3888
添加myid配置:

echo 1 > /apprun/data/zookeeper/myid

echo 2 > /apprun/data/zookeeper/myid

echo 3 > /apprun/data/zookeeper/myid
三台机器启动zookeeper服务
sudo systemctl start zookeeper
检查zk集群状态:
/apprun/zookeeper/bin/zkServer.sh status
四.MYSQL80安装
安装【略】
mysql -uroot -p
Wayidong@100!2025
创建dolphinscheduler数据库
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
创建用户并赋予权限
CREATE USER 'dolphinscheduler'@'%' IDENTIFIED BY 'YiDwang@2025123!';
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%' WITH GRANT OPTION;
flush privileges;
创建notebook数据库
CREATE DATABASE notebook DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
创建用户并赋予权限
CREATE USER 'notebook'@'%' IDENTIFIED BY 'YiDwang@2025123!';
GRANT ALL PRIVILEGES ON notebook.* TO 'notebook'@'%' WITH GRANT OPTION;
flush privileges;
五.DC【dolphinscheduler】集群部署 【要做免密认证,基于运行用户apprun,如果是按官方的基于dolphinscheduler用户运行就基于dolphinscheduler用户做免密认证】

官网文档指导:DolphinScheduler | 文档中心
安装psmisc(两台节点)
yum install -y psmisc
上传安装包:
cd /apprun/soft && tar -zxf apache-dolphinscheduler-1.3.9-bin.tar.gz && cd /apprun/soft/apache-dolphinscheduler-1.3.9-bin/lib
导入mysql驱动jar包mysql-connector-j-8.0.31.jar 到 /apprun/soft/apache-dolphinscheduler-1.3.9-bin/lib
下载地址:MySQL :: Download MySQL Connector/J (Archived Versions)
官网下载mysql连接驱动jar包下载指导:官网下载mysql连接驱动jar包教程「建议收藏」-腾讯云开发者社区-腾讯云
修改数据库配置文件:
cd /apprun/soft/apache-dolphinscheduler-1.3.9-bin/conf/
注释默认的psql配置,启用mysql配置,如下修改
# datasource configuration #spring.datasource.driver-class-name=org.postgresql.Driver #spring.datasource.url=jdbc:postgresql://127.0.0.1:5432/dolphinscheduler #spring.datasource.username=root #spring.datasource.password=root # mysql example spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://192.168.109.138:3306/dolphinscheduler?characterEncoding=UTF-8&allowMultiQueries=true spring.datasource.username=dolphinscheduler spring.datasource.password=YiDwang@2025123!
执行创建表脚本:
cd /apprun/soft/apache-dolphinscheduler-1.3.9-bin/
sh script/create-dolphinscheduler.sh
修改环境变量配置文件:
将不需要使用的组件进行注释
cd /apprun/soft/apache-dolphinscheduler-1.3.9-bin/conf/env
# # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # #export HADOOP_HOME=/opt/soft/hadoop #export HADOOP_CONF_DIR=/opt/soft/hadoop/etc/hadoop #export SPARK_HOME1=/opt/soft/spark1 #export SPARK_HOME2=/opt/soft/spark2 #export PYTHON_HOME=/opt/soft/python #export JAVA_HOME=/opt/soft/java #export HIVE_HOME=/opt/soft/hive #export FLINK_HOME=/opt/soft/flink #export DATAX_HOME=/opt/soft/datax export HADOOP_CONF_DIR=/apprun/api_soft/hadoop/etc/hadoop export JAVA_HOME=/apprun/jdk export HIVE_HOME=/opt/cloudera/parcels/CDH/lib/hive export DATAX_HOME=/export/server/datax/bin/datax.py export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME:$JAVA_HOME/bin:$HIVE_HOME/bin:$FLINK_HOME/bin:$DATAX_HOME/bin:$PATH
将jdk软链到/usr/bin/java下
sudo ln -s /apprun/jdk/bin/java /usr/bin/java
修改部署配置文件:
cd /apprun/soft/apache-dolphinscheduler-1.3.9-bin/conf/config
# # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # # NOTICE : If the following config has special characters in the variable `.*[]^${}\+?|()@#&`, Please escape, for example, `[` escape to `\[` # postgresql or mysql dbtype="mysql" # db config # db address and port dbhost="192.168.109.138:3306" # db username username="dolphinscheduler" # database name dbname="dolphinscheduler" # db passwprd # NOTICE: if there are special characters, please use the \ to escape, for example, `[` escape to `\[` password="YiDwang@2025123!" # zk cluster zkQuorum="192.168.109.139:2181,192.168.109.140:2181,192.168.109.141:2181" # Note: the target installation path for dolphinscheduler, please not config as the same as the current path (pwd) installPath="/apprun/server/data1_1T/dolphinscheduler" # deployment user # Note: the deployment user needs to have sudo privileges and permissions to operate hdfs. If hdfs is enabled, the root directory needs to be created by itself deployUser="apprun" # alert config # mail server host mailServerHost="smtp.exmail.qq.com" # mail server port # note: Different protocols and encryption methods correspond to different ports, when SSL/TLS is enabled, make sure the port is correct. mailServerPort="25" # sender mailSender="xxxxxxxxxx" # user mailUser="xxxxxxxxxx" # sender password # note: The mail.passwd is email service authorization code, not the email login password. mailPassword="xxxxxxxxxx" # TLS mail protocol support starttlsEnable="true" # SSL mail protocol support # only one of TLS and SSL can be in the true state. sslEnable="false" #note: sslTrust is the same as mailServerHost sslTrust="smtp.exmail.qq.com" # user data local directory path, please make sure the directory exists and have read write permissions dataBasedirPath="/tmp/dolphinscheduler" # resource storage type: HDFS, S3, NONE resourceStorageType="NONE" # resource store on HDFS/S3 path, resource file will store to this hadoop hdfs path, self configuration, please make sure the directory exists on hdfs and have read w rite permissions. "/dolphinscheduler" is recommended resourceUploadPath="/dolphinscheduler" # if resourceStorageType is HDFS,defaultFS write namenode address,HA you need to put core-site.xml and hdfs-site.xml in the conf directory. # if S3,write S3 address,HA,for example :s3a://dolphinscheduler, # Note,s3 be sure to create the root directory /dolphinscheduler defaultFS="hdfs://192.168.109.139:8020" # if resourceStorageType is S3, the following three configuration is required, otherwise please ignore #s3Endpoint="http://192.168.xx.xx:9010" #s3AccessKey="xxxxxxxxxx" #s3SecretKey="xxxxxxxxxx" # resourcemanager port, the default value is 8088 if not specified resourceManagerHttpAddressPort="8088" # if resourcemanager HA is enabled, please set the HA IPs; if resourcemanager is single, keep this value empty yarnHaIps="" # if resourcemanager HA is enabled or not use resourcemanager, please keep the default value; If resourcemanager is single, you only need to replace ds1 to actual res ourcemanager hostname singleYarnIp="192.168.109.139" # who have permissions to create directory under HDFS/S3 root path # Note: if kerberos is enabled, please config hdfsRootUser= hdfsRootUser="hdfs" # kerberos config # whether kerberos starts, if kerberos starts, following four items need to config, otherwise please ignore kerberosStartUp="false" # kdc krb5 config file path krb5ConfPath="$installPath/conf/krb5.conf" # keytab username keytabUserName="hdfs-mycluster@ESZ.COM" # username keytab path keytabPath="$installPath/conf/hdfs.headless.keytab" # kerberos expire time, the unit is hour kerberosExpireTime="2" # api server port apiServerPort="12345" # install hosts # Note: install the scheduled hostname list. If it is pseudo-distributed, just write a pseudo-distributed hostname ips="192.168.109.140,192.168.109.141" # ssh port, default 22 # Note: if ssh port is not default, modify here sshPort="22" # run master machine # Note: list of hosts hostname for deploying master masters="192.168.109.140" # run worker machine # note: need to write the worker group name of each worker, the default value is "default" workers="192.168.109.140:default,192.168.109.141:default" # run alert machine # note: list of machine hostnames for deploying alert server alertServer="192.168.109.140" # run api machine # note: list of machine hostnames for deploying api server apiServers="192.168.109.140"
安装:
执行一键部署脚本
cd /apprun/soft/apache-dolphinscheduler-1.3.9-bin/ && sh install.sh
l WebUI登入
访问DS: http://192.168.109.140:12345/dolphinscheduler
用户名: admin
密码: dolphinscheduler123
默认用户密码

六. Spark standalone集群环境部署

官方指导文档:概述 - Spark 3.5.5 文档

cd /apprun/soft/ && tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C /apprun/server/ && cd /apprun/server
ln -s spark-3.1.2-bin-hadoop3.2 spark
修改配置文件:
【workers】
cd /apprun/server/spark/conf && cp workers.template workers
192.168.109.139 192.168.109.140 192.168.109.141
【spark-env.sh】
cd /apprun/server/spark/conf && cp spark-env.sh.template spark-env.sh
#!/usr/bin/env bash JAVA_HOME=/apprun/jdk HADOOP_CONF_DIR=/apprun/server/hadoop/etc/hadoop YARN_CONF_DIR=/apprun/server/hadoop/etc/hadoop export SPARK_MASTER_HOST=192.168.109.139 export SPARK_MASTER_PORT=7077 SPARK_MASTER_WEBUI_PORT=8080 SPARK_WORKER_CORES=2 SPARK_WORKER_MEMORY=2g SPARK_WORKER_PORT=7078 SPARK_WORKER_WEBUI_PORT=8081 SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://192.168.109.139:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
【配置spark应用日志】
第一步: 在HDFS上创建应用运行事件日志目录:
hdfs dfs -mkdir -p /sparklog/
第二步: 配置spark-defaults.conf
cd /apprun/server/spark/conf && cp spark-defaults.conf.template spark-defaults.conf
spark.eventLog.enabled true spark.eventLog.dir hdfs://192.168.109.139:8020/sparklog/ spark.eventLog.compress true
【log4j.properties】
cd /apprun/server/spark/conf && cp log4j.properties.template log4j.properties
vim /apprun/server/spark/conf/log4j.properties
## 改变日志级别
分发到其他机器:
将配置好的将 Spark 安装包分发给集群中其它机器,命令如下:
cd /apprun/server/
rsync -avz --progress -e ssh ./spark-3.1.2-bin-hadoop3.2 192.168.109.140:$PWD
rsync -avz --progress -e ssh ./spark-3.1.2-bin-hadoop3.2 192.168.109.141:$PWD
然后同步的2台主机[192.168.109.140\192.168.109.141]做软连接
cd /apprun/server/ && ln -s spark-3.1.2-bin-hadoop3.2 spark
启动spark Standalone:
l 启动方式1:集群启动和停止

在主节点上启动spark集群:
cd /apprun/server/spark/
sbin/start-all.sh
sbin/start-history-server.sh
当 Spark 检测到默认的 Web UI 端口(如 8080)被占用时,会自动尝试递增端口号(如 8081、8082 等),这是其默认的容错行为。
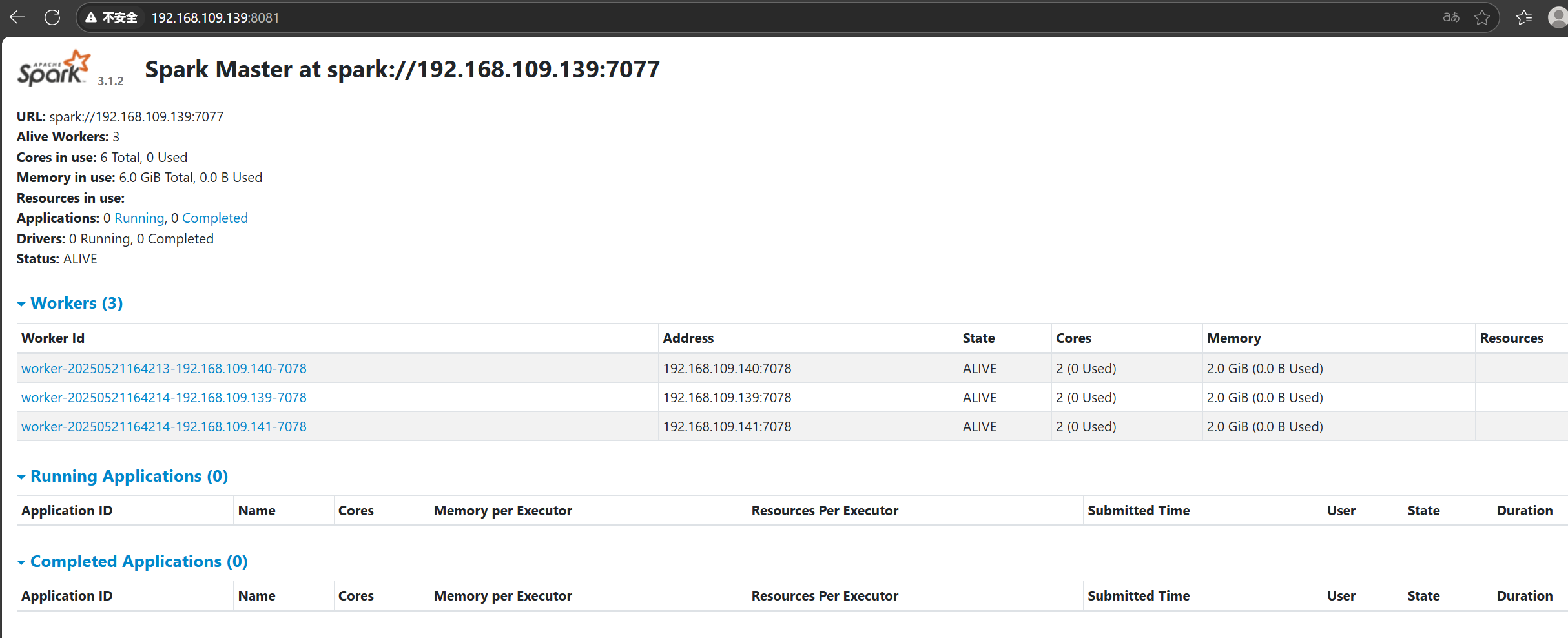
Spark的Master页面:
http://192.168.109.139:8081/ 备注:我们设置的是8080端口,但8080端口占用,spark尝试启动8081端口
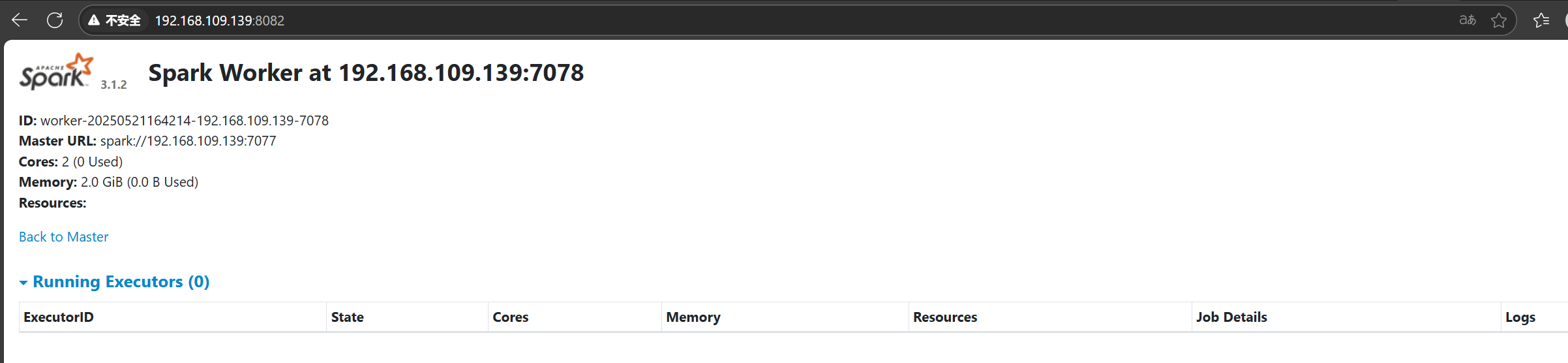
Spark的Worker页面:
http://192.168.109.139:8082/ 备注:我们设置的是8080端口,但8081端口占用,spark尝试启动8082端口
七. Byzer server 安装部署
官方指导文档:https://docs.byzer.org/#/byzer-lang/zh-cn/installation/download/site
下载:
Github Release
Byzer 社区在版本发布时,会在 Byzer-lang 项目以及 Byzer Notebook 项目提供已正式发布的产品的 Release Note 以及对应版本的二进制包和源代码:
Byzer-lang Release :https://github.com/byzer-org/byzer-lang/releases

cd /apprun/soft/ && tar -zxf byzer-lang-3.1.1-2.3.3.tar.gz -C /apprun/server
ln -s byzer-lang-3.1.1-2.3.3 ByzerServer
byzer.server.mode=server streaming.master=spark://192.168.109.139:7077 streaming.name=byzer-engine streaming.rest=true streaming.platform=spark streaming.spark.service=true streaming.driver.port=9003 streaming.enableHiveSupport=false spark.driver.memory=3g spark.executor.memory=2g spark.driver.cores=1 spark.executor.cores=2 spark.executor.instances=2 ##注释其他部分
配置环境变量文件:[3台spark集群机器]
vim /etc/profile 添加
#SPARK_HOME
export SPARK_HOME=/apprun/server/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
source /etc/profile
ByzerServer服务启动:
cd /apprun/server/ByzerServer/bin/
./byzer.sh start
Byzer 引擎在启动时,会引入环境检查以及配置读取,启动成功后,会在终端提供可访问的 Web 地址,你可以在浏览器中访问该地址进入 Byzer Web Console,如下图所示
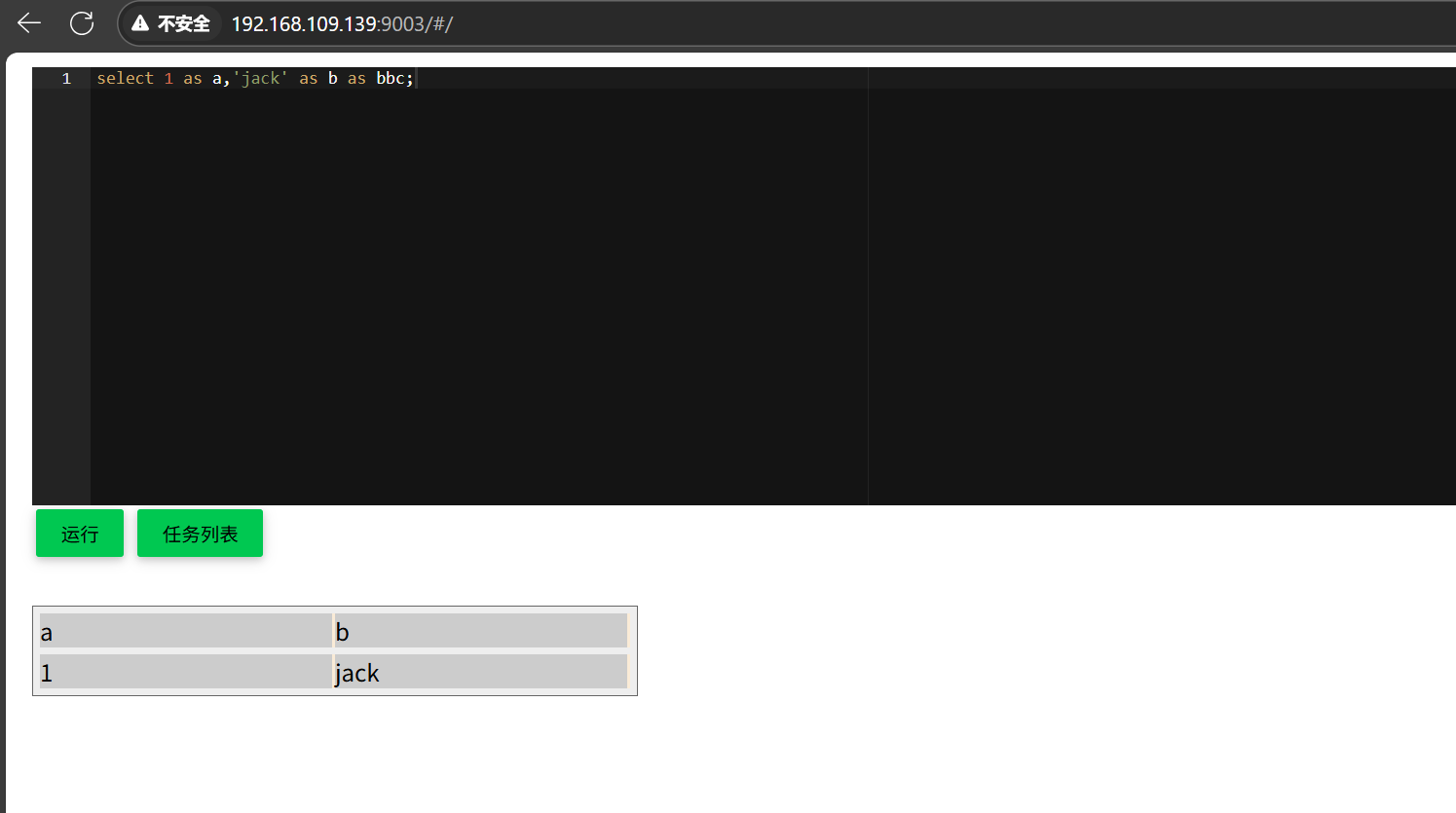
八.Byzer-Notebook 安装部署
官方指导文档:https://docs.byzer.org/#/byzer-lang/zh-cn/installation/download/site
下载:
Github Release
Byzer 社区在版本发布时,会在 Byzer-lang 项目以及 Byzer Notebook 项目提供已正式发布的产品的 Release Note 以及对应版本的二进制包和源代码:
- Byzer Notebook Release :https://github.com/byzer-org/byzer-notebook/releases

cd /apprun/soft/ && tar -zxf Byzer-Notebook-1.2.3.tar.gz -C /apprun/server
ln -s Byzer-Notebook-1.2.3 byzer
配置文件:[忘了注释 下面对接DolphinScheduler的部分配置了,需要手动调整一下]
notebook.port=9002 notebook.session.timeout=12h notebook.security.key=6173646661736466e4bda0e8bf983161 notebook.services.communication.token=6173646661736466e4bda0e8bf983161 notebook.database.type=mysql notebook.database.ip=192.168.109.138 notebook.database.port=3306 notebook.database.name=notebook notebook.database.username=notebook notebook.database.password=YiDwang@2025123! notebook.user.home=/mlsql notebook.url=http://192.168.109.137:9002 notebook.mlsql.engine-url=http://192.168.109.139:9003 notebook.mlsql.engine-backup-url=http://192.168.109.139:9004 notebook.mlsql.auth-client=streaming.dsl.auth.client.DefaultConsoleClient notebook.job.history.max-size=2000000 notebook.job.history.max-time=30 # effective when select mvn profile `redis` notebook.redis.host=localhost notebook.redis.port=6379 notebook.redis.password=redis_pwd notebook.redis.database=0 # configuration for DolphinScheduler notebook.scheduler.enable=true notebook.scheduler.scheduler-name=DolphinScheduler notebook.scheduler.scheduler-url=http://192.168.109.140:12345/dolphinscheduler notebook.scheduler.auth-token=26d536368e4b5c0f82e3496bfe0d5d24 notebook.scheduler.callback-token=6173646661736466e4bda0e8bf983161 #notebook.scheduler.callback-url=http://localhost:9002 ## optional configuration for DolphinScheduler #notebook.scheduler.project-name=ByzerScheduler #notebook.scheduler.warning-type=ALL #notebook.scheduler.warning-group-id=1 #notebook.scheduler.failure-strategy=END #notebook.scheduler.instance-priority=MEDIUM #notebook.scheduler.worker=default ## whether to enable redis notebook.env.redis-enable=false ## whether to enable auto log rotate notebook.env.log-rotate-enabled=false notebook.env.max-keep-log-file-threshold-mb=256 notebook.env.max-keep-log-file-number=10 notebook.env.log-rotate-check-cron=33 * * * *
cc 启动:
cd /apprun/server/byzer/bin/
./notebook.sh start
Byzer Server 本身不提供原生的 Web 管理页面,但它支持通过以下方式实现功能管理和监控:
通过 Byzer Notebook 进行交互管理
- Byzer Notebook 是官方提供的 Web 交互式工具(类似 Jupyter),用于编写 SQL/Python 脚本、提交作业及查看结果。
- 访问地址:默认端口
9002,如http://<Byzer-Server-IP>:9002。默认账号:admin 密码:admin - 核心功能:
- 执行 Byzer 脚本
- 管理数据源
- 查看任务日志
- 监控资源使用情况

九.DolphinScheduler 快速上手:
1)创建队列,如:spark

2)租户管理 【创建租户】,租户管理就相当于用户组,必须保障用户 与hadoop的Owner一致 http://192.168.109.139:9870/explorer.html#/;咋们这里hadoop是用apprun运行的,所以创建租户apprun

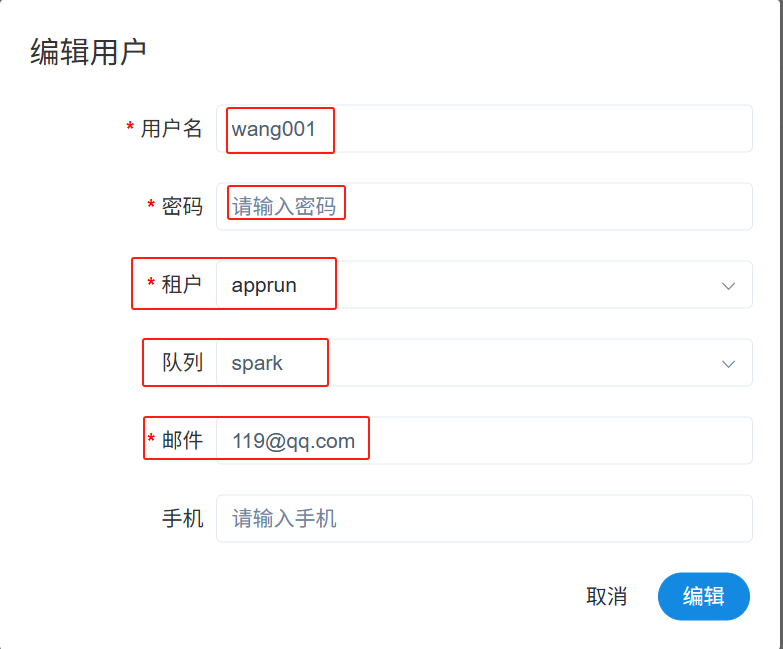
3)用户管理,创建用户:
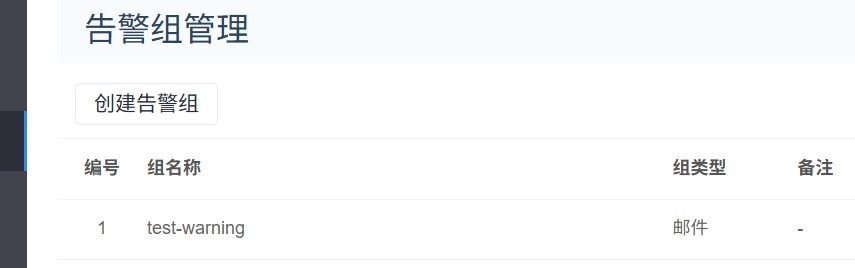
4)告警组管理,创建告警组:
5)令牌管理,创建令牌:
失效时间 自选
用户 wang001
生成令牌--》提交
6)退出,切换到wang001用户操作
7)项目管理
创建项目:
项目名称 test-project01
点击test-project01进入
8)工作流定义
创建工作流:
拖一个基础的shell节点
节点名称:test-helloworld
运行标志:正常
任务优先级:默认的【MEDIUM】 Worker分组: 默认【default】
失败重试次数:默认 失败重试间隔:默认
脚本:echo 'hello world!!!'
添加
添加第二个,拖第二个基础的shell节点
节点名称:test-hello1
脚本:echo 'hello001'
添加
添加第三个,拖第三个基础的shell节点
节点名称:test-hello2
脚本:echo 'hello002'
添加
如果有依赖关系,就用线连起来
保存
设置DAG图名称:test-dag
选择租户: apprun
添加
9)点击上线
10)点击运行:【启动前请先设置参数】都默认 运行

11)生成工作流实列

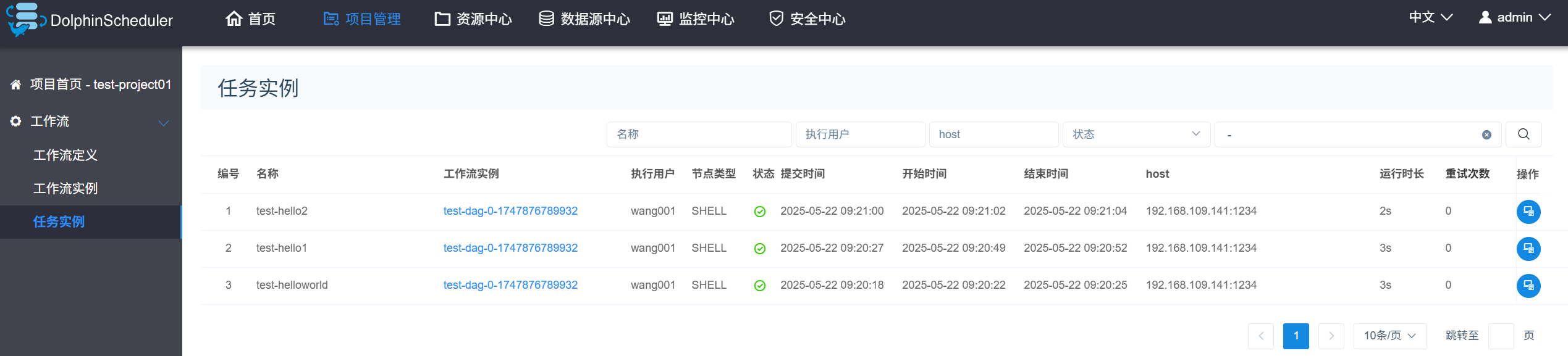
12)查看任务实列
十. Byzer-Notebook 接入 DolphinScheduler
Byzer Notebook 需要访问 DolphinScheduler 的 API 接口管理调度任务,为此需要在 DolphinScheduler 端创建一个专供 Byzer Notebook 使用的用户账号,并为此用户账号配置租户和 API 鉴权 Token。
1. 创建租户 这里我们使用租户apprun,因为我们的Byzer Notebook使用的是apprun运行
2. 创建用户
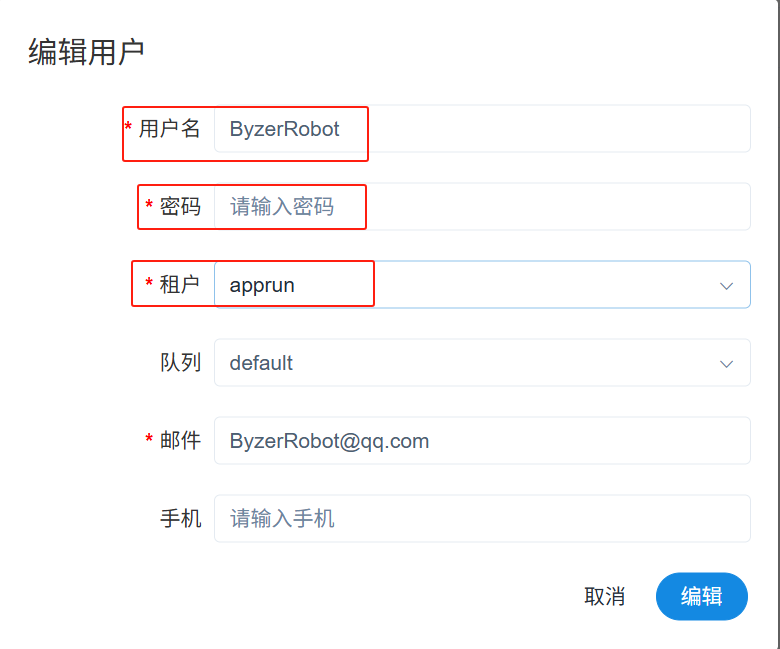
依次点击安全中心—用户管理—创建用户,用户名输入 ByzerRobot,租户选择刚刚创建的 apprun 租户,输入密码和邮箱,提交保存。
3. 创建 AuthToken
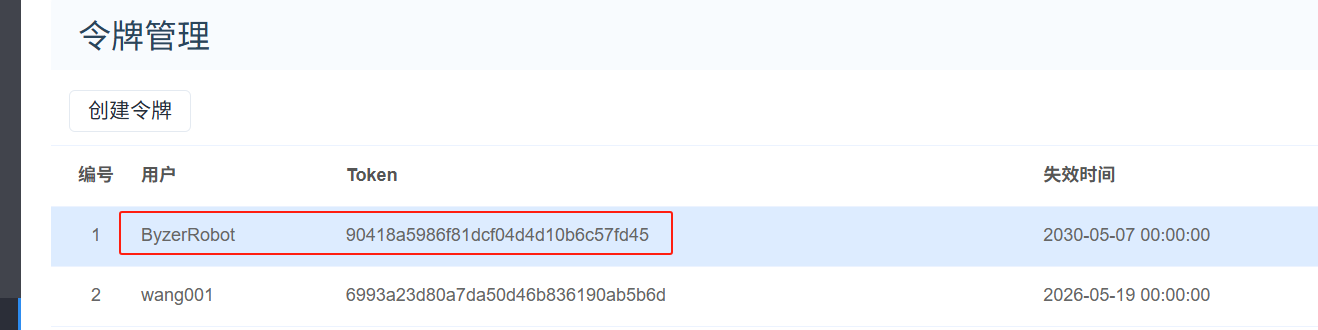
依次点击右上角用户图标—用户信息—令牌管理—创建令牌,失效时间可以酌情设置,点击生成令牌,然后提交保存:
4. 创建项目
使用 ByzerRobot 账号登录 DolphinScheduler 页面,依次点击项目管理—创建项目,项目名称输入 ByzerScheduler(此名称是 Byzer Notebook 默认的项目名称),提交保存:
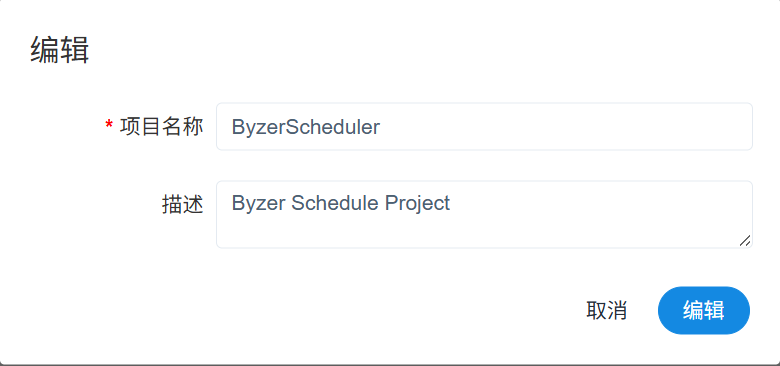
5. 创建调度并验证
进入项目管理页面,依次点击 ByzerScheduler—工作流定义—创建工作流,拖拽工具栏侧的 HTTP 图标至其右侧画布,创建测试节点 test,请求地址填写 Byzer Notebook 的 APIVersion 接口:http://192.168.109.137:9002/api/version (ip 地址需根据 Byzer Notebook 所在服务器调整),点击确认添加—右上角保存:
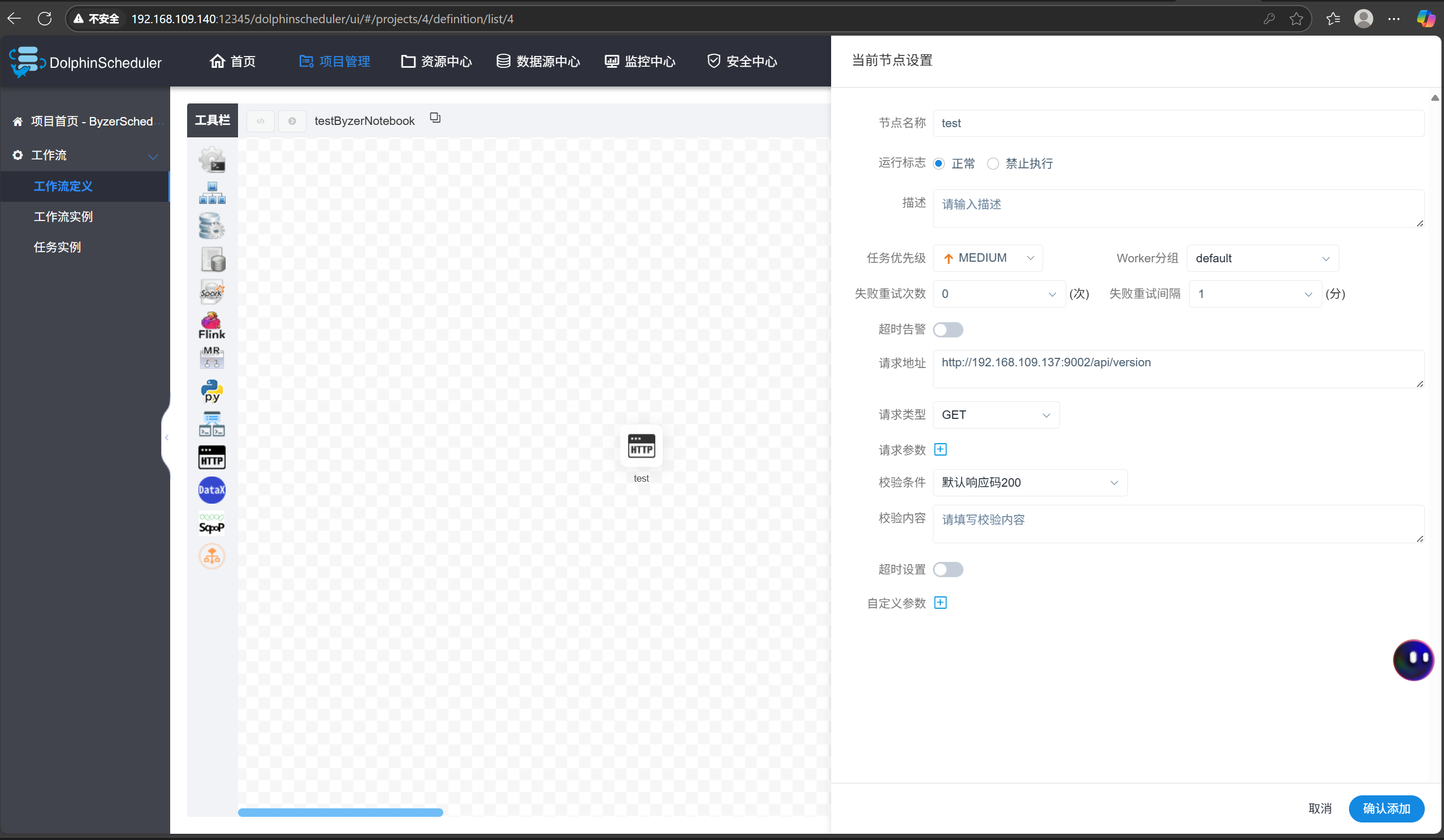
名称栏填入名称 testByzerNotebook,点击添加保存:
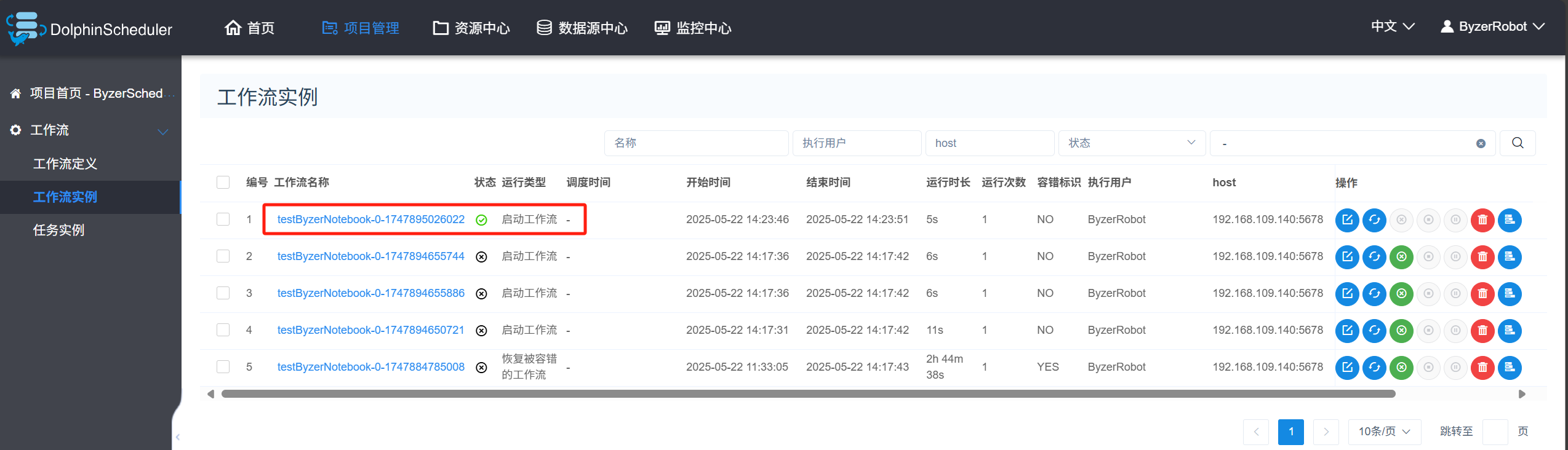
在工作流定义页面点击操作栏第四个图标上线,接着点击第二个图标运行,弹窗后继续点击运行:
进入工作流实例页面等待一段时间后,查看最终的执行状态:
注意:如果这里执行失败,需要检查Byzer Notebook 服务是否还存活。如果 DolphinScheduler 和 Byzer Notebook 分别部署在两台服务器上,需要排查两台服务器间网络连通性。
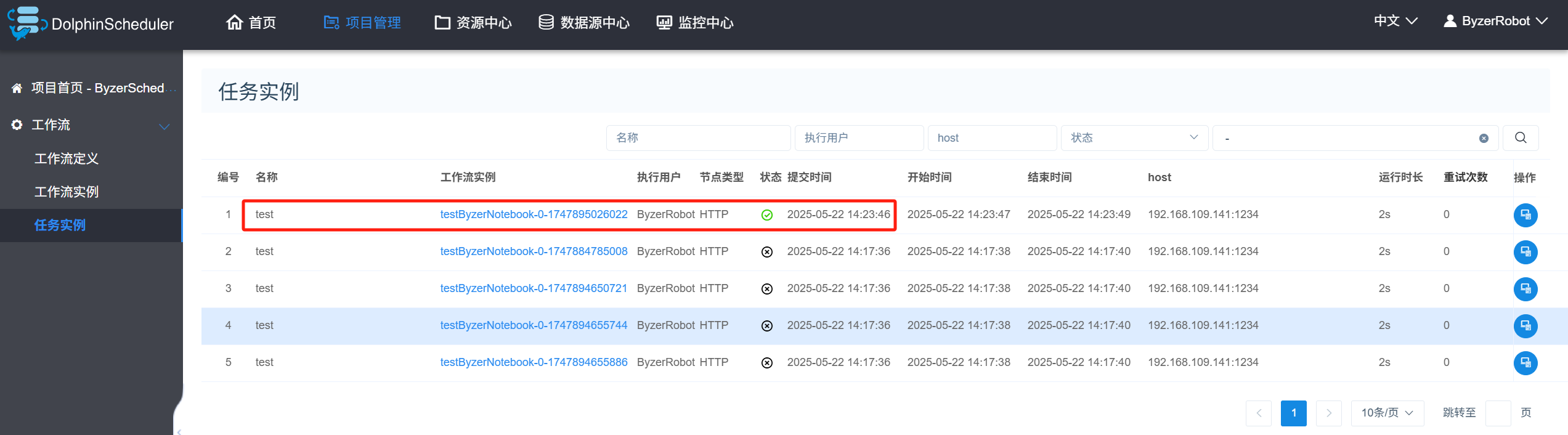
这里前面执行失败的原因是因为内存耗尽执行失败;
虚拟机内存调整:

配置 Byzer Notebook
修改 Byzer Notebook 配置项:
vim /apprun/server/byzer/conf/notebook.properties
需要调整的部分:
# configuration for DolphinScheduler
notebook.scheduler.enable=true
notebook.scheduler.scheduler-name=DolphinScheduler
notebook.scheduler.scheduler-url=http://192.168.109.140:12345/dolphinscheduler
notebook.scheduler.auth-token=90418a5986f81dcf04d4d10b6c57fd45
notebook.scheduler.callback-token=6173646661736466e4bda0e8bf983161
#notebook.scheduler.callback-url=http://localhost:9002
重启服务,即可在 Byzer Notebook 中使用调度功能:
cd /apprun/server/byzer/bin/
./notebook.sh restart
十一. DolphinScheduler 更改用户密码
方法一:通过 UI 界面修改(适用于非 admin 用户)
登录 DolphinScheduler UI(默认地址:http://localhost:12345/dolphinscheduler)
进入 Security Center(安全中心) > User Manage(用户管理)
找到需要修改的用户(如 tenant 等非 admin 用户)
点击 Edit 按钮,输入新密码后保存
⚠️ 注意:admin 账号默认不支持通过 UI 修改,需通过数据库操作
方法二:通过数据库修改(适用于 admin 用户)
连接 DolphinScheduler 的元数据库(如 MySQL)
执行 SQL:
UPDATE t_ds_user SET password = '[加密后密码]' WHERE user_name = 'admin';
重启 DolphinScheduler 服务生效
密码加密工具:
使用官方提供的加密工具生成密码(需安装 Java 环境):
java -cp dolphinscheduler-api.jar org.apache.dolphinscheduler.api.utils.PasswordUtils [你的明文密码]
[apprun@Dolphin01 soft]$
[apprun@Dolphin01 soft]$ java -cp "./dolphinscheduler-api-1.3.9.jar:./lib/*" org.apache.dolphinscheduler.api.utils.PasswordUtils Hzyd007@zxx
错误: 找不到或无法加载主类 org.apache.dolphinscheduler.api.utils.PasswordUtils
[apprun@Dolphin01 soft]$
版本太老不支持a
加密替代方案
如果仍无法解决,可通过以下方式生成密码:
使用 Python 加密(推荐)
import hashlib
print(hashlib.md5("Hzyd007@zxx".encode(encoding="UTF-8")).hexdigest())
# 输出示例:e10adc3949ba59abbe56e057f20f883e
例子:
[apprun@Dolphin01 soft]$ python2
Python 2.7.18 (default, Jun 14 2024, 12:03:20)
[GCC 8.5.0 20210514 (Anolis 8.5.0-20.0.3)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import hashlib
>>> print(hashlib.md5("Hzyd007@zxx".encode(encoding="UTF-8")).hexdigest())
0a1ff69c3d325429ab521a39b34a76da
>>>
[apprun@Dolphin01 soft]$
通过数据库直接更新
-- 使用 MD5 加密后的密码
use dolphinscheduler;
UPDATE t_ds_user SET user_password = '0a1ff69c3d325429ab521a39b34a76da' WHERE user_name = 'admin';
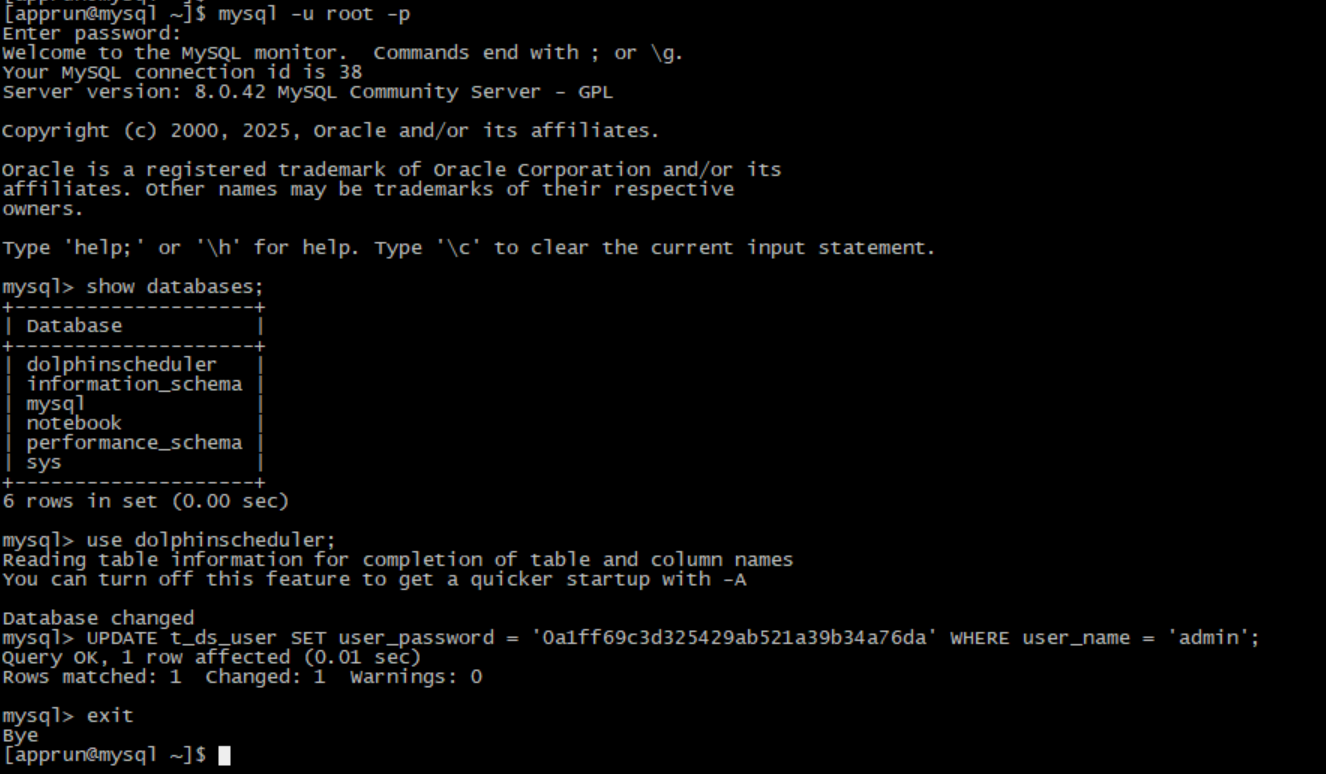
重启 DolphinScheduler 服务生效
http://192.168.109.140:12345/dolphinscheduler
admin
老密码:dolphinscheduler123
新密码:Hzyd007@zxx
问题:
Byzer notebook: http://192.168.109.137:9002/ 登录访问认证失败;
1.排查日志Byzer notebook及 Byzer日志,指向spark;
ERROR AsyncEventQueue: Listener EventLoggingListener threw an exception org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /sparklog/app-20250617101704-0000.lz4.inprogress could only be written to 0 of the 1 minReplication nodes. There are 0 datanode(s) running and 0 node(s) are excluded in this operation.
排查spark日志指向hadoop数据节点不可用;
ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool BP-860304097-ip-1747705176906 (Datanode Uuid a9d863f0-92bb-4d25-9b08-03f155abcaa0) service to ip/ip:8020 Datanode denied communication with namenode because hostname cannot be resolved (ip=*, hostname=*):
hdfs的DataNode,tail -f $HADOOP_HOME/logs/hadoop-apprun-datanode-Dolphin02.log
检查状态:hdfs dfsadmin -report
这个错误表明DataNode注册到NameNode时因主机名解析失败被拒绝。核心问题在于DataNode的IP地址(ip)无法正确解析为有效的主机名。
1. 检查主机名配置
hostname -f # 查看完整主机名
cat /etc/hostname # 验证主机名配置
2. 配置/etc/hosts文件
3. 验证反向解析
# 在DataNode验证
nslookup ip # 应该返回datanode1.example.com
ping -a ip # 应显示主机名
4. 修改HDFS关键配置
在hdfs-site.xml中增加[修改]:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>172.19.90.9:50090</value>
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
</configuration>
5. 重启服务
在每个从节点上使用以下命令启动HDFS DataNode:
$HADOOP_HOME/bin/hdfs --daemon stop datanode
在每个从节点上使用以下命令启动HDFS DataNode:
$HADOOP_HOME/bin/hdfs --daemon start datanode
6. 验证注册状态
hdfs dfsadmin -report # 应显示正常注册的DataNode
此时日志正常;但访问认证依旧失败~
排查各项配置,及mysql中账号/密码/权限正常
[root@byzer1 ~]# mysql -u notebook -p -h 172.19.90.18 -P 3306 -D notebook
mysql> select * from user_info;
访问测试:
curl -X POST "http://127.0.0.1:9002/api/user/authentication" \
-H "Content-Type: application/json" \
-H "Authorization: Basic $(echo -n 'admin:admin' | base64)" \
-v
最后定位为:
notebook.security.key
notebook.services.communication.token
notebook.scheduler.callback-token
改动问题,导致认证失败


 浙公网安备 33010602011771号
浙公网安备 33010602011771号