20172321 2018-2019-1 《程序设计与数据结构》实验二报告
20172321 2018-2019-1 《程序设计与数据结构》实验二报告
- 课程:《程序设计与数据结构》
- 班级: 1723
- 姓名: 吴恒佚
- 学号:20172321
- 实验教师:王志强
- 实验日期:2018年11月11日
- 必修/选修: 必修
一、实验内容
实验1要求——实现二叉树
- 参考教材p212,完成链树LinkedBinaryTree的实现(getRight,contains,toString,preorder,postorder)
- 用JUnit或自己编写驱动类对自己实现的LinkedBinaryTree进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息
- 课下把代码推送到代码托管平台
实验2要求——中序先序序列构造二叉树
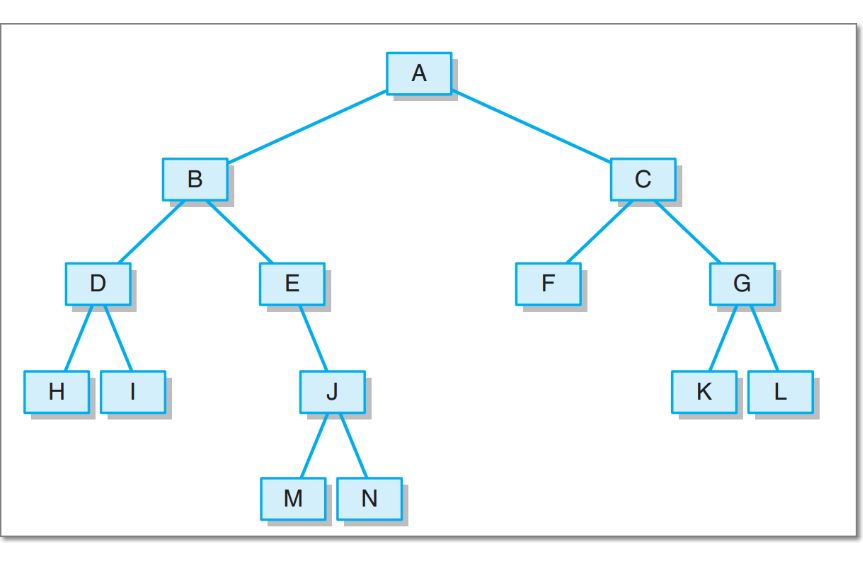
- 基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二㕚树的功能,比如给出中序HDIBEMJNAFCKGL和后序ABDHIEJMNCFGKL,构造出附图中的树
- 用JUnit或自己编写驱动类对自己实现的功能进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息
- 课下把代码推送到代码托管平台
实验3要求——决策树
- 自己设计并实现一颗决策树
- 提交测试代码运行截图,要全屏,包含自己的学号信息
- 课下把代码推送到代码托管平台
实验4要求——表达式树
- 输入中缀表达式,使用树将中缀表达式转换为后缀表达式,并输出后缀表达式和计算结果(如果没有用树,则为0分)
- 提交测试代码运行截图,要全屏,包含自己的学号信息
- 课下把代码推送到代码托管平台
实验5要求——二叉查找树
- 完成PP11.3
- 提交测试代码运行截图,要全屏,包含自己的学号信息
- 课下把代码推送到代码托管平台
实验6要求——红黑树分析
- 参考http://www.cnblogs.com/rocedu/p/7483915.html对Java中的红黑树(TreeMap,HashMap)进行源码分析,并在实验报告中体现分析结果。
- (C:\Program Files\Java\jdk-11.0.1\lib\src\java.base\java\util)
二、实验过程及结果
实验1
- 本实验要求实现
getRight方法、contains方法、toString方法、preorder方法、postorder方法,此五个方法。
getRight方法
public LinkedBinaryTree1<T> getRight() {
LinkedBinaryTree1 node = new LinkedBinaryTree1();
node.root = root.getRight();
return node;
}
这个基本上是之前很久就实现的一个简单的方法,先进行一个树的初始化,可以得到一个新树,然后通过下面一行的代码得到新的根,使我们得到合适的右子树。
contains方法
@Override
public boolean contains(T targetElement) {
if (find(targetElement) == targetElement) {
return true;
} else {
return false;
}
}
@Override
public T find(T targetElement) throws ElementNotFoundException {
BinaryTreeNode<T> current = findNode(targetElement, root);
if (current == null)
throw new ElementNotFoundException("LinkedBinaryTree");
return (current.getElement());
}
这个方法其实本身没有什么东西,但是里面需要用到
find方法,首先用find方法查找这个结点,假如找到了这个结点就返回true,假如没有找到就返回false。
toString方法
public String toString() {
UnorderedListADT<BinaryTreeNode<T>> nodes = new week7.jiumingdaima.ArrayUnorderedList<BinaryTreeNode<T>>();
UnorderedListADT<Integer> levelList = new week7.jiumingdaima.ArrayUnorderedList<Integer>();
BinaryTreeNode<T> current;
String result = "";
int printDepth = this.getHeight();
int possibleNodes = (int) Math.pow(2, printDepth + 1);
int countNodes = 0;
nodes.addToRear(root);
Integer currentLevel = 0;
Integer previousLevel = -1;
levelList.addToRear(currentLevel);
while (countNodes < possibleNodes) {
countNodes = countNodes + 1;
current = nodes.removeFirst();
currentLevel = levelList.removeFirst();
if (currentLevel > previousLevel) {
result = result + "\n\n";
previousLevel = currentLevel;
for (int j = 0; j < ((Math.pow(2, (printDepth - currentLevel))) - 1); j++)
result = result + " ";
} else {
for (int i = 0; i < ((Math.pow(2, (printDepth - currentLevel + 1)) - 1)); i++) {
result = result + " ";
}
}
if (current != null) {
result = result + (current.getElement()).toString();
nodes.addToRear(current.getLeft());
levelList.addToRear(currentLevel + 1);
nodes.addToRear(current.getRight());
levelList.addToRear(currentLevel + 1);
} else {
nodes.addToRear(null);
levelList.addToRear(currentLevel + 1);
nodes.addToRear(null);
levelList.addToRear(currentLevel + 1);
result = result + " ";
}
}
return result;
}
这个代码直接使用的书上
ExpressionTree类的代码
preorder方法
public Iterator<T> iteratorPreOrder() {
ArrayUnorderedList<T> tempList = new ArrayUnorderedList<T>();
preOrder(root, tempList);
return new TreeIterator(tempList.iterator());
}
public ArrayUnorderedList preorder() {
ArrayUnorderedList<T> tempList = new ArrayUnorderedList<T>();
preOrder(root, tempList);
return tempList;
}
protected void preOrder(BinaryTreeNode<T> node,
ArrayUnorderedList<T> tempList) {
if (node != null) {
// System.out.print(node.getElement()+" ");
tempList.addToRear(node.getElement());
preOrder(node.getLeft(), tempList);
preOrder(node.getRight(), tempList);
}
}
这个方法要用到的迭代器方法和本身都是已经给出了的,我加了一段方便方法直接使用
postorder方法
public ArrayUnorderedList postorder() {
ArrayUnorderedList<T> tempList = new ArrayUnorderedList<T>();
postOrder(root, tempList);
return tempList;
}
和前序遍历一样都是现成的方法,只是加了一段
结果
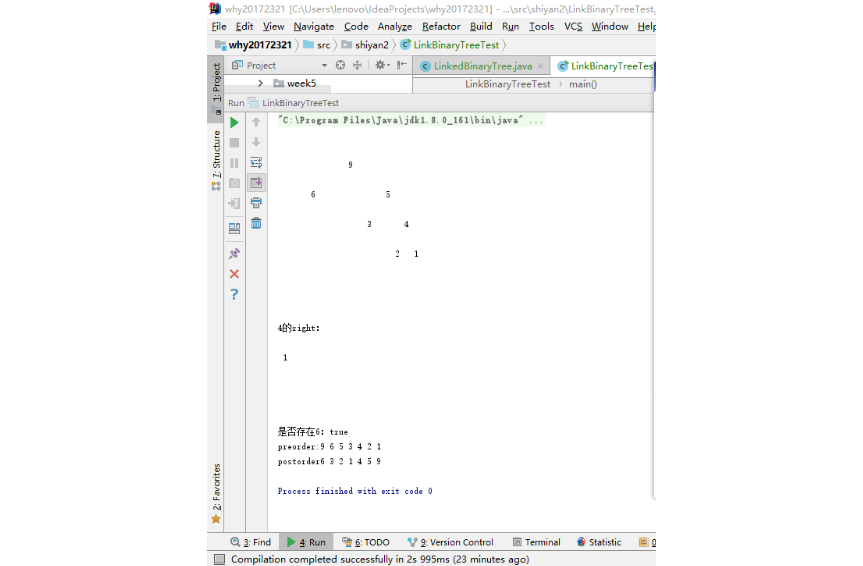
实验2
- 用给出的中序和先序来构建二叉树
//根据前序和中序序列,建立二叉树
public int findroot(String[] S, String s, int begin, int end) {
for (int i = begin; i <= end; i++) {
if (S[i] == s) {
return i;
}
}
return -1;
}
public BinaryTreeNode getAtree(String[] preSort, int prestart, int preend, String[] inSort, int instart, int inend) {
if (prestart > preend || instart > inend) {
return null;
}
if (preSort.length != inSort.length) {
try {
throw new Exception("不满足条件的非法输入!");
} catch (Exception e) {
e.printStackTrace();
}
}
BinaryTreeNode treeroot;
String rootData = preSort[prestart];
treeroot = new BinaryTreeNode(rootData);
int rwhere = findroot(inSort, rootData, instart, inend);//找根节点的位置
treeroot.left = getAtree(preSort, prestart + 1, prestart + rwhere - instart, inSort, instart, rwhere - 1);//左子树
treeroot.right = getAtree(preSort, prestart + rwhere - instart + 1, preend, inSort, rwhere + 1, inend);//右子树
return treeroot;
}
public void getAtree(String[] preOrder, String[] inOrder) {
this.root = getAtree(preOrder, 0, preOrder.length - 1, inOrder, 0, inOrder.length - 1);
}
-
在上个实验的二叉树代码中添加
getAtree方法,结合前序和中序序列,找到根结点和左右子树,然后对左右子树分别递归使用加getAtree方法,逐步往下建立树。 -
已知先序遍历和中序遍历得到二叉树有三个步骤:
找到根结点。因为先序遍历按照先访问根结点再访问左右孩子的顺序进行的,所以先序遍历的第一个结点就是二叉树的根。
区分左右子树。在确定了根结点之后,在中序遍历结果中,根结点之前的就是左子树,根结点之后的就是右子树。如果跟结点前边或后边为空,那么该方向子树为空;如果根节点前边和后边都为空,那么根节点已经为叶子节点。
分别对左右子树再重复第一、二步直至完全构造出该树。
结果
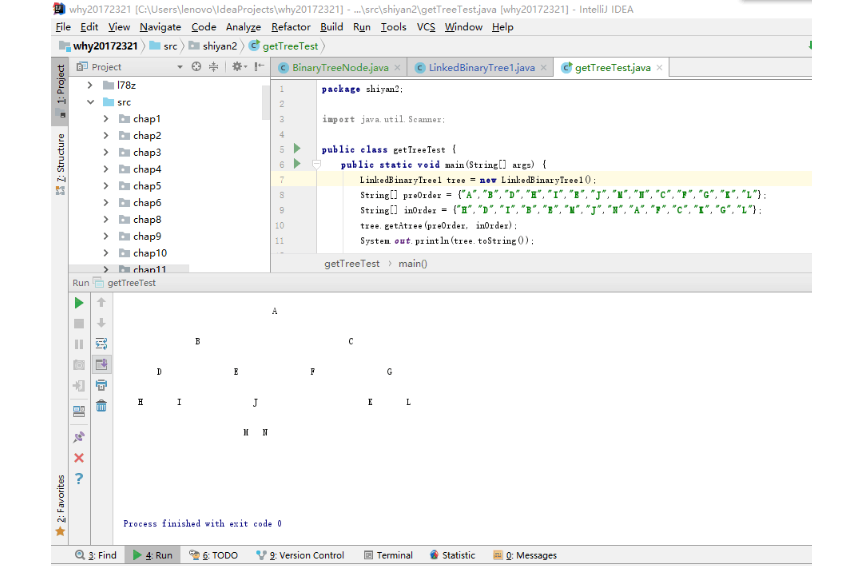
实验3
- 自己写一个决策树,基本上就是仿造书上代码。
- 代码就是书上的例题,如果要偷懒的话,直接把
input.txt每个选项改一下就好了,我改了一下二叉树的形状,结果下面那堆数字就要全部改一下了
5 9 10
7 11 12
8 13 14
3 5 6
4 7 8
2 3 4
0 1 2
结果
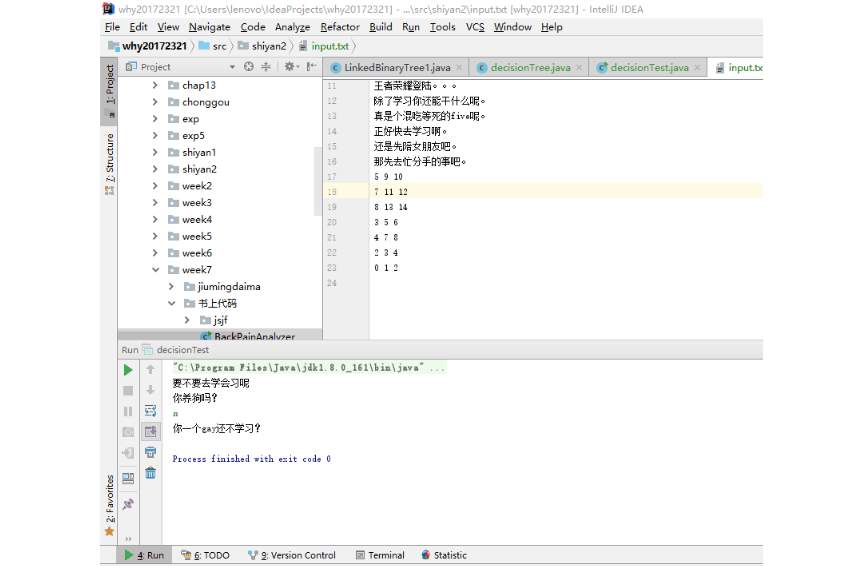
实验4
- 第四个实验要求输入中缀表达式,使用树将中缀表达式转换为后缀表达式,并输出后缀表达式和计算结果
- 我觉得思路很简单,就是先模仿之前的一个书上代码——用后缀表达式得到二叉树,我们就用中缀表达式得到二叉树,
public int evaluate(String expression) throws EmptyCollectionException {
ExpressionTree operand1, operand2;
char operator;
String tempToken;
Scanner parser = new Scanner(expression);
while (parser.hasNext()) {
tempToken = parser.next();
operator = tempToken.charAt(0);
if ((operator == '+') || (operator == '-') || (operator == '*') || (operator == '/'))
{
operand1 = getOperand(treeStack);
operand2 = getOperand(treeStack);
treeStack.push(new ExpressionTree(new ExpressionTreeOp(1, operator, 0), operand2, operand1));
} else
{
treeStack.push(new ExpressionTree(new ExpressionTreeOp(2, ' ',
Integer.parseInt(tempToken)), null, null));
}
}
return (treeStack.peek()).evaluateTree();
}
- 然后把这个二叉树后序遍历一遍就可以了。
public void posorder() {
System.out.println("后缀表达式为: ");
posOrder(root);
System.out.println("");
}
public void posOrder(BinaryNode node) {
if (node != null) {
posOrder(node.getLeft());
posOrder(node.getRight());
System.out.print(node.getData() + " ");
}
}
结果
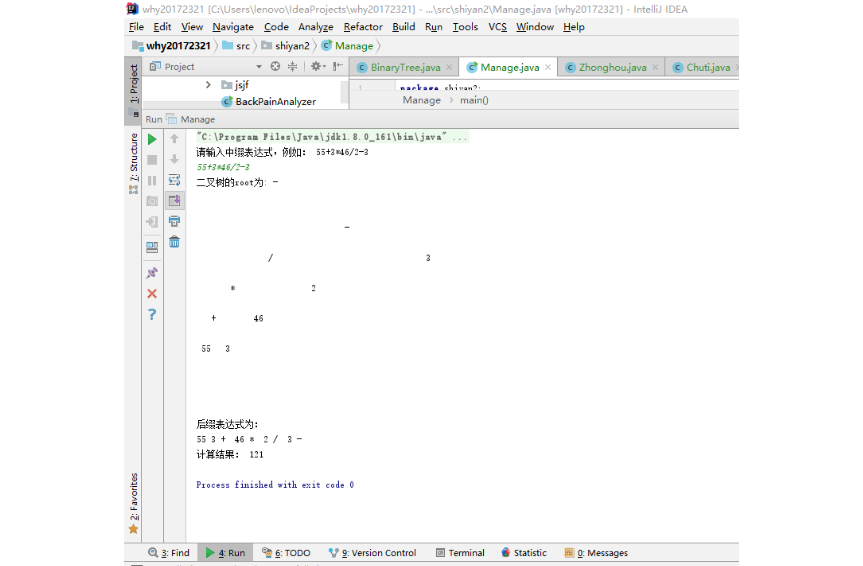
实验5
- 就是把以前的pp在运行一遍
removeMax方法
public T removeMax() throws EmptyCollectionException {
// To be completed as a Programming Project
T result = null;
if (isEmpty())
throw new EmptyCollectionException("LinkedBinarySearchTree");
else {
if (root.right == null) {
result = root.element;
root = root.left;
} else {
BinaryTreeNode<T> parent = root;
BinaryTreeNode<T> current = root.right;
while (current.right != null) {
parent = current;
current = current.right;
}
result = current.element;
parent.right = current.left;
}
modCount--;
}
return result;
}
findMin方法
public T findMin() throws EmptyCollectionException {
// To be completed as a Programming Project
T result = null;
if (isEmpty())
throw new EmptyCollectionException("LinkedBinarySearchTree");
else {
if (root.left == null) {
result = root.element;
} else {
BinaryTreeNode<T> parent = root;
BinaryTreeNode<T> current = root.left;
while (current.left != null) {
parent = current;
current = current.left;
}
result = current.element;
}
}
return result;
}
结果

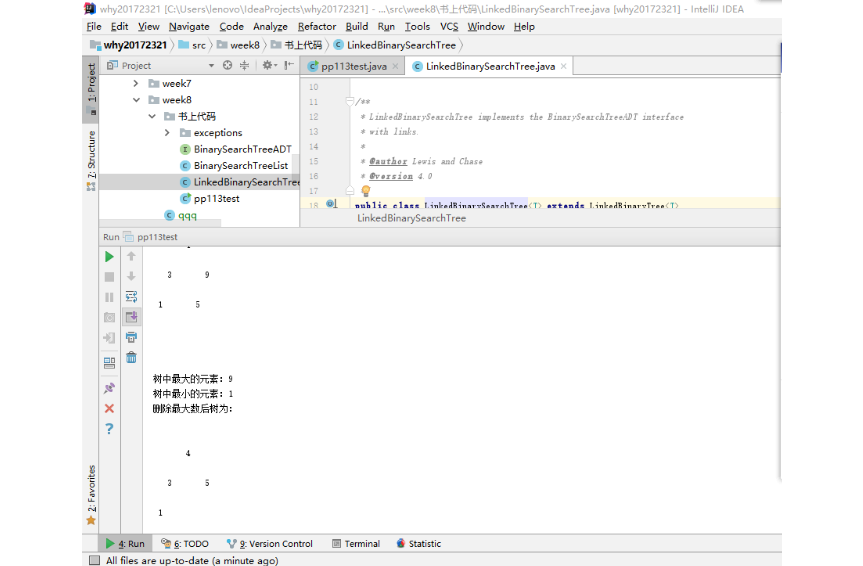
实验6
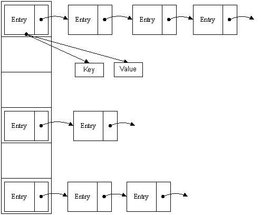
HashMap
- HashMap可以说是Java中最常用的集合类框架之一,是Java语言中非常典型的数据结构,我们总会在不经意间用到它,很大程度上方便了我们日常开发。
- HashMap 是基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
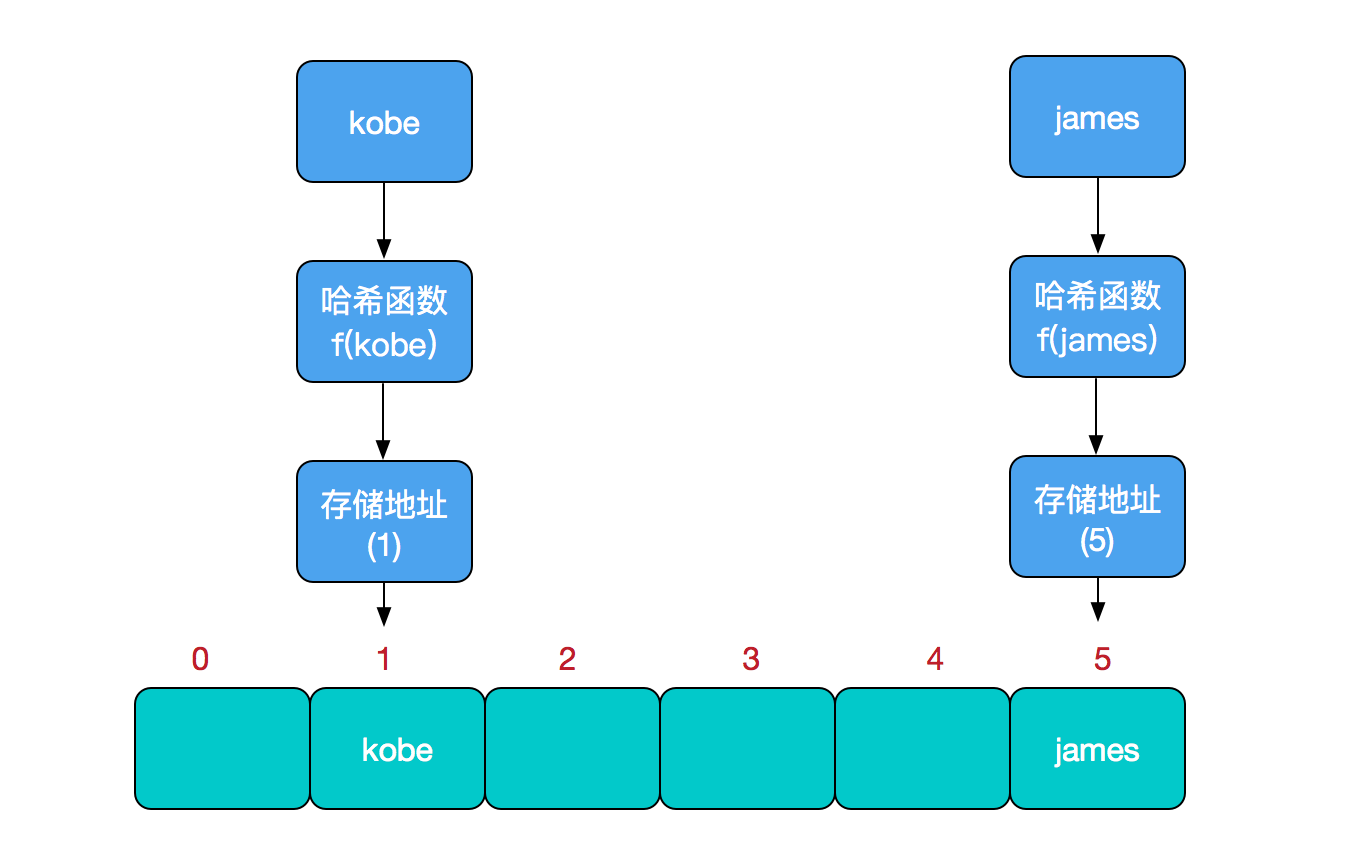
- HashMap 的实例有两个参数影响其性能:初始容量 和加载因子。容量 是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
构造函数和关键方法

- HashMap遵循集合框架的约束,提供了一个参数为空的构造函数和有一个参数且参数类型为Map的构造函数。除此之外,还提供了两个构造函数,用于设置HashMap的容量(capacity)与平衡因子(loadFactor)(平衡因子=|右子树高度-左子树高度|)。
// 默认构造函数。
public HashMap() {
// 设置“加载因子”
this.loadFactor = DEFAULT_LOAD_FACTOR;
// 设置“HashMap阈值”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
// 创建Entry数组,用来保存数据
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
// 指定“容量大小”和“加载因子”的构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// HashMap的最大容量只能是MAXIMUM_CAPACITY
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
// 设置“加载因子”
this.loadFactor = loadFactor;
// 设置“HashMap阈值”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
threshold = (int)(capacity * loadFactor);
// 创建Entry数组,用来保存数据
table = new Entry[capacity];
init();
}
// 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 包含“子Map”的构造函数
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
// 将m中的全部元素逐个添加到HashMap中
putAllForCreate(m);
}

- containsKey()
containsKey() 的作用是判断HashMap是否包含key。
public boolean containsKey(Object key) {
return getEntry(key) != null;
}
containsKey() 首先通过getEntry(key)获取key对应的Entry,然后判断该Entry是否为null。
getEntry()的源码如下:
final Entry<K,V> getEntry(Object key) {
// 获取哈希值
// HashMap将“key为null”的元素存储在table[0]位置,“key不为null”的则调用hash()计算哈希值
int hash = (key == null) ? 0 : hash(key.hashCode());
// 在“该hash值对应的链表”上查找“键值等于key”的元素
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
getEntry() 的作用就是返回“键为key”的键值对,它的实现源码中已经进行了说明。
这里需要强调的是:HashMap将“key为null”的元素都放在table的位置0处,即table[0]中;“key不为null”的放在table的其余位置!
- put()
put() 的作用是对外提供接口,让HashMap对象可以通过put()将“key-value”添加到HashMap中。
public V put(K key, V value) {
// 若“key为null”,则将该键值对添加到table[0]中。
if (key == null)
return putForNullKey(value);
// 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出!
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 若“该key”对应的键值对不存在,则将“key-value”添加到table中
modCount++;
addEntry(hash, key, value, i);
return null;
}
- 若要添加到HashMap中的键值对对应的key已经存在HashMap中,则找到该键值对;然后新的value取代旧的value,并退出!
- 若要添加到HashMap中的键值对对应的key不在HashMap中,则将其添加到该哈希值对应的链表中,并调用addEntry()。
- 说到addEntry(),就不得不说另一个函数createEntry()。
addEntry()一般用在 新增Entry可能导致“HashMap的实际容量”超过“阈值”的情况下。例如,我们新建一个HashMap,然后不断通过put()向HashMap中添加元素;put()是通过addEntry()新增Entry的。在这种情况下,我们不知道何时“HashMap的实际容量”会超过“阈值”;因此,需要调用addEntry()
createEntry() 一般用在 新增Entry不会导致“HashMap的实际容量”超过“阈值”的情况下。例如,我们调用HashMap“带有Map”的构造函数,它绘将Map的全部元素添加到HashMap中;但在添加之前,我们已经计算好“HashMap的容量和阈值”。也就是,可以确定“即使将Map中的全部元素添加到HashMap中,都不会超过HashMap的阈值”。此时,调用createEntry()即可。
- get()
get() 的作用是获取key对应的value,它的实现代码如下:
public V get(Object key) {
if (key == null)
return getForNullKey();
// 获取key的hash值
int hash = hash(key.hashCode());
// 在“该hash值对应的链表”上查找“键值等于key”的元素
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
- remove()
remove() 的作用是删除“键为key”元素
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
// 删除“键为key”的元素
final Entry<K,V> removeEntryForKey(Object key) {
// 获取哈希值。若key为null,则哈希值为0;否则调用hash()进行计算
int hash = (key == null) ? 0 : hash(key.hashCode());
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
// 删除链表中“键为key”的元素
// 本质是“删除单向链表中的节点”
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
三、实验过程中遇到的问题和解决过程
- 问题1:在实现决策树的时候,我发现了这堆看起来夏姬霸乱写的东西他们其实是有排列顺序的,然后在我想顺便改改就行时,竟然不行!!!

- 解决方案: 首先我们可以很容易的发现第一行的那个13是代表了方块的个数。
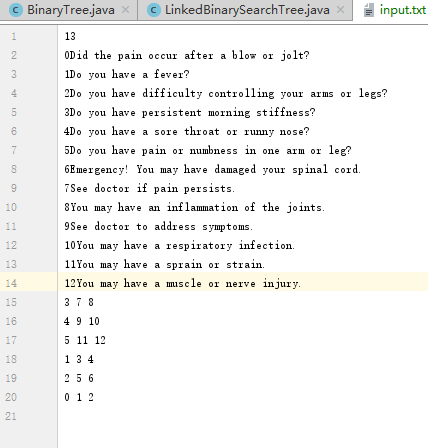
因为这一大堆英语并不是很直观,我在他们前面进行了编号。然后在我自己试着写的时候发现0 1 2必须在最下面一排,1是左孩子,2是右孩子,再上面一排数字必须是先安排右孩子和他的孩子们,就是说必须是
2 5 6
1 3 4
而不是
1 3 4
2 5 6
除非没有右孩子
四、感想
- 脑阔有点疼,好像每次写实验报告都是大过节的吧,上次国庆来着,不过每次实验都能找出以前代码里的许多瑕疵和一些知识上的盲区,尤其是这次的实验4和实验6,我又学到了好多新知识呢。。。满脸开心


 浙公网安备 33010602011771号
浙公网安备 33010602011771号